LLM Finetuning Toolkit
v0.2.3

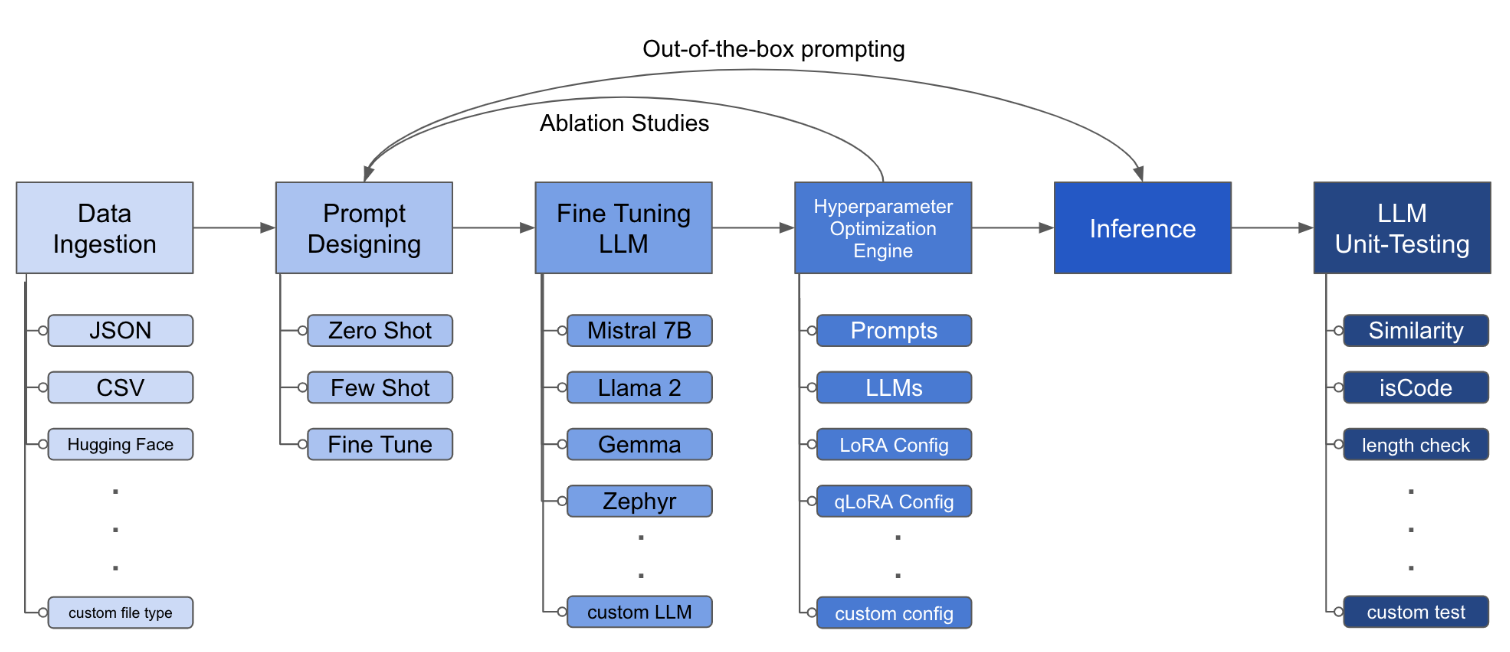
LLM Finetuning Toolkit adalah alat CLI berbasis konfigurasi untuk meluncurkan serangkaian percobaan penyempurnaan LLM pada data Anda dan mengumpulkan hasilnya. Dari satu file konfigurasi yaml tunggal, kontrol semua elemen dari pipa eksperimen khas - prompt , llms open -source , strategi optimasi dan pengujian LLM .
PIPX menginstal paket dan dependensi di lingkungan virtual yang terpisah
pipx install llm-toolkitpip install llm-toolkitPanduan ini berisi 3 tahap yang akan memungkinkan Anda untuk mendapatkan hasil maksimal dari toolkit ini!
llmtune generate config
llmtune run ./config.yml Perintah pertama menghasilkan file config.yml starter yang bermanfaat dan menyimpan di direktori kerja saat ini. Ini diberikan kepada pengguna untuk memulai dengan cepat dan sebagai basis untuk modifikasi lebih lanjut.
