neo4j nlp
1.0.0
Pada Mei 2021, repositori ini telah pensiun.
Plugin NEO4J ini menawarkan kemampuan pemrosesan bahasa alami berbasis grafik.
Modul utama, modul ini, menyediakan antarmuka umum untuk prosesor teks yang mendasari serta bahasa spesifik domain yang dibangun di atas prosedur dan fungsi yang disimpan membuat pengembang alur kerja pemrosesan bahasa Anda ramah.
Muncul dalam 2 versi, komunitas (sumber terbuka) dan perusahaan dengan fitur NLP berikut:
| Edisi Komunitas | Edisi Perusahaan | |
|---|---|---|
| Ekstraksi Informasi Teks | ✔ | ✔ |
| Multi-bahasa dalam database yang sama | ✔ | |
| Pembangun model kustom bernama | ✔ | |
| ConceptNet5 Enrumher | ✔ | ✔ |
| Microsoft Concept Enrumher | ✔ | ✔ |
| Ekstraksi kata kunci | ✔ | ✔ |
| Ringkasan Textrank | ✔ | ✔ |
| Ekstraksi Topik | ✔ | |
| Kata embeddings (word2vec) | ✔ | ✔ |
| Perhitungan kesamaan | ✔ | ✔ |
| Parsing PDF | ✔ | ✔ |
| Apache Spark Binding untuk algoritma terdistribusi | ✔ | |
| Implementasi DOC2VEC | ✔ | |
| Antarmuka pengguna | ✔ | |
| Kemampuan prediksi ML | ✔ | |
| Penggabungan entitas | ✔ |
Dua implementasi prosesor NLP tersedia, masing -masing Stanford NLP dan OpenNLP (OpenNLP menerima pembaruan yang lebih jarang, StanfordNLP direkomendasikan).
Dari versi 3.5.1.53.15 Anda perlu mengunduh model bahasa, lihat di bawah
Dari Direktori Plugins GraphAware, unduh file jar berikut:
neo4j-framework (toples untuk ini diberi label "graphaware-server-enterprise-all")neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download dan salin di direktori plugins Neo4j.
Berhati -hatilah bahwa nomor versi kerangka kerja yang Anda gunakan cocok dengan versi Neo4j yang Anda gunakan . Ini adalah masalah pengaturan yang umum. Misalnya, jika Anda menggunakan NEO4J 3.4.0 dan di atas, semua toples yang Anda unduh harus berisi 3.4 dalam nomor versi mereka.
Contoh plugins/ Direktori:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
Tambahkan konfigurasi berikut dalam file neo4j.conf di config/ Directory:
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
Mulai atau restart database NEO4J Anda.
Catatan: Kedua prosesor teks konkret cukup serakah - Anda perlu mendedikasikan memori yang cukup untuk ruang tumpukan neo4j.
Selain itu, indeks dan kendala berikut disarankan untuk mempercepat kinerja:
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
Atau gunakan prosedur khusus:
CALL ga.nlp.createSchema()
Tentukan bahasa mana yang akan Anda gunakan dalam database ini:
CALL ga.nlp.config.setDefaultLanguage('en')
Setelah ekstensi dimuat, Anda dapat melihat dokumentasi dasar pada semua prosedur yang tersedia dengan menjalankan kueri Cypher ini:
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
Fase ekstraksi teks dilakukan dengan pipa pemrosesan bahasa alami, setiap pipa memiliki daftar komponen yang diaktifkan.
