neo4j nlp
1.0.0
2021年5月現在、このリポジトリは廃止されました。
このNEO4Jプラグインは、グラフベースの自然言語処理機能を提供します。
メインモジュールであるこのモジュールは、基礎となるテキストプロセッサの共通インターフェイスと、自然言語処理ワークフロー開発者に優しいものにするストアドプロシージャと機能の上に構築されたドメイン固有言語を提供します。
次のNLP機能を備えたコミュニティ(オープンソース)とエンタープライズの2つのバージョンがあります。
| コミュニティ版 | エンタープライズエディション | |
|---|---|---|
| テキスト情報抽出 | ✔ | ✔ |
| 同じデータベース内の多言語 | ✔ | |
| Custom AngiantEntityRecognition Model Builder | ✔ | |
| ConceptNet5 Enricher | ✔ | ✔ |
| Microsoft Concept Enricher | ✔ | ✔ |
| キーワード抽出 | ✔ | ✔ |
| テキストランの要約 | ✔ | ✔ |
| トピック抽出 | ✔ | |
| 単語埋め込み(word2vec) | ✔ | ✔ |
| 類似性計算 | ✔ | ✔ |
| PDF解析 | ✔ | ✔ |
| 分散アルゴリズムのApache Sparkバインディング | ✔ | |
| DOC2VEC実装 | ✔ | |
| ユーザーインターフェイス | ✔ | |
| ML予測機能 | ✔ | |
| エンティティの合併 | ✔ |
それぞれStanford NLPとOpenNLP(OpenNLPの更新が少ない、StanfordNLPが推奨される)の2つのNLPプロセッサの実装が利用可能です。
バージョン3.5.1.53.15から言語モデルをダウンロードする必要があります。以下を参照してください
GraphAwareプラグインディレクトリから、次のjarファイルをダウンロードしてください。
neo4j-framework (これの瓶には「graphaware-server-enterprise-all」とラベル付けされています)neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#downloadからダウンロードされる言語モデルNEO4Jのpluginsディレクトリにそれらをコピーします。
使用しているフレームワークのバージョン番号が、使用しているNEO4Jのバージョンと一致することに注意してください。これは一般的なセットアップの問題です。たとえば、NEO4J 3.4.0以降を使用している場合、ダウンロードするすべてのJARはバージョン番号に3.4を含める必要があります。
plugins/ディレクトリの例:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
config/ directoryのneo4j.confファイルに次の構成を追加します。
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
NEO4Jデータベースを起動または再起動します。
注:両方の具体的なテキストプロセッサは非常に貪欲です - NEO4Jヒープスペースに十分なメモリを捧げる必要があります。
さらに、パフォーマンスを高速化するために、次のインデックスと制約が提案されています。
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
または、専用の手順を使用します。
CALL ga.nlp.createSchema()
このデータベースで使用する言語を定義します。
CALL ga.nlp.config.setDefaultLanguage('en')
拡張機能がロードされたら、このCypherクエリを実行することにより、利用可能なすべての手順に関する基本的なドキュメントを確認できます。
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
テキスト抽出段階は、自然言語処理パイプラインで行われ、各パイプラインには有効なコンポーネントのリストがあります。
たとえば、基本的なtokenizerパイプラインには次のコンポーネントがあります。
最初にパイプラインを作成することは必須です:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
利用可能なオプションのパラメーター(デフォルト値はブラケットにあります):
