QuantEase
1.0.0
Dieses Repository enthält die Codes für die Papierquantase: Optimierungsbasierte Quantisierung für Sprachmodelle - ein effizienter und intuitiver Algorithmus
Mit der wachsenden Popularität von Großsprachemodellen (LLMs) besteht ein zunehmendes Interesse an Komprimierungstechniken für ihren effizienten Einsatz. Diese Studie konzentriert sich auf die Quantisierung von LLMs nach dem Training und führt die Quantase ein, ein schichtwise Quantisierungsgerüst, in dem einzelne Schichten eine separate Quantisierung unterzogen werden. Unsere Arbeiten als diskrete nicht konvexe Optimierung von diskreter nicht konvexer Optimierung entwickelt Koordinaten-Abstammungstechniken und bietet hochwertige Lösungen, ohne dass eine Matrixinversion oder -zersetzung erforderlich ist. Wir untersuchen auch eine ausreißigere Variante und bewahren signifikante Gewichte mit vollständiger Präzision auf. Unser Vorschlag erzielt eine modernste Leistung in empirischen Bewertungen in verschiedenen LLMs und Datensätzen mit bis zu 15% Verbesserungen gegenüber Methoden wie GPTQ. Mit sorgfältigen linearen Algebra-Optimierungen quantieren Quantase Modelle wie Falcon-180b in einer einzelnen NVIDIA A100 GPU in ungefähr drei Stunden. Der ausreißerbewusste Algorithmus erreicht mit einem akzeptablen Genauigkeitsabfall in der Nähe oder der Sub-3-Bit-Quantisierung und übertreffen Methoden wie SPQR in Bezug auf Verwirrung um bis zu zweimal.
Ausgewählte Wikitext2 -Verwirrigkeitsergebnisse für Blüte-, OPT- und Falcon -Modellfamilie ohne Gruppierung:
| Modellname | FP16 | 4bit | 3bit | 3bit-strukturierter Ausreißer (1%) | 3-Bit-nicht-Ausreißer (1%) |
|---|---|---|---|---|---|
| Opt-1.3b | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| Opt-13b | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1b7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7b1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| Falcon-7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| Falcon-40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
Null-Shot-Genauigkeit am Lambada-Benchmark für 3-Bit- und 4-Bit-Quantisierung: 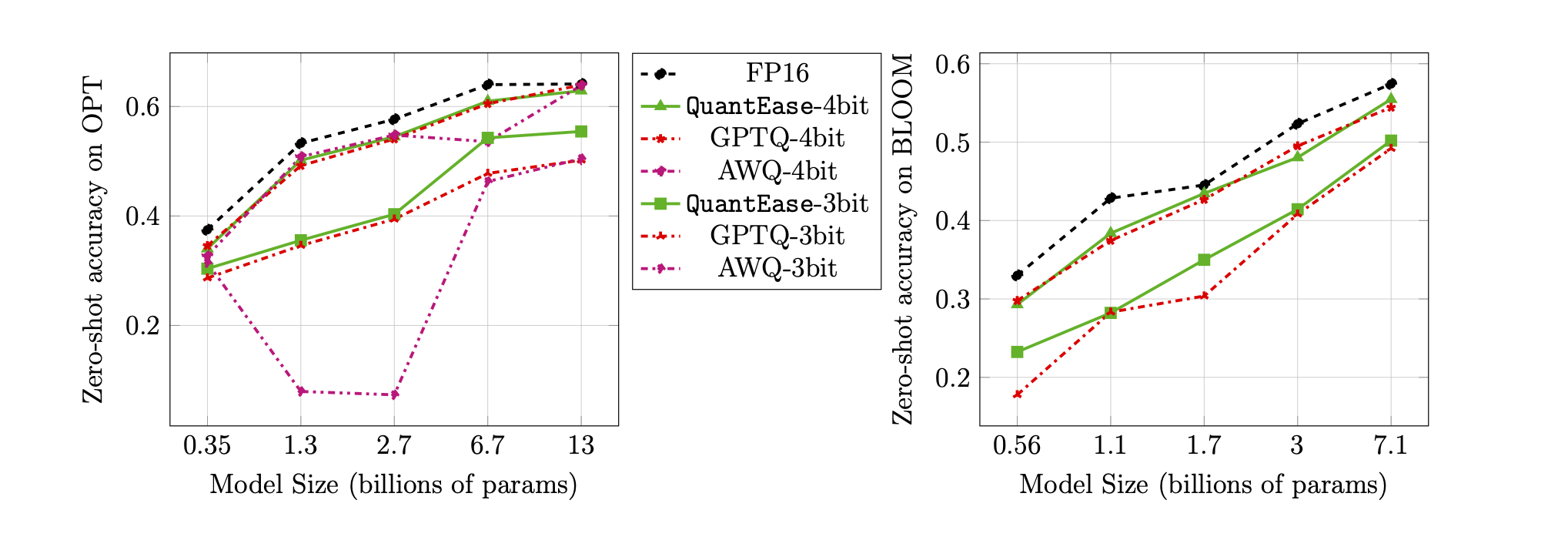
quantease : Der vorgeschlagene Basis -Quantase -Algorithmus mit beschleunigter Implementierung nach Algorithmus 2 im Papier.quantease_outlier : Ausreißer-bewusster Quantase-Algorithmus mit beschleunigter Implementierung nach Algorithmus 3 im Papier.rtn : Basis-Algorithmus mit dem Rundlinie.gptq_quantease : Ein kombinierter Algorithmus von GPTQ + Quantase. Initialisiert mit GPTQ in der ersten Iteration und dann eine Quantase darüber, um eine weitere Leistungsoptimierung zu erhalten. data vor.models unter der QuantEase Root Dir. Und Laden Sie die von Ihnen bevorzugten Namen, die Sie bevorzugt haben, die Quantifizierung der Suggingface -Modelle herunter.pip3 install -r requirements.txttorch : getestet auf v2.0.0+Cu118transformers : getestet auf v4.35.0scipy : getestet auf v1.11.3einops : getestet auf v0.7.0datasets : getestet auf v2.14.7scikit-learn : getestet auf v1.4.0sacrebleu : getestet auf v2.3.1auto-gptq : getestet auf v0.5.0 (verwendet nur zum Packen der Modelle). Wenn Sie das quantisierte Modell packen und exportieren möchten, befolgen Sie bitte die Anweisung auf der Seite autogptq, um https://github.com/panqiwei/autogptq zu installierenAlle Skripte wurden mit einer einzigen A100 NVIDIA -GPU -Maschine mit CUDA 12.0 -Treiber -API -Version und 11.2 Runtime -API -Version getestet.
Wir unterstützen derzeit die Quantisierung von drei Modellfamilien: Bloom, Opt, Falcon, Mistral-7b, Llama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name opt-350m bloom-560m falcon-7balgorithm_name : Wählen Sie aus quantease , rtn und gptq_quantease Um einen Ausreißeralgorithmus zu ermöglichen, geben Sie bitte zusätzliche Argumente an: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : Wählen Sie aus spqr und quantease . HINWEIS: Das outlier für Quantase zeigt den Prozentsatz der Gewichte an, die als Ausreißer aus jeder Schicht ausgewählt werden sollen. Für die SPQR -Methode bezieht er sich jedoch auf den outlier_relative_threshold , der häufig größer ist als das wahre Ausreißerverhältnis. Weitere Informationen finden Sie im ursprünglichen Papiercode und auf dem Papier für detaillierteres Hyperparamter -Setup. Um die strukturierte Ausreißerquantisierung für Quantase zu aktivieren, fügen Sie bitte --structure-outlier im Laufbefehl hinzu.--compute-quantization-recon-error : Zeigen Sie Rekonstruktionsfehler für jede Schicht während der Quantisierung zum Debugging-Zweck an. Es sind mehr Zeit und Speicher erforderlich, wenn es aktiviert ist.--groupsize : gruppiert zur Quantisierung verwendet; Standard verwendet die vollständige Zeile.--act-order : Ob die Aktivierungsreihenfolge GPTQ Heuristic anwendet, ist eine neue Funktion in GPTQ-Codebasis, die in den meisten Fällen gut abschneidet und das numerische Problem während der Quantisierung lindert.--save <path_to_save_the_model_and_results> : Aktivieren Sie Verwirrigkeitsergebnisse in JSON und quantisierte Modellverpackung/-sparung. Stellen Sie sicher, dass Sie auto-gptq -Paket installiert haben, um die quantlineare Schicht und den Cuda-Kernel zu nutzen, um das Modell zu packen und zu speichern.--num-layers-to-quantize : Wie viele Blöcke von oben nach unten quantisieren (hauptsächlich zum Debugging-Zweck). Biblatex -Eintrag:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdin trug zu dieser Arbeit bei, als er im Sommer 2023 Praktikant bei Linkedin war. Diese Arbeit ist nicht Teil seiner MIT -Forschung. Rahul Mazumder trug zu dieser Arbeit bei, während er Berater für LinkedIn war (in Übereinstimmung mit den Richtlinien für externe berufliche Aktivitäten von MIT). Diese Arbeit ist nicht Teil seiner MIT -Forschung.


