neo4j nlp
1.0.0
По состоянию на май 2021 года этот репозиторий был в отставке.
Этот плагин NEO4J предлагает возможности обработки на основе графиков.
Основной модуль, этот модуль, обеспечивает общий интерфейс для базовых текстовых процессоров, а также языка, специфичного для домена , созданного на хранимых процедурах и функциях, что делает ваш разработчик рабочего процесса для обработки естественного языка.
Он поставляется в 2 версиях, сообществе (с открытым исходным кодом и предприятием со следующими функциями NLP:
| Сообщество издание | Enterprise Edition | |
|---|---|---|
| Извлечение текстовой информации | ✔ | ✔ |
| Многоязычные в той же базе данных | ✔ | |
| Пользовательский строитель модели | ✔ | |
| ConceptNet5 Enicher | ✔ | ✔ |
| Microsoft Concept Enicher | ✔ | ✔ |
| Извлечение ключевых слов | ✔ | ✔ |
| Textrank Summarization | ✔ | ✔ |
| Темы добыча | ✔ | |
| Слово внедрения (Word2VEC) | ✔ | ✔ |
| Вычисление сходства | ✔ | ✔ |
| PDF -анализ | ✔ | ✔ |
| Привязка Apache Spark для распределенных алгоритмов | ✔ | |
| Внедрение DOC2VEC | ✔ | |
| Пользовательский интерфейс | ✔ | |
| ML Предсказания | ✔ | |
| Сущность слияния | ✔ |
Доступны две реализации процессора NLP, соответственно Stanford NLP и OpenNLP (OpenNLP получает менее частые обновления, рекомендуется StanfordNLP).
Из версии 3.5.1.53.15 вам нужно загрузить языковые модели, см. Ниже.
В каталоге плагинов Graphaware загрузите следующие файлы jar :
neo4j-framework (банка для этого помечена "Graphaware-Server-Enterprise-All")neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download и скопируйте их в каталоге plugins NEO4J.
Позаботьтесь о том, что номера версий используемой вами фреймворка совпадают с версией Neo4J, которую вы используете . Это общая проблема настройки. Например, если вы используете NEO4J 3.4.0 и выше, все банки, которые вы загружаете, должны содержать 3.4 в номере их версии.
plugins/ пример каталога:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
Добавьте следующую конфигурацию в файл neo4j.conf в config/ каталог:
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
Начните или перезапустите свою базу данных NEO4J.
Примечание. Оба конкретных текстовых процессора довольно жадные - вам нужно будет посвятить достаточную память, чтобы Neo4J -пространство кучи.
Кроме того, следующие индексы и ограничения предлагаются для скорости производительности:
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
Или используйте выделенную процедуру:
CALL ga.nlp.createSchema()
Определите, какой язык вы будете использовать в этой базе данных:
CALL ga.nlp.config.setDefaultLanguage('en')
После загрузки расширения вы можете увидеть базовую документацию по всем доступным процедурам, запустив этот запрос Cypher:
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
Фаза извлечения текста выполняется с помощью конвейера по обработке естественного языка, каждый трубопровод имеет список включенных компонентов.
Например, базовый трубопровод tokenizer имеет следующие компоненты:
Сначала обязательно создать свой трубопровод:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
Доступные дополнительные параметры (значения по умолчанию находятся в скобках):
name : Желаемое название нового трубопроводаtextProcessor : к какому текстовому процессору должен быть добавлен новый трубопроводprocessingSteps : конфигурация трубопровода (доступна как в Stanford, так и в OpenNLP, если не указано иное)tokenize (по умолчанию: true): выполнить токенизациюner (по умолчанию: true): признание именованного объектаsentiment (по умолчанию: false): запустить анализ настроений на предложенияcoref (по умолчанию: false): разрешение Coreference (определить несколько упоминаний об одной и той же сущности, таких как «Барак Обама» и «Он»)relations (по умолчанию: false): запустите идентификацию отношений между двумя токенамиdependency (по умолчанию: false, только Stanfordnlp): извлечь типизированные зависимости (Ex.: AMOD - модификатор прилагательного, con - concunt, ...)cleanxml (по умолчанию: False, только Stanfordnlp): удалить теги XMLtruecase (по умолчанию: False, только StanfordNLP): распознает «истинный» случай токенов (как они будут заглавный в хорошо отредактированном тексте)customNER : список пользовательских идентификаторов модели NER (как строка, идентификаторы модели, разделенные «»,)stopWords : укажите слова, которые необходимо игнорировать (если список начинается с +, следующие слова добавляются в список стоп -слов по умолчанию, в противном случае список по умолчанию перезаписан)threadNumber (по умолчанию: 4): для многопоточногоexcludedNER : (по умолчанию: нет) Укажите список NE, чтобы не быть распознается в верхнем случае, например, для исключения NER_Money и NER_O на узлах тегов, используйте ['O', 'Money']Чтобы установить трубопровод в качестве трубопровода по умолчанию:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
Чтобы удалить трубопровод, используйте эту команду:
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
Чтобы увидеть детали всех существующих трубопроводов:
CALL ga.nlp.processor.getPipelines()
Давайте возьмем следующий текст в качестве примера:
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
Имитировать свой первоначальный корпус
Создайте узел с текстом, этот узел будет представлять ваш исходный корпус или график знаний:
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
Выполните извлечение текстовой информации
Извлечение выполняется с помощью процедуры annotate , которая является точкой входа в извлечение текстовой информации.
