neo4j nlp
1.0.0
اعتبارا من مايو 2021 ، تم تقاعد هذا المستودع.
يوفر المكون الإضافي NEO4J إمكانات معالجة اللغة الطبيعية القائمة على الرسم البياني.
توفر الوحدة الرئيسية ، هذه الوحدة ، واجهة مشتركة لمعالجات النصوص الأساسية بالإضافة إلى لغة محددة للمجال تم إنشاؤها على قمة الإجراءات المخزنة والوظائف التي تجعل مطور سير العمل الطبيعي لتجهيز اللغة.
إنه يأتي في نسختين ، المجتمع (مفتوح المصدر) والمؤسسة مع ميزات NLP التالية:
| طبعة المجتمع | Enterprise Edition | |
|---|---|---|
| استخراج معلومات النص | ✔ | ✔ |
| متعددة اللغات في نفس قاعدة البيانات | ✔ | |
| مخصص المسماة بنموذج النموذج | ✔ | |
| ConceptNet5 المضيء | ✔ | ✔ |
| Microsoft Concept Triricher | ✔ | ✔ |
| استخراج الكلمات الرئيسية | ✔ | ✔ |
| تلخيص Textrank | ✔ | ✔ |
| استخراج الموضوعات | ✔ | |
| تضمينات الكلمات (Word2Vec) | ✔ | ✔ |
| حساب التشابه | ✔ | ✔ |
| PDF تحليل | ✔ | ✔ |
| ارتباط أبلشي شرارة الخوارزميات الموزعة | ✔ | |
| تنفيذ DOC2VEC | ✔ | |
| واجهة المستخدم | ✔ | |
| ML قدرات التنبؤ | ✔ | |
| دمج الكيان | ✔ |
تتوفر تطبيقان معالج NLP ، على التوالي Stanford NLP و OpenNLP (يتلقى OpenNLP تحديثات أقل تكرارًا ، يوصى بـ Stanfordnlp).
من الإصدار 3.5.1.53.15 ، تحتاج إلى تنزيل نماذج اللغة ، انظر أدناه
من دليل GraphAware Plugins ، قم بتنزيل ملفات jar التالية:
neo4j-framework (الجرة لهذا المسمى "Graphaware-Server-Enterprise-All")neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download ونسخها في دليل plugins من Neo4J.
احرص على أن أرقام الإصدار من الإطار الذي تستخدمه مطابقة مع إصدار Neo4J الذي تستخدمه . هذه مشكلة الإعداد الشائعة. على سبيل المثال ، إذا كنت تستخدم Neo4J 3.4.0 وما فوق ، يجب أن تحتوي جميع الجرار التي تنزيلها على 3.4 في رقم الإصدار.
مثال plugins/ الدليل:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
قم بإلحاق التكوين التالي في ملف neo4j.conf في config/ الدليل:
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
ابدأ أو أعد تشغيل قاعدة بيانات NEO4J الخاصة بك.
ملاحظة: كل من معالجات النصوص الملموسة جشعون تمامًا - ستحتاج إلى تكريس ذاكرة كافية لفضاء كومة Neo4J.
بالإضافة إلى ذلك ، يُقترح أن تسرع الفهارس والقيود التالية:
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
أو استخدم الإجراء المخصص:
CALL ga.nlp.createSchema()
حدد اللغة التي ستستخدمها في قاعدة البيانات هذه:
CALL ga.nlp.config.setDefaultLanguage('en')
بمجرد تحميل الامتداد ، يمكنك رؤية الوثائق الأساسية حول جميع الإجراءات المتاحة عن طريق تشغيل استعلام Cypher هذا:
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
تتم مرحلة استخراج النص مع خط أنابيب معالجة اللغة الطبيعية ، يحتوي كل خط أنابيب على قائمة بالمكونات الممكّنة.