name :新しいパイプラインの希望の名前textProcessor :新しいパイプラインを追加するテキストプロセッサーにprocessingSteps :パイプライン構成(特に明記しない限りStanfordとOpenNLPの両方で利用可能)tokenize (デフォルト:真):トークン化を実行しますner (デフォルト:TRUE):名前付きエンティティ認識sentiment (デフォルト:false):文でセンチメント分析を実行しますcoref (デフォルト:false):Coreference Resolution(「Barack Obama」や「He」など、同じエンティティの複数の言及を特定)relations (デフォルト:false):2つのトークン間の関係識別を実行しますdependency (デフォルト:false、stanfordnlpのみ):抽出型依存関係(例:amod -amod-形容詞修飾子、conj-接続詞、...)cleanxml (デフォルト:false、stanfordnlpのみ):XMLタグを削除しますtruecase (デフォルト:false、stanfordnlpのみ):トークンの「真の」ケースを認識します(編集されたテキストでどのように大文字になりますか)customNER :カスタムNERモデル識別子のリスト(文字列、「」で区切られたモデル識別子として)stopWords :無視する必要がある単語を指定します(リストが +で始まる場合、次の単語はデフォルトのstopwordsリストに追加され、それ以外の場合はデフォルトのリストが上書きされます)threadNumber (デフォルト:4):マルチスレッド用excludedNER :(デフォルト:なし)タグノードでNER_MoneyとNER_O除外するなど、neのリストを上品で認識しないように指定します。パイプラインをデフォルトのパイプラインとして設定するには:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
パイプラインを削除するには、このコマンドを使用します。
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
既存のすべてのパイプラインの詳細を確認するには:
CALL ga.nlp.processor.getPipelines()
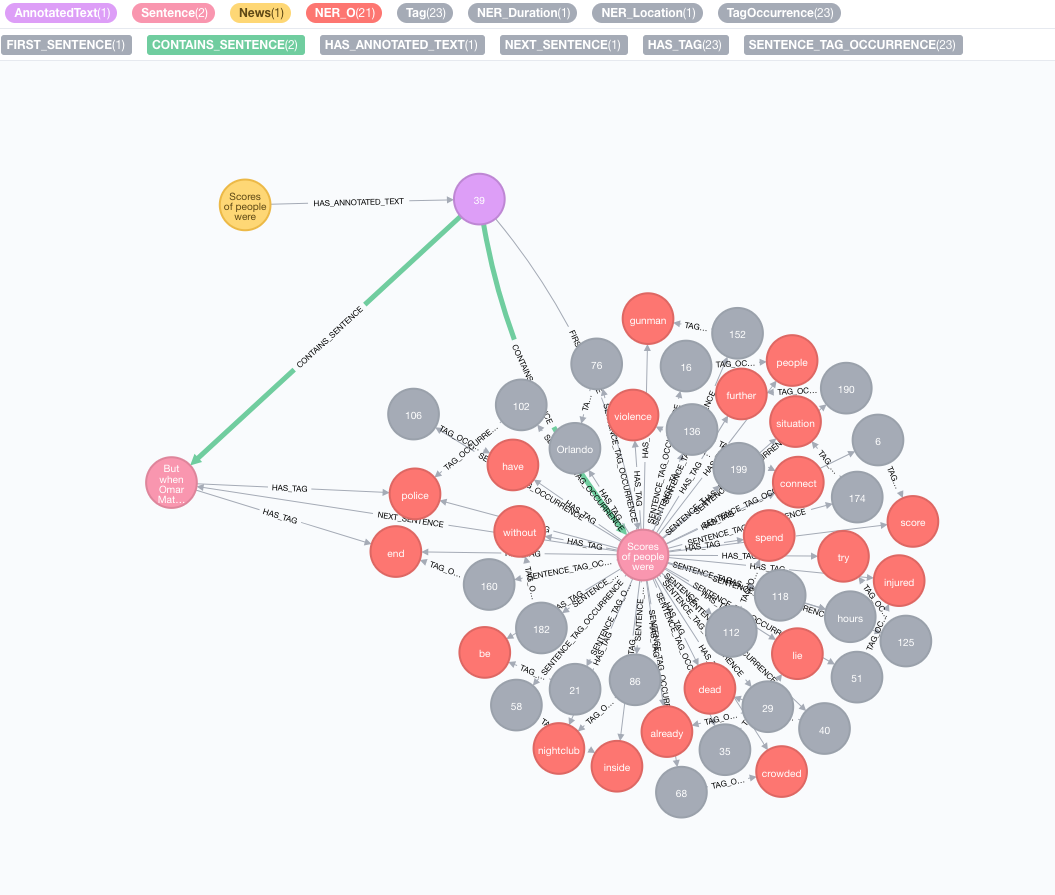
例として、次のテキストを取り上げましょう。
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
元のコーパスをシミュレートします
テキストでノードを作成すると、このノードは元のコーパスまたはナレッジグラフを表します。
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
テキスト情報抽出を実行します
抽出は、テキスト情報抽出へのエントリポイントであるannotate手順を介して行われます
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
annotate手順の利用可能なパラメーター:
text :文字列として表される注釈へのテキストid :新しいAnnotatedTextノードのidプロパティとして使用されるIDを指定しますtextProcessor (デフォルト:「スタンフォード」、利用可能なテキストプロセッサのリストの最初のエントリよりも利用できない場合)pipeline (デフォルト:トークンザー)checkLanguage (デフォルト:true):提供されたテキストで言語検出を実行し、サポートされているかどうかを確認しますこの手順は、元の:NewsノードをAN :AnnotatedTextノードにリンクします。これは、この特定のニュースのグラフベースのNLPのエントリポイントです。元のテキストは、言葉、音声の一部、機能に分類されます。このテキストの分析は、後の手順の出発点として機能します。
注釈のバッチを実行します
注釈を付けるための大きなデータセットがある場合は、APOCを使用することをお勧めします。
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
この例に記載されているように、 batchSizeとiterateListオプションを維持することが重要です。注釈手順を並行して実行すると、デッドロックが作成されます。
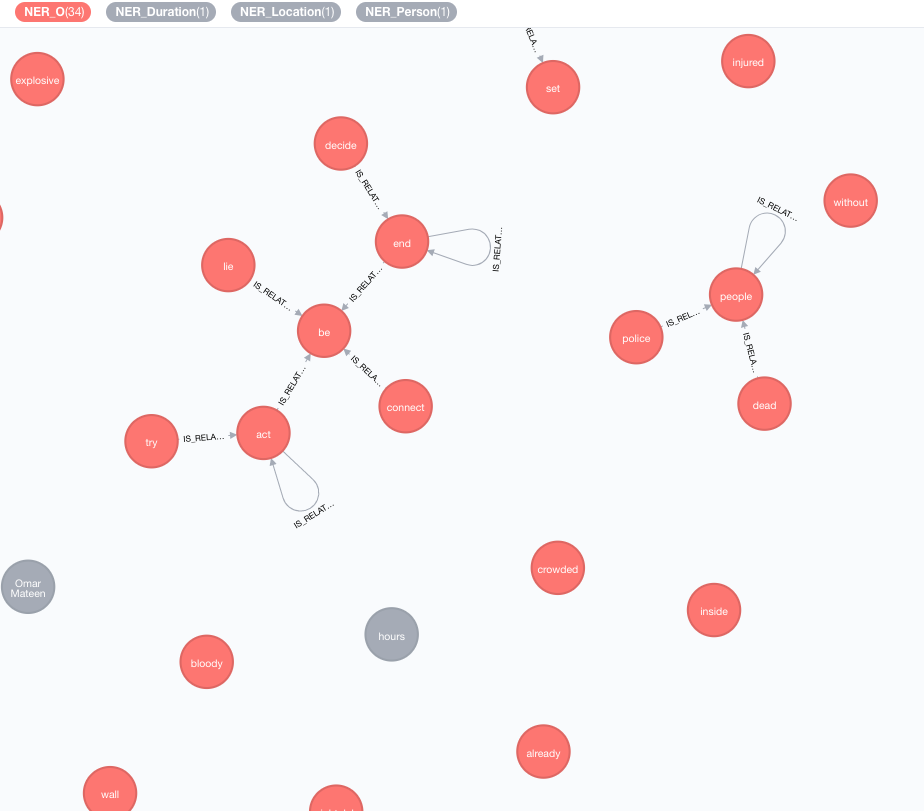
現在のデータの知識を豊かにするために、外部の知識ベースを実装します。
現在のところ、2つの実装が利用可能です。
この濃縮機は、グラフのトークン(タグノード)の意味を拡張します。
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
使用可能なパラメーター(デフォルト値はブラケットにあります):
