QuantEase
1.0.0
Este repositório contém os códigos para a quantização do papel: quantização baseada em otimização para modelos de linguagem - um algoritmo eficiente e intuitivo
Com a crescente popularidade de grandes modelos de linguagem (LLMS), há um interesse crescente em técnicas de compressão para sua implantação eficiente. Este estudo se concentra na quantização pós-treinamento para LLMs, introduzindo o QuantEase, uma estrutura de quantização em camada em que camadas individuais passam por quantização separada. Enquadrando o problema como otimização não convexa de estrutura discreta, nosso trabalho desenvolve técnicas de descida de coordenadas, oferecendo soluções de alta qualidade sem a necessidade de inversão ou decomposição da matriz. Também exploramos uma variante de consciência externa, preservando pesos significativos com precisão completa. Nossa proposta atinge o desempenho de ponta em avaliações empíricas em vários LLMs e conjuntos de dados, com melhorias de até 15% em relação a métodos como o GPTQ. Com otimizações de álgebra linear cuidadosas, o QuantEase quantiza modelos como o Falcon-180B em uma única GPU da NVIDIA A100 em aproximadamente três horas. O algoritmo com reconhecimento de outlier atinge a quantização próxima ou sub-3 bits com uma queda de precisão aceitável, superando métodos como o SPQR em até duas vezes em termos de perplexidade.
Resultados selecionados do Wikitext2 Perplexity para a família Bloom, Opt e Falcon Model sem agrupar:
| Nome do modelo | FP16 | 4 bits | 3 bits | Outlier estruturado de 3 bits (1%) | Outlier de 3 bits (1%) |
|---|---|---|---|---|---|
| OPT-1.3b | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| Opt-13b | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1b7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7b1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| Falcon-7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| Falcon-40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
Precisão de tiro zero na referência Lambada para quantização de 3 e 4 bits: 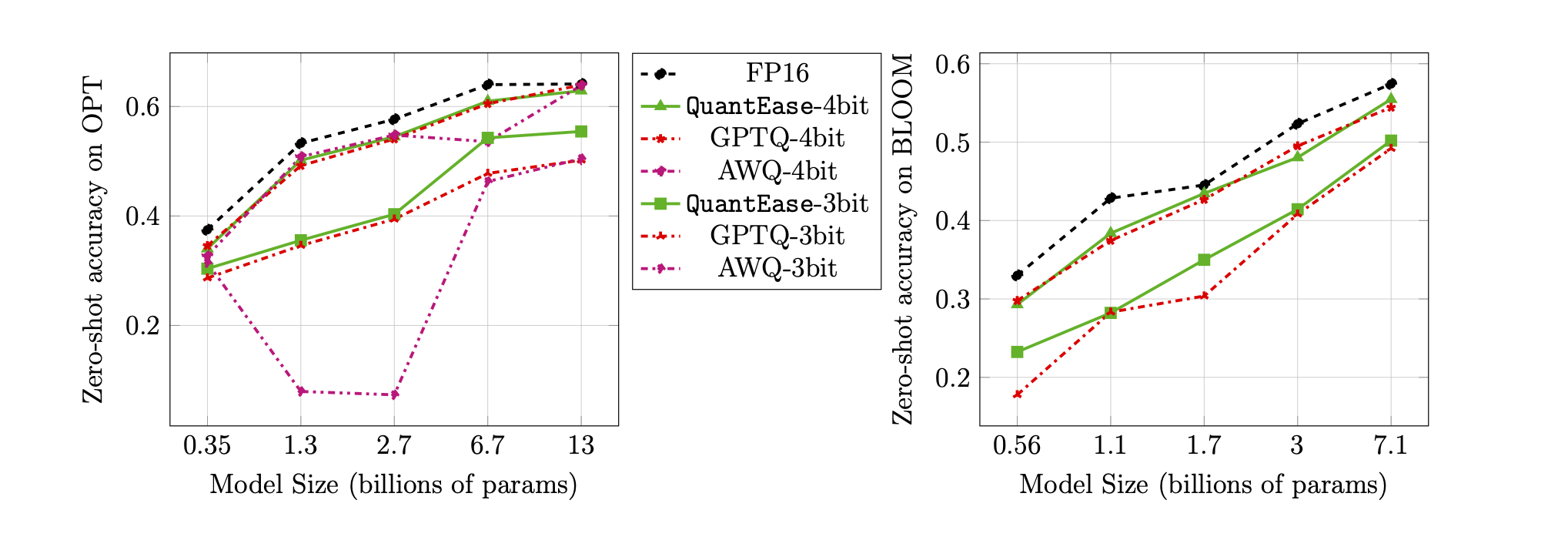
quantease : Algoritmo básico de quantia proposto com implementação acelerada após o algoritmo 2 no artigo.quantease_outlier : algoritmo de quantia com reconhecimento de outlier com implementação acelerada após o algoritmo 3 no artigo.rtn : Algoritmo de redonda de linha de base para o mais próximo.gptq_quantease : Um algoritmo combinado de GPTQ + Quantase. Inicializado com o GPTQ na primeira iteração e, em seguida, quantifique por ele para maior otimização de desempenho. data .models sob o DIR QuantEase Root e faça o download dos modelos Huggingface a serem quantizados com o nome que você prefere.pip3 install -r requirements.txttorch : testado em v2.0.0+Cu118transformers : testado