على سبيل المثال ، يحتوي خط أنابيب tokenizer الأساسي على المكونات التالية:
من الضروري إنشاء خط أنابيبك أولاً:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
المعلمات الاختيارية المتاحة (القيم الافتراضية في قوسين):
name : الاسم المطلوب لخط أنابيب جديدtextProcessor : إلى أي معالج النص يجب إضافة خط الأنابيب الجديدprocessingSteps : تكوين خطوط الأنابيب (متوفر في كل من Stanford و OpenNLP ما لم ينص على خلاف ذلك)tokenize (الافتراضي: صواب): قم بإجراء رمز رمزيner (افتراضي: صواب): التعرف على الكيان المسماةsentiment (الافتراضي: خطأ): تشغيل تحليل المشاعر على الجملcoref (افتراضي: خطأ): قرار Coreference (حدد إشارات متعددة لنفس الكيان ، مثل "Barack Obama" و "He")relations (الافتراضي: خطأ): قم بتشغيل تحديد العلاقات بين اثنين من الرموز الرموزdependency (الافتراضي: خطأ ، Stanfordnlp فقط): استخراج التبعيات المكتوبة (على سبيل المثال: Amod - معدّل صفة ، Concl -conval ، ...)cleanxml (افتراضي: false ، stanfordnlp فقط): إزالة علامات XMLtruecase (الافتراضي: خطأ ، Stanfordnlp فقط): يتعرف على حالة "True" للرموز (كيف سيتم ترحيلها في نص جيد)customNER : قائمة معرفات نموذج NER المخصصة (كسلسلة ، معرفات النموذج مفصولة بـ "،")stopWords : حدد الكلمات المطلوبة لتجاهلها (إذا بدأت القائمة بـ +، يتم إلحاق الكلمات التالية بقائمة Stopwords الافتراضية ، وإلا فإن القائمة الافتراضية مبتكرة)threadNumber (افتراضي: 4): لمادة الخيوط المتعددةexcludedNER : (افتراضي: لا شيء) حدد قائمة من NE بعدم الاعتراف بها في الحالة العليا ، على سبيل المثال لاستبعاد NER_Money و NER_O على عقد العلامات ، استخدم ["O" ، "المال"]لتعيين خط أنابيب كخط أنابيب افتراضي:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
لحذف خط أنابيب ، استخدم هذا الأمر:
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
لمعرفة تفاصيل جميع خطوط الأنابيب الحالية:
CALL ga.nlp.processor.getPipelines()
لنأخذ النص التالي كمثال:
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
محاكاة مجموعتك الأصلية
قم بإنشاء عقدة مع النص ، فإن هذه العقدة ستمثل المجموعة الأصلية أو الرسم البياني للمعرفة:
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
تنفيذ استخراج معلومات النص
يتم الاستخراج من خلال إجراء annotate وهو نقطة الدخول لاستخراج معلومات النص
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
المعلمات المتاحة لإجراءات annotate :
text : رسالة نصية إلى التعليقات التعليق ممثلة كسلسلةid : حدد المعرف الذي سيتم استخدامه كخاصية id لعقدة annotatedtext الجديدةtextProcessor (الافتراضي: "ستانفورد" ، إن لم يكن متوفرًا من الإدخال الأول في قائمة معالجات النصوص المتاحة)pipeline (افتراضي: Tokenizer)checkLanguage (الافتراضي: صواب): قم بتشغيل الكشف عن اللغة على النص المقدم وتحقق مما إذا كان مدعومًا سوف يربط هذا الإجراء الأصلي الخاص بك :News إلى AN :AnnotatedText NODE والتي هي نقطة الدخول لـ NLP المستند إلى الرسم البياني لهذا الأخبار بالذات. يتم تقسيم النص الأصلي إلى كلمات وأجزاء من الكلام والوظائف. يعمل هذا التحليل للنص كنقطة انطلاق للخطوات اللاحقة.
