neo4j nlp
1.0.0
ณ เดือนพฤษภาคม 2564 ที่เก็บนี้ได้รับการเกษียณแล้ว
ปลั๊กอิน Neo4J นี้มีความสามารถในการประมวลผลภาษาธรรมชาติที่ใช้กราฟ
โมดูลหลักคือโมดูลนี้จัดเตรียมอินเทอร์เฟซทั่วไปสำหรับตัวประมวลผลข้อความพื้นฐานรวมถึง ภาษาเฉพาะโดเมน ที่สร้างขึ้นบนขั้นตอนและฟังก์ชั่นที่เก็บไว้ซึ่งทำให้นักพัฒนาระบบการประมวลผลภาษาธรรมชาติของคุณเป็นมิตร
มันมาใน 2 เวอร์ชันชุมชน (โอเพ่นซอร์ส) และองค์กรที่มีคุณสมบัติ NLP ต่อไปนี้:
| รุ่นชุมชน | Enterprise Edition | |
|---|---|---|
| การสกัดข้อมูลข้อความ | ||
| หลายภาษาในฐานข้อมูลเดียวกัน | ||
| ตัวสร้างโมเดลที่กำหนดชื่อ | ||
| ConceptNet5 Enricher | ||
| Microsoft Concept Enricher | ||
| การสกัดคำหลัก | ||
| การสรุป Textrank | ||
| การสกัดหัวข้อ | ||
| Word Embeddings (Word2Vec) | ||
| การคำนวณความคล้ายคลึงกัน | ||
| การแยกวิเคราะห์ PDF | ||
| Apache Spark ผูกพันสำหรับอัลกอริทึมแบบกระจาย | ||
| การใช้งาน doc2vec | ||
| ส่วนต่อประสานผู้ใช้ | ||
| ความสามารถในการทำนาย ML | ||
| การรวมกิจการ |
มีการใช้งานโปรเซสเซอร์ NLP สองตัวตามลำดับ Stanford NLP และ OpenNLP (OpenNLP ได้รับการอัปเดตน้อยกว่าบ่อยครั้งแนะนำให้ใช้ StanfordNLP)
จากเวอร์ชัน 3.5.1.53.15 คุณต้องดาวน์โหลดโมเดลภาษาดูด้านล่าง
จากไดเร็กทอรีกราฟีวาร์ปลั๊กอินดาวน์โหลดไฟล์ jar ต่อไปนี้:
neo4j-framework (jar สำหรับสิ่งนี้มีป้ายกำกับ "graphaware-server-enterprise-all")))neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download และคัดลอกในไดเรกทอรี plugins ของ Neo4J
ระวังว่าหมายเลขเวอร์ชันของเฟรมเวิร์กที่คุณใช้การจับคู่กับเวอร์ชันของ Neo4J ที่คุณใช้ นี่เป็นปัญหาการตั้งค่าทั่วไป ตัวอย่างเช่นหากคุณใช้ Neo4J 3.4.0 ขึ้นไปขวดทั้งหมดที่คุณดาวน์โหลดควรมี 3.4 ในหมายเลขเวอร์ชันของพวกเขา
plugins/ ไดเรกทอรีตัวอย่าง:
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
ผนวกการกำหนดค่าต่อไปนี้ในไฟล์ neo4j.conf ใน config/ directory:
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
เริ่มต้นหรือรีสตาร์ทฐานข้อมูล Neo4J ของคุณ
หมายเหตุ: โปรเซสเซอร์ข้อความคอนกรีตทั้งสองค่อนข้างโลภ - คุณจะต้องอุทิศหน่วยความจำที่เพียงพอสำหรับพื้นที่ Neo4J heap
