neo4j nlp
1.0.0
A partir de mayo de 2021, este repositorio ha sido retirado.
Este complemento Neo4J ofrece capacidades de procesamiento de lenguaje natural basadas en gráficos.
El módulo principal, este módulo, proporciona una interfaz común para los procesadores de texto subyacentes, así como un lenguaje específico de dominio construido sobre los procedimientos y funciones almacenados que hacen que su desarrollador de flujo de trabajo de procesamiento de lenguaje natural sea amigable.
Viene en 2 versiones, comunidad (de código abierto) y Enterprise con las siguientes características de PNL:
| Edición comunitaria | Edición empresarial | |
|---|---|---|
| Extracción de información de texto | ✔ | ✔ |
| Varios idiomas en la misma base de datos | ✔ | |
| Constructor de modelos CustomedNeNeDeScEgelition | ✔ | |
| ConceptNet5 Enrique | ✔ | ✔ |
| Microsoft Concept enrique | ✔ | ✔ |
| Extracción de palabras clave | ✔ | ✔ |
| Resumen de Textrank | ✔ | ✔ |
| Extracción de temas | ✔ | |
| Incrustaciones de palabras (Word2Vec) | ✔ | ✔ |
| Cálculo de similitud | ✔ | ✔ |
| Análisis de pdf | ✔ | ✔ |
| Apache Spark Enlace para algoritmos distribuidos | ✔ | |
| Implementación DOC2VEC | ✔ | |
| Interfaz de usuario | ✔ | |
| Capacidades de predicción de ML | ✔ | |
| Entidad fusionando | ✔ |
Hay dos implementaciones de procesadores NLP disponibles, respectivamente, Stanford NLP y OpenNLP (OpenNLP recibe actualizaciones menos frecuentes, se recomienda StanfordNLP).
De la versión 3.5.1.53.15 debe descargar los modelos de idioma, ver a continuación
Desde el directorio de complementos de Grapraware, descargue los siguientes archivos jar :
neo4j-framework (el frasco para esto está etiquetado como "Grapraware-server-enterprise-all")neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download y copiarlos en el directorio plugins de Neo4J.
Tenga cuidado de que los números de versión del marco que está utilizando Match con la versión de NEO4J que está utilizando . Este es un problema de configuración común. Por ejemplo, si está utilizando NEO4J 3.4.0 y superior, todos los frascos que descargue deben contener 3.4 en su número de versión.
Ejemplo plugins/ directorio:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
Agregue la siguiente configuración en el archivo neo4j.conf en el directorio config/ :
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
Inicie o reinicie su base de datos NEO4J.
Nota: Ambos procesadores de texto concretos son bastante codiciosos: deberá dedicar suficiente memoria para el espacio de montón neo4j.
Además, se sugieren los siguientes índices y restricciones para acelerar el rendimiento:
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
O utilice el procedimiento dedicado:
CALL ga.nlp.createSchema()
Defina qué idioma usará en esta base de datos:
CALL ga.nlp.config.setDefaultLanguage('en')
Una vez que se carga la extensión, puede ver la documentación básica sobre todos los procedimientos disponibles ejecutando esta consulta de Cypher:
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
La fase de extracción de texto se realiza con una tubería de procesamiento del lenguaje natural, cada tubería tiene una lista de componentes habilitados.
