neo4j nlp
1.0.0
En mai 2021, ce référentiel a été retiré.
Ce plugin NEO4J propose des capacités de traitement du langage naturel basées sur des graphiques.
Le module principal, ce module, fournit une interface commune pour les processeurs de texte sous-jacents ainsi qu'un langage spécifique au domaine construit au sommet des procédures et des fonctions stockées, ce qui rend votre développeur de workflow de travail de traitement du langage naturel.
Il est disponible en 2 versions, communauté (open source) et entreprise avec les fonctionnalités NLP suivantes:
| Édition communautaire | Edition d'entreprise | |
|---|---|---|
| Extraction d'informations sur le texte | ✔ | ✔ |
| Multi-langages dans la même base de données | ✔ | |
| Custom NamedentityRecognition Model Builder | ✔ | |
| ConceptNet5 Enricher | ✔ | ✔ |
| Microsoft Concept Enricher | ✔ | ✔ |
| Extraction de mots clés | ✔ | ✔ |
| Résumé de Textrank | ✔ | ✔ |
| Extraction des sujets | ✔ | |
| Word Embeddings (Word2Vec) | ✔ | ✔ |
| Calcul de similitude | ✔ | ✔ |
| PDF Analyse | ✔ | ✔ |
| Apache Spark Binding pour les algorithmes distribués | ✔ | |
| Implémentation DOC2VEC | ✔ | |
| Interface utilisateur | ✔ | |
| Capacités de prédiction ML | ✔ | |
| Fusion d'entité | ✔ |
Deux implémentations de processeurs NLP sont disponibles, respectivement Stanford NLP et OpenNLP (OpenNLP reçoit des mises à jour moins fréquentes, StanfordNLP est recommandé).
À partir de la version 3.5.1.53.15, vous devez télécharger les modèles de langue, voir ci-dessous
Dans le répertoire des plugins Graphaware, téléchargez les fichiers jar suivants:
neo4j-framework (le pot est étiqueté "Graphaware-Server-Entrise-All")neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download et copiez-les dans le répertoire plugins de Neo4j.
Faites attention que les numéros de version du cadre que vous utilisez correspondent à la version de Neo4j que vous utilisez . Il s'agit d'un problème de configuration commun. Par exemple, si vous utilisez Neo4j 3.4.0 et supérieur, tous les pots que vous téléchargez doivent contenir 3,4 dans leur numéro de version.
plugins/ Exemple du répertoire:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
Ajoutez la configuration suivante dans le fichier neo4j.conf dans le répertoire config/ :
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
Démarrez ou redémarrez votre base de données NEO4J.
Remarque: Les deux processeurs de texte en béton sont assez gourmands - vous devrez consacrer une mémoire suffisante à l'espace de tas Neo4j.
De plus, les index et contraintes suivants sont suggérés pour accélérer les performances:
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
Ou utilisez la procédure dédiée:
CALL ga.nlp.createSchema()
Définissez la langue que vous utiliserez dans cette base de données:
CALL ga.nlp.config.setDefaultLanguage('en')
Une fois l'extension chargée, vous pouvez voir la documentation de base sur toutes les procédures disponibles en exécutant cette requête Cypher:
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
La phase d'extraction de texte se fait avec un pipeline de traitement du langage naturel, chaque pipeline a une liste de composants activés.