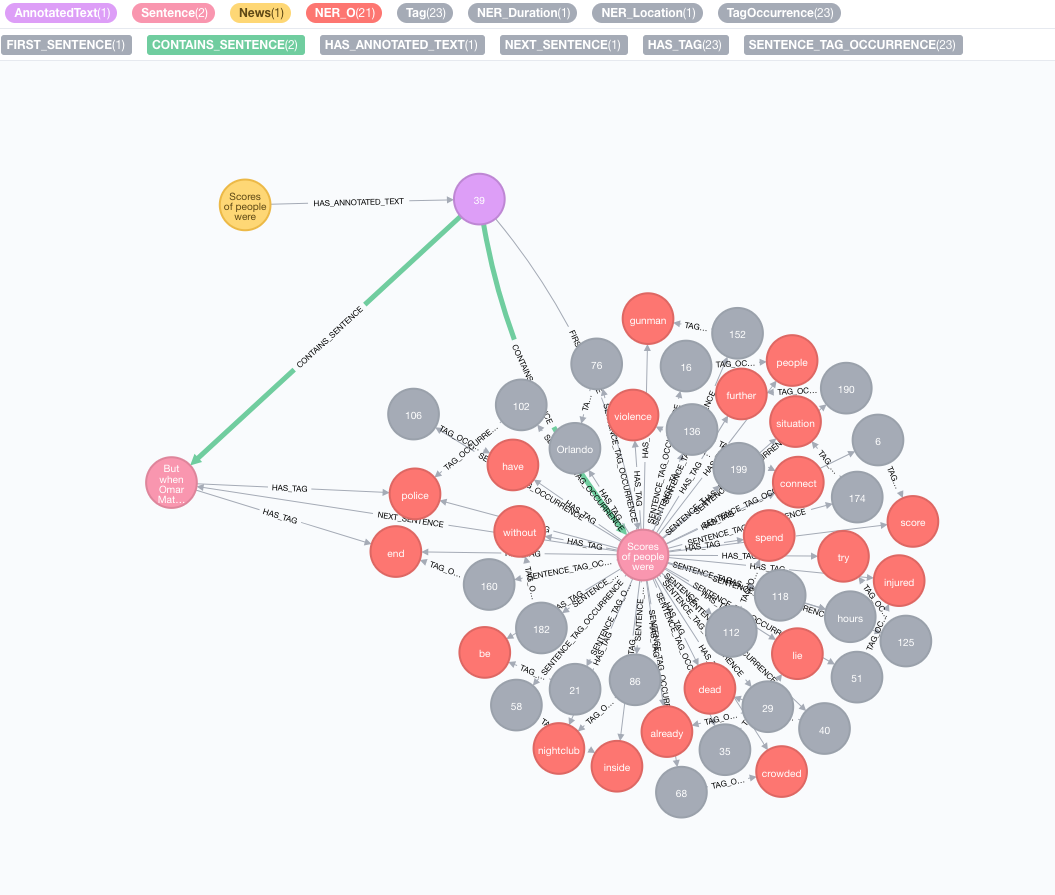
تشغيل مجموعة من التعليقات التوضيحية
إذا كان لديك مجموعة كبيرة من البيانات للتعليق عليها ، فإننا نوصي باستخدام APOC:
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
من المهم الحفاظ على خيارات batchSize iterateList كما هو مذكور في المثال. سيؤدي تشغيل إجراء التعليقات التوضيحية بالتوازي إلى إنشاء مسدود.