tag :濃縮されるタグenricher ( "conceptnet5" ): microsoftまたはconceptnet5選択しますdepth ( 2 ):コンセプトの階層にどのように深く入るかadmittedRelationships :希望の概念関係タイプを選択してください。詳細については、ConceptNetドキュメントを参照してくださいpipeline :DBに保存する前に、コンセプトのクレンジングに使用するパイプライン名を選択します。それ以外の場合は、システムのデフォルトパイプラインが使用されますfilterByLanguage ( true ): outputLanguagesで指定された言語の概念のみを許可します。言語が指定されていない場合、 tagと同じ言語が必要ですoutputLanguages ( [] ):指定された言語で概念のみを返すrelDirection ( "out" ):コンセプト階層における関係の望ましい方向( "in" 、 "out" 、 "both" )minWeight ( 0.0 ):最小限の認められた概念関係の重みlimit ( 10 ): tagごとの概念の最大数splitTag ( false ): trueの場合、 tagは最初にトークン化され、次に個々のトークンが濃縮されますタグには、他の充実した概念との関係がIS_RELATED_TOなりました。
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText 、分析する必要がある注釈付きドキュメントを指す必須パラメーターです。
使用可能なオプションパラメーター(デフォルト値はブラケットにあります):
keywordLabel (キーワード):キーワードノードのラベル名useDependencies (True):普遍的な依存関係を使用して、化合物とAMOD関係を介して関連するタグによって抽出されたキーワードとキーフレーズを豊かにするdependenciesGraph (false):タグ共起グラフを作成するためにユニバーサル依存関係を使用します(デフォルトはfalseです。つまり、自然な単語の流れが共起の構築に使用されます)cleanKeywords (true):クリーニング手順を実行しますtopXTags (1/3):キーワード /キーフレーズとして使用される最高評価のタグの一部を設定しますrespectSentences (虚偽):共起グラフビルディングの尊重かどうかrespectDirections (虚偽):共起グラフの方向性と尊敬の尊重(単語がどのように続くか)iterations (30):ページランクの反復の数damp (0.85):Pagerank Damping Factorthreshold (0.0001):Pagerank Convergenceしきい値removeStopwords (True):共起グラフの構築とキーワードの最終クリーニングにはStopwordsリストを使用しますstopwords :stopwordsリストのカスタマイズ(リストが+で始まる場合、次の単語がデフォルトのstopwordsリストに追加され、それ以外の場合はデフォルトのリストが上書きされます)admittedPOSs :キーワード候補と見なされるPOSラベルを指定します。英語とは異なる言語を使用するときに必要ですforbiddenPOSs :共起グラフを構築するときに無視するPOSラベルのリストを指定します。英語とは異なる言語を使用するときに必要ですforbiddenNEs :無視するNEのリストを指定します詳細なTextRankアルゴリズムの説明については、監視されていないキーワード抽出に関するブログ投稿を参照してください。
キーワードエンリッチメントにユニバーサル依存関係を使用すると( useDependenciesオプション)、不必要なレベルの詳細を備えたキーワード、たとえばキーワードスペースシャトルロジスティクスプログラムになります。多くのユースケースでは、ドキュメントが一般的にスペースシャトル(またはロジスティックプログラム)について話していることも知ることに興味があるかもしれません。それを行うには、これらのオプションのいずれかで後処理を実行します。
direct - nタグ数の各キーフレーズは、1 <m <nタグ数を持つすべてのドキュメントのすべてのキーフレーズに対してチェックされます。前者に後者のキーフレーズが含まれている場合、 n keyphraseのすべての注釈付きテキストにmキープDESCRIBESから関係が作成されます。subgroups - directと同じ手順ですが、より高いレベルのキーワードをAnnotatedTextsに直接接続する代わりに、 HAS_SUBGROUP関係を持つ低レベルのキーワードに接続されています // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel 、デフォルトで「キーワード」に設定されたオプションの引数です。