Par exemple, le pipeline tokenizer de base a les composants suivants:
Il est obligatoire de créer d'abord votre pipeline:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
Les paramètres optionnels disponibles (les valeurs par défaut sont entre parenthèses):
name : nom souhaité d'un nouveau pipelinetextProcessor : auquel le processeur de texte doit être ajouté le nouveau pipelineprocessingSteps : Configuration du pipeline (disponible dans Stanford et OpenNLP sauf indication contraire)tokenize (par défaut: true): effectuer la tokenisationner (par défaut: true): reconnaissance de l'entité nomméesentiment (par défaut: false): exécutez l'analyse du sentiment sur les phrasescoref (par défaut: false): Résolution de la coreférence (identifier plusieurs mentions de la même entité, telles que "Barack Obama" et "He")relations (par défaut: false): exécuter l'identification des relations entre deux jetonsdependency (par défaut: false, stanfordnlp uniquement): extraire les dépendances typées (Ex.: Modificateur adjectif AMOD, conjonctif, ...)cleanxml (par défaut: faux, stanfordnlp uniquement): supprimer les balises XMLtruecase (par défaut: False, Stanfordnlp uniquement): reconnaît le "vrai" cas de jetons (comment ils seraient capitalisés dans un texte bien édité)customNER : Liste des identificateurs de modèle NER personnalisés (en tant que chaîne, identifiants de modèle séparés par «»)stopWords : Spécifiez les mots qui doivent être ignorés (si la liste commence par +, les mots suivants sont annexés à la liste des mots d'arrêt par défaut, sinon la liste par défaut est écrasée)threadNumber (par défaut: 4): pour le multi-threadingexcludedNER : (par défaut: aucun) Spécifiez une liste de NE à ne pas être reconnue dans le haut du cas, par exemple pour exclure NER_Money et NER_O sur les nœuds de balise, utilisez ['o', 'Money']Pour définir un pipeline comme pipeline par défaut:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
Pour supprimer un pipeline, utilisez cette commande:
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
Pour voir les détails de tous les pipelines existants:
CALL ga.nlp.processor.getPipelines()
Prenons le texte suivant comme exemple:
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
Simulez votre corpus d'origine
Créez un nœud avec le texte, ce nœud représentera votre corpus ou graphique de connaissances d'origine:
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
Effectuer l'extraction d'informations de texte
L'extraction se fait via la procédure annotate qui est le point d'entrée à l'extraction des informations texte
