neo4j nlp
1.0.0
Em maio de 2021, esse repositório foi aposentado.
Este plug -in NEO4J oferece recursos de processamento de linguagem natural baseados em gráficos.
O módulo principal, este módulo, fornece uma interface comum para os processadores de texto subjacentes, bem como um idioma específico de domínio construído no topo de procedimentos e funções armazenadas, tornando o seu desenvolvedor de fluxo de trabalho de processamento de linguagem natural amigável.
Ele vem em 2 versões, comunidade (de código aberto) e empresa com os seguintes recursos da PNL:
| Edição da comunidade | Enterprise Edition | |
|---|---|---|
| Extração de informações de texto | ✔ | ✔ |
| Multi-idiomas no mesmo banco de dados | ✔ | |
| Construtor de modelos Custom NamendEntityRecognition | ✔ | |
| ConceptNet5 Enriquecedor | ✔ | ✔ |
| Microsoft Concept Enricher | ✔ | ✔ |
| Extração de palavras -chave | ✔ | ✔ |
| Resumo do TexTrank | ✔ | ✔ |
| Extração de tópicos | ✔ | |
| INCLIMENTOS DE PALAVRAS (WORD2VEC) | ✔ | ✔ |
| Computação de similaridade | ✔ | ✔ |
| PDF Parsing | ✔ | ✔ |
| Apache Spark Binding para algoritmos distribuídos | ✔ | |
| Implementação do DOC2VEC | ✔ | |
| Interface do usuário | ✔ | |
| Recursos de previsão de ML | ✔ | |
| Fusão da entidade | ✔ |
Duas implementações do processador PNL estão disponíveis, respectivamente, Stanford PNL e OpenNLP (o OpenNLP recebe atualizações menos frequentes, recomenda -se Stanfordnlp).
Na versão 3.5.1.53.15, você precisa baixar os modelos de idiomas, veja abaixo
No diretório de plug -ins de graxaware, faça o download dos seguintes arquivos jar :
neo4j-framework (o frasco para isso é rotulado como "graxaware-server-a-Enterprise-All")neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download e copie -os no diretório plugins do neo4j.
Cuide -se com o número de versão da estrutura que você está usando com a versão do Neo4J que você está usando . Este é um problema de configuração comum. Por exemplo, se você estiver usando o NEO4J 3.4.0 e acima, todos os frascos que você baixará devem conter 3.4 no número da versão deles.
Exemplo plugins/ diretório:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
Anexe a seguinte configuração no arquivo neo4j.conf no Diretório config/
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
Inicie ou reinicie seu banco de dados NEO4J.
NOTA: Ambos os processadores de texto concreto são bastante gananciosos - você precisará dedicar memória suficiente para o espaço de heap neo4j.
Além disso, os seguintes índices e restrições são sugeridos para acelerar o desempenho:
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
Ou use o procedimento dedicado:
CALL ga.nlp.createSchema()
Defina qual idioma você usará neste banco de dados:
CALL ga.nlp.config.setDefaultLanguage('en')
Depois que a extensão é carregada, você pode ver a documentação básica sobre todos os procedimentos disponíveis executando esta consulta do Cypher:
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
A fase de extração de texto é feita com um pipeline de processamento de linguagem natural, cada pipeline possui uma lista de componentes ativados.
