neo4j nlp
1.0.0
2021 년 5 월 현재이 저장소는 은퇴했습니다.
이 NEO4J 플러그인은 그래프 기반 자연어 처리 기능을 제공합니다.
기본 모듈 인이 모듈은 기본 텍스트 프로세서를위한 공통 인터페이스와 저장된 절차 및 기능에 구축 된 도메인 특정 언어를 제공하여 자연어 처리 워크 플로우 개발자 친화적 인 기능을 제공합니다.
다음 NLP 기능이있는 2 가지 버전의 커뮤니티 (오픈 소스) 및 엔터프라이즈로 제공됩니다.
| 커뮤니티 에디션 | 엔터프라이즈 에디션 | |
|---|---|---|
| 텍스트 정보 추출 | ✔ | ✔ |
| 동일한 데이터베이스의 다국어 | ✔ | |
| Custom NamedEntityRecognition Model Builder | ✔ | |
| ConceptNet5 Enricher | ✔ | ✔ |
| Microsoft Concept Enicher | ✔ | ✔ |
| 키워드 추출 | ✔ | ✔ |
| Textrank 요약 | ✔ | ✔ |
| 주제 추출 | ✔ | |
| Word Embeddings (Word2Vec) | ✔ | ✔ |
| 유사성 계산 | ✔ | ✔ |
| PDF 파싱 | ✔ | ✔ |
| 분산 알고리즘에 대한 아파치 스파크 바인딩 | ✔ | |
| DOC2VEC 구현 | ✔ | |
| 사용자 인터페이스 | ✔ | |
| ML 예측 기능 | ✔ | |
| 엔티티 병합 | ✔ |
Stanford NLP 및 OpenNLP와 같은 두 가지 NLP 프로세서 구현을 사용할 수 있습니다 (OpenNLP는 덜 빈번한 업데이트를 받고 Stanfordnlp가 권장됩니다).
버전 3.5.1.53.15에서 언어 모델을 다운로드해야합니다. 아래를 참조하십시오.
GraphAware 플러그인 디렉토리에서 다음 jar 파일을 다운로드하십시오.
neo4j-framework (이것의 JAR은 "Graphaware-Server-Enterprise-All"으로 표시됩니다.neo4j-nlpneo4j-nlp-stanfordnlphttps://stanfordnlp.github.io/CoreNLP/#download 에서 다운로드 할 언어 모델 NEO4J의 plugins 디렉토리에 복사하십시오.
사용중인 프레임 워크의 버전 번호가 사용중인 Neo4J 버전과 일치하도록주의하십시오 . 이것은 일반적인 설정 문제입니다. 예를 들어, NEO4J 3.4.0 이상을 사용하는 경우 다운로드 한 모든 항아리에는 버전 번호에 3.4가 포함되어 있어야합니다.
plugins/ 디렉토리 예 :
-rw-r--r-- 1 ikwattro staff 58M Oct 11 11:15 graphaware-nlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 13M Aug 22 15:22 graphaware-server-community-all-3.5.1.53.jar
-rw-r--r-- 1 ikwattro staff 16M Oct 11 11:28 nlp-stanfordnlp-3.5.1.53.14.jar
-rw-r--r--@ 1 ikwattro staff 991M Oct 11 11:45 stanford-english-corenlp-2018-10-05-models.jar
config/ 디렉토리의 neo4j.conf 파일에서 다음 구성을 추가하십시오.
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.1=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*
NEO4J 데이터베이스를 시작하거나 다시 시작하십시오.
참고 : 두 콘크리트 텍스트 프로세서는 매우 탐욕 스럽습니다. NEO4J 힙 공간에 충분한 메모리를 전용해야합니다.
또한 속도 성능을 위해 다음 인덱스 및 제약 조건이 제안됩니다.
CREATE CONSTRAINT ON (n:AnnotatedText) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Tag) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Sentence) ASSERT n.id IS UNIQUE;
CREATE INDEX ON :Tag(value);
또는 전용 절차를 사용하십시오.
CALL ga.nlp.createSchema()
이 데이터베이스에서 사용할 언어를 정의하십시오.