Por ejemplo, la tubería tokenizer básico tiene los siguientes componentes:
Es obligatorio crear su tubería primero:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
Los parámetros opcionales disponibles (los valores predeterminados están entre paréntesis):
name : Nombre deseado de una nueva tuberíatextProcessor : a qué procesador de texto se debe agregar la nueva tuberíaprocessingSteps : Configuración de la tubería (disponible tanto en Stanford como en OpenNLP a menos que se indique lo contrario)tokenize (predeterminado: verdadero): realizar tokenizaciónner (predeterminado: verdadero): reconocimiento de entidad nombradosentiment (predeterminado: falso): ejecutar análisis de sentimientos en oracionescoref (predeterminado: falso): resolución de coreferencia (identifique múltiples menciones de la misma entidad, como "Barack Obama" y "He")relations (predeterminado: falso): Ejecutar identificación de relaciones entre dos tokensdependency (predeterminada: False, STANFORDNLP SOLO): Extraer dependencias tipadas (Ej.: AMOD - Modificador de adjetivo, conjunción, ...)cleanxml (predeterminado: falso, stanfordnlp solamente): eliminar las etiquetas XMLtruecase (predeterminado: falso, solo stanfordnlp): reconoce el caso "verdadero" de los tokens (cómo se capitalizarían en un texto bien editado)customNER : Lista de identificadores del modelo NER personalizado (como una cadena, identificadores de modelo separados por ",")stopWords : especifique las palabras que se requieren para ignorarse (si la lista comienza con +, las siguientes palabras se agregan a la lista de palabras de parada predeterminadas, de lo contrario, la lista predeterminada se sobrescribe)threadNumber (predeterminado: 4): para múltiples subprocesosexcludedNER : (predeterminado: Ninguno) Especifique una lista de NE para no ser reconocida en la caja superior, por ejemplo, por excluir NER_Money y NER_O en los nodos de etiqueta, use ['O', 'Money']Para establecer una tubería como una tubería predeterminada:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
Para eliminar una tubería, use este comando:
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
Para ver los detalles de todas las tuberías existentes:
CALL ga.nlp.processor.getPipelines()
Tomemos el siguiente texto como ejemplo:
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
Simule su corpus original
Cree un nodo con el texto, este nodo representará su corpus original o gráfico de conocimiento:
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
Realizar la extracción de información de texto
La extracción se realiza a través del procedimiento annotate , que es el punto de entrada a la extracción de información de texto