นอกจากนี้ดัชนีและข้อ จำกัด ดังต่อไปนี้จะแนะนำให้เพิ่มประสิทธิภาพการทำงาน:
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
หรือใช้ขั้นตอนเฉพาะ:
CALL ga.nlp.createSchema()
กำหนดภาษาที่คุณจะใช้ในฐานข้อมูลนี้:
CALL ga.nlp.config.setDefaultLanguage('en')
เมื่อโหลดส่วนขยายแล้วคุณจะเห็นเอกสารพื้นฐานเกี่ยวกับขั้นตอนที่มีอยู่ทั้งหมดโดยเรียกใช้ Cypher Query นี้:
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
ขั้นตอนการสกัดข้อความทำด้วยท่อประมวลผลภาษาธรรมชาติแต่ละท่อมีรายการของส่วนประกอบที่เปิดใช้งาน
ตัวอย่างเช่นไปป์ไลน์ tokenizer พื้นฐานมีส่วนประกอบดังต่อไปนี้:
เป็นข้อบังคับในการสร้างท่อของคุณก่อน:
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
พารามิเตอร์ตัวเลือกที่มีอยู่ (ค่าเริ่มต้นอยู่ในวงเล็บ):
name : ชื่อที่ต้องการของไปป์ไลน์ใหม่textProcessor : ตัวประมวลผลข้อความใดที่ควรเพิ่มไปป์ไลน์ใหม่processingSteps : การกำหนดค่าไปป์ไลน์ (มีอยู่ในทั้ง Stanford และ OpenNLP เว้นแต่จะระบุไว้เป็นอย่างอื่น)tokenize (ค่าเริ่มต้น: จริง): ดำเนินการ tokenizationner (ค่าเริ่มต้น: จริง): การจดจำเอนทิตีชื่อsentiment (ค่าเริ่มต้น: เท็จ): เรียกใช้การวิเคราะห์ความเชื่อมั่นในประโยคcoref (ค่าเริ่มต้น: false): การแก้ไข coreFerence (ระบุหลายคำกล่าวของเอนทิตีเดียวกันเช่น "Barack Obama" และ "เขา")relations (ค่าเริ่มต้น: เท็จ): เรียกใช้การระบุความสัมพันธ์ระหว่างสองโทเค็นdependency (ค่าเริ่มต้น: false, stanfordnlp เท่านั้น): แยกการพึ่งพาที่พิมพ์ (เช่น: Amod - Adjective Modifier, Conn - Connction, ... )cleanxml (ค่าเริ่มต้น: false, stanfordnlp เท่านั้น): ลบแท็ก xmltruecase (ค่าเริ่มต้น: FALSE, StanfordNLP เท่านั้น): รับรู้กรณี "จริง" ของโทเค็น (วิธีที่พวกเขาจะเป็นตัวพิมพ์ใหญ่ในข้อความที่ได้รับการแก้ไขอย่างดี)customNER : รายการตัวระบุโมเดลที่กำหนดเอง (เป็นสตริงตัวระบุโมเดลคั่นด้วย“,”)stopWords : ระบุคำที่จำเป็นต้องถูกละเว้น (หากรายการเริ่มต้นด้วย +คำต่อไปนี้จะถูกผนวกเข้ากับรายการคำสั่งหยุดเริ่มต้นมิฉะนั้นรายการเริ่มต้นจะถูกเขียนทับ)threadNumber (ค่าเริ่มต้น: 4): สำหรับมัลติเธรดexcludedNER : (ค่าเริ่มต้น: ไม่มี) ระบุรายการของ NE ที่จะไม่ได้รับการยอมรับในกรณีบนตัวอย่างเช่นการยกเว้น NER_Money และ NER_O บนโหนดแท็กใช้ ['o', 'money']ในการตั้งค่าไปป์ไลน์เป็นไปป์ไลน์เริ่มต้น:
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
ในการลบไปป์ไลน์ให้ใช้คำสั่งนี้:
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
เพื่อดูรายละเอียดของท่อส่งที่มีอยู่ทั้งหมด:
CALL ga.nlp.processor.getPipelines()
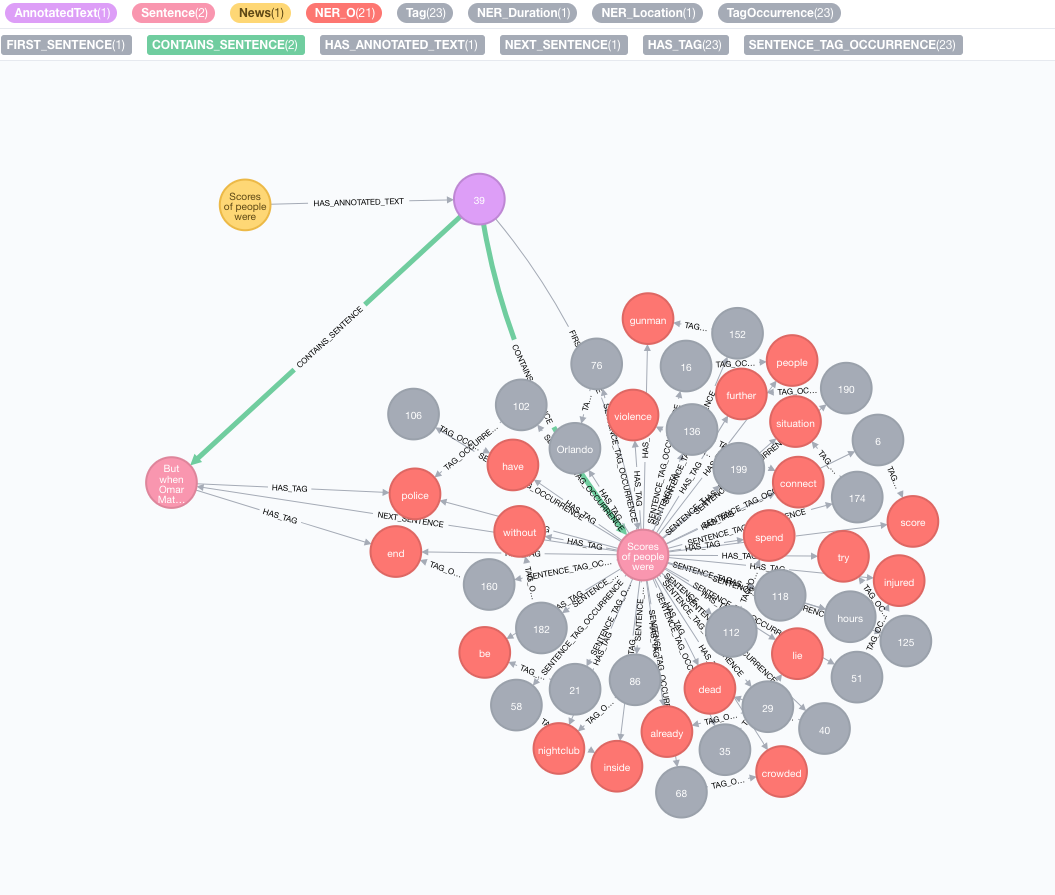
ลองใช้ข้อความต่อไปนี้เป็นตัวอย่าง:
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
จำลองคลังข้อมูลดั้งเดิมของคุณ
สร้างโหนดด้วยข้อความโหนดนี้จะเป็นตัวแทนของคลังข้อมูลดั้งเดิมหรือกราฟความรู้ของคุณ:
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
ทำการแยกข้อมูลข้อความ
การสกัดจะทำผ่านขั้นตอน annotate ซึ่งเป็นจุดเข้าสู่การสกัดข้อมูลข้อความ
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
พารามิเตอร์ที่มีอยู่ของขั้นตอน annotate ประกอบ:
text : ข้อความเป็นคำอธิบายประกอบเป็นสตริงid : ระบุ ID ที่จะใช้เป็นคุณสมบัติ id ของโหนด NENNOTATEDTEXtextProcessor (ค่าเริ่มต้น: "Stanford" หากไม่สามารถใช้งานได้มากกว่ารายการแรกในรายการโปรเซสเซอร์ข้อความที่มีอยู่)pipeline (ค่าเริ่มต้น: Tokenizer)checkLanguage (ค่าเริ่มต้น: จริง): เรียกใช้การตรวจจับภาษาบนข้อความที่ให้ไว้และตรวจสอบว่ารองรับ ขั้นตอนนี้จะเชื่อมโยงต้นฉบับของคุณ :News ไปยัง :AnnotatedText NODE ซึ่งเป็นจุดเริ่มต้นสำหรับ NLP ที่ใช้กราฟของข่าวนี้โดยเฉพาะ ข้อความต้นฉบับถูกแบ่งออกเป็นคำพูดส่วนหนึ่งของคำพูดและฟังก์ชั่น การวิเคราะห์ข้อความนี้ทำหน้าที่เป็นจุดเริ่มต้นสำหรับขั้นตอนในภายหลัง
ใช้ชุดคำอธิบายประกอบ
หากคุณมีชุดข้อมูลจำนวนมากเพื่อเพิ่มความคิดเห็นเราขอแนะนำให้ใช้ APOC:
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
เป็น สิ่งสำคัญ ที่จะต้องรักษาตัวเลือก batchSize และ iterateList ตามที่กล่าวไว้ในตัวอย่าง การเรียกใช้ขั้นตอนการเพิ่มความคิดเห็นในแบบคู่ขนานจะสร้างการหยุดชะงัก
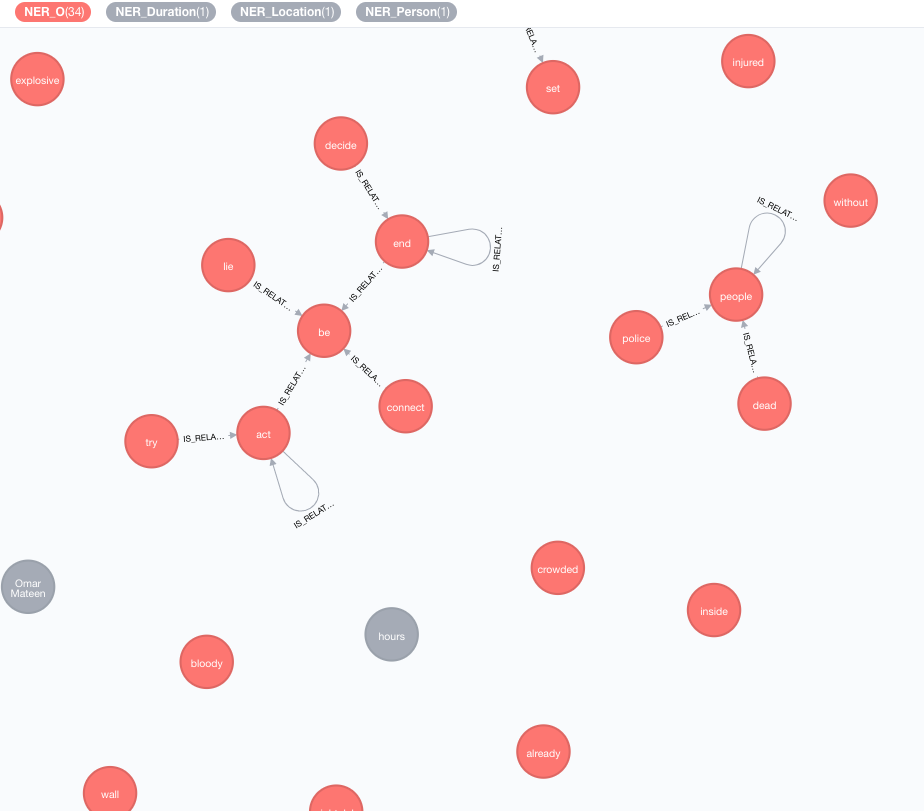
เราใช้ฐานความรู้ภายนอกเพื่อเพิ่มความรู้เกี่ยวกับข้อมูลปัจจุบันของคุณ
ณ ตอนนี้มีการใช้งานสองครั้ง:
Enricher นี้จะขยายความหมายของโทเค็น (แท็กโหนด) ในกราฟ
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
พารามิเตอร์ที่มีอยู่ (ค่าเริ่มต้นอยู่ในวงเล็บ):
