QuantEase
1.0.0
Ce référentiel contient les codes pour le papier quantique: quantification basée sur l'optimisation pour les modèles de langage - un algorithme efficace et intuitif
Avec la popularité croissante des modèles de grandes langues (LLM), il y a un intérêt croissant pour les techniques de compression pour leur déploiement efficace. Cette étude se concentre sur la quantification post-entraînement pour les LLM, l'introduction de Quantonase, un cadre de quantification par couche où les couches individuelles subissent une quantification distincte. En encadrant le problème comme une optimisation non structurée discrète, notre travail développe des techniques de descente de coordonnées, offrant des solutions de haute qualité sans avoir besoin d'inversion ou de décomposition matricielle. Nous explorons également une variante de valeur aberrante, préservant des poids importants avec une précision complète. Notre proposition atteint des performances de pointe dans des évaluations empiriques dans divers LLM et ensembles de données, avec jusqu'à 15% d'améliorations par rapport aux méthodes comme GPTQ. Avec des optimisations d'algèbre linéaires prudentes, Quantalase quantise des modèles comme Falcon-180B sur un seul GPU NVIDIA A100 en environ trois heures. L'algorithme de la valeur aberrante atteint la quantification proche ou sous-3 bits avec une baisse de précision acceptable, sur-performant des méthodes comme SPQR jusqu'à deux fois en termes de perplexité.
Sélection des résultats de perplexité Wikitext2 pour la famille Bloom, OPT et Falcon sans regroupement:
| Nom du modèle | FP16 | 4 bits | 3 bits | Aberbe-structurée à 3 bits (1%) | Superbe à 3 bits (1%) |
|---|---|---|---|---|---|
| Opt-1.3b | 14.62 | 15.28 | 21h30 | 18.51 | 16.25 |
| Opt-13b | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1b7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7b1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| Falcon-7B | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| Falcon-40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
Précision zéro-shot sur la référence Lambada pour la quantification 3 bits et 4 bits: 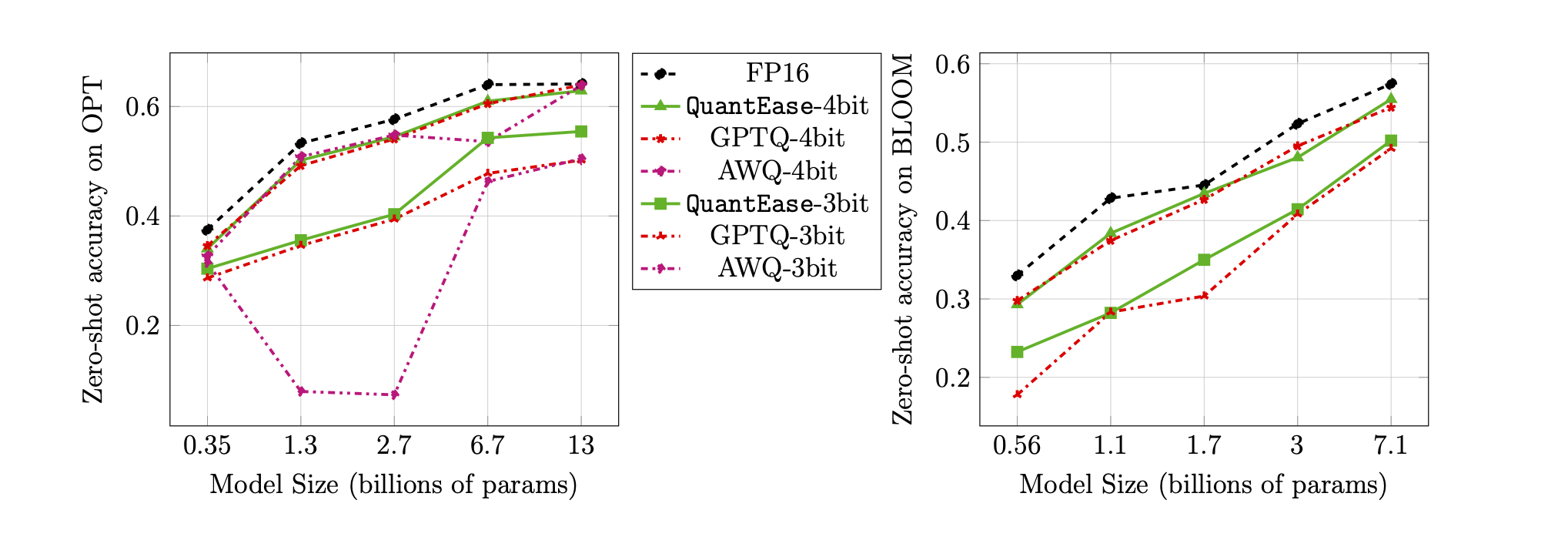
quantease : algorithme de quanton de base proposé avec implémentation accélérée suivant l'algorithme 2 dans le document.quantease_outlier : Algorithme QuantalEase comprise avec la valeur aberrante avec une implémentation accélérée après l'algorithme 3 dans le document.rtn : algorithme de base rond-to-plus nécessaire.gptq_quantease : Un algorithme combiné de GPTQ + Quantonase. Initialisé avec GPTQ dans la première itération, puis effectuez une quanquette en plus pour une optimisation des performances supplémentaires. data .models sous le QuantEase ROOT DIR et télécharger les modèles HuggingFace à quantifier avec le nom que vous préférez.pip3 install -r requirements.txttorch : testé sur v2.0.0 + Cu118transformers : Testé sur V4.35.0scipy : testé sur v1.11.3einops : testé sur V0.7.0datasets : testés sur v2.14.7scikit-learn : testé sur v1.4.0sacrebleu : testé sur v2.3.1auto-gptq : Testé sur V0.5.0 (utilisé pour emballer les modèles uniquement), si vous souhaitez emballer et exporter le modèle quantifié, veuillez suivre les instructions sur la page AutogptQ pour installer https://github.com/panqiwei/autogptqTous les scripts ont été testés avec une machine GPU NVIDIA unique A100 avec la version API du pilote CUDA 12.0 et la version API d'exécution 11.2.