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
Paramètres disponibles de la procédure annotate :
text : texte à annoter représenté comme une chaîneid : Spécifiez l'ID qui sera utilisé comme propriété id du nouveau nœud annottextProcessor (par défaut: "Stanford", sinon disponible que la première entrée dans la liste des processeurs de texte disponibles)pipeline (par défaut: tokenizer)checkLanguage (par défaut: true): exécutez la détection de la langue sur le texte fourni et vérifiez s'il est pris en charge Cette procédure reliera votre nœud original :News à un nœud :AnnotatedText qui est le point d'entrée du PNL basé sur le graphique de cette nouvelle particulière. Le texte d'origine est décomposé en mots, parties de la parole et fonctions. Cette analyse du texte agit comme un point de départ pour les étapes ultérieures.
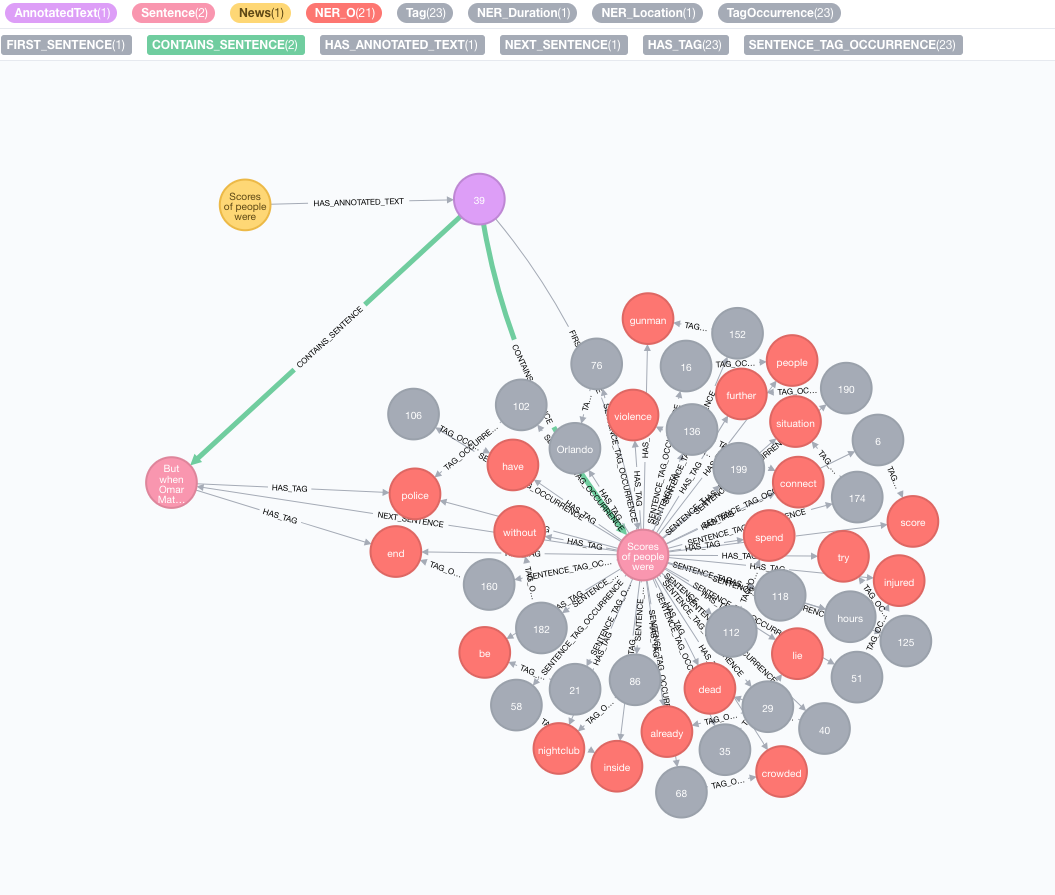
Exécuter un lot d'annotations
Si vous avez un grand ensemble de données pour annoter, nous vous recommandons d'utiliser APOC:
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
Il est important de conserver les options batchSize et iterateList comme mentionné dans l'exemple. L'exécution de la procédure d'annotation en parallèle créera des impasses.
Nous mettons en œuvre des bases de connaissances externes afin d'enrichir les connaissances de vos données actuelles.
À ce jour, deux implémentations sont disponibles:
Cet enricher étendra la signification des jetons (nœuds de balise) dans le graphique.
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
Les paramètres disponibles (les valeurs par défaut sont entre parenthèses):
tag : tag à enrichirenricher ( "conceptnet5" ): Choisissez microsoft ou conceptnet5depth ( 2 ): Quelle est la profondeur de la hiérarchie du conceptadmittedRelationshipspipeline : Choisissez le nom du pipeline à utiliser pour le nettoyage des concepts avant de les stocker à votre base de données; Le pipeline par défaut de votre système est utilisé autrementfilterByLanguage ( true ): autoriser uniquement les concepts de langues spécifiées dans outputLanguages ; Si aucune langue n'est spécifiée, la même langue que tag est requiseoutputLanguages ( [] ): Renvoyez uniquement les concepts avec des langues spécifiéesrelDirection ( "out" ): direction souhaitée des relations dans la hiérarchie des concepts ( "in" , "out" , "both" )minWeight ( 0.0 ): Minimal Admis Concept Relation Weightlimit ( 10 ): nombre maximal de concepts par tagsplitTag ( false ): Si true , tag est d'abord tokenisée, puis des jetons individuels enrichis Les balises ont désormais des relations IS_RELATED_TO avec d'autres concepts enrichis.