tag : แท็กที่จะเพิ่มคุณค่าenricher ( "conceptnet5" ): เลือก microsoft หรือ conceptnet5depth ( 2 ): ความลึกของการไปตามลำดับชั้นของแนวคิดadmittedRelationships : เลือกประเภทความสัมพันธ์แนวคิดที่ต้องการโปรดดูเอกสารประกอบ ConceptNet สำหรับรายละเอียดpipeline : เลือกชื่อไปป์ไลน์ที่จะใช้สำหรับการทำความสะอาดแนวคิดก่อนเก็บไว้ในฐานข้อมูลของคุณ ระบบเริ่มต้นของระบบของคุณจะใช้เป็นอย่างอื่นfilterByLanguage ( true ): อนุญาตเฉพาะแนวคิดของภาษาที่ระบุใน outputLanguages ; หากไม่มีการระบุภาษาภาษาเดียวกับ tag จำเป็นoutputLanguages ( [] ): ส่งคืนแนวคิดเท่านั้นด้วยภาษาที่ระบุrelDirection ( "out" ): ทิศทางที่ต้องการของความสัมพันธ์ในลำดับชั้นแนวคิด ( "in" , "out" , "both" )minWeight ( 0.0 ): น้ำหนักความสัมพันธ์ที่ยอมรับน้อยที่สุดlimit ( 10 ): จำนวนแนวคิดสูงสุดต่อ tagsplitTag ( false ): ถ้า true tag เป็นตัวแรกที่มีโทเค็นและโทเค็นแต่ละตัวที่ได้รับการเสริม แท็กตอนนี้มีความสัมพันธ์ IS_RELATED_TO กับแนวคิดที่ได้รับการตกแต่งอื่น ๆ
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText เป็นพารามิเตอร์บังคับซึ่งอ้างถึงเอกสารที่มีคำอธิบายประกอบที่จำเป็นต้องวิเคราะห์
พารามิเตอร์เสริมที่มีอยู่ (ค่าเริ่มต้นอยู่ในวงเล็บ):
keywordLabel (คำหลัก): ชื่อฉลากของโหนดคำหลักuseDependencies (จริง): ใช้การพึ่งพาสากลเพื่อเสริมสร้างคำหลักที่สกัดและวลีสำคัญโดยแท็กที่เกี่ยวข้องผ่านสารประกอบและความสัมพันธ์ของ AMODdependenciesGraph (เท็จ): ใช้การพึ่งพาสากลสำหรับการสร้างกราฟการเกิดขึ้นของแท็ก (ค่าเริ่มต้นเป็นเท็จซึ่งหมายความว่าการไหลของคำธรรมชาติถูกใช้สำหรับการสร้างการเกิดขึ้นร่วมกัน)cleanKeywords (จริง): เรียกใช้ขั้นตอนการทำความสะอาดtopXTags (1/3): ตั้งค่าเศษส่วนของแท็กอันดับสูงสุดที่จะใช้เป็นคำหลัก / วลีคีย์respectSentences (เท็จ): ความเคารพหรือไม่ขอบเขตประโยคสำหรับการสร้างกราฟการเกิดร่วมrespectDirections (FALSE): เคารพหรือไม่ทิศทางในกราฟการเกิดร่วม (วิธีการที่จะติดตามซึ่งกันและกัน)iterations (30): จำนวนการทำซ้ำของ Pagerankdamp (0.85): ปัจจัยการทำให้หมาด ๆ ของ PageRankthreshold (0.0001): Pagerank Convergence ThresholdremoveStopwords (จริง): ใช้รายการคำสั่งสำหรับการสร้างกราฟการเกิดร่วมและการทำความสะอาดคำหลักขั้นสุดท้ายstopwords : ปรับแต่งรายการคำสั่งหยุด (หากรายการเริ่มต้นด้วย + คำต่อไปนี้จะถูกผนวกเข้ากับรายการคำสั่งหยุดเริ่มต้นมิฉะนั้นรายการเริ่มต้นจะถูกเขียนทับ)admittedPOSs : ระบุว่าป้ายกำกับ POS ใดที่ถือเป็นคำหลัก จำเป็นเมื่อใช้ภาษาที่แตกต่างจากภาษาอังกฤษforbiddenPOSs : ระบุรายการของป้ายกำกับ POS ที่จะถูกละเว้นเมื่อสร้างกราฟการเกิดร่วม จำเป็นเมื่อใช้ภาษาที่แตกต่างจากภาษาอังกฤษforbiddenNEs : ระบุรายการ NES ที่จะถูกละเว้น สำหรับคำอธิบายอัลกอริทึม TextRank โดยละเอียดโปรดดูโพสต์บล็อกของเราเกี่ยวกับการแยกคำหลักที่ไม่ได้รับการดูแล
การใช้การพึ่งพาสากลสำหรับการเพิ่มขึ้นของคำหลัก (ตัวเลือก useDependencies ) อาจส่งผลให้คำหลักที่มีระดับรายละเอียดที่ไม่จำเป็นเช่น โปรแกรมโลจิสติกส์อวกาศ ของคำหลัก ในหลายกรณีการใช้งานเราอาจสนใจที่จะรู้ว่าเอกสารที่ได้รับโดยทั่วไปพูดเกี่ยวกับ กระสวยอวกาศ (หรือ โปรแกรมโลจิสติก ) ในการทำเช่นนั้นให้รันโพสต์การประมวลผลด้วยหนึ่งในตัวเลือกเหล่านี้:
direct - แต่ละวลีสำคัญของจำนวนแท็ก n ถูกตรวจสอบกับวลีสำคัญทั้งหมดจากเอกสารทั้งหมดที่มี 1 <m <n จำนวนแท็ก; หากอดีตมีวลีสำคัญหลังความสัมพันธ์ DESCRIBES จะถูกสร้างขึ้นจาก m -keyphrase ไปจนถึงข้อความที่ใส่คำอธิบายประกอบทั้งหมดของ n -keyphesubgroups - ขั้นตอนเดียวกับ direct แต่แทนที่จะเชื่อมต่อคำหลักระดับที่สูงขึ้นโดยตรงกับ คำอธิบายประกอบข้อความ จะเชื่อมต่อกับคำหลักระดับล่างด้วยความสัมพันธ์ HAS_SUBGROUP // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel เป็นอาร์กิวเมนต์เสริมที่กำหนดโดยค่าเริ่มต้นเป็น "คำหลัก"
การดำเนินการ postprocess โดยค่าเริ่มต้นคือการประมวลผลในคำหลักทั้งหมดซึ่งอาจหนักมากบนกราฟขนาดใหญ่ คุณสามารถระบุ textext ที่จะใช้การดำเนินการ postprocess ด้วยอาร์กิวเมนต์ annotatedText :
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
ตัวอย่างสำหรับการรันอย่างมีประสิทธิภาพในชุดคำหลักเต็มรูปแบบด้วย APOC:
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
วิธีการที่คล้ายกันกับการสกัดคำหลักสามารถใช้เพื่อใช้การสรุปอย่างง่าย กราฟที่เชื่อมต่ออย่างหนาแน่นของประโยคถูกสร้างขึ้นโดยมีความสัมพันธ์ประโยคประโยคที่แสดงถึงความคล้ายคลึงกันตามคำที่ใช้ร่วมกัน (จำนวนคำที่ใช้ร่วมกันเทียบกับผลรวมของลอการิทึมของจำนวนคำในประโยค) จากนั้น PageRank จะถูกใช้เป็นตัวชี้วัดศูนย์กลางเพื่อจัดอันดับความสำคัญสัมพัทธ์ของประโยคในเอกสาร