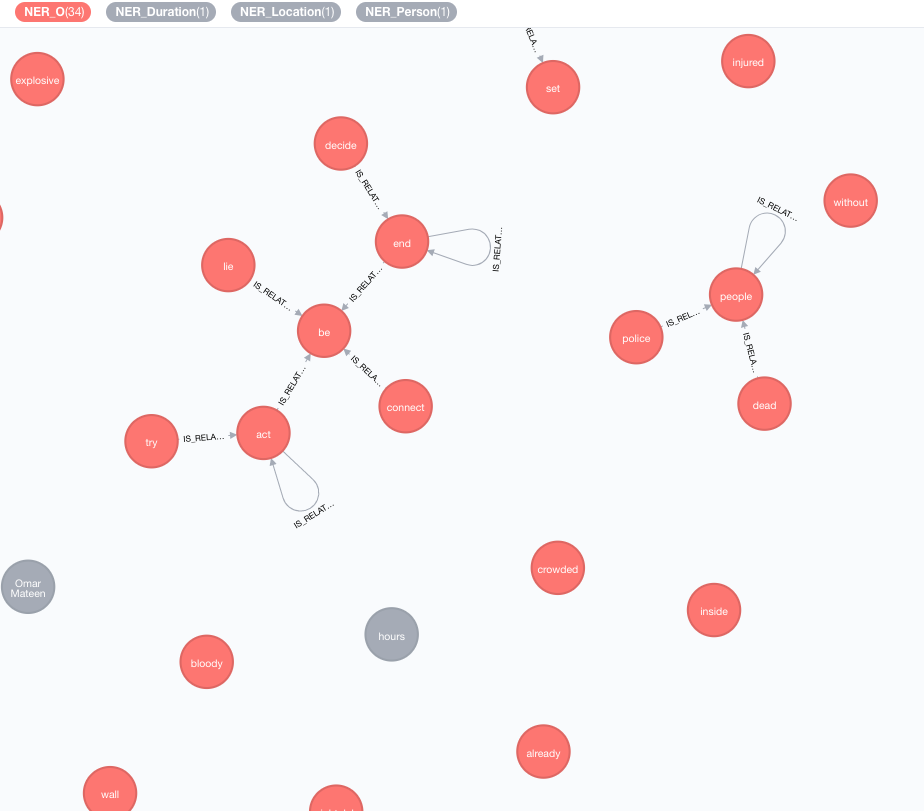
نحن ننفذ قواعد المعرفة الخارجية من أجل إثراء معرفة بياناتك الحالية.
اعتبارا من الآن ، يتوفر تطبيقان:
سيؤدي هذا الإثراء إلى تمديد معنى الرموز (عقد العلامات) في الرسم البياني.
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
المعلمات المتاحة (القيم الافتراضية في قوسين):
tag : علامة ليتم تخصيبهاenricher ( "conceptnet5" ): اختر microsoft أو conceptnet5depth ( 2 ): ما مدى عمق التسلسل الهرمي للمفهومadmittedRelationships : اختر أنواع علاقات المفاهيم المطلوبة ، يرجى الرجوع إلى وثائق المفاهيم للحصول على التفاصيلpipeline : اختر اسم خط الأنابيب لاستخدامه لتطهير المفاهيم قبل تخزينها إلى ديسيبل ؛ يتم استخدام خط أنابيب نظامك الافتراضي خلاف ذلكfilterByLanguage ( true ): السماح فقط مفاهيم اللغات المحددة في outputLanguages ؛ إذا لم يتم تحديد لغات ، فإن نفس لغة tag مطلوبةoutputLanguages ( [] ): إرجاع المفاهيم فقط بلغات محددةrelDirection ( "out" ): الاتجاه المطلوب للعلاقات في التسلسل الهرمي للمفهوم ( "in" ، "out" ، "both" )minWeight ( 0.0 ): الحد الأدنى من وزن المفهوم المعترف بهlimit ( 10 ): الحد الأقصى لعدد المفاهيم لكل tagsplitTag ( false ): إذا كان true ، فسيتم تخصيص tag أولاً ثم يخصك الرموز الفردية العلامات لديها الآن IS_RELATED_TO العلاقات مع المفاهيم المخصب الأخرى.
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText هو معلمة إلزامية تشير إلى المستند المشروح المطلوب لتحليله.