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
Доступные параметры процедуры annotate :
text : текст, чтобы аннотировать представлен как строкуid : укажите идентификатор, который будет использоваться в качестве id свойства нового аннотированного текстового узлаtextProcessor (по умолчанию: «Стэнфорд», если не доступна, чем первая запись в списке доступных текстовых процессоров)pipeline (по умолчанию: токенизатор)checkLanguage (по умолчанию: true): запустите обнаружение языка при предоставленном тексте и проверьте, поддерживается ли он Эта процедура свяжет ваш оригинал :News с :AnnotatedText узлом, который является точкой входа для НЛП на основе графика этой конкретной новости. Оригинальный текст разбивается на слова, части речи и функции. Этот анализ текста действует как отправная точка для более поздних шагов.
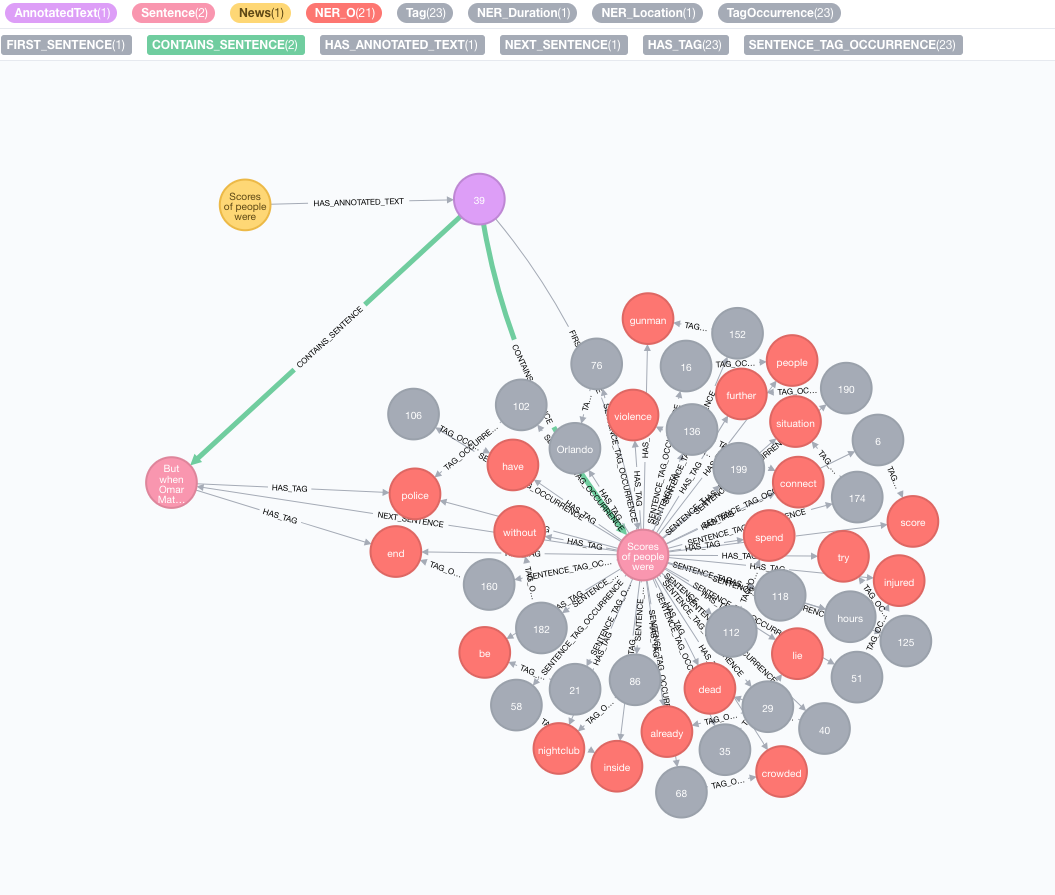
Запуск партии аннотаций
Если у вас есть большой набор данных для аннотирования, мы рекомендуем использовать APOC:
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
Важно сохранить варианты batchSize и iterateList , как упомянуто в примере. Запуск процедуры аннотации в параллельной форме создаст тупики.