Misalnya, pipa tokenizer dasar memiliki komponen berikut:
Adalah wajib untuk membuat pipa Anda terlebih dahulu:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
Parameter opsional yang tersedia (nilai default ada dalam tanda kurung):
name : Nama yang diinginkan dari pipa barutextProcessor : ke mana prosesor teks harus ditambahkan pipa baruprocessingSteps : Konfigurasi pipa (tersedia di Stanford dan OpenNLP kecuali dinyatakan sebaliknya)tokenize (default: true): lakukan tokenisasiner (default: true): pengakuan entitas bernamasentiment (default: false): Jalankan analisis sentimen pada kalimatcoref (default: false): Resolusi Coreference (mengidentifikasi beberapa menyebutkan entitas yang sama, seperti "Barack Obama" dan "He")relations (default: false): Jalankan identifikasi hubungan antara dua tokendependency (default: false, stanfordnlp saja): Ekstrak dependensi yang diketik (mis.: amod - pengubah kata sifat, conjunct, ...)cleanxml (default: false, stanfordnlp saja): Hapus tag XMLtruecase (default: false, stanfordnlp saja): Mengakui kasus token "benar" (bagaimana mereka akan dikapitalisasi dalam teks yang diedit dengan baik)customNER : Daftar Pengidentifikasi Model NER Kustom (sebagai string, pengidentifikasi model yang dipisahkan oleh ",")stopWords : Tentukan kata -kata yang harus diabaikan (jika daftar dimulai dengan +, kata -kata berikut ditambahkan ke daftar stopword default, jika tidak daftar default ditimpa)threadNumber (default: 4): Untuk multi-threadingexcludedNER : (Default: Tidak Ada) Menentukan daftar NE untuk tidak dikenali dalam huruf besar, misalnya untuk mengecualikan NER_Money dan NER_O pada node tag, gunakan ['o', 'uang']Untuk mengatur pipa sebagai pipa default:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
Untuk menghapus pipa, gunakan perintah ini:
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
Untuk melihat detail semua pipa yang ada:
CALL ga.nlp.processor.getPipelines()
Mari kita ambil teks berikut sebagai contoh:
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
Simulasi korpus asli Anda
Buat node dengan teks, node ini akan mewakili korpus asli atau grafik pengetahuan Anda:
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
Lakukan ekstraksi informasi teks
Ekstraksi dilakukan melalui prosedur annotate yang merupakan titik masuk ke ekstraksi informasi teks
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
Parameter yang tersedia dari prosedur annotate :
text : Teks ke Anotasi Diwakili sebagai Stringid : Tentukan ID yang akan digunakan sebagai properti id dari node AnnotatedText barutextProcessor (default: "Stanford", jika tidak tersedia dari entri pertama dalam daftar prosesor teks yang tersedia)pipeline (default: tokenizer)checkLanguage (default: true): Jalankan deteksi bahasa pada teks yang disediakan dan periksa apakah itu didukung Prosedur ini akan menautkan Node :News Asli Anda ke :AnnotatedText yang merupakan titik masuk untuk NLP berbasis grafik dari berita khusus ini. Teks asli dipecah menjadi kata -kata, bagian ucapan, dan fungsi. Analisis teks ini bertindak sebagai titik awal untuk langkah -langkah selanjutnya.
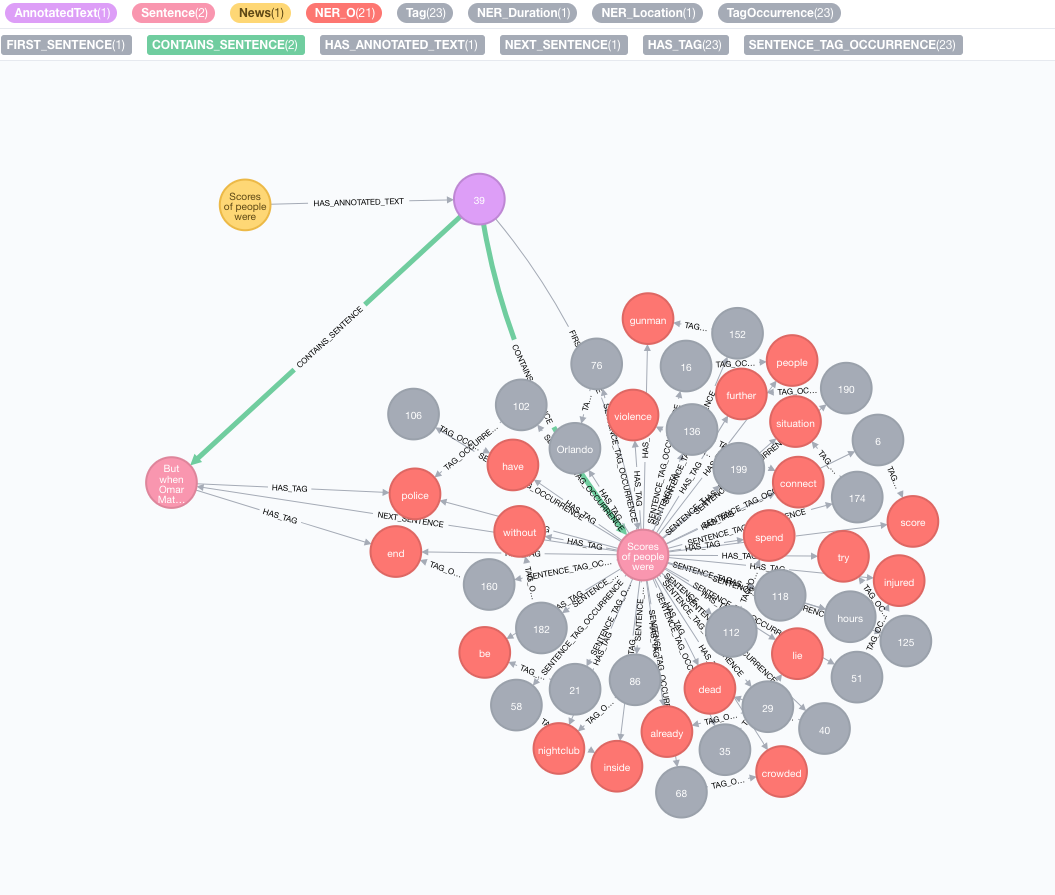
Menjalankan sejumlah anotasi
Jika Anda memiliki set data besar untuk Annotate, kami sarankan untuk menggunakan APOC:
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
Penting untuk menjaga opsi batchSize dan iterateList seperti yang disebutkan dalam contoh. Menjalankan prosedur anotasi secara paralel akan membuat kebuntuan.
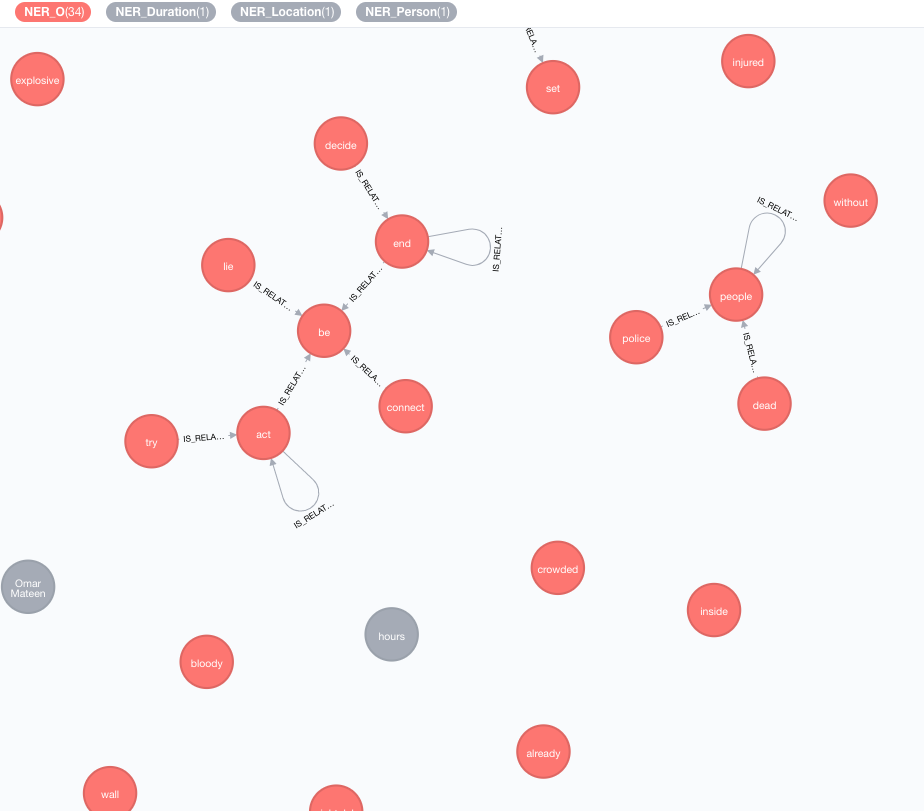
Kami menerapkan basis pengetahuan eksternal untuk memperkaya pengetahuan tentang data Anda saat ini.