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
Parámetros disponibles del procedimiento annotate :
text : texto para anotar representado como una cadenaid : especificar ID que se utilizará como propiedad id del nuevo nodo AnnotatedTexttextProcessor (predeterminado: "Stanford", si no está disponible que la primera entrada en la lista de procesadores de texto disponibles)pipeline (predeterminado: tokenizer)checkLanguage (predeterminado: verdadero): ejecute la detección de idiomas en el texto proporcionado y verifique si es compatible Este procedimiento vinculará su nodo original :News a un nodo :AnnotatedText , que es el punto de entrada para el PNL basado en gráficos de esta noticia en particular. El texto original se divide en palabras, partes del habla y funciones. Este análisis del texto actúa como un punto de partida para los pasos posteriores.
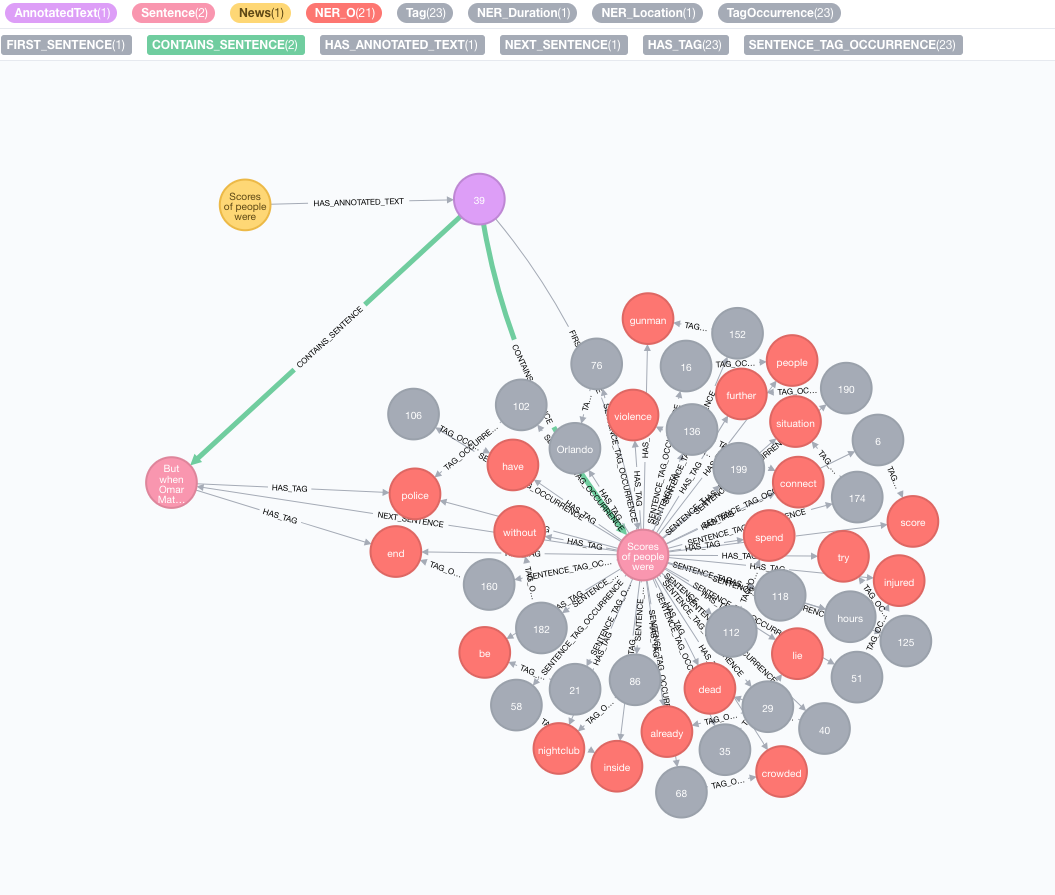
Ejecutar un lote de anotaciones
Si tiene un gran conjunto de datos para anotar, recomendamos usar APOC:
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
Es importante mantener las opciones batchSize y iterateList como se menciona en el ejemplo. Ejecutar el procedimiento de anotación en paralelo creará puntos muertos.
Implementamos bases de conocimiento externas para enriquecer el conocimiento de sus datos actuales.
A partir de ahora, hay dos implementaciones disponibles:
Este enriquecedor extenderá el significado de tokens (nodos de etiqueta) en el gráfico.
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
Los parámetros disponibles (los valores predeterminados están en los paréntesis):
tag : Etiqueta para enriquecerenricher ( "conceptnet5" ): elija microsoft o conceptnet5depth ( 2 ): Qué tan profundo ir en la jerarquía de conceptosadmittedRelationships : elija Tipos de relaciones conceptuales deseadas, consulte la documentación de conceptnet para obtener más detallespipeline : elija el nombre de la tubería que se utilizará para la limpieza de conceptos antes de almacenarlos en su DB; La tubería predeterminada de su sistema se usa de otra manerafilterByLanguage ( true ): permita solo conceptos de idiomas especificados en outputLanguages ; Si no se especifican idiomas, se requiere el mismo idioma que tagoutputLanguages ( [] ): devuelva solo conceptos con idiomas especificadosrelDirection ( "out" ): Dirección de relaciones deseada en la jerarquía de conceptos ( "in" , "out" , "both" )minWeight ( 0.0 ): peso de relación conceptual mínima admitidalimit ( 10 ): Número máximo de conceptos por tagsplitTag ( false ): si es true , tag se tokenize primero y luego enriquece los tokens individuales Las etiquetas ahora tienen relaciones IS_RELATED_TO con otros conceptos enriquecidos.