CALL ga.nlp.config.setDefaultLanguage('en')
연장이로드되면이 Cypher 쿼리를 실행하여 사용 가능한 모든 절차에 대한 기본 문서를 볼 수 있습니다.
CALL dbms.procedures() YIELD name, signature, description
WHERE name =~ 'ga.nlp.*'
RETURN name, signature, description ORDER BY name asc;
텍스트 추출 단계는 자연어 처리 파이프 라인으로 수행되며 각 파이프 라인에는 활성화 된 구성 요소 목록이 있습니다.
예를 들어, 기본 토큰 tokenizer 파이프 라인에는 다음 구성 요소가 있습니다.
먼저 파이프 라인을 만드는 것은 필수입니다.
CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false}, stopWords: '+,result, all, during',
threadNumber: 20})
사용 가능한 선택적 매개 변수 (기본값은 괄호 안에 있습니다) :
name : 새 파이프 라인의 원하는 이름textProcessor : 새 파이프 라인을 추가 해야하는 텍스트 프로세서processingSteps : 파이프 라인 구성 (달리 명시되지 않는 한 Stanford 및 OpenNLP에서 사용할 수 있음)tokenize (default : true) : 토큰 화를 수행하십시오ner (기본값 : true) : 명명 된 엔티티 인식sentiment (기본값 : 거짓) : 문장에 대한 감정 분석을 실행하십시오coref (Default : False) : Correference 해상도 ( "Barack Obama"및 "He"와 같은 동일한 엔티티의 여러 언급을 식별)relations (기본값 : False) : 두 토큰 간의 실행 관계 식별dependency (기본값 : False, Stanfordnlp 만 해당) : 유형의 종속성 추출 (예 : AMOD- 형용사 수정 자, 결합, ...)cleanxml (default : false, stanfordnlp 만 해당) : XML 태그를 제거합니다truecase (기본값 : False, Stanfordnlp 만 해당) : "진정한"토큰의 사례를 인식합니다 (잘 편집 된 텍스트로 대문자화되는 방법)customNER : Custom NER 모델 식별자 목록 (문자열, 모델 식별자로 ",")stopWords : 무시 해야하는 단어를 지정합니다 (목록이 +로 시작하는 경우 다음 단어는 기본 Stopwords 목록에 추가됩니다. 그렇지 않으면 기본 목록이 덮어 쓰기).threadNumber (기본값 : 4) : 멀티 스레딩의 경우excludedNER : (기본값 : 없음) 태그 노드에서 NER_Money 및 NER_O 제외하고 [ 'o', 'money'를 사용하는 것과 같이 대문자에서 인식되지 않는 NE 목록을 지정하십시오.]파이프 라인을 기본 파이프 라인으로 설정하려면 :
CALL ga.nlp.processor.pipeline.default(<your-pipeline-name>)
파이프 라인을 삭제하려면이 명령을 사용하십시오.