Sampai sekarang, dua implementasi tersedia:
Enrumher ini akan memperluas arti token (node tag) dalam grafik.
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
Parameter yang tersedia (nilai default ada dalam tanda kurung):
tag : Tag untuk diperkayaenricher ( "conceptnet5" ): Pilih microsoft atau conceptnet5depth ( 2 ): seberapa dalam untuk pergi dalam hirarki konsepadmittedRelationships : Pilih jenis hubungan konsep yang diinginkan, silakan merujuk ke dokumentasi ConceptNet untuk detailnyapipeline : Pilih Nama Pipa yang akan digunakan untuk membersihkan konsep sebelum menyimpannya ke DB Anda; Pipa default sistem Anda digunakan sebaliknyafilterByLanguage ( true ): Izinkan hanya konsep bahasa yang ditentukan dalam outputLanguages ; Jika tidak ada bahasa yang ditentukan, bahasa yang sama dengan tag diperlukanoutputLanguages ( [] ): Kembalikan hanya konsep dengan bahasa yang ditentukanrelDirection ( "out" ): Arah yang diinginkan dari hubungan dalam hirarki konsep ( "in" , "out" , "both" )minWeight ( 0.0 ): Berat hubungan konsep minimal yang diakuilimit ( 10 ): jumlah maksimal konsep per tagsplitTag ( false ): Jika true , tag adalah tokenisasi pertama dan kemudian token individu diperkaya Tag sekarang memiliki hubungan IS_RELATED_TO dengan konsep yang diperkaya lainnya.
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText adalah parameter wajib yang mengacu pada dokumen anotasi yang harus dianalisis.
Parameter opsional yang tersedia (nilai default ada dalam tanda kurung):
keywordLabel (kata kunci): Nama label dari Node Kata KunciuseDependencies (Benar): Gunakan dependensi universal untuk memperkaya kata kunci yang diekstraksi dan frasa kunci dengan tag yang terkait melalui hubungan senyawa dan amoddependenciesGraph (false): Gunakan dependensi universal untuk membuat grafik tag co-kejadian (default adalah false, yang berarti bahwa aliran kata alami digunakan untuk membangun co-kejadian)cleanKeywords (Benar): Jalankan prosedur pembersihantopXTags (1/3): Tetapkan sebagian kecil dari tag berperingkat tertinggi yang akan digunakan sebagai kata kunci / frasa kuncirespectSentences (Salah): Batas Hormat atau TidakrespectDirections (false): menghormati atau tidak arah dalam grafik co-kejadian (bagaimana kata-kata mengikuti satu sama lain)iterations (30): Jumlah iterasi PageRankdamp (0,85): Faktor redaman PageRankthreshold (0,0001): Pagerank Convergence ThresholdremoveStopwords (true): Gunakan daftar stopwords untuk pembuatan grafik co-kejadian dan pembersihan akhir kata kuncistopwords : Kustomisasi daftar Stopwords (jika daftar dimulai dengan + , kata -kata berikut ditambahkan ke daftar Stopwords default, jika tidak daftar default ditimpa)admittedPOSs : Tentukan label POS mana yang dianggap sebagai kandidat kata kunci; dibutuhkan saat menggunakan bahasa yang berbeda dari bahasa InggrisforbiddenPOSs : Tentukan daftar label POS yang akan diabaikan saat membangun grafik kemunculan bersama; dibutuhkan saat menggunakan bahasa yang berbeda dari bahasa InggrisforbiddenNEs : Tentukan daftar NES yang akan diabaikan Untuk deskripsi algoritma TextRank yang terperinci, silakan merujuk ke posting blog kami tentang ekstraksi kata kunci tanpa pengawasan.