na v4.35.0scipy : testado na v1.11.3einops : testado em v0.7.0datasets : testado na v2.14.7scikit-learn : testado em v1.4.0sacrebleu : testado em v2.3.1auto-gptq : Testado na v0.5.0 (usado apenas para embalar os modelos), se você deseja embalar e exportar o modelo quantizado, siga as instruções na página AutoGPTQ para instalar https://github.com/panqiwei/autogptqTodos os scripts foram testados com a máquina A100 NVIDIA GPU com a versão da API do driver CUDA 12.0 e a versão de API de tempo de execução 11.2.
Atualmente, apoiamos a quantização de três famílias modelo: Bloom, Opt, Falcon, Mistral-7b, Llama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name : por exemplo, bloom-560m , opt-350m e falcon-7b , etc. Nosso script escolherá automaticamente o tipo de modelo correspondente / configuração com base no nome do modeloalgorithm_name : escolha entre quantease , rtn e gptq_quantease Para habilitar o algoritmo de reconhecimento outlier, forneça um argumento extra: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : escolha no spqr e quantease . NOTA: O argumento outlier da quantia indica a porcentagem de pesos a serem selecionados como outliers de cada camada, mas para o método SPQR, refere -se ao outlier_relative_threshold , que geralmente é maior que a verdadeira proporção outlier, consulte o código e o papel originais para obter uma configuração hiperparamter mais detalhada. Para ativar a quantização externa estruturada para quantia, adicione --structure-outlier no comando em execução.--compute-quantization-recon-error : Exibir erros de reconstrução para cada camada durante a quantização para fins de depuração. Mais tempo e memória são necessários se ativados.--groupsize : Groupsize usar para quantização; O padrão usa a linha completa.--act-order : Se você deve aplicar a ordem de ativação GPTQ Heuristic, é um novo recurso na Base GPTQ que se mostra bem na maioria dos casos e alivia a questão numérica durante a quantização.--save <path_to_save_the_model_and_results> : Ativar resultados da perplexidade Economizando em JSON e Quantized Model Packing/Saving. Certifique-se de instalar o pacote auto-gptq para aproveitar a camada Quantlinear e o kernel CUDA para ajudar a embalar e salvar o modelo.--num-layers-to-quantize : quantos blocos quantizam de cima para baixo (usados principalmente para fins de depuração). Entrada do Biblatex:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdin contribuiu para este trabalho enquanto era estagiário no LinkedIn durante o verão de 2023. Este trabalho não faz parte de sua pesquisa no MIT. Rahul Mazumder contribuiu para este trabalho enquanto era consultor do LinkedIn (em conformidade com as políticas de atividades profissionais externas do MIT). Este trabalho não faz parte de sua pesquisa no MIT.


