QuantEase
1.0.0
يحتوي هذا المستودع على رموز الكمية الورقية: الكمية القائمة على التحسين لنماذج اللغة - خوارزمية فعالة وبديهية
مع تزايد شعبية نماذج اللغة الكبيرة (LLMS) ، هناك اهتمام متزايد بتقنيات الضغط لنشرها الفعال. تركز هذه الدراسة على قياس كمية ما بعد التدريب لـ LLMS ، وإدخال الكمية ، وهو إطار لتكييف الطبقة حيث تخضع الطبقات الفردية إلى كمية منفصلة. بتأطير المشكلة كتحسين غير منظم غير منظم ، يطور عملنا تقنيات نزول تنسيق ، ويقدم حلولًا عالية الجودة دون الحاجة إلى انعكاس المصفوفة أو التحلل. نستكشف أيضًا متغيرًا غريب الأطوار ، مع الحفاظ على أوزان كبيرة بدقة كاملة. يحقق اقتراحنا أداءً أحدث في التقييمات التجريبية عبر مختلف LLMs ومجموعات البيانات ، مع تحسينات تصل إلى 15 ٪ على أساليب مثل GPTQ. مع تحسينات الجبر الخطية الدقيقة ، تقوم الكميات بتقديم نماذج كمية مثل Falcon-180b على وحدة معالجة الرسومات Nvidia A100 واحدة في حوالي ثلاث ساعات. تحقق خوارزمية خارجة عن الكميات القريبة أو دون 3 بت مع انخفاض دقة مقبولة ، وتتفوق على أساليب مثل SPQR بمقدار ما يصل إلى مرتين من حيث الحيرة.
نتائج محيرة Wikitext2 المحددة لـ Bloom و OPT و Falcon Model Family بدون تجميع:
| اسم النموذج | FP16 | 4bit | 3bit | 3bitrictive outlier (1 ٪) | 3bit غير المنظم (1 ٪) |
|---|---|---|---|---|---|
| OPT-1.3B | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| OPT-13B | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| بلوم -1B7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| بلوم -7B1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| فالكون -7 ب | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| فالكون -40 ب | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
دقة الصفر الدقة على معيار Lambada لكميات 3 بت و 4 بت: 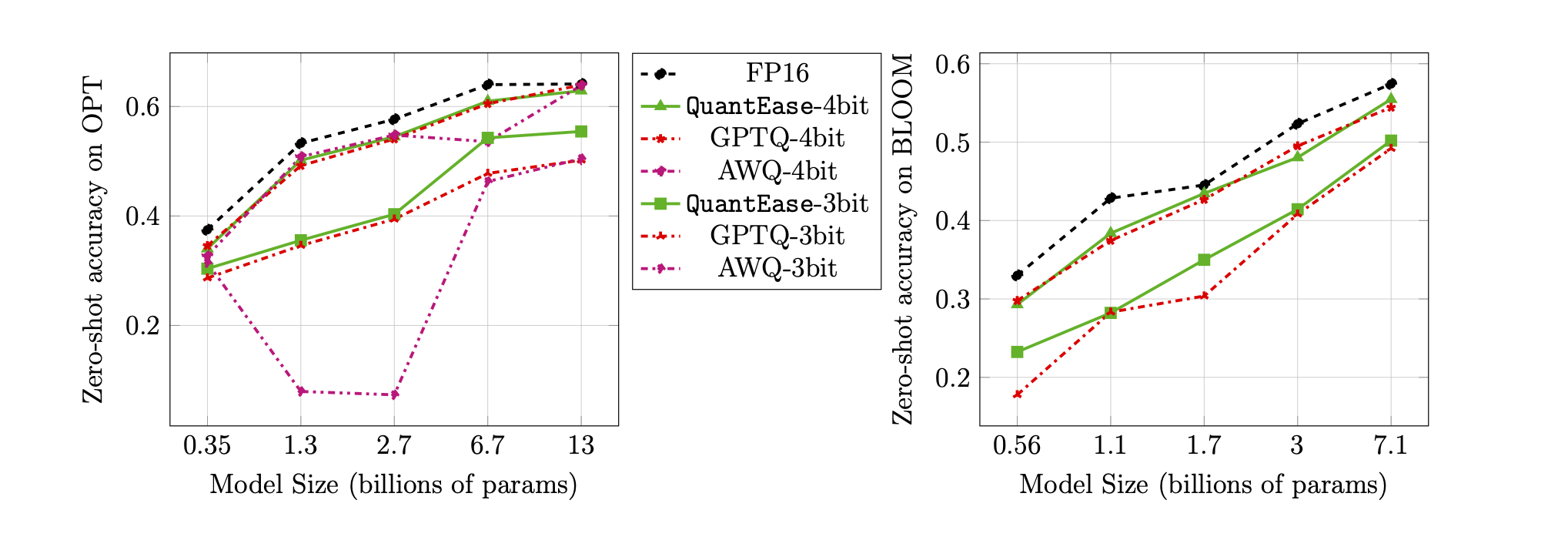
quantease : خوارزمية الكمية الأساسية المقترحة مع التنفيذ المتسارع بعد الخوارزمية 2 في الورقة.quantease_outlier : خوارزمية Quantive exklier مع التنفيذ المتسارع بعد الخوارزمية 3 في الورقة.rtn : خط الأساس حول الخوارزمية.gptq_quantease : خوارزمية مشتركة لـ GPTQ + Quantease. تهيئته مع GPTQ في التكرار الأول ، ثم قم بعمل كمي عليه لمزيد من تحسين الأداء. data .models تحت جذر QuantEase Dir وتنزيل نماذج Huggingface ليتم تقديرها فيها بالاسم الذي تفضله.pip3 install -r requirements.txttorch : تم اختباره على v2.0.0+Cu118transformers : تم اختبارها على v4.35.0scipy : تم اختباره على v1.11.3einops : تم اختباره على v0.7.0datasets : تم