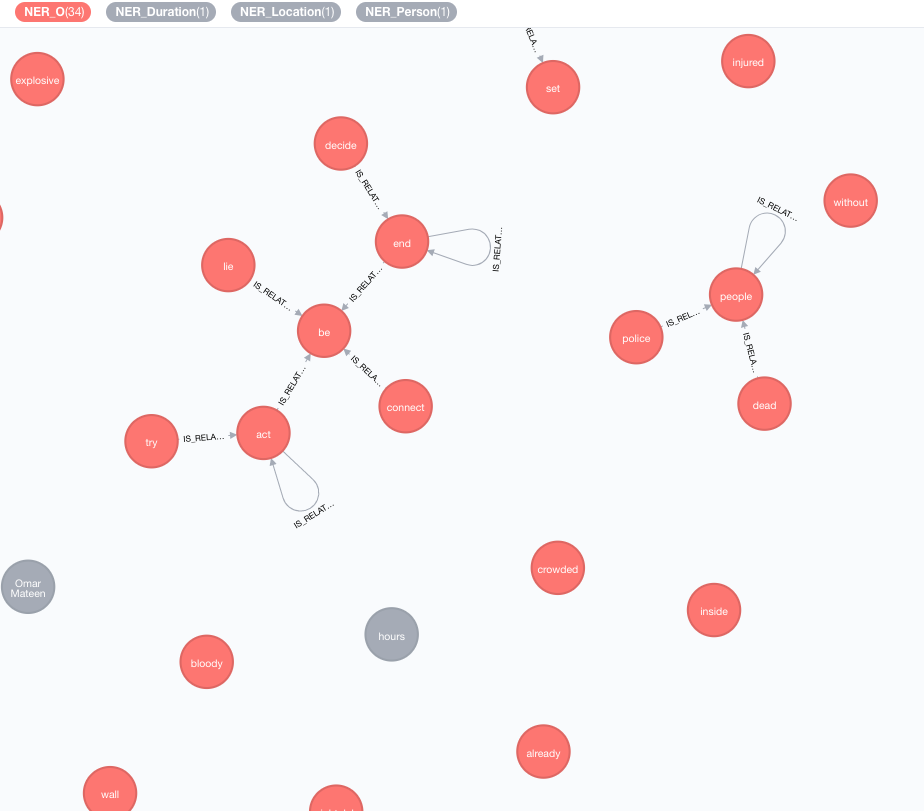
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText es un parámetro obligatorio que se refiere al documento anotado que debe analizarse.
Parámetros opcionales disponibles (los valores predeterminados están en los soportes):
keywordLabel (palabra clave): nombre de etiqueta de los nodos de palabras claveuseDependencies (verdadero): use dependencias universales para enriquecer las palabras clave extraídas y las frases clave por etiquetas relacionadas a través de relaciones compuestas y AMODdependenciesGraph (falso): use dependencias universales para crear un gráfico de co-ocurrencia de etiqueta (el valor predeterminado es falso, lo que significa que se usa un flujo de palabras natural para construir co-ocurrencias)cleanKeywords (verdadero): Procedimiento de limpieza de ejecucióntopXTags (1/3): establezca una fracción de etiquetas con mejor calificación que se utilizarán como palabras clave / frases claverespectSentences (falso): respeto o no los límites de las oraciones para la construcción de gráficos de concurrenciarespectDirections (falso): respeto o no direcciones en el gráfico de concurrencia (cómo las palabras se siguen entre sí)iterations (30): Número de iteraciones de PageRankdamp (0.85): factor de amortiguación de PageRankthreshold (0.0001): umbral de convergencia de PageRankremoveStopwords (verdadero): use una lista de palabras de parada para la construcción de gráficos de concurrencia y la limpieza final de palabras clavestopwords : Personalizar la lista de palabras de parada (si la lista comienza con + , las siguientes palabras se agregan a la lista de palabras de parada predeterminadas, de lo contrario, la lista predeterminada se sobrescribe)admittedPOSs : especifique qué etiquetas POS se consideran candidatos de palabras clave; necesario cuando se usa un idioma diferente al inglésforbiddenPOSs : especifique la lista de etiquetas POS que se ignorarán al construir un gráfico de co-ocurrencia; necesario cuando se usa un idioma diferente al inglésforbiddenNEs : especifique la lista de NES para ser ignorado Para obtener una descripción detallada del algoritmo de TextRank , consulte nuestra publicación de blog sobre extracción de palabras clave no supervisadas.