CALL ga.nlp.processor.removePipeline(<pipeline-name>, <text-processor>)
모든 기존 파이프 라인의 세부 사항을 보려면 :
CALL ga.nlp.processor.getPipelines()
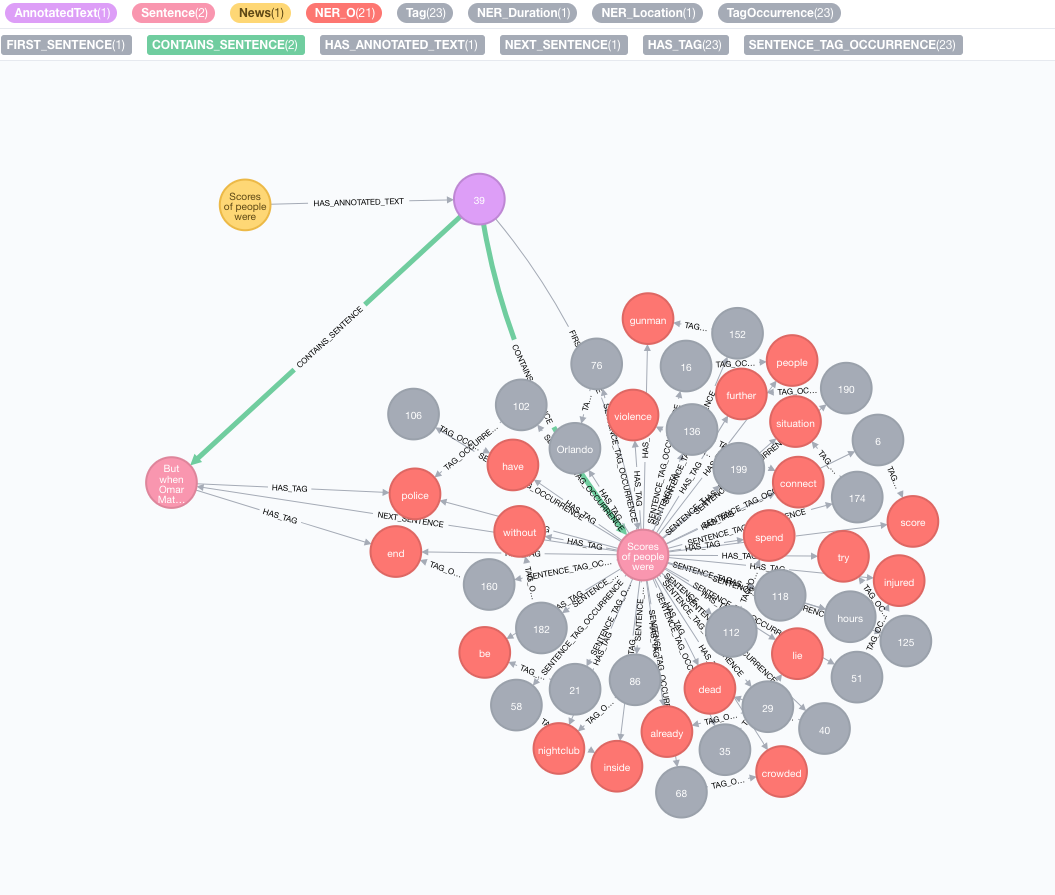
다음 텍스트를 예로 들어 봅시다.
Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.
원래 코퍼스를 시뮬레이션하십시오
텍스트와 함께 노드를 만들면이 노드는 원래 코퍼스 또는 지식 그래프를 나타냅니다.
CREATE (n:News)
SET n.text = "Scores of people were already lying dead or injured inside a crowded Orlando nightclub,
and the police had spent hours trying to connect with the gunman and end the situation without further violence.
But when Omar Mateen threatened to set off explosives, the police decided to act, and pushed their way through a
wall to end the bloody standoff.";
텍스트 정보 추출을 수행하십시오
추출은 텍스트 정보 추출에 대한 진입 지점 인 annotate 절차를 통해 수행됩니다.
MATCH (n:News)
CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result
MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)
RETURN result
annotate 프로 시저의 사용 가능한 매개 변수 :
text : 주석으로 문자열로 표시되는 텍스트id : 새 AnnotatedText 노드의 id 속성으로 사용될 ID를 지정하십시오.textProcessor (기본값 : "Stanford", 사용 가능한 텍스트 프로세서 목록의 첫 번째 항목보다 사용할 수없는 경우)pipeline (기본값 : 토 케이저)checkLanguage (기본값 : true) : 제공된 텍스트에서 언어 감지를 실행하고 지원되는지 확인하십시오. 이 절차는 원본 :News Node 가이 특정 뉴스의 그래프 기반 NLP의 진입 점인 :AnnotatedText 노드에 연결됩니다. 원본 텍스트는 단어, 연설의 일부 및 기능으로 나뉩니다. 이 텍스트 분석은 이후 단계의 출발점 역할을합니다.
주석 배치를 실행합니다
주석을 달 수있는 큰 데이터 세트가있는 경우 APOC를 사용하는 것이 좋습니다.
CALL apoc.periodic.iterate(
"MATCH (n:News) RETURN n",
"CALL ga.nlp.annotate({text: n.text, id: id(n)})
YIELD result MERGE (n)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
예제에 언급 된대로 batchSize 및 iterateList 옵션을 유지하는 것이 중요합니다 . 주석 절차를 동시에 실행하면 교착 상태가됩니다.