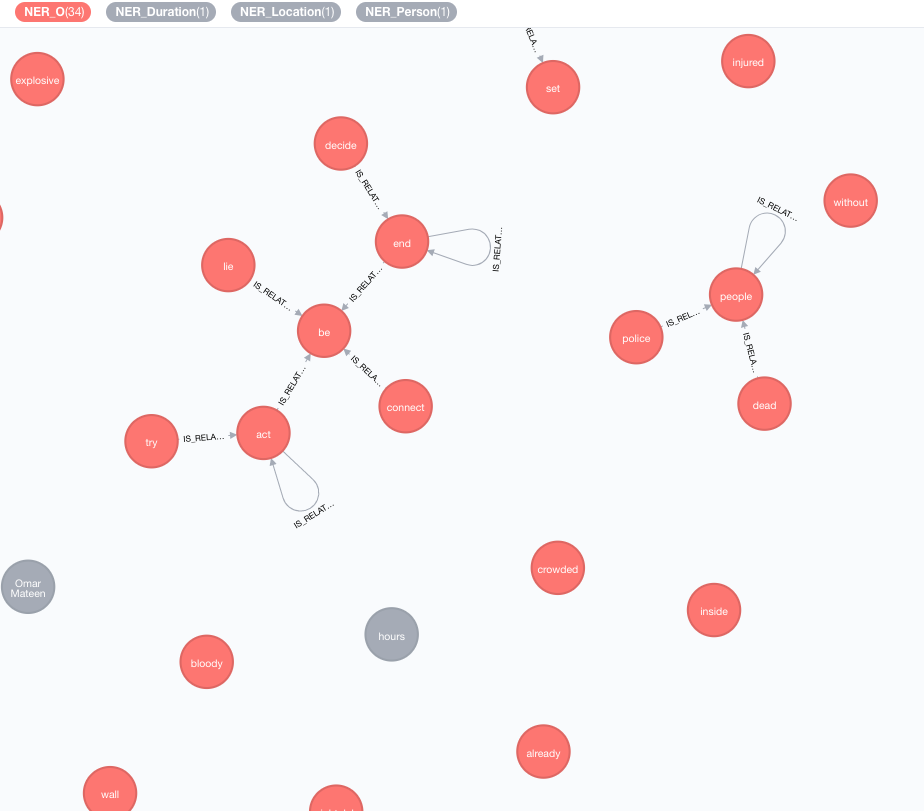
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText est un paramètre obligatoire qui fait référence au document annoté qui doit être analysé.
Paramètres facultatifs disponibles (les valeurs par défaut sont entre parenthèses):
keywordLabel (mot-clé): nom d'étiquette des nœuds de mots clésuseDependencies (vrai): utilisez des dépendances universelles pour enrichir les mots clés extraits et les phrases clés par des balises liées à des relations composées et AMODdependenciesGraph (false): utilisez des dépendances universelles pour créer un graphique de cooccurrence de balise (la valeur par défaut est fausse, ce qui signifie qu'un flux de mots naturel est utilisé pour construire des cooccurrences)cleanKeywords (true): Exécutez la procédure de nettoyagetopXTags (1/3): définissez une fraction des balises les mieux notées qui seront utilisées comme mots clés / phrases clésrespectSentences (FAUX): Respect ou non les limites des phrases pour la construction de graphiques de cooccurrencerespectDirections (False): Respect ou non des instructions dans le graphique de cooccurrence (comment les mots se suivent)iterations (30): nombre d'itérations de pagerankdamp (0,85): facteur d'amortissement du pagerankthreshold (0,0001): seuil de convergence de pagerankremoveStopwords (VRAI): Utilisez une liste de mots arrêtés pour la construction de graphiques cooccurrence et le nettoyage final des mots clésstopwords : Personnaliser la liste des mots arrêtés (si la liste commence par + , les mots suivants sont annexés à la liste des mots d'arrêt par défaut, sinon la liste par défaut est écrasée)admittedPOSs : Spécifiez les étiquettes POS considérées comme des candidats de mots clés; nécessaire lorsque vous utilisez une langue différente de l'anglaisforbiddenPOSs : spécifiez la liste des étiquettes POS à ignorer lors de la construction du graphique de cooccurrence; nécessaire lorsque vous utilisez une langue différente de l'anglaisforbiddenNEs : spécifiez la liste des NES à ignorer Pour une description détaillée de l'algorithme TextRank , veuillez vous référer à notre article de blog sur l'extraction de mots clés non supervisée.
