QuantEase
1.0.0
该存储库包含论文量化的代码:基于语言模型的优化量化 - 一种有效而直观的算法
随着大语言模型(LLM)的日益普及,对压缩技术的有效部署引起了人们的兴趣。这项研究的重点是LLM的训练后量化,引入量化量,这是一个层次的量化框架,单个层进行单独的量化。我们的工作将问题构建为离散的非凸优化,开发了坐标下降技术,提供了高质量的解决方案,而无需矩阵倒置或分解。我们还探索一个异常感知的变体,以完全精确地保留了重要的权重。我们的建议在各种LLM和数据集的经验评估中取得了最新的表现,比GPTQ等方法的提高了15%。通过仔细的线性代数优化,量词可以在大约三个小时内量化单个NVIDIA A100 GPU上的Falcon-180b之类的模型。以可接受的精度下降,诸如SPQR(例如SPQR)的量度可接受的量化量相近或低3位的量化量,就困惑而言,最多两次。
wikitext2的选定bloom,opt和falcon模型家族的困惑结果,而无需分组:
| 模型名称 | FP16 | 4bit | 3位 | 3位结构离群值(1%) | 3位未结构的离群值(1%) |
|---|---|---|---|---|---|
| OPT-1.3B | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| OPT-13B | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1B7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7b1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| Falcon-7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| Falcon-40B | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
LAMBADA基准的零击精度用于3位和4位量化: 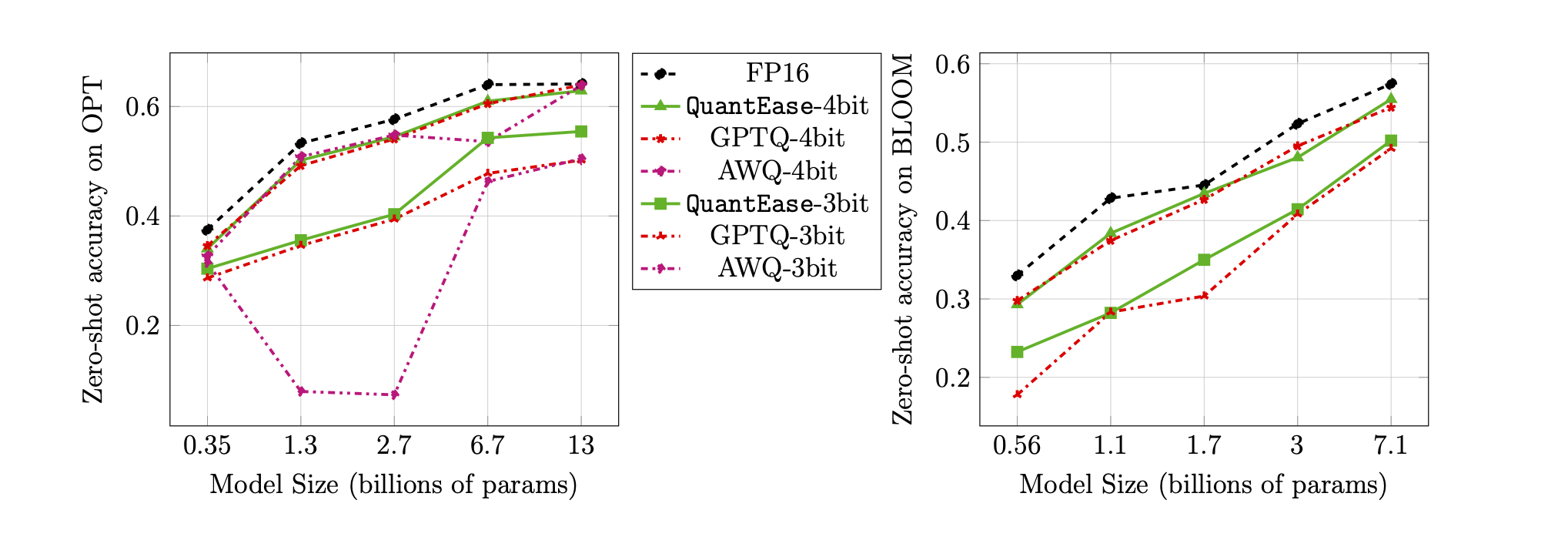
quantease :本文中算法2后,提出了具有加速实现的基本量化算法。quantease_outlier :本文中算法3之后具有加速实现的异常值量化算法。rtn :基线往返最终算法。gptq_quantease :GPTQ +量化的组合算法。在第一次迭代中用GPTQ初始化,然后在其上进行定量,以进一步优化性能。 data文件夹中的校准和评估数据集。QuantEase root dir”下创建models文件夹,然后下载以您喜欢的名称进行量化的HuggingFace模型。pip3 install -r requirements.txttorch :在v2.0.0+CU118上进行测试transformers :在v4.35.0上测试scipy :在V1.11.3上测试einops :在V0.7.0上测试datasets :在v2.14.7上测试scikit-learn :在V1.4.0上进行了测试sacrebleu :在v2.3.1上进行了测试auto-gptq :在V0.5.0上进行测试(仅用于包装模型),如果要打包和导出量化的型号,请按照AutoGPTQ页面上的指令进行安装https://github.com/panqiwei/autogptq所有脚本均已使用带有CUDA 12.0驱动程序API版本和11.2运行时API版本的单个A100 NVIDIA GPU计算机测试。
我们目前支持三个模型系列的量化:Bloom,Opt,Falcon,Mistral-7B,Llama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name :例如, bloom-560m , opt-350m和falcon-7b等。我们的脚本将自动根据模型名称选择相应的模型类型 /配置algorithm_name :从quantease , rtn和gptq_quantease中选择要启用异常值算法,请提供额外的论点: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name :从spqr和quantease中进行选择。注意:量化的outlier参数指示从每一层选择的权重百分比,但对于SPQR方法,它是指通常大于真实比率的outlier_relative_threshold ,请参阅原始纸质代码和纸张以获取更详细的超参数设置。要启用结构化离群器量化以进行量化,请在运行命令中添加--structure-outlier 。--compute-quantization-recon-error :在量化期间,在调试目的中显示每一层的重建错误。如果启用,则需要更多的时间和内存。--groupsize :用于量化的组;默认使用完整行。--act-order :是否要应用激活顺序GPTQ启发式,这是GPTQ代码库中的一项新功能,在大多数情况下显示出表现良好并减轻量化过程中的数值问题。--save <path_to_save_the_model_and_results> :启用JSON和量化模型包装/保存中保存的困惑结果。确保安装了auto-gptq软件包,以利用量化层和CUDA内核来帮助包装和保存模型。--num-layers-to-quantize :从上到下量化多少个块(主要用于调试目的)。 Biblatex条目:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdin在2023年夏季在LinkedIn实习时为这项工作做出了贡献。这项工作不是他的麻省理工学院研究的一部分。拉胡尔·马祖德(Rahul Mazumder)在LinkedIn的顾问(遵守MIT的外部专业活动政策)时为这项工作做出了贡献。这项工作不是他的麻省理工学院研究的一部分。