Мы реализуем внешние базы знаний, чтобы обогатить знания ваших текущих данных.
На данный момент доступны две реализации:
Этот обогачик расширит значение токенов (узлов тегов) на графике.
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
Доступные параметры (значения по умолчанию находятся в скобках):
tag : тег для обогащенияenricher ( "conceptnet5" ): выберите microsoft или conceptnet5depth ( 2 ): как глубоко идти в иерархию концепцииadmittedRelationships : выберите желаемые типы концептуальных отношений, пожалуйста, обратитесь к документации ConceptNet для получения подробной информацииpipeline : выберите название трубопровода, которое будет использоваться для очистки концепций, прежде чем хранить их в своем БД; Ваша система по умолчанию используется иначеfilterByLanguage ( true ): Разрешить только концепции языков, указанных в outputLanguages ; Если не указаны языки, требуется тот же язык, что и tagoutputLanguages ( [] ): вернуть только концепции с указанными языкамиrelDirection ( "out" ): желаемое направление отношений в концептуальной иерархии ( "in" , "out" , "both" )minWeight ( 0.0 ): минимальный допустимый вес концепции отношенийlimit ( 10 ): максимальное количество понятий на tagsplitTag ( false ): если true , tag сначала токенизирован, а затем индивидуальные токены обогащены Теги теперь имеют отношения IS_RELATED_TO с другими обогащенными понятиями.
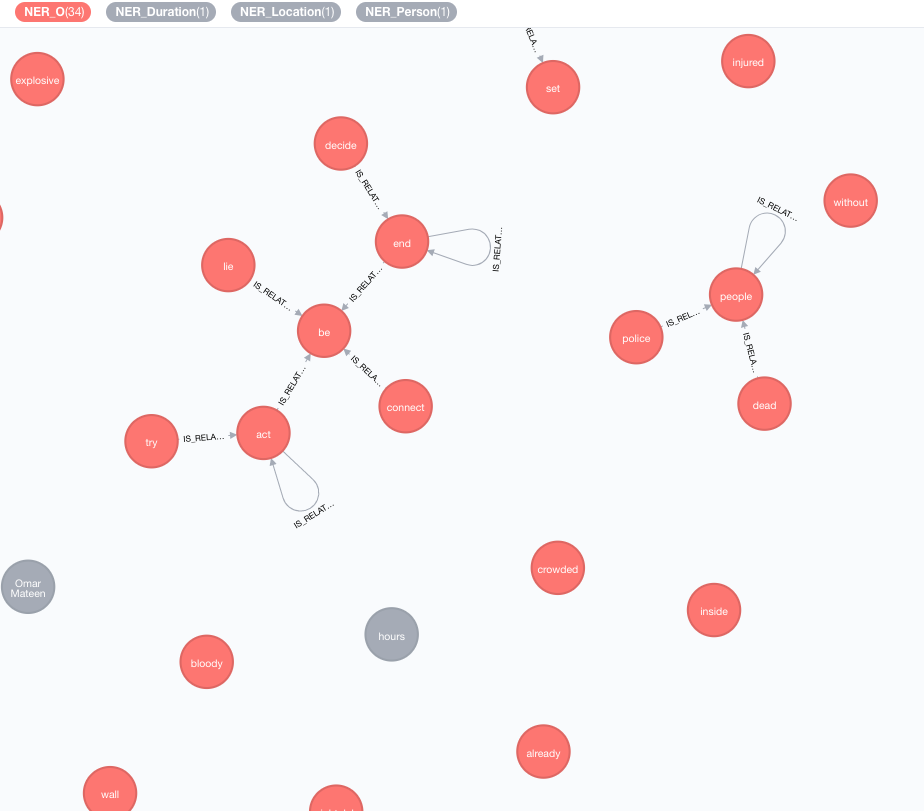
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText - это обязательный параметр, который относится к аннотированному документу, который должен быть проанализирован.