Nous soutenons actuellement la quantification de trois familles de modèles: Bloom, Opt, Falcon, Mistral-7b, lama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name : par exemple, bloom-560m , opt-350m et falcon-7b , etc. Notre script choisira automatiquement le type de modèle / configuration correspondant en fonction du nom du modèlealgorithm_name : choisissez parmi quantease , rtn et gptq_quantease Pour activer l'algorithme de la valeur aberrante, veuillez fournir un argument supplémentaire: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : Choisissez parmi spqr et quantease . Remarque: L'argument de outlier pour Quantifier indique le pourcentage de poids à sélectionner comme valeurs aberrantes de chaque couche mais pour la méthode SPQR, il se réfère à la outlier_relative_threshold qui est souvent plus grande que le véritable rapport de la valeur aberrante, veuillez vous référer au code papier d'origine et au papier pour une configuration d'hyperparamter plus détaillée. Pour activer la quantification de la valeur aberrante structurée pour QuankingEase, veuillez ajouter --structure-outlier dans la commande en cours d'exécution.--compute-quantization-recon-error : Affichez les erreurs de reconstruction pour chaque couche pendant la quantification à des fins de débogage. Plus de temps et de mémoire sont nécessaires si vous êtes activé.--groupsize : GroupeSize à utiliser pour la quantification; Par défaut utilise la ligne complète.--act-order : Il faut appliquer l'ordre d'activation GPTQ HEURIST, c'est une nouvelle fonctionnalité dans la base de code GPTQ qui se déroule bien dans la plupart des cas et atténue le problème numérique pendant la quantification.--save <path_to_save_the_model_and_results> : Activer les résultats de perplexité Sauvegarde dans JSON et l'emballage / enregistrement du modèle quantifié. Assurez-vous que vous avez installé le package auto-gptq pour tirer parti de la couche Quantlinear et du noyau Cuda pour aider à emballer et à enregistrer le modèle.--num-layers-to-quantize : combien de blocs à quantifier de haut en bas (principalement utilisés à des fins de débogage). Entrée Biblatex:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdin a contribué à ce travail alors qu'il était stagiaire chez LinkedIn pendant l'été 2023. Ce travail ne fait pas partie de ses recherches sur le MIT. Rahul Mazumder a contribué à ce travail alors qu'il était consultant pour LinkedIn (conformément aux politiques des activités professionnelles externes du MIT). Ce travail ne fait pas partie de ses recherches sur le MIT.