اختبارها على v2.14.7scikit-learn : تم اختباره على v1.4.0sacrebleu : تم اختباره على v2.3.1auto-gptq : تم اختباره على V0.5.0 (يستخدم لتعبئة النماذج فقط) ، إذا كنت ترغب في حزم وتصدير النموذج الكمي ، فيرجى اتباع التعليمات على صفحة AutogptQ لتثبيت https://github.com/panqiwei/Autogptqتم اختبار جميع البرامج النصية باستخدام آلة GPU A100 NVIDIA مع إصدار API CUDA 12.0 و 11.2 إصدار API.
نحن ندعم حاليًا تقدير كمية ثلاث عائلات نموذجية: Bloom ، OPT ، Falcon ، Mistral-7B ، Llama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name : EG ، bloom-560m ، opt-350m و falcon-7b ، إلخalgorithm_name : اختر من quantease و rtn و gptq_quantease لتمكين خوارزمية خارجة عن الراغبين ، يرجى تقديم حجة إضافية: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : اختر من spqr و quantease . ملاحظة: تشير الوسيطة outlier عن Quanteas إلى النسبة المئوية للأوزان التي يتعين اختيارها كقمان متطورة من كل طبقة ولكن بالنسبة لطريقة SPQR ، فإنها تشير إلى outlier_relative_threshold والتي غالبًا ما تكون أكبر من النسبة الخارجة الحقيقية ، يرجى الرجوع إلى رمز الورق الأصلي والورق لمزيد من التفصيل. لتمكين القياس الكمي المنظم من أجل الكمية ، يرجى إضافة --structure-outlier في الأمر قيد التشغيل.--compute-quantization-recon-error : أخطاء إعادة بناء العرض لكل طبقة أثناء القياس الكمي لغرض تصحيح الأخطاء. هناك حاجة إلى مزيد من الوقت والذاكرة إذا تم تمكينها.--groupsize : مجموعات لاستخدامها في القياس الكمي ؛ الافتراضي يستخدم الصف الكامل.--act-order : ما إذا كان لتطبيق أمر التنشيط GPTQ الإرشادي ، فهو ميزة جديدة في قاعدة كود GPTQ التي تظهر أنها تؤدي بشكل جيد في معظم الحالات وتخفيف القضية العددية أثناء القياس الكمي.--save <path_to_save_the_model_and_results> : تمكين نتائج الحيرة في الادخار في JSON والتعبئة/التوفير الكمي. تأكد من تثبيت حزمة auto-gptq للاستفادة من الطبقة الكمية و kernel cuda للمساعدة في حزم وحفظ النموذج.--num-layers-to-quantize : كم عدد الكتل التي يجب تحديدها من الأعلى إلى الأسفل (تستخدم بشكل رئيسي لغرض تصحيح الأخطاء). دخول Biblex:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}ساهم Kayhan Behdin في هذا العمل بينما كان متدربًا في LinkedIn خلال صيف عام 2023. هذا العمل ليس جزءًا من بحثه في معهد ماساتشوستس للتكنولوجيا. ساهم Rahul Mazumder في هذا العمل بينما كان مستشارًا لـ LinkedIn (وفقًا لسياسات الأنشطة المهنية الخارجية لـ MIT). هذا العمل ليس جزءًا من بحثه في معهد ماساتشوستس للتكنولوجيا.