Доступны дополнительные параметры (значения по умолчанию находятся в скобках):
keywordLabel (Keyword): Имя метки узлов ключевых словuseDependencies (TRUE): Используйте универсальные зависимости для обогащения извлеченных ключевых слов и ключевых фраз с помощью тегов, связанных с составными и амодными отношениямиdependenciesGraph (false): используйте универсальные зависимости для создания графика совместного появления тегов (по умолчанию является ложным, что означает, что природный поток используется для строительства совместных веществ)cleanKeywords (True): Процедура чистки запускаtopXTags (1/3): установите долю тегов с наибольшим рейтингом, которые будут использоваться в качестве ключевых слов / ключевых фразrespectSentences (false): Уважение или не границы предложения для здания графика совместного поступленияrespectDirections (false): Уважение или не направления на графике совместного появления (как слова следуют друг за другом)iterations (30): количество итераций PageRankdamp (0,85): коэффициент демпфирования PageRankthreshold (0,0001): порог конвергенции PageRankremoveStopwords (true): используйте список стоп-слов для строительства графа совместного вещества и окончательной очистки ключевых словstopwords : Настройка списка стоп -слов (если список начинается с + , следующие слова добавляются в список стоп -слов по умолчанию, в противном случае список по умолчанию перезаписан)admittedPOSs : укажите, какие POS -метки считаются кандидатами на ключевые слова; необходимо при использовании другого языка, чем английскийforbiddenPOSs : укажите список POS-метков, которые будут игнорироваться при построении графа совместного появления; необходимо при использовании другого языка, чем английскийforbiddenNEs : укажите список NES, которые следует игнорировать Для получения подробного описания алгоритма TextRank , пожалуйста, обратитесь к нашему сообщению в блоге о извлечении ключевых слов без присмотра.
Использование универсальных зависимостей для обогащения ключевых слов (опция useDependencies ) может привести к ключевым словам с ненужным уровнем детализации, например, программа логистики космического трансфера ключевых слов. Во многих вариантах использования нам может быть интересно также знать, что данное документ говорит о коммунальном шаттле (или логистической программе ). Для этого запустите пост-обработку с одним из этих вариантов:
direct - каждая ключевая фраза N Количество тегов проверяется на всех ключевых фразах из всех документов с 1 <M <N Количеством тегов; Если первая содержит последнюю ключевую фразу, то A DESCRIBES отношения из M -KeyPhrase для всех аннотированных текстов N -KeyPhrasesubgroups - та же самая процедура, что и для direct , но вместо того, чтобы подключать ключевые слова более высокого уровня непосредственно с аннотированныминексами , они подключены к ключевым словам нижнего уровня с отношениями HAS_SUBGROUP // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel - это необязательный аргумент, установленной по умолчанию в «Ключевое слово» .
Операция постпроцесса по умолчанию обрабатывает все ключевые слова, которые могут быть очень тяжелыми на больших графиках. Вы можете указать аннотированный текст для применения операции постпроцесса с аргументом annotatedText :
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
Пример для эффективного запуска его в полном наборе ключевых слов с APOC:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
Аналогичный подход к извлечению ключевых слов может быть использован для реализации простой суммирования. Создается плотно подключенный график предложений, с отношениями с изначальными предложениями, представляющими их сходство, основанные на общих словах (количество общих слов против суммы логарифмов количества слов в предложении). Затем PageRank используется в качестве меры центральности для оценки относительной важности предложений в документе.
Чтобы запустить этот алгоритм:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
Доступные параметры:
annotatedTextiterations (30): количество итераций PageRankdamp (0,85): коэффициент демпфирования PageRankthreshold (0,0001): порог конвергенции PageRank Процедура суммирования сохраняет новые свойства в узлах предложения: summaryRelevance (значение PAGERANK данного предложения) и summaryRank (рейтинг; 1 = предложение с наибольшим ранжированным предложением). Пример запроса для получения резюме:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
Вы также можете определить, является ли представленный текст положительным, отрицательным или нейтральным. Эта процедура требует аннотированного текстового узла, который создается ga.nlp.annotate выше.
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
Эта процедура просто вернет «успех», когда она будет успешной, но она применит :POSITIVE :NEUTRAL или :NEGATIVE метка для каждого предложения. В результате, когда обнаружение настроений завершено, вы можете запросить настроение предложений как таковые:
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
Как только теги извлекаются из всех новостей или других узлов, содержащих некоторый текст, можно вычислить сходство между ними, используя сходство на основе контента. Во время этого процесса каждый аннотированный текст описывается с использованием формата кодирования TF-IDF. TF-IDF является установленным методом из области поиска информации и обозначает частоту с частотой негативной документы. Текстовые документы могут быть закодированы в виде векторов в многомерном евклидовом пространстве. Размеры пространства соответствуют тегам, ранее извлеченным из документов. Координаты данного документа в каждом измерении (то есть для каждого тега) рассчитываются как произведение двух подразделений: частота термина и обратная частота документов.