Por exemplo, o oleoduto Basic tokenizer possui os seguintes componentes:
É obrigatório criar seu pipeline primeiro:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
Os parâmetros opcionais disponíveis (os valores padrão estão entre colchetes):
name : Nome desejado de um novo pipelinetextProcessor : ao qual processador de texto se o novo pipeline for adicionadoprocessingSteps : Configuração do pipeline (disponível em Stanford e OpenNLP, a menos que indicado de outra forma)tokenize (padrão: true): execute tokenizaçãoner (padrão: true): reconhecimento de entidade nomeadosentiment (Padrão: Falso): Executar análise de sentimentos em frasescoref (PADRÃO: FALSE): Resolução de Coreferência (Identifique várias menções da mesma entidade, como "Barack Obama" e "He")relations (Padrão: False): Execute a identificação de relações entre dois tokensdependency (padrão: false, somente Stanfordnlp): Extrair dependências digitadas (Ex.: Amod - Modificador Adjetivo, Conjunto - Conjunção, ...)cleanxml (padrão: false, apenas Stanfordnlp): Remova as tags XMLtruecase (padrão: false, apenas Stanfordnlp): reconhece o caso "verdadeiro" de tokens (como eles seriam capitalizados em texto bem editado)customNER : Lista de identificadores de modelo NER personalizados (como uma string, identificadores de modelo separados por ",")stopWords : Especifique palavras que devem ser ignoradas (se a lista começar com +, as seguintes palavras serão anexadas à lista de palavras -parques padrão, caso contrário, a lista padrão será substituída)threadNumber (Padrão: 4): Para multi-threadingexcludedNER : (Padrão: Nenhum) Especifique uma lista de NE para não ser reconhecida na caixa, por exemplo, para excluir NER_Money e NER_O nos nós da tag, use ['O', 'Money']Para definir um pipeline como um pipeline padrão:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
Para excluir um pipeline, use este comando:
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
Para ver detalhes de todos os oleodutos existentes:
CALL ga.nlp.processor.getPipelines()
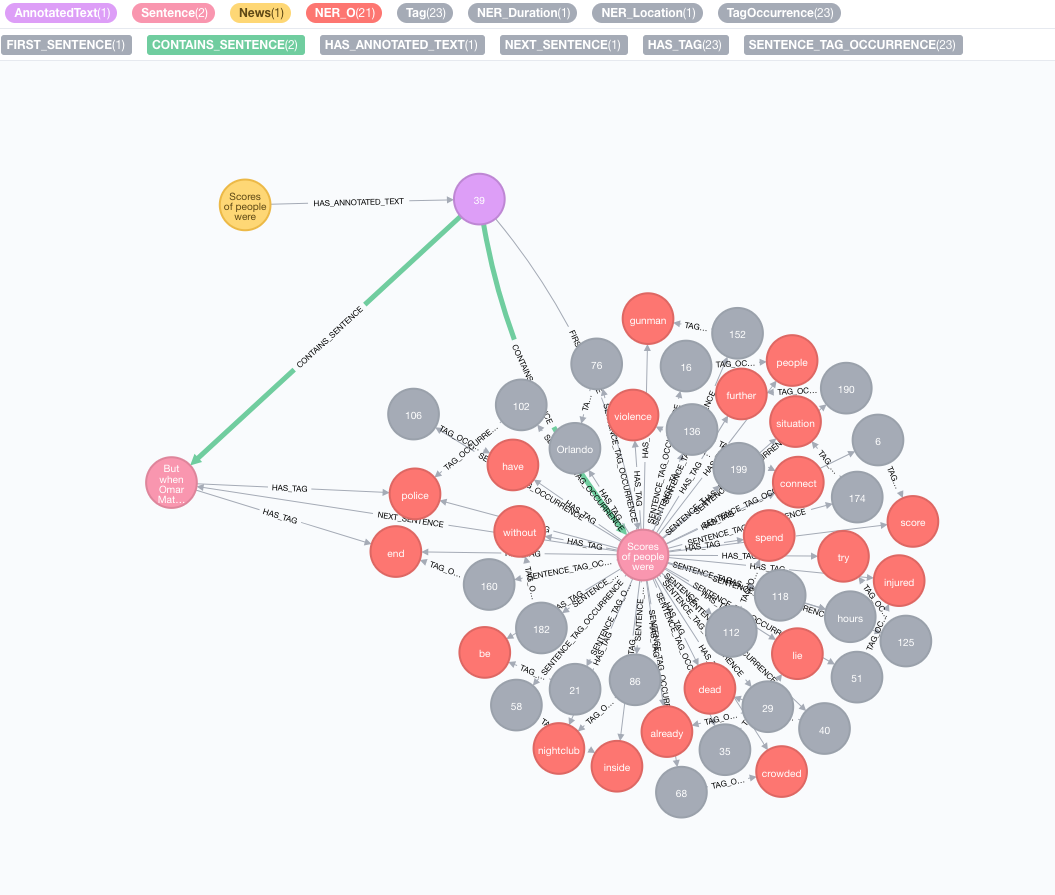
Vamos pegar o seguinte texto como exemplo:
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
Simule seu corpus original
Crie um nó com o texto, este nó representará seu corpus ou gráfico de conhecimento original:
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
Executar a extração de informações de texto
A extração é feita através do procedimento annotate , que é o ponto de entrada para extração de informações de texto
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
Parâmetros disponíveis do procedimento annotate :
text : texto para anotar representado como uma stringid : especifique o ID que será usado como propriedade id do novo nó AnoTatedTexttextProcessor (padrão: "Stanford", se não estiver disponível que a primeira entrada na lista de processadores de texto disponíveis)pipeline (padrão: tokenizer)checkLanguage (padrão: true): Execute a detecção de linguagem no texto fornecido e verifique se é suportado Este procedimento vinculará seu nó original :News a um nó :AnnotatedText , que é o ponto de entrada para o NLP baseado em gráfico dessas notícias específicas. O texto original é dividido em palavras, partes da fala e funções. Essa análise do texto atua como um ponto de partida para as etapas posteriores.
