QuantEase
1.0.0
Este repositorio contiene los códigos para el papel cuantise: cuantización basada en la optimización para modelos de lenguaje: un algoritmo eficiente e intuitivo
Con la creciente popularidad de los modelos de idiomas grandes (LLM), existe un interés creciente en las técnicas de compresión para su implementación eficiente. Este estudio se centra en la cuantización posterior al entrenamiento para los LLM, la introducción de Quantese, un marco de cuantización en forma de capa donde las capas individuales experimentan cuantización separada. Enmarcando el problema como optimización no convexa estructurada discreta, nuestro trabajo desarrolla técnicas de descenso de coordenadas, ofreciendo soluciones de alta calidad sin la necesidad de inversión o descomposición de matriz. También exploramos una variante atípica consciente, preservando pesos significativos con una precisión completa. Nuestra propuesta logra el rendimiento de última generación en evaluaciones empíricas en varios LLM y conjuntos de datos, con mejoras de hasta el 15% sobre métodos como GPTQ. Con cuidadosas optimizaciones de álgebra lineal, Quantease cuantifica modelos como Falcon-180B en una sola GPU NVIDIA A100 en aproximadamente tres horas. El algoritmo atípico consciente se logra cuantización cercana o sub-3 bits con una caída de precisión aceptable, que superan los métodos como SPQR hasta dos veces en términos de perplejidad.
Resultados seleccionados de perplejidad Wikitext2 para la familia Modelo Bloom, Opt y Falcon sin agrupar:
| Nombre del modelo | FP16 | 4 bits | 3 bits | Atípico estructurado con 3 bits (1%) | Outlier no estructurado de 3 bits (1%) |
|---|---|---|---|---|---|
| Opt-1.3b | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| Opt-13b | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1b7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7b1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| Falcon-7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| Falcon-40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
Precisión de disparo cero en el punto de referencia de Lambada para cuantización de 3 bits y 4 bits: 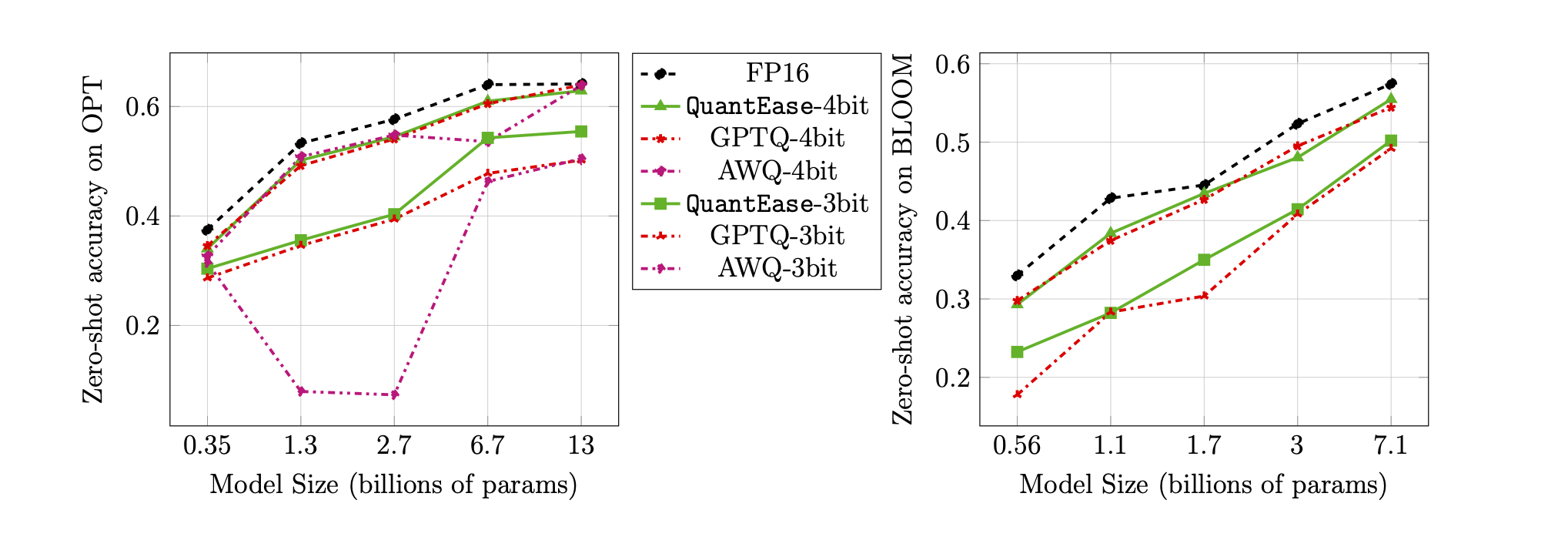
quantease : algoritmo básico de cuantose propuesto con implementación acelerada después del algoritmo 2 en el documento.quantease_outlier : algoritmo de QuantEess consciente de Atentude con implementación acelerada después del Algoritmo 3 en el documento.rtn : algoritmo de referencia de línea de base.gptq_quantease : un algoritmo combinado de GPTQ + Quantase. Inicializado con GPTQ en la primera iteración, y luego hace cuantose encima para una mayor optimización del rendimiento. data .models debajo del Dir de la raíz QuantEase y descargue los modelos Huggingface que se cuantificarán en ella con el nombre que prefirió.pip3 install -r requirements.txttorch : probado en v2.0.0+cu118transformers : probado en v4.35.0scipy : probado en v1.11.3einops : Probado en V0.7.0datasets : probado en v2.14.7scikit-learn : probado en v1.4.0sacrebleu : probado en v2.3.1auto-gptq : probado en V0.5.0 (utilizado solo para empacar los modelos), si desea empacar y exportar el modelo cuantificado, siga las instrucciones en la página AutoGPTQ para instalar https://github.com/panqiwei/autogptqTodos los scripts se han probado con una sola máquina GPU A100 NVIDIA con la versión API del controlador CUDA 12.0 y la versión API de tiempo de ejecución 11.2.
Actualmente apoyamos la cuantización de tres familias modelo: Bloom, Opt, Falcon, Mistral-7B, Llama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name : EG, bloom-560m , opt-350m y falcon-7b , etc. Nuestro script elegirá automáticamente el tipo / configuración del modelo correspondiente basado en el nombre del modeloalgorithm_name : elija entre quantease , rtn y gptq_quantease Para habilitar el algoritmo de Award-Award, proporcione argumento adicional: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : elija entre spqr y quantease . Nota: El argumento outlier para Quantase indica el porcentaje de pesos que se seleccionarán como valores atípicos de cada capa, pero para el método SPQR, se refiere al outlier_relative_threshold que a menudo es más grande que la relación de valores atípico verdadero, consulte el código de papel y el documento originales para obtener una configuración de hiperamter más detallada más detallada. Para habilitar la cuantización atípica estructurada para Quantise, agregue --structure-outlier en el comando en ejecución.--compute-quantization-recon-error : Muestra errores de reconstrucción para cada capa durante la cuantización para fines de depuración. Se necesita más tiempo y memoria si está habilitado.--groupsize : Grupesizar para usar para cuantización; El valor predeterminado usa la fila completa.--act-order : si se debe aplicar la orden de activación GPTQ Heuristic, es una nueva característica en la base de código GPTQ que se muestra que funciona bien en la mayoría de los casos y alivia el problema numérico durante la cuantificación.--save <path_to_save_the_model_and_results> : habilitar el ahorro de resultados de perplejidad en el empaque/ahorro del modelo cuantificado y el modelo cuantificado. Asegúrese de instalar el paquete auto-gptq para aprovechar la capa cuantlinal y el núcleo CUDA para ayudar a empacar y guardar el modelo.--num-layers-to-quantize : cuántos bloques cuantifican de arriba a abajo (se usa principalmente para fines de depuración). Entrada de Biblatex:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdin contribuyó a este trabajo mientras era pasante en LinkedIn durante el verano de 2023. Este trabajo no es parte de su investigación del MIT. Rahul Mazumder contribuyó a este trabajo mientras era consultor de LinkedIn (de conformidad con las políticas de actividades profesionales externas del MIT). Este trabajo no es parte de su investigación del MIT.