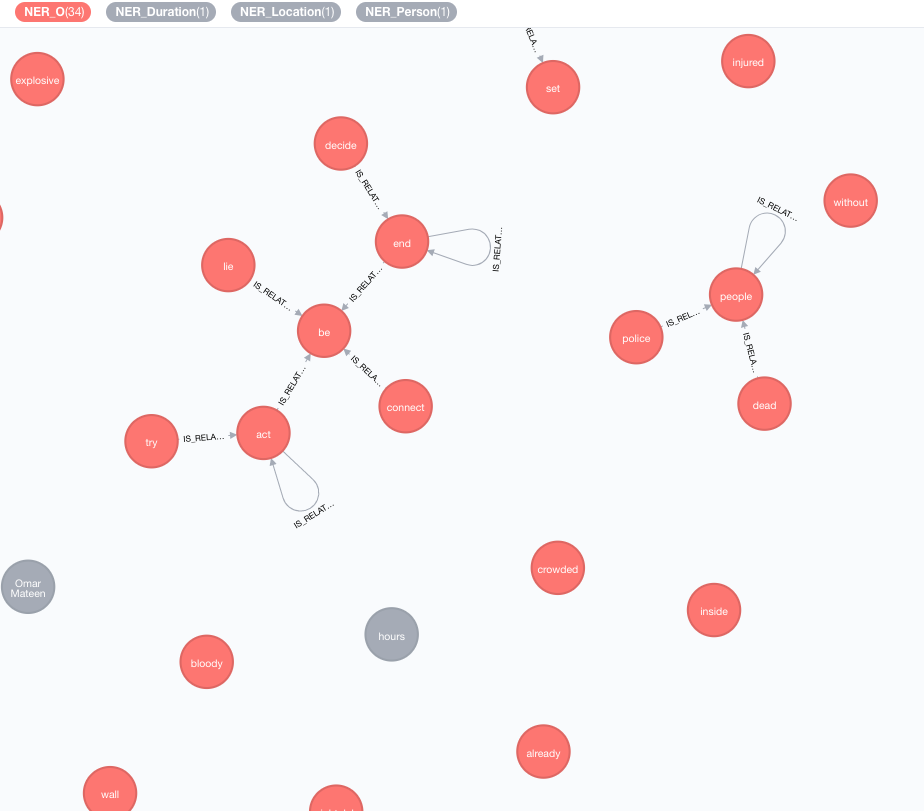
현재 데이터에 대한 지식을 풍부하게하기 위해 외부 지식 기반을 구현합니다.
현재 두 가지 구현을 사용할 수 있습니다.
이 농축기는 그래프에서 토큰 (태그 노드)의 의미를 확장합니다.
MATCH (n:Tag)
CALL ga.nlp.enrich.concept({enricher: 'conceptnet5', tag: n, depth:1, admittedRelationships:["IsA","PartOf"]})
YIELD result
RETURN result
사용 가능한 매개 변수 (기본값은 괄호 안에 있습니다) :
tag : 풍성한 태그enricher ( "conceptnet5" ) : microsoft 또는 conceptnet5 선택하십시오depth ( 2 ) : 개념 계층에 얼마나 깊이 가야 하는가admittedRelationships : 원하는 개념 관계 유형을 선택하십시오. 자세한 내용은 ConceptNet 문서를 참조하십시오.pipeline : DB에 저장하기 전에 개념을 정리하는 데 사용할 파이프 라인 이름을 선택하십시오. 시스템 기본 파이프 라인이 사용됩니다filterByLanguage ( true ) : outputLanguages 에 지정된 언어 개념 만 허용합니다. 언어가 지정되지 않은 경우 tag 와 동일한 언어가 필요합니다.outputLanguages ( [] ) : 지정된 언어를 가진 개념 만 반환relDirection ( "out" ) : 개념 계층에서 원하는 관계 방향 ( "in" , "out" , "both" )minWeight ( 0.0 ) : 최소 인정 된 개념 관계 가중치limit ( 10 ) : tag 최대 개념 수splitTag ( false ) : true 인 경우 tag 먼저 토큰 화되고 개별 토큰이 풍부합니다. 태그는 이제 다른 풍부한 개념과 IS_RELATED_TO 관계를 가지고 있습니다.
