neo4j nlp
1.0.0
截至2021年5月,该存储库已退休。
该NEO4J插件提供基于图形的自然语言处理功能。
主模块该模块为基础文本处理器以及在存储过程和功能上构建的域特定语言提供了一个常见的接口,使您的自然语言处理工作流程开发人员友好。
它具有2个版本,社区(开源)和具有以下NLP功能的企业:
| 社区版 | 企业版 | |
|---|---|---|
| 文本信息提取 | ✔ | ✔ |
| 同一数据库中的多语言 | ✔ | |
| 定制命名义务识别模型构建器 | ✔ | |
| ConceptNet5富集 | ✔ | ✔ |
| Microsoft概念丰富 | ✔ | ✔ |
| 关键字提取 | ✔ | ✔ |
| Textrank摘要 | ✔ | ✔ |
| 主题提取 | ✔ | |
| 单词嵌入(Word2Vec) | ✔ | ✔ |
| 相似性计算 | ✔ | ✔ |
| PDF解析 | ✔ | ✔ |
| Apache Spark绑定分布式算法 | ✔ | |
| DOC2VEC实施 | ✔ | |
| 用户界面 | ✔ | |
| ML预测功能 | ✔ | |
| 实体合并 | ✔ |
提供了两个NLP处理器实现,分别提供了Stanford NLP和OpenNLP(OpenNLP收到较少的更新,建议使用StanfordNLP)。
从版本3.5.1.53.15您需要下载语言模型,请参见下文
从Graphaware插件目录中,下载以下jar文件:
neo4j-framework (此罐子的标签为“ Graphaware-Server-enterprise-all”)neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download下载的语言模型并在Neo4J的plugins目录中复制它们。
请注意,您使用的框架的版本编号与您使用的Neo4J版本匹配。这是一个常见的设置问题。例如,如果您使用的是Neo4J 3.4.0及以上,则您下载的所有罐子都应在其版本号中包含3.4。
plugins/目录示例:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
在config/目录中的neo4j.conf文件中附加以下配置:
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
启动或重新启动您的Neo4J数据库。
注意:两个混凝土文本处理器都非常贪婪 - 您需要将足够的内存用于Neo4J Heap空间。
此外,建议以下索引和约束来加快绩效:
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
或使用专用程序:
CALL ga.nlp.createSchema()
定义您将在此数据库中使用哪种语言:
CALL ga.nlp.config.setDefaultLanguage('en')
加载扩展名后,您可以通过运行此Cypher查询来查看所有可用过程的基本文档:
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
文本提取阶段是通过自然语言处理管道完成的,每个管道都有一个启用的组件列表。
例如,基本的tokenizer管道具有以下组件:
必须首先创建您的管道:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
可用的可选参数(默认值在括号中):
name :新管道的所需名称textProcessor :应向哪个文本处理器添加新管道processingSteps :管道配置(除非另有说明,否则在斯坦福和OpenNLP中可用)tokenize (默认值:true):执行令牌化ner (默认值:true):命名实体识别sentiment (默认:false):对句子进行情感分析coref (默认值:false):核心分辨率(识别同一实体的多个提及,例如“巴拉克·奥巴马”和“他”)relations (默认值:false):在两个令牌之间运行关系识别dependency (默认:false,仅是stanfordnlp):提取键入依赖项(ex。:amod-形容词修饰符,conj- conjunct,...)cleanxml (默认值:false,仅是stanfordnlp):删除XML标签truecase (默认:false,仅仅是stanfordnlp):识别令牌的“真实”案例(如何在精心编辑的文本中大写)customNER :自定义NER模型标识符列表(作为字符串,由“'”隔开的模型标识符)stopWords :指定需要忽略的单词(如果列表以 +开头,以下单词将附加到默认的stopwords列表中,否则默认列表被覆盖)threadNumber (默认值:4):用于多线程excludedNER :(默认值:none)指定在大写案例中未识别的NE列表,例如用于在标签节点上排除NER_Money和NER_O ,请使用['o','Money']将管道设置为默认管道:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