المعلمات الاختيارية المتاحة (القيم الافتراضية في قوسين):
keywordLabel (الكلمة الرئيسية): تسمية اسم العقد الرئيسية للكلمات الرئيسيةuseDependencies (صواب): استخدم تبعيات عالمية لإثراء الكلمات الرئيسية المستخرجة والعبارات الرئيسية بالعلامات المتعلقة من خلال علاقات المركب و AMODdependenciesGraph (False): استخدم التبعيات الشاملة لإنشاء الرسم البياني لتواجد العلامة (الافتراضي هو خطأ ، مما يعني أن تدفق الكلمات الطبيعي يستخدم لبناء تواجد مشترك)cleanKeywords (صواب): تشغيل إجراء التنظيفtopXTags (1/3): اضبط جزءًا من أعلى العلامات التي سيتم استخدامها ككلمات رئيسية / عبارات مفتاحrespectSentences (FALSE): احترام أو لا حدود الجملة لبناء الرسم البياني للاتحاد المشتركrespectDirections (خطأ): الاحترام أو عدم الاتجاهات في الرسم البياني المشترك (كيف تتبع الكلمات بعضها البعض)iterations (30): عدد تكرارات Pagerankdamp (0.85): عامل التخميد الوطنيthreshold (0.0001): عتبة تقارب PagerankremoveStopwords (TRUE): استخدم قائمة Stopwords لبناء الرسم البياني المشترك والتنظيف النهائي للكلمات الرئيسيةstopwords : تخصيص قائمة STOPWORDS (إذا بدأت القائمة بـ + ، يتم إلحاق الكلمات التالية بقائمة Stopwords الافتراضية ، وإلا فإن القائمة الافتراضية يتم الكتابة فوقها)admittedPOSs : حدد علامات POS التي تعتبر كمرشحين للكلمات الرئيسية ؛ مطلوب عند استخدام لغة مختلفة عن اللغة الإنجليزيةforbiddenPOSs : حدد قائمة ملصقات نقاط البيع التي سيتم تجاهلها عند إنشاء رسم بياني للاتحاد المشترك ؛ مطلوب عند استخدام لغة مختلفة عن اللغة الإنجليزيةforbiddenNEs : حدد قائمة NEs المراد تجاهلها للحصول على وصف خوارزمية TextRank مفصلة ، يرجى الرجوع إلى منشور المدونة حول استخراج الكلمات الرئيسية غير الخاضعة للإشراف.
يمكن أن يؤدي استخدام التبعيات الشاملة لإثراء الكلمات الرئيسية (خيار useDependencies ) إلى كلمات رئيسية ذات مستوى غير ضروري للتفاصيل ، على سبيل المثال برنامج لوجستيات مكوك فضاء الكلمات الرئيسية. في العديد من حالات الاستخدام ، قد نكون مهتمين أيضًا بمعرفة أن المستند المعطى يتكلم بشكل عام عن مكوك الفضاء (أو البرنامج اللوجستي ). للقيام بذلك ، قم بتشغيل ما بعد المعالجة مع أحد هذه الخيارات:
direct - يتم فحص كل عبارة رئيسية لعدد العلامات n مقابل جميع العبارات الرئيسية من جميع المستندات مع عدد العلامات 1 <m <n ؛ إذا كان الأول يحتوي على العبارة الرئيسية الأخيرة ، فسيتم إنشاء العلاقة من DESCRIBES M -Keyphrase إلى جميع النصوص المشروحة في N -keyphrasesubgroups - نفس الإجراء الذي يوجهه direct ، ولكن بدلاً من توصيل الكلمات الرئيسية ذات المستوى الأعلى مباشرةً إلى EnnotatedTexts ، فهي متصلة بالكلمات الرئيسية ذات المستوى الأدنى مع علاقات HAS_SUBGROUP // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel هي وسيطة اختيارية تم تعيينها افتراضيًا على "الكلمة الرئيسية" .