L'utilisation de dépendances universelles pour l'enrichissement des mots clés (option useDependencies ) peut entraîner des mots clés avec un niveau de détail inutile, par exemple un programme de logistique de navette spatiale de mots clés. Dans de nombreux cas d'utilisation, nous pourrions être intéressés à savoir que le document donné parle généralement de la navette spatiale (ou du programme logistique ). Pour ce faire, exécutez le post-traitement avec l'une de ces options:
direct - Chaque phrase clé de n nombre de balises est vérifiée par rapport à toutes les phrases clés de tous les documents avec 1 <m <n nombre de balises; Si le premier contient la dernière phrase clé, alors une relation DESCRIBES est créée à partir de la M -KeyPhrase à tous les textes annotés de la N -KeyPhrasesubgroups - La même procédure que pour direct , mais au lieu de connecter les mots clés de niveau supérieur directement aux textes annotés , ils sont connectés aux mots clés de niveau inférieur avec les relations HAS_SUBGROUP // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel est un argument facultatif défini par défaut sur "Mot-clé" .
L'opération post-traitement par défaut est le traitement de tous les mots clés, qui peuvent être très lourds sur les gros graphiques. Vous pouvez spécifier le texte annoté sur lequel appliquer l'opération de post-processus avec l'argument annotatedText :
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
Exemple pour l'exécuter efficacement sur l'ensemble complet de mots clés avec APOC:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
Une approche similaire à l'extraction de mots clés peut être utilisée pour implémenter une résumé simple. Un graphique densément connecté des phrases est créé, avec des relations de phrase-phrase représentant leur similitude en fonction des mots partagés (nombre de mots partagés vs somme de logarithmes de nombre de mots dans une phrase). PageRank est ensuite utilisé comme mesure de centralité pour classer l'importance relative des phrases dans le document.
Pour exécuter cet algorithme:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
Paramètres disponibles:
annotatedTextiterations (30): nombre d'itérations de pagerankdamp (0,85): facteur d'amortissement du pagerankthreshold (0,0001): seuil de convergence de pagerank La procédure de résumé économise de nouvelles propriétés aux nœuds de phrase: summaryRelevance (valeur de pagerank de la phrase donnée) et summaryRank (classement; 1 = phrase la plus élevée). Exemple de requête pour récupérer le résumé:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
Vous pouvez également déterminer si le texte présenté est positif, négatif ou neutre. Cette procédure nécessite un nœud AnnotatedText, qui est produit par ga.nlp.annotate ci-dessus.
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
Cette procédure rendra simplement le «succès» lorsqu'elle réussit, mais elle appliquera :POSITIVE , :NEUTRAL ou :NEGATIVE à chaque phrase. En conséquence, lorsque la détection des sentiments est terminée, vous pouvez interroger le sentiment des phrases en tant que telles:
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
Une fois que les balises sont extraites de toutes les nouvelles ou d'autres nœuds contenant du texte, il est possible de calculer des similitudes entre eux en utilisant la similitude basée sur le contenu. Au cours de ce processus, chaque texte annoté est décrit à l'aide du format de codage TF-IDF. TF-IDF est une technique établie à partir du domaine de la récupération de l'information et signifie la fréquence des documents envers la fréquence des termes. Les documents texte peuvent être codés en TF-IDF en tant que vecteurs dans un espace euclidien multidimensionnel. Les dimensions de l'espace correspondent aux balises, précédemment extraites des documents. Les coordonnées d'un document donné dans chaque dimension (c'est-à-dire pour chaque étiquette) sont calculées comme un produit de deux sous-mesures: fréquence à terme et fréquence de document inverse.
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
Paramètres disponibles (les valeurs par défaut sont entre parenthèses):
input : liste des nœuds d'entrée - Texts annotésrelationshipType (Simility_cosine): Type de similitude Relation, utilisez-le avec queryquery : spécifiez votre propre requête pour extraire TF et IDF dans le formulaire ... RETURN id(Tag), tf, idfpropertyName (valeur): nom d'une propriété de nœud existante (tableau de valeurs numériques) qui contient un vecteur de document déjà préparéWord2VEC est un modèle de réseau neuronal à deux couches peu profond utilisé pour produire des intégres de mots (mots représentés comme vecteurs sémantiques multidimensionnels) et il est l'un des modèles utilisés dans ConceptNet Numberbatch.