要删除管道,请使用此命令:
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
查看所有现有管道的详细信息:
CALL ga.nlp.processor.getPipelines()
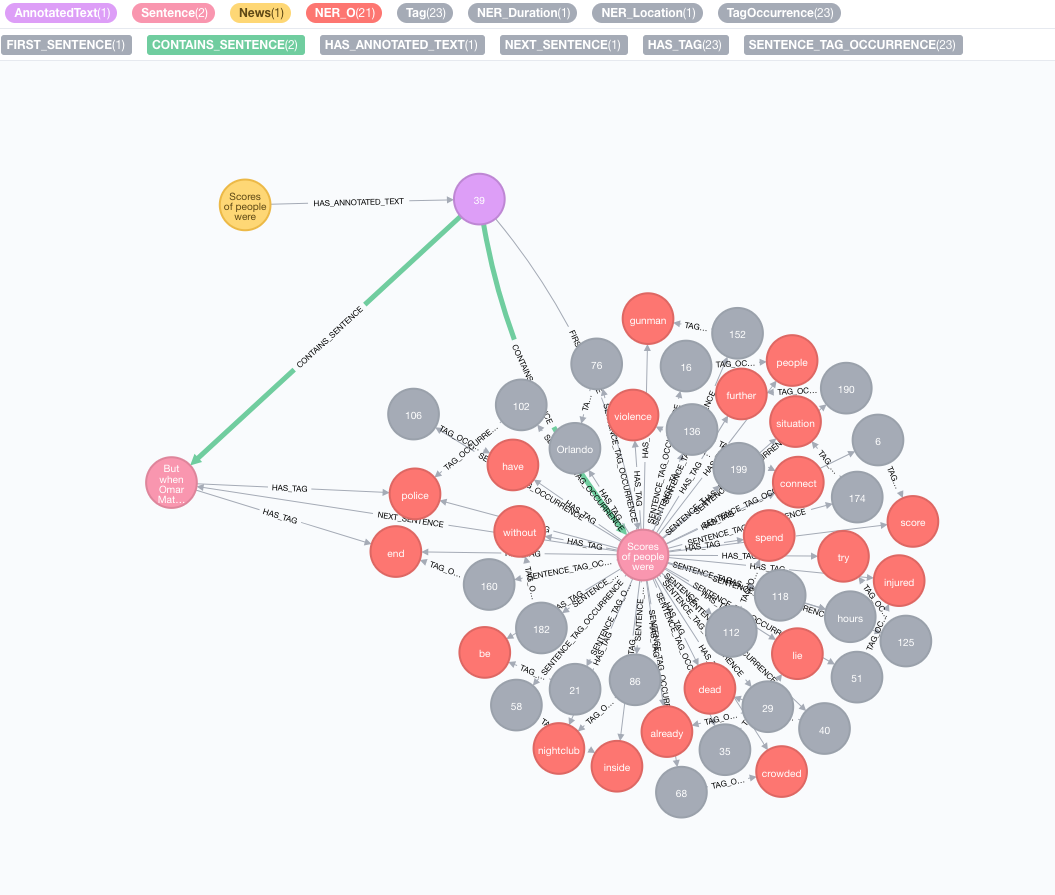
让我们以以下文本为例:
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
模拟您的原始语料库
使用文本创建一个节点,此节点将表示您的原始语料库或知识图:
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
执行文本信息提取
提取是通过annotate过程完成的,这是文本信息提取的切入点
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
annotate过程的可用参数:
text :以注释为字符串的文字id :指定将用作新的注释text节点的id属性的IDtextProcessor (默认:“ Stanford”,如果不可用,则比可用文本处理器列表中的第一个条目)pipeline (默认:令牌)checkLanguage (默认值:true):在提供的文本上运行语言检测并检查是否支持此过程将将您的原始内容链接到:News节点与:AnnotatedText节点,该节点是该特定新闻基于图的NLP的输入点。原始文本分为单词,语音的部分和功能。对文本的分析是后来步骤的起点。
运行一批注释
如果您有大量的注释数据,我们建议使用apoc:
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
如示例中提到的那样,保持batchSize和iterateList选项非常重要。并行运行注释过程将造成死锁。
我们实施外部知识库,以丰富您当前数据的知识。
截至目前,有两个实现:
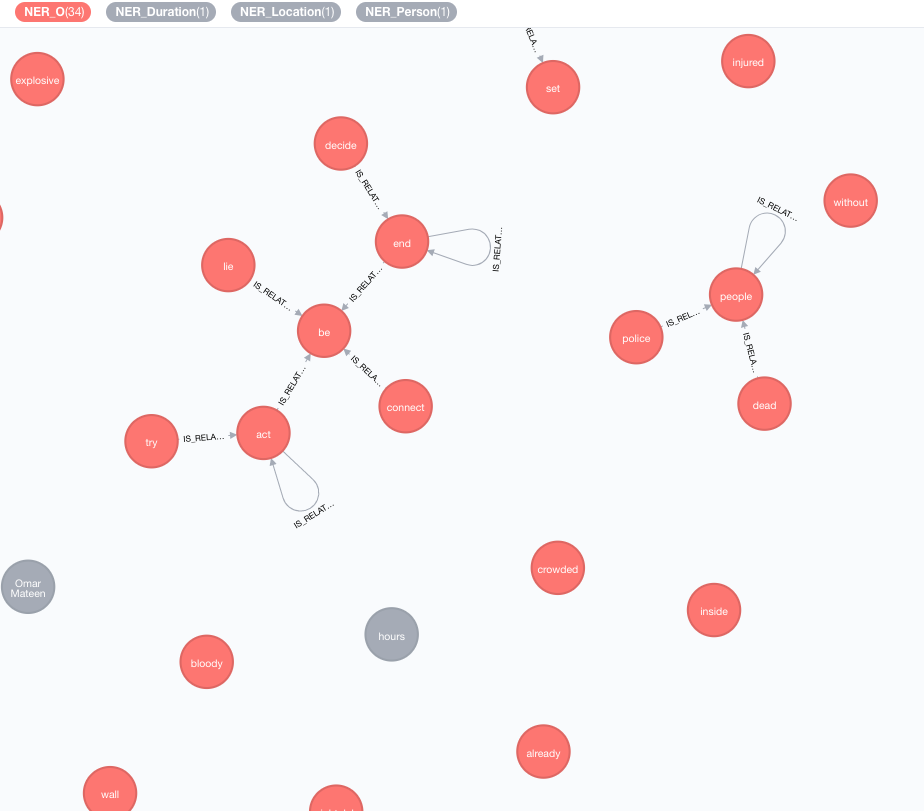
此富集将扩展图形中令牌(标签节点)的含义。
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
可用参数(默认值在括号中):
tag :标签要丰富enricher ( "conceptnet5" ):选择microsoft或conceptnet5depth ( 2 ):在概念层次结构中有多深admittedRelationships :选择所需的概念关系类型,请参阅概念文档以获取详细信息pipeline :在将概念存储到DB之前,请选择用于清洁概念的管道名称;您的系统默认管道否则使用filterByLanguage ( true ):仅允许outputLanguages中指定的语言概念;如果没有指定语言,则需要与tag相同的语言outputLanguages ( [] ):仅返回带有指定语言的概念relDirection ( "out" ):概念层次结构中的关系方向( "in" , "out" , "both" )中minWeight ( 0.0 ):最小的接纳概念关系重量limit ( 10 ):最大概念tagsplitTag ( false ):如果为true ,则tag首先被标记,然后单个令牌丰富现在,标签具有与其他丰富概念的IS_RELATED_TO 。
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText是一个强制性参数,指的是需要分析的注释文档。
可选参数(默认值在括号中):
keywordLabel (关键字):关键字节点的标签名称useDependencies (true):使用通用依赖性通过复合和AMOD关系相关的标签来丰富提取的关键字和关键短语dependenciesGraph (false):使用通用依赖关系来创建标签共发生图(默认为false,这意味着自然单词流用于构建共发生)cleanKeywords (true):运行清洁程序topXTags (1/3):设置将用作关键字 /键短语的最高评级标签的一小部分respectSentences (false):尊重或不句子的句子边界共存图形构建respectDirections (false):尊重或不尊重的指示(单词如何互相跟随)iterations (30):Pagerank迭代的数量damp (0.85):Pagerank阻尼因子threshold (0.0001):Pagerank收敛阈值removeStopwords (true):使用optwords列表共同出现图形构建和关键字的最终清洁stopwords :customize stopwords列表(如果列表以+开头,以下单词将附加到默认的stopwords列表中,否则默认列表被覆盖)admittedPOSs :指定哪些POS标签被视为关键字候选人;使用与英语不同的语言时需要forbiddenPOSs :指定构造共汇图时要忽略的POS标签列表;使用与英语不同的语言时需要forbiddenNEs :指定要忽略的NES的列表有关详细的TextRank算法说明,请参阅我们有关无监督关键字提取的博客文章。
将通用依赖项用于关键字富集( useDependencies选项)可能会导致关键字具有不必要的细节级别,例如关键字Space Shuttle Logistics程序。在许多用例中,我们也可能有兴趣知道,给定文档通常会谈论航天飞机(或Logistic程序)。为此,请使用以下一个选项进行后处理:
direct - n个标签数的每个密钥短语都针对所有文档的所有密钥短语检查,标签数为1 <m <n ;如果前者包含后一个键短语,则DESCRIBES关系是从M键词到N -Keyphrase的所有带注释的文本创建的subgroups - 与direct相同的过程,但没有直接将较高级别的关键字连接到带有注释的文本,而是通过HAS_SUBGROUP关系连接到较低级别的关键字 // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel是默认设置为“关键字”的可选参数。
默认情况下,后过程操作正在处理所有关键字,这在大图上可能很重。您可以指定在该注释上使用带有annotatedText参数应用后处理操作的注释文本:
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
示例用于使用apoc的完整关键字上有效运行它:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
可以采用类似的关键字提取方法来实施简单的摘要。创建了一个密集的连接图表,句子句句的关系代表其基于共享单词的相似性(共享单词的数量与句子中单词数的对数的总和)。然后将Pagerank用作中心度度量,以对文档中句子的相对重要性进行排名。
运行此算法:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
可用参数:
annotatedTextiterations (30):Pagerank迭代的数量damp (0.85):Pagerank阻尼因子threshold (0.0001):Pagerank收敛阈值摘要过程将新属性保存到句子节点: summaryRelevance (给定句子的pagerank值)和summaryRank (排名; 1 =最高排名句)。检索摘要的示例查询:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
您还可以确定呈现的文本是正面,负面还是中立。此过程需要一个注释的节点,该节点由上面的ga.nlp.annotate产生。
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
此过程将在成功时简单地返回“成功”,但它将应用:POSITIVE :NEUTRAL或:NEGATIVE标签对每个句子。结果,当完成情感检测完成后,您可以查询句子的情感:
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
一旦从包含某些文本的所有新闻或其他节点中提取标签后,就可以使用基于内容的相似性来计算它们之间的相似性。在此过程中,使用TF-IDF编码格式描述了每个带注释的文本。 TF-IDF是信息检索领域已建立的技术,代表术语频率为单位的文档频率。文本文档可以在多维欧几里得空间中编码为tf-idf。空间尺寸对应于先前从文档中提取的标签。每个维度(即,对于每个标签)中给定文档的坐标被计算为两个子测量的乘积:项频率和反向文档频率。
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
可用参数(默认值在括号中):
input :输入节点列表-AntotatedTextsrelationshipType (Samelity_cosine):相似性关系的类型,将其与query一起使用query :指定自己的查询以提取表格中提取TF和IDF ... RETURN id(Tag), tf, idfpropertyName (value):现有节点属性的名称(数值数组),该属性包含已经准备好的文档向量Word2Vec是一种浅的两层神经网络模型,用于产生单词嵌入(表示为多维语义向量),它是ConceptNet Numberbatch中使用的模型之一。