Executando um lote de anotações
Se você tem um grande conjunto de dados para anotar, recomendamos usar o APOC:
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
É importante manter as opções batchSize e iterateList , conforme mencionado no exemplo. A execução do procedimento de anotação em paralelo criará impasse.
Implementamos bases de conhecimento externas para enriquecer o conhecimento de seus dados atuais.
A partir de agora, duas implementações estão disponíveis:
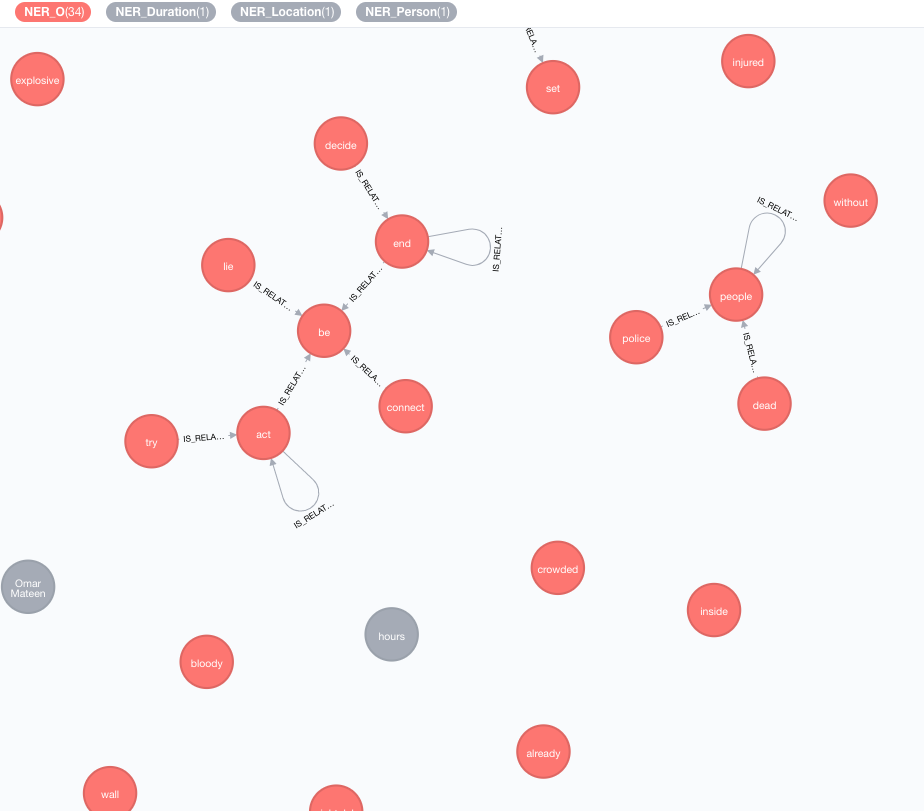
Este enriqueador estenderá o significado dos tokens (nós de tags) no gráfico.
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
Os parâmetros disponíveis (valores padrão estão entre colchetes):
tag : tag a ser enriquecidoenricher ( "conceptnet5" ): escolha microsoft ou conceptnet5depth ( 2 ): Quão profunda na hierarquia conceitualadmittedRelationships : Escolha os tipos de relacionamentos conceitos desejados, consulte a documentação do conceito para obter detalhespipeline : escolha o nome do pipeline a ser usado para limpar conceitos antes de armazená -los no seu banco de dados; O pipeline padrão do seu sistema é usado de outra formafilterByLanguage ( true ): Permitir apenas conceitos de idiomas especificados em outputLanguages ; Se nenhum idioma for especificado, o mesmo idioma que tag será necessáriooutputLanguages ( [] ): retorna apenas conceitos com linguagens especificadasrelDirection ( "out" ): direção desejada dos relacionamentos na hierarquia conceitual ( "in" , "out" , "both" )minWeight ( 0.0 ): Peso de relacionamento conceitual mínimo admitidolimit ( 10 ): Número máximo de conceitos por tagsplitTag ( false ): se true , tag é a primeira tokenizada e depois os tokens individuais enriquecidos As tags têm agora um relacionamento IS_RELATED_TO para outros conceitos enriquecidos.
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText é um parâmetro obrigatório que se refere ao documento anotado que deve ser analisado.