يتم معالجة عملية ما بعد العملية بشكل افتراضي على جميع الكلمات الرئيسية ، والتي يمكن أن تكون ثقيلة للغاية على الرسوم البيانية الكبيرة. يمكنك تحديد annotatedtext لتطبيق عملية ما بعد المعالجة مع وسيطة annotatedText :
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
مثال لتشغيله بكفاءة على مجموعة كاملة من الكلمات الرئيسية مع APOC:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
يمكن استخدام نهج مماثل لاستخراج الكلمات الرئيسية لتنفيذ تلخيص بسيط. يتم إنشاء رسم بياني للاتصال بكثافة للجمل ، مع علاقات الجملة الجملة التي تمثل تشابهها استنادًا إلى الكلمات المشتركة (عدد الكلمات المشتركة مقابل مجموع اللوغاريتمات لعدد الكلمات في جملة). ثم يتم استخدام Pagerank كتدبير مركزي لتصنيف الأهمية النسبية للجمل في المستند.
لتشغيل هذه الخوارزمية:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
المعلمات المتاحة:
annotatedTextiterations (30): عدد تكرارات Pagerankdamp (0.85): عامل التخميد الوطنيthreshold (0.0001): عتبة تقارب Pagerank يوفر إجراء تلخيص الخصائص الجديدة لعقد الجملة: summaryRelevance (قيمة Pagerank من الجملة المعطاة) و summaryRank (الترتيب ؛ 1 = أعلى جملة في المرتبة). مثال على الاستعلام لاسترداد الملخص:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
يمكنك أيضًا تحديد ما إذا كان النص المقدم إيجابيًا أو سلبيًا أو محايدًا. يتطلب هذا الإجراء عقدة مشروح ، والتي يتم إنتاجها بواسطة ga.nlp.annotate أعلاه.
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
سيعود هذا الإجراء ببساطة "النجاح" عندما يكون ناجحًا ، لكنه سيطبق :POSITIVE ، :NEUTRAL أو :NEGATIVE لكل جملة. نتيجة لذلك ، عند اكتمال اكتشاف المشاعر ، يمكنك الاستعلام عن شعور الجمل على هذا النحو:
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
بمجرد استخراج العلامات من جميع الأخبار أو العقد الأخرى التي تحتوي على بعض النص ، من الممكن حساب أوجه التشابه بينها باستخدام التشابه القائم على المحتوى. خلال هذه العملية ، يتم وصف كل نص مشروح باستخدام تنسيق ترميز TF-IDF. TF-IDF هي تقنية ثابتة من مجال استرجاع المعلومات ويعني بتردد الوثيقة على أساس التردد. يمكن ترميز المستندات النصية TF-IDF كمتجهات في مساحة إقليدية متعددة الأبعاد. تتوافق أبعاد الفضاء مع العلامات ، التي تم استخلاصها مسبقًا من المستندات. يتم حساب إحداثيات وثيقة معينة في كل بعد (أي لكل علامة) كمنتج لمؤتمرات فرعية: تردد مصطلح وتردد المستند العكسي.
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
المعلمات المتاحة (القيم الافتراضية بين قوسين):
input : قائمة العقد الإدخال - annotatedtextsrelationshipType (التشابه _cosine): نوع العلاقة بين التشابه ، استخدمه مع queryquery : حدد استعلامك الخاص لاستخراج TF و IDF في النموذج ... RETURN id(Tag), tf, idfpropertyName (القيمة): اسم خاصية عقدة موجودة (صفيف من القيم العددية) التي تحتوي على متجه المستندات المعد بالفعلWord2Vec هو نموذج شبكة عصبية من طبقتين ضحلة يستخدم لإنتاج تضمينات الكلمات (تمثل الكلمات التي تمثلها ناقلات دلالية متعددة الأبعاد) وهي واحدة من النماذج المستخدمة في مفهوم NumberBatch.