デフォルトでのポストプロセス操作は、すべてのキーワードで処理されています。これは、大きなグラフで非常に重い場合があります。 annotatedText引数でポストプロセス操作を適用するためのAnnotatedTextを指定できます。
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
APOCを使用したキーワードの完全なセットで効率的に実行する例:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
キーワード抽出に対する同様のアプローチを使用して、簡単な要約を実装できます。文の密に接続されたグラフが作成され、共有単語(共有単語の数と文の単語数の合計の合計)に基づいて類似性を表す文センテンス関係が作成されます。 Pagerankは、文書内の文の相対的な重要性をランク付けするために、中心性尺度として使用されます。
このアルゴリズムを実行するには:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
利用可能なパラメーター:
annotatedTextiterations (30):ページランクの反復の数damp (0.85):Pagerank Damping Factorthreshold (0.0001):Pagerank Convergenceしきい値要約手順により、新しいプロパティを文ノードに保存します: summaryRelevance (指定された文のpagerank値)およびsummaryRank (ランキング; 1 =最高ランクの文)。概要を取得するためのクエリの例:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
また、提示されたテキストが正、負、またはニュートラルであるかどうかを判断することもできます。この手順には、上記のga.nlp.annotateによって生成されるAnnotatedTextノードが必要です。
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
この手順は、成功したときに「成功」を返すだけですが、各文には:POSITIVE 、 :NEUTRAL 、または:NEGATIVEラベルを適用します。その結果、センチメントの検出が完了した場合、次のような文章の感情を照会できます。
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
いくつかのテキストを含むすべてのニュースまたは他のノードからタグが抽出されると、コンテンツベースの類似性を使用して、それらの間で類似性を計算することができます。このプロセス中、各注釈付きテキストは、TF-IDFエンコード形式を使用して説明されています。 TF-IDFは、情報検索の分野から確立された手法であり、用語の周波数逆ドキュメント頻度を表しています。テキストドキュメントは、多次元ユークリッド空間のベクトルとしてTF-IDFをエンコードできます。空間寸法は、以前にドキュメントから抽出されたタグに対応しています。各ディメンションの特定のドキュメントの座標(つまり、各タグに対して)は、ターム周波数と逆ドキュメント頻度の2つのサブメジャーの積として計算されます。
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
使用可能なパラメーター(デフォルト値はブラケットにあります):
input :入力ノードのリスト-AnnotatedTextsrelationshipType (類似性_cosine):類似性関係のタイプ、 queryと一緒に使用してくださいquery : TFとIDFをフォームで抽出するための独自のクエリを指定します... RETURN id(Tag), tf, idfpropertyName (値):既存のドキュメントベクトルを含む既存のノードプロパティ(数値値の配列)の名前word2vecは、単語の埋め込み(多次元セマンティックベクターとして表される単語)を生成するために使用される浅い2層ニューラルネットワークモデルであり、コンセプトネット番号バッチで使用されるモデルの1つです。
ソースモデル(ベクトル)をLuceneインデックスに追加します
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir>は、インデックス化されるソースベクトルを備えたディレクトリへのフルパスです<path_to_index>は、インデックスが保存されるフルパスです<identifier>モデルを一意に識別するカスタム文字列です利用可能なモデルをリストするには:
CALL ga.nlp.ml.word2vec.listModels
モデルを使用して、単語間のコサインの類似性を計算することができます。
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
