QuantEase
1.0.0
このリポジトリには、論文のコードが含まれています。
大規模な言語モデル(LLMS)の人気が高まっているため、効率的な展開のための圧縮技術に関心が高まっています。この研究は、LLMSのトレーニング後の量子化に焦点を当て、個々の層が個別の量子化を受ける層ごとの量子化フレームワークであるQuanteaseを導入します。この問題を離散構造の非凸最適化としてフレーミングすると、私たちの研究は座標降下技術を開発し、マトリックスの反転または分解を必要とせずに高品質のソリューションを提供します。また、異常値の異なるバリアントを探索し、完全な精度で有意な重みを保存します。私たちの提案は、さまざまなLLMSおよびデータセットにわたって経験的評価において最先端のパフォーマンスを達成し、GPTQのような方法よりも最大15%の改善があります。慎重な線形代数の最適化により、Quanteaseは、約3時間で単一のNvidia A100 GPUでFalcon-180Bのようなモデルを量子化します。外れ値に認識されたアルゴリズムは、許容される精度ドロップを使用して、またはSPQRのようなアウトパフォーマンス方法を使用して、近くまたはサブ3ビットの量子化を実現します。
グループ化なしで、Bloom、Opt、およびFalconモデルファミリの選択されたWikitext2困惑の結果:
| モデル名 | FP16 | 4ビット | 3ビット | 3ビット構造の外れ値(1%) | 3ビット非構造外れ値(1%) |
|---|---|---|---|---|---|
| OPT-1.3B | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| OPT-13B | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1B7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7B1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| ファルコン-7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| ファルコン-40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
3ビットおよび4ビット量子化のランバダベンチマークのゼロショット精度: 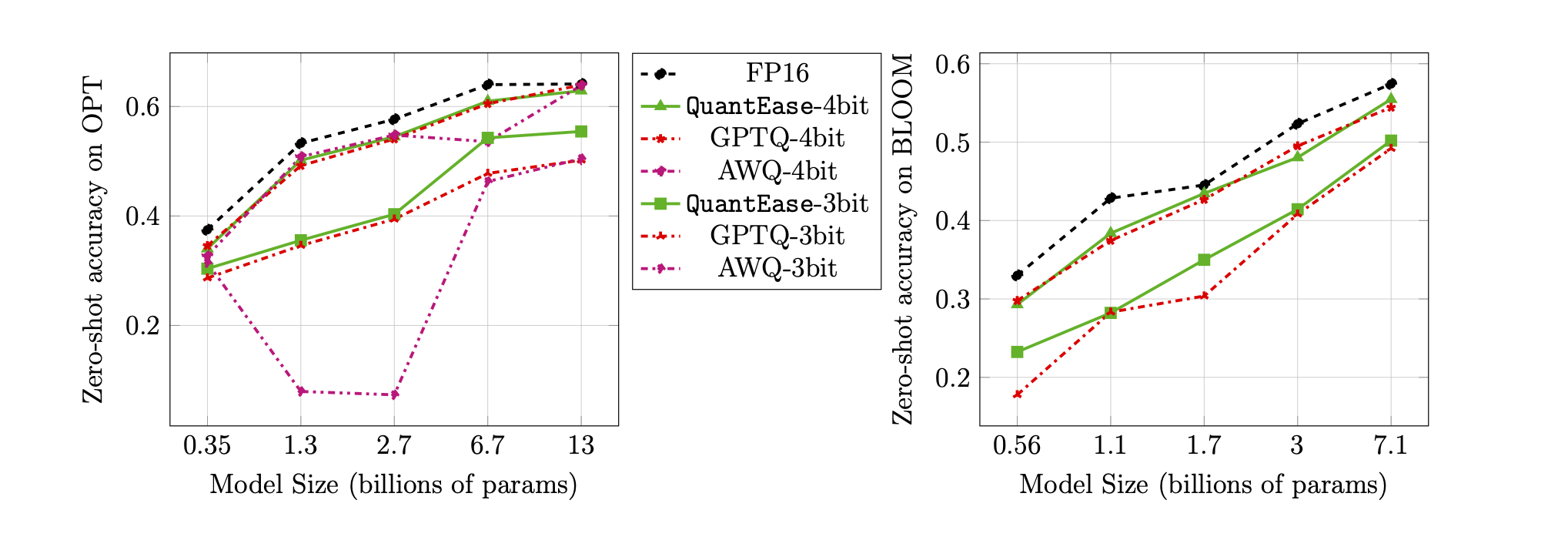
quantease :提案された基本的なQuanteaseアルゴリズムは、論文のアルゴリズム2に従って実装を加速します。quantease_outlier :論文のアルゴリズム3に従って実装が加速した外れ値のQuanteaseアルゴリズム。rtn :ベースラインラウンドツーアリースアルゴリズム。gptq_quantease :GPTQ + Quanteaseの組み合わせアルゴリズム。最初のイテレーションでGPTQで初期化され、その上に測定され、パフォーマンスの最適化をさらに最適化します。 dataフォルダーのキャリブレーションデータセットと評価データセットを準備します。QuantEase Root dirの下にmodelsフォルダーを作成し、希望する名前で定量化するハグするフェイスモデルをダウンロードしてください。