El uso de dependencias universales para el enriquecimiento de palabras clave (Opción useDependencies ) puede dar lugar a palabras clave con un nivel de detalle innecesario, por ejemplo, un programa de logística de transbordador espacial de palabras clave. En muchos casos de uso, podríamos estar interesados en saber también que el documento dado habla generalmente sobre el transbordador espacial (o el programa logístico ). Para hacer eso, ejecute el procesamiento posterior con una de estas opciones:
direct : cada frase clave de n número de etiquetas se verifica en todas las frases clave de todos los documentos con 1 <m <n número de etiquetas; Si el primero contiene la última frase clave, entonces se crea una relación DESCRIBES a partir de la frase m a todos los textos anotados de la n -keyphrasesubgroups : el mismo procedimiento que para direct , pero en lugar de conectar palabras clave de nivel superior directamente a AnnotatedTexts , están conectados a las palabras clave de nivel inferior con relaciones HAS_SUBGROUP // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel es un argumento opcional establecido de forma predeterminada en "Palabra clave" .
La operación posterior al proceso de forma predeterminada se procesa en todas las palabras clave, que pueden ser muy pesadas en gráficos grandes. Puede especificar el AnnotatedText en el que aplicar la operación posterior al proceso con el argumento annotatedText :
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
Ejemplo para ejecutarlo de manera eficiente en el conjunto completo de palabras clave con APOC:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
Se puede emplear un enfoque similar a la extracción de palabras clave para implementar un resumen simple. Se crea un gráfico de oraciones densamente conectado, con relaciones de oración de oración que representan su similitud basada en palabras compartidas (número de palabras compartidas frente a suma de logaritmos de número de palabras en una oración). PageRank se usa como medida de centralidad para clasificar la importancia relativa de las oraciones en el documento.
Para ejecutar este algoritmo:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
Parámetros disponibles:
annotatedTextiterations (30): Número de iteraciones de PageRankdamp (0.85): factor de amortiguación de PageRankthreshold (0.0001): umbral de convergencia de PageRank El procedimiento de resumen ahorra nuevas propiedades a los nodos de oración: summaryRelevance (valor de PageRank de la oración dada) y summaryRank (clasificación; 1 = oración más alta en clasificación). Consulta de ejemplo para recuperar resumen:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
También puede determinar si el texto presentado es positivo, negativo o neutral. Este procedimiento requiere un nodo de texto anotado, que produce ga.nlp.annotate arriba.
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
Este procedimiento simplemente devolverá el "éxito" cuando sea exitoso, pero aplicará la etiqueta :POSITIVE :NEUTRAL o :NEGATIVE para cada oración. Como resultado, cuando se completa la detección de sentimientos, puede consultar el sentimiento de las oraciones como tales:
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
Una vez que se extraen las etiquetas de todas las noticias u otros nodos que contienen algún texto, es posible calcular las similitudes entre ellas utilizando la similitud basada en el contenido. Durante este proceso, cada texto anotado se describe utilizando el formato de codificación TF-IDF. TF-IDF es una técnica establecida del campo de recuperación de información y representa la frecuencia de documentos de la frecuencia a término. Los documentos de texto se pueden codificar TF-IDF como vectores en un espacio euclidiano multidimensional. Las dimensiones espaciales corresponden a las etiquetas, previamente extraídas de los documentos. Las coordenadas de un documento dado en cada dimensión (es decir, para cada etiqueta) se calculan como un producto de dos subconectivas: frecuencia de término y frecuencia de documento inverso.