Menggunakan ketergantungan universal untuk pengayaan kata kunci (opsi useDependencies ) dapat menghasilkan kata kunci dengan tingkat detail yang tidak perlu, misalnya program kunci space shuttle . Dalam banyak kasus penggunaan, kami mungkin tertarik untuk mengetahui bahwa dokumen yang diberikan berbicara secara umum tentang pesawat ulang -alik (atau program logistik ). Untuk melakukan itu, jalankan pasca pemrosesan dengan salah satu opsi ini:
direct - Setiap frasa kunci dari jumlah t tag diperiksa terhadap semua frasa kunci dari semua dokumen dengan 1 <m <n jumlah tag; Jika yang pertama berisi frasa kunci yang terakhir, maka hubungan DESCRIBES dibuat dari m -keyphrase ke semua teks beranotasi dari n -keyphrasesubgroups - Prosedur yang sama seperti untuk direct , tetapi alih -alih menghubungkan kata kunci tingkat yang lebih tinggi secara langsung ke AnnotatedTexts , mereka terhubung ke kata kunci level yang lebih rendah dengan hubungan HAS_SUBGROUP // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel adalah argumen opsional yang ditetapkan secara default ke "kata kunci" .
Operasi postprocess secara default sedang diproses pada semua kata kunci, yang bisa sangat berat pada grafik besar. Anda dapat menentukan AnnotatedText untuk menerapkan operasi postprocess dengan argumen annotatedText :
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
Contoh untuk menjalankannya secara efisien pada set kata kunci lengkap dengan APOC:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
Pendekatan serupa dengan ekstraksi kata kunci dapat digunakan untuk mengimplementasikan ringkasan sederhana. Grafik kalimat yang sangat terhubung dibuat, dengan hubungan kalimat kalimat yang mewakili kesamaan mereka berdasarkan kata-kata bersama (jumlah kata bersama vs jumlah logaritma jumlah kata dalam sebuah kalimat). PageRank kemudian digunakan sebagai ukuran sentralitas untuk memberi peringkat kepentingan relatif kalimat dalam dokumen.
Untuk menjalankan algoritma ini:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
Parameter yang tersedia:
annotatedTextiterations (30): Jumlah iterasi PageRankdamp (0,85): Faktor redaman PageRankthreshold (0,0001): Pagerank Convergence Threshold Prosedur peringkasan menyimpan properti baru ke node kalimat: summaryRelevance (nilai pagerank dari kalimat yang diberikan) dan summaryRank (peringkat; 1 = kalimat peringkat tertinggi). Contoh kueri untuk mengambil ringkasan:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
Anda juga dapat menentukan apakah teks yang disajikan positif, negatif, atau netral. Prosedur ini membutuhkan node AnnotatedText, yang diproduksi oleh ga.nlp.annotate di atas.
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
Prosedur ini hanya akan mengembalikan "kesuksesan" ketika berhasil, tetapi akan menerapkan label :POSITIVE , :NEUTRAL atau :NEGATIVE untuk setiap kalimat. Akibatnya, ketika deteksi sentimen selesai, Anda dapat meminta sentimen kalimat seperti itu:
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
Setelah tag diekstraksi dari semua berita atau node lain yang berisi beberapa teks, dimungkinkan untuk menghitung kesamaan di antara mereka menggunakan kesamaan berbasis konten. Selama proses ini, setiap teks beranotasi dijelaskan menggunakan format pengkodean TF-IDF. TF-IDF adalah teknik yang ditetapkan dari bidang pengambilan informasi dan merupakan singkatan dari frekuensi dokumen yang berinversal frekuensi. Dokumen teks dapat disandikan TF-IDF sebagai vektor dalam ruang Euclidean multidimensi. Dimensi ruang sesuai dengan tag, yang sebelumnya diekstraksi dari dokumen. Koordinat dari dokumen yang diberikan di setiap dimensi (yaitu, untuk setiap tag) dihitung sebagai produk dari dua sub-pengukuran: frekuensi istilah dan frekuensi dokumen terbalik.
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
Parameter yang tersedia (nilai default ada dalam tanda kurung):
input : Daftar Node Input - AnnotatedTextsrelationshipType (kesamaan_cosine): Jenis hubungan kesamaan, gunakan bersama dengan queryquery : Tentukan kueri Anda sendiri untuk mengekstraksi TF dan IDF dalam bentuk ... RETURN id(Tag), tf, idfpropertyName (Nilai): Nama properti simpul yang ada (array nilai numerik) yang berisi vektor dokumen yang sudah disiapkanWord2Vec adalah model jaringan saraf dua lapis yang dangkal yang digunakan untuk menghasilkan embeddings kata (kata-kata yang direpresentasikan sebagai vektor semantik multidimensi) dan merupakan salah satu model yang digunakan dalam ConceptNet NumberBatch.
