QuantEase
1.0.0
이 저장소에는 용지 Quantease의 코드가 포함되어 있습니다 : 언어 모델의 최적화 기반 양자화 - 효율적이고 직관적 인 알고리즘
LLM (Largin Language Model)의 인기가 높아짐에 따라 효율적인 배포를위한 압축 기술에 대한 관심이 높아지고 있습니다. 이 연구는 개별 층이 별도의 양자화를 겪는 층별 양자화 프레임 워크 인 LLM에 대한 훈련 후 양자화에 중점을 둡니다. 이산 구조화되지 않은 비 컨버드 최적화로 문제를 프레임하는 우리의 작업은 조정 된 하강 기술을 개발하여 매트릭스 역전 또는 분해없이 고품질 솔루션을 제공합니다. 우리는 또한 범죄자 인식 변형을 탐색하여 완전한 정밀도로 중요한 가중치를 보존합니다. 우리의 제안은 다양한 LLM 및 데이터 세트에서 경험적 평가에서 최첨단 성과를 달성하며 GPTQ와 같은 방법에 비해 최대 15%가 개선됩니다. 신중한 선형 대수 최적화를 통해, 양자 제제는 약 3 시간 안에 단일 NVIDIA A100 GPU에서 FALCON-180B와 같은 모델을 정량화합니다. 이상치 인식 알고리즘은 허용 가능한 정확도 낙하, SPQR과 같은 우수한 방법으로 당연한 측면에서 최대 2 배나 더 성능이 우수한 방법을 달성합니다.
Bloom, Opt 및 Falcon Model 제품군에 대한 선택된 Wikitext2 Perplexity 결과를 그룹화하지 않고 :
| 모델 이름 | FP16 | 4 비트 | 3 비트 | 3 비트 구조화 된 이상 (1%) | 3 비트-구조화 된 특이점 (1%) |
|---|---|---|---|---|---|
| OPT-1.3B | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| OPT-13B | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1B7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| 블룸 -7b1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| 팔콘 -7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| 팔콘 -40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
3 비트 및 4 비트 양자화에 대한 Lambada 벤치 마크의 제로 샷 정확도 : 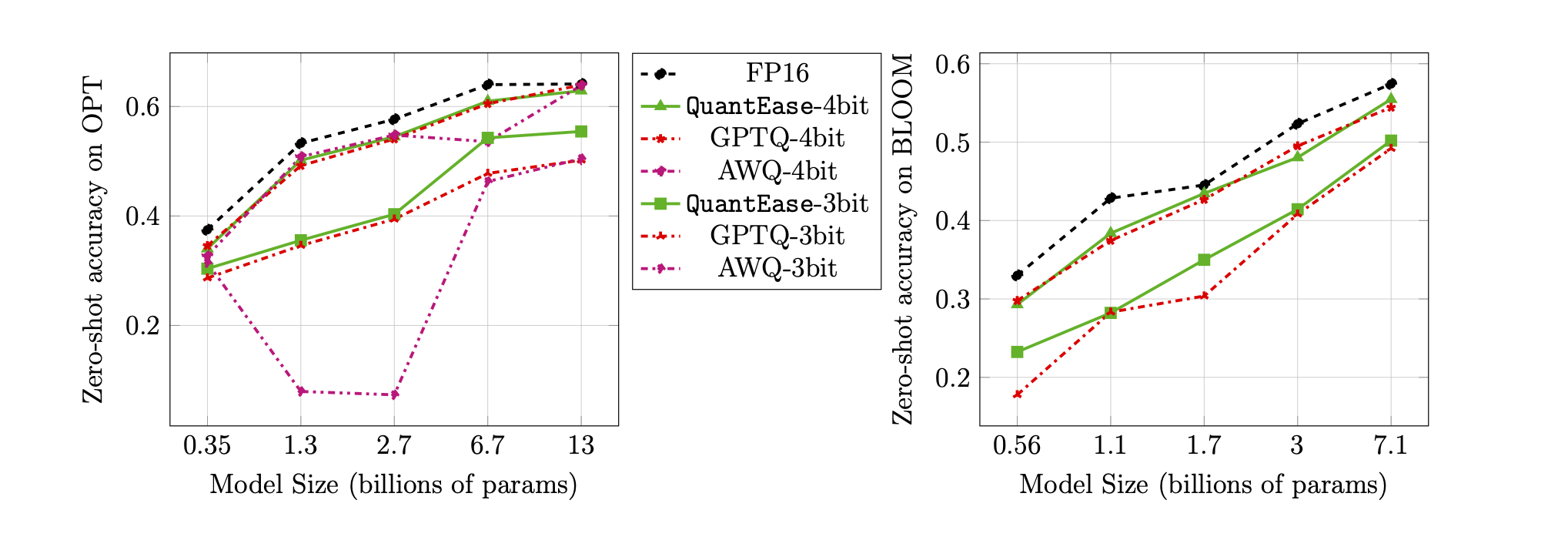
quantease : 논문에서 알고리즘 2에 따라 구현 된 구현이있는 기본 양자 알고리즘을 제안했습니다.quantease_outlier : 논문에서 알고리즘 3에 이어 구현 된 구현이있는 Onder-Aware Quantease 알고리즘.rtn : 기준선에서 가장 큰 알고리즘.gptq_quantease : GPTQ + Quantease의 결합 된 알고리즘. 첫 번째 반복에서 GPTQ로 초기화 한 다음 추가 성능 최적화를 위해 IT 위에 양자를 수행합니다. data 폴더에서 교정 및 평가 데이터 세트를 준비합니다.QuantEase Root Dir 아래에서 models 폴더를 만들고 Huggingface 모델을 다운로드하여 선호하는 이름으로 정량화하십시오.pip3 install -r requirements.txttorch : v2.0.0+Cu118에서 테스트transformers : v4.35.0에서 테스트scipy : v1.11.3에서 테스트einops : V0.7.0에서 테스트datasets : v2.14.7에서 테스트scikit-learn : V1.4.0에서 테스트sacrebleu : v2.3.1에서 테스트auto-gptq : V0.5.0에서 테스트 됨 (모델 만 포장하는 데 사용), 양자화 된 모델을 포장하고 내보내려면 AutoGPTQ 페이지의 명령어를 따라 https://github.com/panqiwei/autogptq를 설치하십시오.