pip3 install -r requirements.txttorch :V2.0.0+Cu118でテストtransformers :V4.35.0でテストscipy :v1.11.3でテストeinops :v0.7.0でテストdatasets :V2.14.7でテストされていますscikit-learn :V1.4.0でテストsacrebleu :V2.3.1でテストauto-gptq :v0.5.0でテストされています(モデルのみの梱包に使用)Quantizedモデルを梱包およびエクスポートする場合は、autogptqページの命令に従ってhttps://github.com/panqiwei/autogptqをインストールしてくださいすべてのスクリプトは、CUDA 12.0ドライバーAPIバージョンと11.2ランタイムAPIバージョンを備えたシングルA100 NVIDIA GPUマシンでテストされています。
現在、Bloom、Opt、Falcon、Mistral-7B、Llamaの3つのモデルファミリの量子化をサポートしています
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name :例えば、 bloom-560m 、 opt-350m 、 falcon-7bなど。スクリプトは、モデル名に基づいて対応するモデルタイプ /構成を自動的に選択しますalgorithm_name : quantease 、 rtn 、 gptq_quanteaseから選択します外れ値の認識アルゴリズムを有効にするには、追加の議論を提供してください: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : spqrとquanteaseから選択します。注: Quanteaseのoutlierの引数は、各レイヤーの外れ値として選択される重みの割合を示しますが、SPQRメソッドの場合、それはTrue Outlier比より大きいことが多いoutlier_relative_thresholdを指します。 Quanteaseの構造化された外れ値の量子化を有効にするには、実行中のコマンドに--structure-outlierを追加してください。--compute-quantization-recon-error :デバッグ目的のための量子化中に、各レイヤーの再構築エラーを表示します。有効にすると、より多くの時間とメモリが必要です。--groupsize :量子化に使用するためにグループ化。デフォルトは完全な行を使用します。--act-order :Activation Order GPTQ Heuristicを適用するかどうかにかかわらず、これはGPTQコードベースの新機能であり、ほとんどの場合、量子化中に数値問題を軽減することが示されています。--save <path_to_save_the_model_and_results> :JSONで浸透した結果を有効にして、モデルの梱包/保存を量子化します。 auto-gptqパッケージをインストールして、QuantlinearレイヤーとCuda Kernelを活用して、モデルの梱包と保存を支援してください。--num-layers-to-quantize :上から下まで量子化するブロック数(主にデバッグ目的に使用されます)。 Biblatexエントリ:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdinは、2023年夏にLinkedInでインターンを務めている間、この作業に貢献しました。この作業は彼のMIT研究の一部ではありません。 Rahul Mazumderは、LinkedInのコンサルタントである間にこの作業に貢献しました(MITの外部の専門活動ポリシーに準拠しています)。この作品は彼のMIT研究の一部ではありません。