Kemudian perintah kedua memulai proses fine-tuning menggunakan pengaturan yang ditentukan dalam config.yaml file konfigurasi YAML default.yaml.
File konfigurasi adalah bagian utama yang mendefinisikan perilaku toolkit. Ini ditulis dalam format YAML dan terdiri dari beberapa bagian yang mengontrol berbagai aspek proses, seperti konsumsi data, definisi model, pelatihan, inferensi, dan jaminan kualitas. Kami menyoroti beberapa bagian penting.
Untuk mengaktifkan perhatian flash untuk model yang didukung. Instal pertama flash-attn :
pipx
pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolationPip
pip install flash-attn --no-build-isolation
Kemudian, tambahkan ke file konfigurasi.
model :
torch_dtype : " bfloat16 " # or "float16" if using older GPU
attn_implementation : " flash_attention_2 " Contoh dari apa konsumsi data itu terlihat:
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
# ## Instruction: {instruction}
# ## Input: {input}
# ## Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 file_type : " json "
path : " <path to your data file> file_type : " csv "
path : " <path to your data file> Bidang prompt membantu membuat instruksi untuk menyempurnakan LLM. Ini membaca data dari kolom tertentu, disebutkan dalam braket {}, yang ada dalam dataset Anda. Dalam contoh yang disediakan, diharapkan file data memiliki nama kolom: instruction , input dan output .
Bidang prompt menggunakan prompt dan prompt_stub selama penyesuaian. Namun, selama pengujian, hanya bagian prompt yang digunakan sebagai input ke LLM yang disempurnakan.
model :
hf_model_ckpt : " NousResearch/Llama-2-7b-hf "
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 "
# LoRA Params -------------------
lora :
task_type : " CAUSAL_LM "
r : 32
lora_dropout : 0.1
target_modules :
- q_proj
- v_proj
- k_proj
- o_proj
- up_proj
- down_proj
- gate_proj hf_model_ckpt : " mistralai/Mistral-7B-v0.1 " hf_model_ckpt : " tiiuae/falcon-7b "r dan putus sekolah, dapat diubah. lora :
r : 64
lora_dropout : 0.25 qa :
llm_metrics :
- length_test
- word_overlap_test Konfigurasi ini akan menjalankan penyesuaian dan menyimpan hasil di bawah direktori ./experiment/[unique_hash] . Setiap konfigurasi yang unik akan menghasilkan hash yang unik, sehingga alat kami dapat secara otomatis mengambil tempat yang ditinggalkan. Misalnya, jika Anda perlu keluar di tengah pelatihan, dengan meluncurkan kembali skrip, program akan secara otomatis memuat dataset yang ada yang telah dihasilkan di bawah direktori, alih -alih melakukannya lagi.
Setelah skrip selesai berjalan, Anda akan melihat artefak yang berbeda ini:
/dataset # generated pkl file in hf datasets format
/model # peft model weights in hf format
/results # csv of prompt, ground truth, and predicted values
/qa # csv of test results: e.g. vector similarity between ground truth and predictionSetelah semua perubahan telah dimasukkan dalam file YAML, Anda dapat menggunakannya untuk menjalankan eksperimen fine-tuning khusus!
python toolkit.py --config-path < path to custom YAML file >Alur kerja yang menyempurnakan biasanya melibatkan menjalankan studi ablasi di berbagai LLM, desain cepat dan teknik optimasi. File konfigurasi dapat diubah untuk mendukung menjalankan studi ablasi.
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
- >-
This is the first prompt template to iterate over
### Input: {input}
### Output:
- >-
This is the second prompt template
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 model :
hf_model_ckpt :
[
" NousResearch/Llama-2-7b-hf " ,
mistralai/Mistral-7B-v0.1",
" tiiuae/falcon-7b " ,
]
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 " lora :
r : [16, 32, 64]
lora_dropout : [0.25, 0.50] Toolkit ini menyediakan arsitektur yang modular dan dapat diperluas yang memungkinkan pengembang untuk menyesuaikan dan meningkatkan fungsinya sesuai dengan kebutuhan spesifik mereka. Setiap komponen toolkit, seperti konsumsi data, penyesuaian, inferensi, dan pengujian jaminan kualitas, dirancang agar mudah diperpanjang.
Kontribusi sumber terbuka untuk toolkit ini dipersilakan dan didorong. Jika Anda ingin berkontribusi, silakan lihat Contributing.md.