Untuk menambahkan model sumber (vektor) ke dalam indeks Lucene
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir> adalah jalur lengkap ke direktori dengan vektor sumber yang akan diindeks<path_to_index> adalah jalur lengkap di mana indeks akan disimpan<identifier> adalah string khusus yang secara unik mengidentifikasi modelUntuk daftar model yang tersedia:
CALL ga.nlp.ml.word2vec.listModels
Model sekarang dapat digunakan untuk menghitung kesamaan cosinus antara kata -kata:
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
Atau Anda dapat meminta langsung untuk sebuah node yang memiliki kata yang disimpan dalam value properti:
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
Kami juga dapat menyimpan vektor Word2Vec secara permanen untuk menandai node:
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query : Permintaan yang mengembalikan tag yang harus dilampirkan oleh vektor embeddingmodelName : Model untuk digunakanAnda juga bisa mendapatkan tetangga terdekat dengan prosedur berikut:
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
Untuk model besar, misalnya fasttext penuh untuk bahasa Inggris, sekitar 2 juta kata, tidak efisien untuk menghitung tetangga terdekat dengan cepat.
Anda dapat memuat model ke dalam memori agar tetangga terdekat yang lebih cepat (FastText 1M Word Vector umumnya membutuhkan waktu 27 detik jika perlu membaca dari disk, ~ 300ms dalam memori):
Pastikan memori tumpukan efisien yang didedikasikan untuk NEO4J:
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
Muat model ke dalam memori:
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
Dan mengambilnya dengan
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
Anda dapat menggunakan model embedding kata apa pun selama berikut ini benar:
.txt Misalnya, Anda dapat memuat model dari FastText dan hanya mengubah nama file dari .vec ke .txt : https://fasttext.cc/docs/en/english-vectors.html
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
Prosedur mengembalikan baris dengan number kolom adalah nomor halaman dan paragraphs menjadi List<String> dari teks paragraf.
Anda juga dapat melewati URL http atau https ke prosedur untuk memuat file dari lokasi jarak jauh.
Dalam beberapa kasus, dokumen PDF memiliki beberapa konten tidak berguna yang berulang seperti footer halaman dll, Anda dapat mengecualikannya dari parsing dengan menyampaikan daftar regex yang mendefinisikan bagian -bagian untuk dikecualikan:
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
Tika dapat diakui sebagai crawler dan ditolak akses ke beberapa situs yang berisi PDF. Anda dapat mengesampingkan ini dengan memberikan opsi UserAgent :
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
Dalam situasi tertentu, akan berguna untuk hanya menyimpan nilai -nilai tertentu alih -alih grafik penuh, perhatikan bahwa hal itu dapat mengurangi kemampuan untuk mengekstraksi wawasan (Textrank) misalnya:
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
WebVTT adalah format untuk trek teks video web, seperti transkrip youtube video: https://fr.wikipedia.org/wiki/webvtt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Daftar prosedur di atas hanya dari direktori saat ini, jika Anda perlu berjalan di direktori anak -anak juga, gunakan walkdir :
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Daftar model yang tersimpan dan jalurnya
Hapus dan buat ulang pipa dengan konfigurasi yang sama (berguna saat menggunakan file ner statis yang telah diubah misalnya)
Hak Cipta (C) 2013-2019 Graphaware
GraphAware adalah perangkat lunak gratis: Anda dapat mendistribusikannya kembali dan/atau memodifikasinya di bawah ketentuan Lisensi Publik Umum GNU seperti yang diterbitkan oleh Free Software Foundation, baik versi 3 dari lisensi, atau (pada opsi Anda) versi selanjutnya. Program ini didistribusikan dengan harapan akan bermanfaat, tetapi tanpa jaminan apa pun; bahkan tanpa jaminan tersirat dari dapat diperjualbelikan atau kebugaran untuk tujuan tertentu. Lihat Lisensi Publik Umum GNU untuk lebih jelasnya. Anda seharusnya menerima salinan Lisensi Publik Umum GNU bersama dengan program ini. Jika tidak, lihat http://www.gnu.org/licenses/.