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank({annotatedText: a, stopwords: '+,other,email', useDependencies: true})
YIELD result RETURN result
annotatedText 분석 해야하는 주석화 된 문서를 나타내는 필수 매개 변수입니다.
사용 가능한 선택적 매개 변수 (기본값은 괄호 안에 있습니다) :
keywordLabel (키워드) : 키워드 노드의 레이블 이름useDependencies (true) : 보편적 종속성을 사용하여 화합물 및 아모드 관계를 통해 관련된 태그별로 추출 된 키워드 및 키 문구를 풍부하게합니다.dependenciesGraph (False) : 태그 동시 발생 그래프를 생성하기 위해 범용 종속성을 사용합니다 (기본값은 False입니다. 즉, 자연적인 단어 흐름이 동시 발생을 구축하는 데 사용됨)cleanKeywords (True) : 청소 절차를 실행하십시오topXTags (1/3) : 키워드 / 키 문구로 사용될 가장 높은 등급의 태그의 일부를 설정respectSentences (거짓) : 동시 발생 그래프 빌 구축에 대한 문장 경계 존중 여부respectDirections (거짓) : 동시 발생 그래프의 지시를 존중하는 지 방향 (단어가 서로 따르는 방법)iterations (30) : PageRank 반복 수damp (0.85) : PageRank 댐핑 계수threshold (0.0001) : PageRank 수렴 임계 값removeStopwords (true) : 동시 발생 그래프 빌드 및 키워드의 최종 청소에는 Stopwords 목록을 사용합니다.stopwords : stopwords 목록 사용자 정의 (목록이 + 로 시작하는 경우 다음 단어가 기본 stopwords 목록에 추가됩니다. 그렇지 않으면 기본 목록이 덮어 씁니다)admittedPOSs : 키워드 후보로 간주되는 POS 레이블을 지정합니다. 영어와 다른 언어를 사용할 때 필요합니다forbiddenPOSs : 동시 발생 그래프를 구성 할 때 무시할 POS 라벨 목록을 지정합니다. 영어와 다른 언어를 사용할 때 필요합니다forbiddenNEs : 무시할 NES 목록을 지정하십시오 자세한 TextRank 알고리즘 설명은 감독되지 않은 키워드 추출에 대한 블로그 게시물을 참조하십시오.
키워드 강화에 대한 범용 종속성을 사용하면 ( useDependencies 옵션) Keyword Space Shuttle Logistics 프로그램 과 같은 세부 수준의 키워드가 발생할 수 있습니다. 많은 사용 사례에서 우리는 주어진 문서가 일반적으로 우주 왕복선 (또는 물류 프로그램 )에 대해 말하는 것을 알고 싶어 할 것입니다. 이를 위해 다음 옵션 중 하나를 사용하여 후 처리를 실행하십시오.
direct - N 수의 각각의 주요 문구는 1 <m <n 태그 수를 가진 모든 문서의 모든 주요 문구에 대해 확인됩니다. 전자가 후자의 핵심 문구를 포함하는 경우, a는 m -Keyphrase에서 n -Keyphrase의 모든 주석이 달린 텍스트에 이르기까지 관계를 DESCRIBES .subgroups - direct 과 동일한 절차이지만 더 높은 레벨 키워드를 AnnotatedTexts 에 직접 연결하는 대신 HAS_SUBGROUP 관계를 가진 하위 레벨 키워드에 연결됩니다. // Important note: create subsequent indices to optimise the post-process method performance
CREATE INDEX ON :Keyword(numTerms)
CREATE INDEX ON :Keyword(value)
CALL ga.nlp.ml.textRank.postprocess({keywordLabel: "Keyword", method: "subgroups"})
YIELD result
RETURN result
keywordLabel 은 기본적으로 "키워드" 로 설정된 선택적 인수입니다.
기본적으로 후 프로세스 작업은 모든 키워드를 처리하는 것입니다. 이는 큰 그래프에서 매우 무거울 수 있습니다. AnnotatedText 인수와 함께 후 처리 작업을 적용 할 annotatedText 텍스트를 지정할 수 있습니다.