لإضافة نموذج المصدر (المتجهات) إلى فهرس لوسين
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir> هو مسار كامل للدليل مع متجهات المصدر المراد فهرستها<path_to_index> هو مسار كامل حيث سيتم تخزين الفهرس<identifier> عبارة عن سلسلة مخصصة تحدد النموذج بشكل فريدلسرد النماذج المتاحة:
CALL ga.nlp.ml.word2vec.listModels
يمكن الآن استخدام النموذج لحساب أوجه تشابه جيب التمام بين الكلمات:
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
أو يمكنك أن تسأل مباشرة عن Word2Vec للعقدة التي تحتوي على كلمة مخزنة في value الخصائص:
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
يمكننا أيضًا تخزين ناقلات Word2Vec بشكل دائم لتمييز العقد:
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query : استعلام يرجع العلامات التي يجب إرفاقها بتضمين المتجهاتmodelName : نموذج للاستخداميمكنك أيضًا الحصول على أقرب الجيران مع الإجراء التالي:
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
بالنسبة للموديلات الكبيرة ، على سبيل المثال ، فإن النص السريع الكامل للغة الإنجليزية ، ما يقرب من 2 مليون كلمة ، سيكون من غير الكفاءة حساب أقرب الجيران على الطيران.
يمكنك تحميل النموذج في الذاكرة من أجل الحصول على أقرب جيران أسرع (يستغرق ناقلات Word FastText 1M عمومًا 27 ثانية إذا لزم الأمر للقراءة من القرص ، ~ 300 مللي ثانية في الذاكرة):
تأكد من وجود ذاكرة كومة فعالة مخصصة لـ Neo4J:
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
قم بتحميل النموذج في الذاكرة:
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
واسترداده مع
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
يمكنك استخدام أي نموذج تضمين الكلمات طالما أن ما يلي صحيح:
.txt على سبيل المثال ، يمكنك تحميل النماذج من FastText وإعادة تسمية الملف فقط من .vec إلى .txt : https://fasttext.cc/docs/en/english-vectors.html
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
الإجراءات إرجاع صفوف مع number الأعمدة هو رقم الصفحة paragraphs كونها List<String> من نصوص الفقرة.
يمكنك أيضًا تمرير عنوان URL http أو https إلى الإجراء لتحميل ملف من موقع بعيد.
في بعض الحالات ، تحتوي مستندات PDF على بعض محتوى عديمة الفائدة متكررة مثل تذييلات الصفحات وما إلى ذلك ، يمكنك استبعادها من التحليل عن طريق تمرير قائمة من regexes التي تحدد الأجزاء لاستبعادها:
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
يمكن الاعتراف بـ Tika كزحف ويرفض الوصول إلى بعض المواقع التي تحتوي على PDF. يمكنك تجاوز هذا عن طريق تمرير خيار UserAgent :
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
في بعض المواقف ، سيكون من المفيد تخزين قيم معينة فقط بدلاً من الرسم البياني الكامل ، على الرغم من أنه قد يقلل من القدرة على استخراج رؤى (Textrank) على سبيل المثال:
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
WebVTT هو تنسيق مسارات نص الفيديو على الويب ، مثل نصوص youtube من مقاطع الفيديو: https://fr.wikipedia.org/wiki/webvtt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
ملفات قائمة الإجراءات أعلاه للدليل الحالي فقط ، إذا كنت بحاجة إلى المشي في أدلة الأطفال أيضًا ، استخدم walkdir :
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
قائمة النماذج المخزنة ومساراتها
إزالة وإعادة إنشاء خط أنابيب بنفس التكوين (مفيد عند استخدام ملفات NER ثابتة تم تغييرها لـ EG)
حقوق الطبع والنشر (C) 2013-2019 Graphaware
Graphaware هو برنامج مجاني: يمكنك إعادة توزيعه و/أو تعديله بموجب شروط ترخيص GNU العام العام كما تم نشره من قبل مؤسسة البرمجيات المجانية ، إما الإصدار 3 من الترخيص ، أو (في خيارك) أي إصدار لاحق. يتم توزيع هذا البرنامج على أمل أن يكون مفيدًا ، ولكن بدون أي ضمان ؛ بدون حتى الضمان الضمني للتسويق أو اللياقة لغرض معين. راجع رخصة GNU العامة لمزيد من التفاصيل. يجب أن تكون قد تلقيت نسخة من رخصة GNU العامة العامة مع هذا البرنامج. إذا لم يكن الأمر كذلك ، راجع http://www.gnu.org/licenses/.