Parâmetros opcionais disponíveis (os valores padrão estão entre colchetes):
keywordLabel (palavra -chave): nome do rótulo dos nós de palavra -chaveuseDependencies (true): use dependências universais para enriquecer palavras -chave extraídas e frases -chave por tags relacionadas através de relacionamentos compostos e amoddependenciesGraph (false): use dependências universais para criar o gráfico de co-ocorrência de tags (o padrão é falso, o que significa que um fluxo de palavras natural é usado para a construção de co-ocorrências)cleanKeywords (True): Execute o procedimento de limpezatopXTags (1/3): Defina uma fração das tags mais altas que serão usadas como palavras-chave / frases-chaverespectSentences (FALSE): Respeito ou não Limites da frase para a construção de gráficos de co-ocorrênciarespectDirections (FALSO): Respeito ou não direções no gráfico de co-ocorrência (como as palavras se seguem)iterations (30): Número de iterações do PageRankdamp (0,85): fator de amortecimento do PageRankthreshold (0,0001): limiar de convergência PageRankremoveStopwords (true): use uma lista de palavras de parada para construção de gráficos de co-ocorrência e limpeza final de palavras-chavestopwords : Personalize Stopwords List (se a lista começar com + , as seguintes palavras serão anexadas à lista de palavras de parada padrão, caso contrário, a lista padrão será substituída)admittedPOSs : Especifique quais etiquetas POS são consideradas candidatos a palavras -chave; necessário ao usar idioma diferente do inglêsforbiddenPOSs : Especifique a lista dos rótulos do POS a ser ignorada ao construir o gráfico de co-ocorrência; necessário ao usar idioma diferente do inglêsforbiddenNEs : especifique a lista de NES a ser ignorada Para uma descrição detalhada do algoritmo TextRank , consulte nossa postagem no blog sobre extração de palavras -chave não supervisionada.
O uso de dependências universais para enriquecimento de palavras -chave (opção useDependencies ) pode resultar em palavras -chave com nível de detalhe desnecessário, por exemplo, um programa de logística de ônibus espacial de palavras -chave. Em muitos casos de uso, podemos estar interessados em saber também que, dado o documento, fala geralmente sobre o ônibus espacial (ou programa logístico ). Para fazer isso, execute o pós-processamento com uma dessas opções:
direct - cada frase -chave de N número de tags é verificada em todas as frases -chave de todos os documentos com 1 <m <n número de tags; Se o primeiro contém a última frase -chave, um relacionamento DESCRIBES é criado a partir da m -Keyphrase para todos os textos anotados da N -Keyphrasesubgroups - O mesmo procedimento que para direct , mas, em vez de conectar palavras -chave de nível superior diretamente aos textos anotados , eles estão conectados às palavras -chave de nível inferior com relacionamentos HAS_SUBGROUP // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel é um argumento opcional definido por padrão para "palavra -chave" .
A operação pós -processo por padrão está processando em todas as palavras -chave, que podem ser muito pesadas em gráficos grandes. Você pode especificar o ANOTATATATETTEXT no qual aplicar a operação pós -processo com o argumento annotatedText :
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
Exemplo para executá -lo com eficiência em todo o conjunto de palavras -chave com o APOC:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
Abordagem semelhante à extração de palavras -chave pode ser empregada para implementar a sumarização simples. Um gráfico densamente conectado de frases é criado, com relacionamentos de frase-frase representando sua semelhança com base em palavras compartilhadas (número de palavras compartilhadas versus soma dos logaritmos de número de palavras em uma frase). O PageRank é então usado como uma medida de centralidade para classificar a importância relativa das frases no documento.
Para executar este algoritmo:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
Parâmetros disponíveis:
annotatedTextiterations (30): Número de iterações do PageRankdamp (0,85): fator de amortecimento do PageRankthreshold (0,0001): limiar de convergência PageRank O procedimento de resumo economiza novas propriedades para os nós da sentença: summaryRelevance (valor do PageRank da determinada sentença) e summaryRank (classificação; 1 = sentença mais bem classificada). Exemplo de consulta para recuperar o resumo:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
Você também pode determinar se o texto apresentado é positivo, negativo ou neutro. Este procedimento requer um nó AnoTatedText, produzido por ga.nlp.annotate acima.
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
Esse procedimento simplesmente retornará "sucesso" quando for bem -sucedido, mas aplicará o :POSITIVE ,: :NEUTRAL ou :NEGATIVE a cada frase. Como resultado, quando a detecção de sentimentos é concluída, você pode consultar o sentimento de sentenças como tal:
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
Depois que as tags são extraídas de todas as notícias ou outros nós que contêm algum texto, é possível calcular semelhanças entre elas usando similaridade baseada em conteúdo. Durante esse processo, cada texto anotado é descrito usando o formato de codificação TF-IDF. O TF-IDF é uma técnica estabelecida do campo de recuperação de informações e significa frequência de frequência a termo frequência de documentos. Os documentos de texto podem ser TF-IDF codificados como vetores em um espaço euclidiano multidimensional. As dimensões do espaço correspondem às tags, anteriormente extraídas dos documentos. As coordenadas de um determinado documento em cada dimensão (isto é, para cada tag) são calculadas como um produto de dois sub-medidas: frequência a termo e frequência inversa de documentos.