MATCH (n:AnnotatedText) WITH n LIMIT 100
CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:'subgroups'}) YIELD result RETURN count(n)
APOC가있는 전체 키워드 세트에서 효율적으로 실행하는 예 :
CALL apoc.periodic.iterate(
'MATCH (n:AnnotatedText) RETURN n',
'CALL ga.nlp.ml.textRank.postprocess({annotatedText: n, method:"subgroups"}) YIELD result RETURN count(n)',
{batchSize: 1, iterateList:false}
)
간단한 요약을 구현하기 위해 키워드 추출과 유사한 접근법을 사용 할 수 있습니다. 문장의 조밀하게 연결되는 그래프가 생성되며, 문장 서식 관계는 공유 단어 (공유 단어의 수 vs 문장의 단어 수의 합)를 나타내는 유사성을 나타냅니다. 그런 다음 PageRank는 문서에서 문장의 상대적 중요성을 평가하기 위해 중심 측정 값으로 사용됩니다.
이 알고리즘을 실행하려면 :
MATCH (a:AnnotatedText)
CALL ga.nlp.ml.textRank.summarize({annotatedText: a}) YIELD result
RETURN result
사용 가능한 매개 변수 :
annotatedTextiterations (30) : PageRank 반복 수damp (0.85) : PageRank 댐핑 계수threshold (0.0001) : PageRank 수렴 임계 값 요약 절차는 새로운 속성을 문장 노드에 저장합니다. summaryRelevance (주어진 문장의 PagerAnk 값) 및 summaryRank (순위; 1 = 가장 높은 순위가 높은 문장). 요약 검색을위한 예제 쿼리 :
match (n:Kapitel)-[:HAS_ANNOTATED_TEXT]->(a:AnnotatedText)
where id(n) = 233
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)
with a, count(*) as nSentences
match (a)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_TAG]->(t:Tag)
with a, s, count(distinct t) as nTags, (CASE WHEN nSentences*0.1 > 10 THEN 10 ELSE toInteger(nSentences*0.1) END) as nLimit
where nTags > 4
with a, s, nLimit
order by s.summaryRank
with a, collect({text: s.text, pos: s.sentenceNumber})[..nLimit] as summary
unwind summary as sent
return sent.text
order by sent.pos
제시된 텍스트가 양수, 부정적 또는 중립인지 여부를 결정할 수도 있습니다. 이 절차에는 위의 ga.nlp.annotate 에 의해 생성되는 주석 텍스트 노드가 필요합니다.
MATCH (t:MyNode)-[]-(a:AnnotatedText)
CALL ga.nlp.sentiment(a) YIELD result
RETURN result;
이 절차는 성공할 때 "성공 :POSITIVE 을 단순히 반환하지만 다음은 다음과 :NEUTRAL 적용 :NEGATIVE . 결과적으로 감정 탐지가 완료되면 다음과 같은 문장의 감정을 쿼리 할 수 있습니다.
MATCH (s:Sentence)
RETURN s.text, labels(s)
CALL ga.nlp.detectLanguage("What language is this in?")
YIELD result return result
CALL ga.nlp.filter({text:'On 8 May 2013,
one week before the Pakistani election, the third author,
in his keynote address at the Sentiment Analysis Symposium,
forecast the winner of the Pakistani election. The chart
in Figure 1 shows varying sentiment on the candidates for
prime minister of Pakistan in that election. The next day,
the BBC’s Owen Bennett Jones, reporting from Islamabad, wrote
an article titled Pakistan Elections: Five Reasons Why the
Vote is Unpredictable, in which he claimed that the election
was too close to call. It was not, and despite his being in Pakistan,
the outcome of the election was exactly as we predicted.', filter: 'Owen Bennett Jones/PERSON, BBC, Pakistan/LOCATION'}) YIELD result
return result
일부 텍스트가 포함 된 모든 뉴스 또는 기타 노드에서 태그가 추출되면 컨텐츠 기반 유사성을 사용하여 유사성을 계산할 수 있습니다. 이 과정에서 각 주석이 달린 텍스트는 TF-IDF 인코딩 형식을 사용하여 설명됩니다. TF-IDF는 정보 검색 분야에서 확립 된 기술이며 용어 주파수 inverse document quickency를 나타냅니다. 텍스트 문서는 다차원 유클리드 공간에서 벡터로 TF-IDF를 인코딩 할 수 있습니다. 공간 치수는 이전에 문서에서 추출한 태그에 해당합니다. 각 차원 (즉, 각 태그에 대해 주어진 문서의 좌표는 두 가지 하위 측정의 산물로 계산됩니다 : 용어 주파수 및 역 문서 주파수.