모든 스크립트는 CUDA 12.0 드라이버 API 버전과 11.2 런타임 API 버전이있는 단일 A100 NVIDIA GPU 머신으로 테스트했습니다.
우리는 현재 Bloom, Opt, Falcon, Mistral-7b, Llama의 세 가지 모델 패밀리의 양자화를 지원합니다.
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name : 예 : 예 : bloom-560m , opt-350m 및 falcon-7b 등. 스크립트는 모델 이름을 기반으로 해당 모델 유형 / 구성을 자동으로 선택합니다.algorithm_name : quantease , rtn 및 gptq_quantease 를 선택하십시오 이상적인 인식 알고리즘을 활성화하려면 추가 인수를 제공하십시오. --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : spqr 및 quantease 에서 선택하십시오. 참고 : Quantease에 대한 outlier 인수는 각 층의 특이 치로 선택할 가중치의 백분율을 나타내지 만 SPQR 방법의 경우 종종 실제 특이 치 비율보다 더 큰 outlier_relative_threshold 를 나타냅니다. 더 자세한 하이퍼 파라미터 설정은 원래 용지 코드 및 용지를 참조하십시오. Quantease에 대한 구조화 된 특이점 양자화를 활성화하려면 런닝 명령에 --structure-outlier 추가하십시오.--compute-quantization-recon-error : 디버깅 목적을위한 양자화 동안 각 층에 대한 재구성 오류를 표시합니다. 활성화되면 더 많은 시간과 기억이 필요합니다.--groupsize : 양자화에 사용하기 위해 그룹화; 기본값은 전체 행을 사용합니다.--act-order : 활성화 순서 GPTQ 휴리스틱을 적용할지 여부에 관계없이 GPTQ 코드베이스의 새로운 기능으로 대부분의 경우 성능이 좋으며 양자화 중 수치 문제를 완화합니다.--save <path_to_save_the_model_and_results> : JSON 및 양자화 된 모델 포장/저장에서 당황한 결과를 절약 할 수 있습니다. Quantlinear 레이어와 Cuda 커널을 활용하여 모델을 포장하고 저장하는 데 도움이되도록 auto-gptq 패키지를 설치해야합니다.--num-layers-to-quantize : 위에서 아래로 양자화 할 블록 수 (주로 디버깅 목적으로 사용). Biblatex 항목 :
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdin은 2023 년 여름 Linkedin에서 인턴이었던 동안이 작업에 기여했습니다.이 작업은 그의 MIT 연구의 일부가 아닙니다. Rahul Mazumder는 LinkedIn의 컨설턴트 인 동안이 작업에 기여했습니다 (MIT의 외부 전문 활동 정책에 따라). 이 작품은 그의 MIT 연구의 일부가 아닙니다.