เพื่อเรียกใช้อัลกอริทึมนี้:
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
พารามิเตอร์ที่มีอยู่:
annotatedTextiterations (30): จำนวนการทำซ้ำของ Pagerankdamp (0.85): ปัจจัยการทำให้หมาด ๆ ของ PageRankthreshold (0.0001): Pagerank Convergence Threshold ขั้นตอนการสรุปช่วยประหยัดคุณสมบัติใหม่ไปยังโหนดประโยค: summaryRelevance (ค่า Pagerank ของประโยคที่กำหนด) และ summaryRank (การจัดอันดับ; 1 = ประโยคอันดับสูงสุด) ตัวอย่างแบบสอบถามสำหรับการดึงข้อมูลสรุป:
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
นอกจากนี้คุณยังสามารถตรวจสอบได้ว่าข้อความที่นำเสนอนั้นเป็นบวกลบหรือเป็นกลาง ขั้นตอนนี้ต้องการโหนดคำอธิบายประกอบข้อความซึ่งผลิตโดย ga.nlp.annotate ด้านบน
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
ขั้นตอนนี้จะกลับ "ความสำเร็จ" เมื่อประสบความสำเร็จ แต่จะใช้ :POSITIVE , :NEUTRAL หรือ :NEGATIVE กับแต่ละประโยค เป็นผลให้เมื่อการตรวจจับความเชื่อมั่นเสร็จสมบูรณ์คุณสามารถสอบถามความเชื่อมั่นของประโยคได้เช่น:
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
เมื่อแท็กถูกดึงออกมาจากข่าวทั้งหมดหรือโหนดอื่น ๆ ที่มีข้อความบางส่วนก็เป็นไปได้ที่จะคำนวณความคล้ายคลึงกันระหว่างพวกเขาโดยใช้ความคล้ายคลึงกันตามเนื้อหา ในระหว่างกระบวนการนี้ข้อความที่มีคำอธิบายประกอบแต่ละรายการจะอธิบายโดยใช้รูปแบบการเข้ารหัส TF-IDF TF-IDF เป็นเทคนิคที่จัดตั้งขึ้นจากสาขาการดึงข้อมูลและย่อมาจากความถี่เอกสารความถี่ที่มีความถี่ เอกสารข้อความสามารถเข้ารหัส TF-IDF เป็นเวกเตอร์ในพื้นที่ Euclidean หลายมิติ ขนาดของพื้นที่สอดคล้องกับแท็กก่อนหน้านี้สกัดจากเอกสาร พิกัดของเอกสารที่กำหนดในแต่ละมิติ (เช่นสำหรับแต่ละแท็ก) จะถูกคำนวณเป็นผลิตภัณฑ์ของสองมาตรการย่อย: ความถี่คำและความถี่เอกสารผกผัน
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
พารามิเตอร์ที่มีอยู่ (ค่าเริ่มต้นอยู่ในวงเล็บ):