MATCH (a:AnnotatedText)
//WHERE ...
WITH collect(a) as nodes
CALL ga.nlp.ml.similarity.cosine({input: <list_of_annotated_texts>[, query: <tfidf_query>, relationshipType: "CUSTOM_SIMILARITY", ...]}) YIELD result
RETURN result
사용 가능한 매개 변수 (기본값은 괄호 안에 있습니다) :
input : 입력 노드 목록 - 주석 텍스트relationshipType (유사성 _cosine) : 유사성 관계 유형, query 와 함께 사용하십시오.query : 양식에서 TF 및 IDF를 추출하기 위해 자신의 쿼리를 지정합니다 ... RETURN id(Tag), tf, idfpropertyName (값) : 이미 준비된 문서 벡터를 포함하는 기존 노드 속성 (숫자 값 배열)의 이름Word2Vec은 단어 임베딩 (다차원 의미 벡터로 표시되는 단어)을 생성하는 데 사용되는 얕은 2 층 신경망 모델이며 Conceptnet Numberbatch에 사용되는 모델 중 하나입니다.
소스 모델 (벡터)을 Lucene 지수에 추가합니다
CALL ga.nlp.ml.word2vec.addModel(<path_to_source_dir>, <path_to_index>, <identifier>)
<path_to_source_dir> 는 인덱싱 될 소스 벡터가있는 디렉토리의 전체 경로입니다.<path_to_index> 인덱스가 저장 될 전체 경로입니다.<identifier> 모델을 고유하게 식별하는 사용자 정의 문자열입니다.사용 가능한 모델을 나열하려면 :
CALL ga.nlp.ml.word2vec.listModels
이제 모델을 사용하여 단어 간의 코사인 유사성을 계산할 수 있습니다.
WITH ga.nlp.ml.word2vec.wordVector('äpple', 'swedish-numberbatch') AS appleVector,
ga.nlp.ml.word2vec.wordVector('frukt', 'swedish-numberbatch') AS fruitVector
RETURN ga.nlp.ml.similarity.cosine(appleVector, fruitVector) AS similarity
또는 속성 value 에 저장된 단어가있는 노드의 Word2Vec을 직접 요청할 수 있습니다.
MATCH (n1:Tag), (n2:Tag)
WHERE ...
WITH ga.nlp.ml.word2vec.vector(n1, <model_name>) AS vector1,
ga.nlp.ml.word2vec.vector(n2, <model_name>) AS vector2
RETURN ga.nlp.ml.similarity.cosine(vector1, vector2) AS similarity
또한 Word2Vec 벡터를 영구적으로 저장하여 노드를 태그 할 수도 있습니다.
CALL ga.nlp.ml.word2vec.attach({query:'MATCH (t:Tag) RETURN t', modelName:'swedish-numberbatch'})
query : 벡터를 포함 해야하는 태그를 반환하는 쿼리modelName : 사용할 모델다음 절차로 가장 가까운 이웃을 얻을 수도 있습니다.
CALL ga.nlp.ml.word2vec.nn('analyzed', 10, 'fasttext') YIELD word, distance RETURN word, distance
대형 모델의 경우, 예를 들어 영어 용 Fast Text, 약 2 백만 단어의 경우 가장 가까운 이웃을 계산하는 것이 비효율적입니다.
가장 가까운 이웃을 가리려면 모델을 메모리에로드 할 수 있습니다 (FastText 1m Word 벡터는 일반적으로 디스크에서 읽는 데 필요한 경우 27 초가 걸립니다. 메모리에서 ~ 300ms).
NEO4J 전용 효율적인 힙 메모리를 확보하십시오.
dbms.memory.heap.initial_size=3000m
dbms.memory.heap.max_size=5000m
모델을 메모리에로드하십시오.