将源模型(向量)添加到Lucene指数中
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir>是通往目录的完整途径,该目录用要索引的源向量<path_to_index>是一个完整的路径,将存储索引<identifier>是一个自定义字符串,可唯一标识模型列出可用模型:
CALL ga.nlp.ml.word2vec.listModels
该模型现在可以用来计算单词之间的余弦相似性:
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
或者,您可以直接询问一个节点的word2vec,该节点存储在属性value中:
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
我们还可以永久存储Word2Vec向量以标记节点:
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query :返回标签的查询应附加嵌入向量modelName :使用的模型您还可以通过以下过程获得最近的邻居:
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
对于大型型号,例如,英语的完整快速文本,大约200万个单词,即时计算最近的邻居的效率低下。
您可以将模型加载到内存中,以使最近的邻居更快(FastText 1M Word Vectors通常需要27秒,如果需要从磁盘读取,则在内存中〜300ms):
确保具有专用于Neo4J的有效堆内存:
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
将模型加载到内存中:
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
并取回
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
您可以使用任何单词嵌入模型,只要以下内容是正确的:
.txt扩展名例如,您可以从fastText加载模型,然后将文件从.vec重命名为.txt :https://fasttext.cc/docs/en/english-vectors.html
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
该过程返回行,列number为页码, paragraphs是段落文本的List<String> 。
您还可以将http或https URL传递到从远程位置加载文件的过程中。
在某些情况下,PDF文档具有一些无用的内容,例如页面页脚等,您可以通过通过定义零件的零件列表来将它们排除在解析之外:
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
Tika可以被认为是爬行者,并被拒绝访问某些包含PDF的站点。您可以通过传递UserAgent选项来覆盖此内容:
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
在某些情况下,仅存储某些值而不是完整图是有用的,但请注意,尽管它可能会降低为EG提取见解(Textrank)的能力:
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
WebVTT是网络视频文本轨道的格式,例如视频的YouTube成绩单:https://fr.wikipedia.org/wiki/webvtt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
仅当当前目录的上述过程列表文件,如果您还需要走儿童目录,请使用walkdir :
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
列表存储的模型及其路径
删除并重新创建具有相同配置的管道(使用已更改的静态NER文件时有用)
版权(C)2013-2019 Graphaware
Graphaware是免费软件:您可以根据自由软件基金会发布的GNU通用公共许可证的条款进行重新分配和/或对其进行修改。该程序的分布是希望它将有用的,但没有任何保修;即使没有对特定目的的适销性或适合性的隐含保证。有关更多详细信息,请参见GNU通用公共许可证。您应该已经收到了GNU通用公共许可证的副本以及此计划。如果没有,请参见http://www.gnu.org/licenses/。