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
Parámetros disponibles (los valores predeterminados están en los soportes):
input : Lista de nodos de entrada - AnotatedTextsrelationshipType (similitude_cosina): tipo de relación de similitud, úsela junto con queryquery : especifique su propia consulta para extraer TF e IDF en formulario ... RETURN id(Tag), tf, idfpropertyName (valor): nombre de una propiedad de nodo existente (matriz de valores numéricos) que contiene un vector de documento ya preparadoWord2VEC es un modelo de red neuronal de dos capas poco profundo que se utiliza para producir incrustaciones de palabras (palabras representadas como vectores semánticos multidimensionales) y es uno de los modelos utilizados en ConceptNet NumberBatch.
Para agregar el modelo de origen (vectores) en un índice de Lucene
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir> es una ruta completa al directorio con los vectores de origen a indexar<path_to_index> es una ruta completa donde se almacenará el índice<identifier> es una cadena personalizada que identifica de manera única el modeloPara enumerar los modelos disponibles:
CALL ga.nlp.ml.word2vec.listModels
El modelo ahora se puede usar para calcular las similitudes de coseno entre las palabras:
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
O puede solicitar directamente un Word2Vec de un nodo que tenga una palabra almacenada en value de la propiedad:
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
También podemos almacenar permanentemente los vectores Word2Vec en los nodos de etiqueta:
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query : consulta que devuelve etiquetas a las que se deben adjuntar vectores de incrustaciónmodelName : Model para usarTambién puede obtener los vecinos más cercanos con el siguiente procedimiento:
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
Para modelos grandes, por ejemplo, Full FastText para inglés, aproximadamente 2 millones de palabras, será ineficiente calcular a los vecinos más cercanos sobre la marcha.
Puede cargar el modelo en la memoria para tener vecinos más cercanos más rápidos (los vectores de palabras de 1M FastText generalmente tardan 27 segundos si es necesario para leer desde el disco, ~ 300 ms en la memoria):
Asegúrese de tener una memoria de montón eficiente dedicada a NEO4J:
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
Cargue el modelo en la memoria:
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
Y recuperarlo con
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
Puede usar cualquier modelo de incrustación de palabras siempre que lo siguiente sea verdadero:
.txt Por ejemplo, puede cargar los modelos de FastText y simplemente cambiar el nombre del archivo de .vec a .txt : https://fasttext.cc/docs/en/english-vectors.html
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
El procedimiento devuelve las filas con number de columnas que son el número de página y paragraphs son una List<String> de textos de párrafo.
También puede pasar una URL http o https al procedimiento para cargar un archivo desde una ubicación remota.
En algunos casos, los documentos PDF tienen un contenido inútil recurrente como los pies de página, etc., puede excluirlos del análisis al pasar una lista de reglas que definen las partes para excluir:
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
Tika puede ser reconocido como rastreador y se le niega el acceso a algunos sitios que contienen PDF. Puede anular esto pasando una opción UserAgent :
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
En ciertas situaciones, sería útil almacenar solo ciertos valores en lugar del gráfico completo, tenga en cuenta que podría reducir la capacidad de extraer ideas (Textrank) para EG:
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
WebVTT es el formato de las pistas de texto de video web, como las transcripciones de los videos de YouTube: https://fr.wikipedia.org/wiki/webvtt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Los archivos de la lista de procedimientos anteriores del directorio actual, si también necesita caminar por los directorios de los niños, use walkdir :
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Lista de modelos almacenados y sus caminos
Eliminar y recrear una tubería con la misma configuración (útil cuando se usa archivos ner estáticos que se han cambiado para EG)
Copyright (c) 2013-2019 Grapraware
Grapraware es el software gratuito: puede redistribuirlo y/o modificarlo bajo los términos de la Licencia Pública General de GNU publicada por Free Software Foundation, ya sea la versión 3 de la licencia o (a su opción) cualquier versión posterior. Este programa se distribuye con la esperanza de que sea útil, pero sin ninguna garantía; Sin siquiera la garantía implícita de comerciabilidad o estado físico para un propósito particular. Vea la Licencia Pública General de GNU para más detalles. Debería haber recibido una copia de la Licencia Pública General de GNU junto con este programa. Si no, consulte http://www.gnu.org/licenses/.