CALL ga.nlp.ml.word2vec.load(<maxNeighbors>, <modelName>)
그리고 그것을 검색하십시오
CALL ga.nlp.ml.word2vec.nn(<word>,<maxNeighbors>,<modelName>)
다음이 사실 인 한 단어 임베딩 모델을 사용할 수 있습니다.
.txt 확장자가 있습니다 예를 들어, FastText에서 모델을로드하고 파일의 .vec 에서 .txt : https://fasttext.cc/docs/en/english-vectors.html의 이름을 바꿀 수 있습니다.
CALL ga.nlp.parser.pdf("file:///Users/ikwattro/_graphs/nlp/import/myfile.pdf") YIELD number, paragraphs
절차는 열 number 가 페이지 번호와 paragraphs 단락 텍스트의 List<String> 인 행을 반환합니다.
원격 위치에서 파일을로드하기위한 절차에 http 또는 https URL을 전달할 수도 있습니다.
경우에 따라 PDF 문서에는 페이지 바닥 글 등과 같은 반복적 인 쓸모없는 콘텐츠가 있으므로 배제 할 부분을 정의하는 Regexes 목록을 전달하여 구문 분석에서 제외 할 수 있습니다.
CALL ga.nlp.parser.pdf("myfile.pdf", ["^[0-9]$","^Licensed to"])
Tika는 크롤러로 인식 될 수 있으며 PDF가 포함 된 일부 사이트에 대한 액세스 거부가 거부 될 수 있습니다. UserAgent 옵션을 전달하여이를 무시할 수 있습니다.
CALL ga.nlp.parser.pdf($url, [], {UserAgent: 'Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.7.2) Gecko/20040803'})
RETURN ga.nlp.parse.raw(<path-to-file>) AS content
특정 상황에서는 전체 그래프 대신 특정 값 만 저장하는 것이 유용하지만, 예를 들어 통찰력 (Textrank)을 추출하는 능력을 줄일 수 있습니다.
CALL ga.nlp.processor.addPipeline({
name:"whitelist",
whitelist:"hello,john,ibm",
textProcessor:"com.graphaware.nlp.enterprise.processor.EnterpriseStanfordTextProcessor",
processingSteps:{tokenize:true, ner:true}})
CALL ga.nlp.annotate({text:"Hello, my name is John and I worked at IBM.", id:"test-123", pipeline:"whitelist", checkLanguage:false})
YIELD result
RETURN result
webvtt는 비디오의 YouTube Transcripts : https://fr.wikipedia.org/wiki/webvtt와 같은 웹 비디오 텍스트 트랙의 형식입니다.
CALL ga.nlp.parser.webvtt("url-to-transcript.vtt") YIELD startTime, endTime, text
CALL ga.nlp.utils.listFiles(<path-to-directory>, <extensionFilter>)
// eg:
CALL ga.nlp.utils.listFiles("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
위의 절차는 현재 디렉토리의 파일을 목록으로 만, 어린이 디렉토리를 걸어야하는 경우 walkdir 사용하십시오.
CALL ga.nlp.utils.walkdir("/Users/ikwattro/dev/papers", ".pdf") YIELD filePath RETURN filePath
저장된 모델과 경로를 나열하십시오
동일한 구성으로 파이프 라인을 제거하고 재창조하십시오 (예 : 변경된 정적 NER 파일을 사용할 때 유용함)
저작권 (C) 2013-2019 그래프와 케어
GraphAware는 무료 소프트웨어입니다. Free Software Foundation, License의 버전 3 또는 이후 버전에서 게시 한 GNU 일반 공개 라이센스의 조건에 따라 재분배 및/또는 수정할 수 있습니다. 이 프로그램은 유용 할 것이지만 보증이 없다는 희망으로 배포됩니다. 상업성 또는 특정 목적에 대한 적합성에 대한 묵시적 보증조차 없습니다. 자세한 내용은 GNU 일반 공개 라이센스를 참조하십시오. 이 프로그램과 함께 GNU 일반 공개 라이센스 사본을 받았어야합니다. 그렇지 않은 경우 http://www.gnu.org/licenses/를 참조하십시오.