Pour ajouter un modèle source (vecteurs) dans un index lucene
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir> est un chemin complet vers le répertoire avec des vecteurs source à indexer<path_to_index> est un chemin complet où l'index sera stocké<identifier> est une chaîne personnalisée qui identifie uniquement le modèlePour énumérer les modèles disponibles:
CALL ga.nlp.ml.word2vec.listModels
Le modèle peut désormais être utilisé pour calculer les similitudes en cosinus entre les mots:
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
Ou vous pouvez demander directement un word2vec d'un nœud qui a un mot stocké dans value de la propriété:
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
Nous pouvons également stocker en permanence les vecteurs Word2Vec sur les nœuds de balise:
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query : requête qui renvoie des étiquettes auxquelles des vecteurs d'intégration doivent être jointsmodelName : modèle à utiliserVous pouvez également obtenir les voisins les plus proches avec la procédure suivante:
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
Pour les grands modèles, par exemple un texte rapide complet pour l'anglais, environ 2 millions de mots, il sera inefficace de calculer les voisins les plus proches à la volée.
Vous pouvez charger le modèle en mémoire afin d'avoir des voisins les plus proches plus rapides (les vecteurs de mot de 1M FastText prennent généralement 27 secondes si nécessaire pour lire à partir du disque, ~ 300 ms en mémoire):
Assurez-vous d'avoir une mémoire de tas efficace dédiée à NEO4J:
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
Chargez le modèle en mémoire:
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
Et le récupérer avec
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
Vous pouvez utiliser n'importe quel modèle d'incorporation de mots tant que ce qui suit est vrai:
.txt Par exemple, vous pouvez charger les modèles à partir de FastText et renommer simplement le fichier de .vec à .txt : https://fasttext.cc/docs/en/english-vectors.html
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
La procédure renvoie les lignes avec number de colonnes étant le numéro de page et paragraphs étant une List<String> des textes de paragraphe.
Vous pouvez également transmettre une URL http ou https à la procédure de chargement d'un fichier à partir d'un emplacement distant.
Dans certains cas, les documents PDF ont un contenu récurrent inutile comme les pieds de page, etc., vous pouvez les exclure de l'analyse en passant une liste de regents définissant les pièces à exclure:
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
Tika peut être reconnue comme robot et se voir refuser l'accès à certains sites contenant des PDF. Vous pouvez remplacer cela en passant une option UserAgent :
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
Dans certaines situations, il serait utile de stocker uniquement certaines valeurs au lieu du graphique complet, notez que cela pourrait réduire la capacité d'extraire des informations (Textrank) pour EG:
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
WebVTT est le format pour les pistes de texte vidéo Web, telles que les transcriptions YouTube de vidéos: https://fr.wikipedia.org/wiki/webvttt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Les fichiers de procédure ci-dessus de la répertoire actuel uniquement, si vous devez également parcourir les répertoires pour enfants, utilisez walkdir :
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Liste des modèles stockés et leurs chemins
Supprimer et recréer un pipeline avec la même configuration (utile lorsque vous utilisez des fichiers NER statiques qui ont été modifiés pour EG)
Copyright (c) 2013-2019 Graphaware
Graphaware est un logiciel gratuit: vous pouvez le redistribuer et / ou le modifier en vertu des termes de la licence GNU General Public publiée par la Free Software Foundation, soit la version 3 de la licence, soit (à votre option) n'importe quelle version ultérieure. Ce programme est distribué dans l'espoir qu'il sera utile, mais sans aucune garantie; Sans même la garantie implicite de qualité marchande ou d'adéquation à un usage particulier. Voir la licence publique générale GNU pour plus de détails. Vous devriez avoir reçu une copie de la licence publique générale GNU avec ce programme. Sinon, voir http://www.gnu.org/licenses/.