input : รายการของโหนดอินพุต - AnnotatedTextsrelationshipType (lamarity_cosine): ประเภทของความสัมพันธ์ที่คล้ายคลึงกันใช้มันพร้อมกับ queryquery : ระบุแบบสอบถามของคุณเองสำหรับการแยก TF และ IDF ในแบบฟอร์ม ... RETURN id(Tag), tf, idfpropertyName (value): ชื่อของคุณสมบัติโหนดที่มีอยู่ (อาร์เรย์ของค่าตัวเลข) ซึ่งมีเวกเตอร์เอกสารที่เตรียมไว้แล้วWord2vec เป็นโมเดลเครือข่ายประสาทสองชั้นตื้นที่ใช้ในการผลิตคำที่ฝังคำ (คำที่แสดงเป็นเวกเตอร์ความหมายหลายมิติ) และเป็นหนึ่งในโมเดลที่ใช้ใน NumberBatch ConceptNet
เพื่อเพิ่มโมเดลต้นทาง (เวกเตอร์) ลงในดัชนี Lucene
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir> เป็นเส้นทางเต็มไปยังไดเรกทอรีที่มีเวกเตอร์ต้นทางที่จะจัดทำดัชนี<path_to_index> เป็นเส้นทางเต็มรูปแบบที่ดัชนีจะถูกเก็บไว้<identifier> เป็นสตริงที่กำหนดเองที่ระบุโมเดลที่ไม่ซ้ำกันในรายการรุ่นที่มีอยู่:
CALL ga.nlp.ml.word2vec.listModels
ตอนนี้โมเดลสามารถใช้ในการคำนวณความคล้ายคลึงกันของโคไซน์ระหว่างคำ:
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
หรือคุณสามารถขอ Word2vec โดยตรงของโหนดซึ่งมีคำที่เก็บไว้ใน value คุณสมบัติ:
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
นอกจากนี้เรายังสามารถจัดเก็บเวกเตอร์ Word2Vec อย่างถาวรเพื่อติดแท็กโหนด:
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query : แบบสอบถามที่ส่งคืนแท็กที่ควรแนบเวกเตอร์ฝังmodelName : รุ่นที่จะใช้นอกจากนี้คุณยังสามารถรับเพื่อนบ้านที่ใกล้ที่สุดด้วยขั้นตอนต่อไปนี้:
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
สำหรับโมเดลขนาดใหญ่ตัวอย่างเช่น fasttext แบบเต็มสำหรับภาษาอังกฤษประมาณ 2 ล้านคำจะไม่มีประสิทธิภาพในการคำนวณเพื่อนบ้านที่ใกล้ที่สุดในทันที
คุณสามารถโหลดโมเดลลงในหน่วยความจำเพื่อให้เพื่อนบ้านที่ใกล้ที่สุดได้เร็วขึ้น (โดยทั่วไปแล้ว FastText 1M Word Vectors ใช้เวลา 27 วินาทีหากจำเป็นต้องอ่านจากดิสก์, ~ 300ms ในหน่วยความจำ):
ตรวจสอบให้แน่ใจว่ามีหน่วยความจำกองที่มีประสิทธิภาพที่ทุ่มเทให้กับ Neo4J:
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
โหลดโมเดลลงในหน่วยความจำ:
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
และเรียกคืนด้วย
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
คุณสามารถใช้โมเดลการฝังคำใด ๆ ตราบเท่าที่ต่อไปนี้เป็นจริง:
.txt ตัวอย่างเช่นคุณสามารถโหลดโมเดลจาก FastText และเปลี่ยนชื่อไฟล์จาก .vec เป็น .txt : https://fasttext.cc/docs/en/english-vectors.html
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
ขั้นตอนการส่งคืนแถวพร้อม number คอลัมน์คือหมายเลขหน้าและ paragraphs เป็น List<String> ของข้อความย่อหน้า
นอกจากนี้คุณยังสามารถส่ง URL http หรือ https ไปยังขั้นตอนการโหลดไฟล์จากตำแหน่งระยะไกล
ในบางกรณีเอกสาร PDF มีเนื้อหาที่ไร้ประโยชน์เช่นหน้าท้ายหน้าอื่น ๆ คุณสามารถแยกออกจากการแยกวิเคราะห์ได้โดยผ่านรายการ regexes ที่กำหนดชิ้นส่วนเพื่อยกเว้น:
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
Tika สามารถรับรู้ได้ว่าเป็นตัวรวบรวมข้อมูลและถูกปฏิเสธการเข้าถึงบางไซต์ที่มี PDF คุณสามารถแทนที่สิ่งนี้ได้โดยผ่านตัวเลือก UserAgent :
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
ในบางสถานการณ์มันจะมีประโยชน์ในการจัดเก็บเฉพาะค่าบางอย่างแทนที่จะเป็นกราฟเต็มรูปแบบโปรดทราบว่ามันอาจลดความสามารถในการดึงข้อมูลเชิงลึก (Textrank) สำหรับเช่น:
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
WebVTT เป็นรูปแบบสำหรับแทร็กข้อความวิดีโอเว็บเช่นการถอดเสียง YouTube ของวิดีโอ: https://fr.wikipedia.org/wiki/webvtt
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
ไฟล์รายการขั้นตอนข้างต้นของไดเรกทอรีปัจจุบันเท่านั้นหากคุณต้องการเดินไดเรกทอรีเด็กเช่นกันใช้ walkdir :
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
รายการโมเดลที่เก็บไว้และเส้นทางของพวกเขา
ลบและสร้างท่อใหม่ด้วยการกำหนดค่าเดียวกัน (มีประโยชน์เมื่อใช้ไฟล์ ner แบบคงที่ที่มีการเปลี่ยนแปลงสำหรับเช่น)
ลิขสิทธิ์ (c) 2013-2019 graphaware
graphaware เป็นซอฟต์แวร์ฟรี: คุณสามารถแจกจ่ายใหม่และ/หรือแก้ไขภายใต้เงื่อนไขของใบอนุญาตสาธารณะ GNU ทั่วไปที่เผยแพร่โดย Free Software Foundation ไม่ว่าจะเป็นเวอร์ชัน 3 ของใบอนุญาตหรือ (ตามตัวเลือกของคุณ) รุ่นใหม่ ๆ โปรแกรมนี้มีการแจกจ่ายด้วยความหวังว่าจะมีประโยชน์ แต่ไม่มีการรับประกันใด ๆ โดยไม่มีการรับประกันโดยนัยเกี่ยวกับความสามารถในการค้าหรือความเหมาะสมสำหรับวัตถุประสงค์เฉพาะ ดูใบอนุญาตสาธารณะ GNU ทั่วไปสำหรับรายละเอียดเพิ่มเติม คุณควรได้รับสำเนาใบอนุญาตสาธารณะ GNU ทั่วไปพร้อมกับโปรแกรมนี้ ถ้าไม่ดู http://www.gnu.org/licenses/