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
Доступные параметры (значения по умолчанию находятся в скобках):
input : Список входных узлов - AnnotatedTextsrelationshipType (seganity_cosine): тип взаимосвязи сходства, используйте его вместе с queryquery : Укажите свой собственный запрос для извлечения TF и IDF в форме ... RETURN id(Tag), tf, idfpropertyName (значение): имя существующего свойства узла (массив численных значений), которое содержит уже подготовленный вектор документовWord2VEC-это неглубокая двухслойная модель нейронной сети, используемая для производства встраиваний Word (слова, представленные в качестве многомерных семантических векторов), и это одна из моделей, используемых в Becondet NumberBatch.
Чтобы добавить исходную модель (векторы) в индекс Lucene
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir> - полный путь к каталогу с источниками, которые должны быть индексированы<path_to_index> - полный путь, в котором будет сохранен индекс<identifier> - это индивидуальная строка, которая уникально идентифицирует модельЧтобы перечислить доступные модели:
CALL ga.nlp.ml.word2vec.listModels
Теперь модель можно использовать для вычисления сходства косинуса между словами:
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
Или вы можете попросить напрямую Word2VEC узла, в котором хранится слово в value свойства:
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
Мы также можем постоянно хранить векторы Word2VEC для пометок узлов:
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query : запрос, который возвращает теги, к которым следует прикреплять встраивающие векторыmodelName : модель для использованияВы также можете получить ближайших соседей со следующей процедурой:
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
Для больших моделей, например, полный быстрый текст для английского, приблизительно 2 миллиона слов, будет неэффективно вычислять ближайших соседей на лету.
Вы можете загрузить модель в память, чтобы иметь более быстрых ближайших соседей (векторы слов FASTTEXT 1M обычно занимают 27 секунд, если это необходимо для чтения с диска, ~ 300 мс в памяти):
Убедитесь, что у вас есть эффективная память кучи, посвященная NEO4J:
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
Загрузите модель в память:
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
И получить это с
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
Вы можете использовать любую модель встраивания слов, если следующее является правдой:
.txt Например, вы можете загрузить модели с FastText и просто переименовать файл с .vec до .txt : https://fastext.cc/docs/en/english-vectors.html
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
Процедура возвращает строки с number столбцов, являющимся номером страницы, а paragraphs являются List<String> текстами абзаца.
Вы также можете передать URL -адрес http или https в процедуру загрузки файла из удаленного места.
В некоторых случаях документы в PDF имеют некоторое повторное бесполезное содержание, например, нижние колонтитулы страниц и т. Д., Вы можете исключить их из разбора, пропустив список регулярных лиц, определяющих детали, чтобы исключить:
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
Tika может быть признана хрупкой и быть отказано в доступе к некоторым сайтам, содержащим PDF. Вы можете переопределить это, передавая опцию UserAgent :
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
В определенных ситуациях было бы полезно хранить только определенные значения вместо полного графика, обратите внимание, что это может уменьшить способность извлекать Insights (Textrank), например:
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
WebVtt - это формат для веб -текстовых треков, таких как транскрипты YouTube видео: https://fr.wikipedia.org/wiki/webvtt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Приведенные выше файлы списка процедур только текущего каталога, если вам также нужно пройти и gother -каталоги, используйте walkdir :
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Список хранимых моделей и их пути
Удалить и воссоздать трубопровод с той же конфигурацией (полезно при использовании статических файлов NER, которые были изменены для EG)
Copyright (C) 2013-2019 Graphaware
GraphAware - это бесплатное программное обеспечение: вы можете перераспределить его и/или изменить его в соответствии с условиями общей публичной лицензии GNU, опубликованных Фондом Free Software, либо версией 3 лицензии, либо (по варианту) любой более поздней версии. Эта программа распространяется в надежде, что она будет полезна, но без каких -либо гарантий; даже без подразумеваемой гарантии торговой точки зрения или пригодности для определенной цели. Смотрите общую публичную лицензию GNU для получения более подробной информации. Вы должны были получить копию общей публичной лицензии GNU вместе с этой программой. Если нет, см. Http://www.gnu.org/licenses/.