または、プロパティvalueにWordが保存されているノードのWord2vecを直接尋ねることができます。
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
Word2Vecベクトルを恒久的に保存することもできます。
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query :埋め込みベクターを添付するタグを返すクエリmodelName :使用するモデルまた、次の手順で最近隣人を取得することもできます。
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
大規模なモデル、たとえば英語の完全なファストテキストの場合、約200万語では、その場で最も近い隣人を計算することは非効率的です。
モデルをメモリにロードして、より高速な最近の隣人を持つことができます(FastText 1Mワードベクトルは通常、ディスクから読むのに必要な場合は27秒かかり、メモリは約300ms):
NEO4Jに特化した効率的なヒープメモリを必ず用意してください。
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
モデルをメモリにロードします。
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
そしてそれを取得します
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
以下が真である限り、任意の単語埋め込みモデルを使用できます。
.txt拡張子がありますたとえば、モデルをFastTextからロードして、 .vecから.txt :https://fasttext.cc/docs/en/english-vectors.htmlにファイルを変更するだけです。
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
手順は、列numberがページ番号であり、 paragraphs段落テキストのList<String>文字列>であるという行を返す行を返します。
また、 httpまたはhttps URLをリモートの場所からファイルをロードする手順に渡すこともできます。
場合によっては、PDFドキュメントには、ページフッターなどの繰り返し役に立たないコンテンツがあり、除外するように部品を定義する正規表現のリストを渡すことで、解析から除外できます。
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
ティカはクローラーとして認識され、PDFを含むいくつかのサイトへのアクセスを拒否されます。 UserAgentオプションを渡すことで、これをオーバーライドできます。
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
特定の状況では、完全なグラフの代わりに特定の値のみを保存することは有用ですが、例:例えば、洞察(テキストラン)を抽出する能力が低下する可能性があることに注意してください。
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
WebVTTは、ビデオのYouTubeトランスクリプトなど、Webビデオテキストトラックの形式です:https://fr.wikipedia.org/wiki/webvtt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
上記の手順は、現在のディレクトリのファイルをリストします。子供のディレクトリも散歩する必要がある場合は、 walkdirを使用してください。
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
保存されたモデルとそのパスをリストします
同じ構成でパイプラインを削除して再作成します(例えば変更された静的NERファイルを使用する場合に役立ちます)
Copyright(c)2013-2019 Graphaware
GraphAwareはフリーソフトウェアです。FreeSoftware Foundationが公開しているGNU General Publicライセンスの条件、ライセンスのバージョン3、または(オプションで)後のバージョンのいずれかで公開されているように、それを再配布したり、変更したりできます。このプログラムは、それが有用であることを期待して配布されますが、保証はありません。商品性や特定の目的に対するフィットネスの暗黙の保証さえありません。詳細については、GNU一般公開ライセンスを参照してください。このプログラムとともに、GNU一般公開ライセンスのコピーを受け取る必要があります。そうでない場合は、http://www.gnu.org/licenses/を参照してください。