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
Parâmetros disponíveis (valores padrão estão entre colchetes):
input : Lista de nós de entrada - ANNOTATATETTEXTSrelationshipType (similarity_cosine): tipo de relação de similaridade, use -o junto com queryquery : especifique sua própria consulta para extrair TF e IDF em forma ... RETURN id(Tag), tf, idfpropertyName (Value): Nome de uma propriedade Node existente (matriz de valores numéricos) que contém vetor de documento já preparadoO Word2vec é um modelo de rede neural de duas camadas superficial usado para produzir incorporações de palavras (palavras representadas como vetores semânticos multidimensionais) e é um dos modelos usados no NumBatch do conceito.
Para adicionar o modelo de origem (vetores) em um índice Lucene
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir> é um caminho completo para o diretório com vetores de origem a serem indexados<path_to_index> é um caminho completo onde o índice será armazenado<identifier> é uma string personalizada que identifica exclusivamente o modeloPara listar os modelos disponíveis:
CALL ga.nlp.ml.word2vec.listModels
O modelo agora pode ser usado para calcular semelhanças de cosseno entre palavras:
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
Ou você pode pedir diretamente um Word2Vec de um nó que tenha uma palavra armazenada no value da propriedade:
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
Também podemos armazenar permanentemente os vetores Word2vec para marcar nós:
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query : consulta que retorna tags às quais os vetores incorporados devem ser anexadosmodelName : Model to UseVocê também pode obter os vizinhos mais próximos com o seguinte procedimento:
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
Para modelos grandes, por exemplo, FastText completo para o inglês, aproximadamente 2 milhões de palavras, será ineficiente calcular os vizinhos mais próximos em tempo real.
Você pode carregar o modelo na memória para ter vizinhos mais rápidos mais rápidos (os vetores de palavras de 1M de 1M geralmente leva 27 segundos, se necessário, para ler do disco, ~ 300ms na memória):
Certifique -se de ter memória de heap eficiente dedicada ao neo4J:
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
Carregue o modelo na memória:
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
E recuperá -lo com
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
Você pode usar qualquer modelo de incorporação de palavras, desde que o seguinte seja verdadeiro:
.txt Por exemplo, você pode carregar os modelos do FastText e apenas renomear o arquivo de .vec para .txt : https://fasttext.cc/docs/en/english-vectors.html
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
O procedimento retorna linhas com number das colunas sendo o número da página e paragraphs sendo uma List<String> dos textos do parágrafo.
Você também pode passar um URL http ou https para o procedimento para carregar um arquivo de um local remoto.
Em alguns casos, os documentos em PDF têm algum conteúdo inútil recorrente, como os rodapés da página etc.
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
Tika pode ser reconhecido como rastreador e ter acesso negado a alguns sites que contêm PDFs. Você pode substituir isso passando por uma opção UserAgent :
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
Em certas situações, seria útil armazenar apenas certos valores em vez do gráfico completo, observe que isso poderia reduzir a capacidade de extrair insights (Textrank) para por exemplo:
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
Webvtt é o formato para faixas de texto em vídeo da web, como transcrições do YouTube de vídeos: https://fr.wikipedia.org/wiki/webvtt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Os arquivos da lista de procedimentos acima apenas do diretório atual, se você precisar percorrer os diretórios infantis também, use walkdir :
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
Lista de modelos armazenados e seus caminhos
Remova e recrie um pipeline com a mesma configuração (útil ao usar arquivos NER estáticos que foram alterados para por exemplo)
Copyright (c) 2013-2019 grapague
O grapaware é um software livre: você pode redistribuí -lo e/ou modificá -lo nos termos da licença pública geral da GNU, conforme publicado pela Free Software Foundation, versão 3 da licença ou (por sua opção) qualquer versão posterior. Este programa é distribuído na esperança de que seja útil, mas sem garantia; sem a garantia implícita de comercialização ou aptidão para uma finalidade específica. Veja a licença pública geral da GNU para obter mais detalhes. Você deveria ter recebido uma cópia da licença pública geral da GNU junto com este programa. Caso contrário, consulte http://www.gnu.org/license/.


