QuantEase
1.0.0
Repositori ini berisi kode untuk kuantase kertas: kuantisasi berbasis optimisasi untuk model bahasa - algoritma yang efisien dan intuitif
Dengan semakin populernya model bahasa besar (LLM), ada peningkatan minat pada teknik kompresi untuk penyebarannya yang efisien. Studi ini berfokus pada kuantisasi pasca-pelatihan untuk LLMS, memperkenalkan kuanta, kerangka kerja kuantisasi lapisan-bijaksana di mana lapisan individu mengalami kuantisasi terpisah. Membingkai masalah sebagai optimasi non-cembung terstruktur diskrit, pekerjaan kami mengembangkan teknik keturunan yang terkoordinasi, menawarkan solusi berkualitas tinggi tanpa perlu inversi matriks atau dekomposisi. Kami juga mengeksplorasi varian outlier-sadar, menjaga bobot yang signifikan dengan presisi lengkap. Proposal kami mencapai kinerja canggih dalam evaluasi empiris di berbagai LLM dan set data, dengan peningkatan hingga 15% dibandingkan metode seperti GPTQ. Dengan optimasi aljabar linier yang hati-hati, kuantase mengukur model seperti Falcon-180b pada GPU NVIDIA A100 tunggal dalam waktu sekitar tiga jam. Algoritma outlier-sadar mencapai kuantisasi dekat atau sub-3-bit dengan penurunan akurasi yang dapat diterima, mengungguli metode seperti SPQR hingga dua kali dalam hal kebingungan.
Hasil WIDITEXT2 yang dipilih untuk keluarga mekar, opt, dan falcon tanpa pengelompokan:
| Nama model | FP16 | 4bit | 3bit | Outlier terstruktur 3bit (1%) | Outlier yang tidak terstruktur 3bit (1%) |
|---|---|---|---|---|---|
| Opt-1.3b | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| Opt-13b | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1B7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7B1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| Falcon-7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| Falcon-40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
Akurasi Zero-Shot pada Benchmark Lambada untuk kuantisasi 3-bit dan 4-bit: 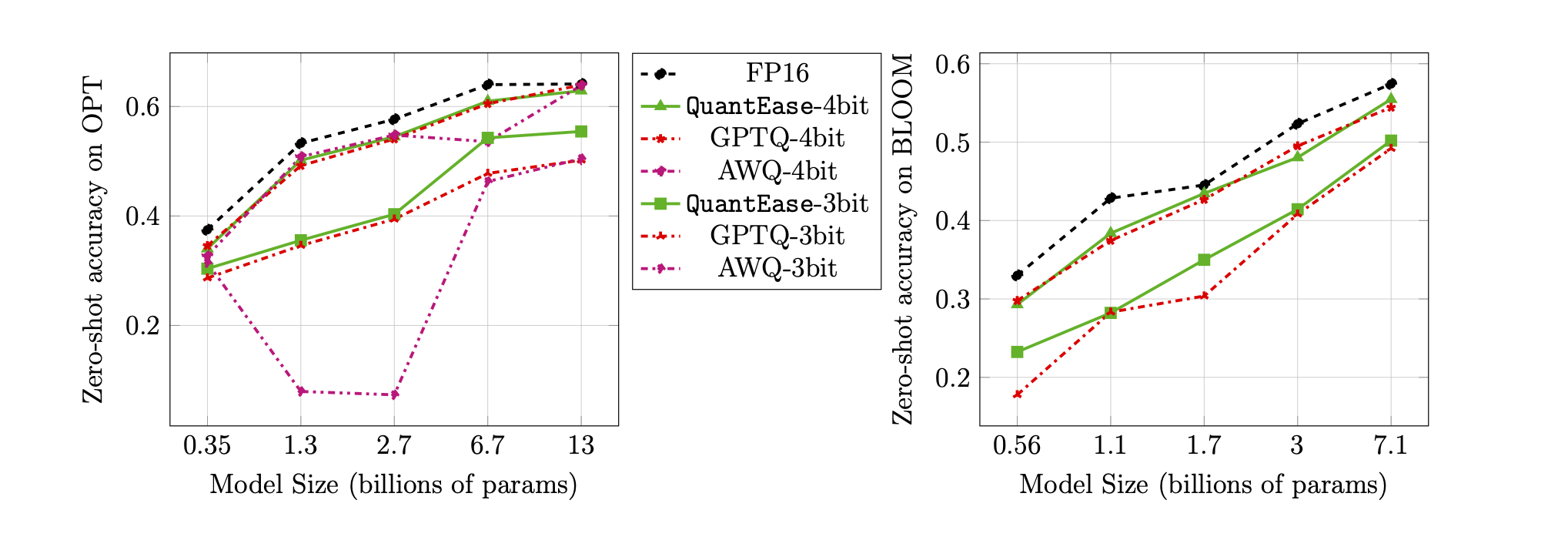
quantease : Algoritma kuantase dasar yang diusulkan dengan implementasi yang dipercepat mengikuti algoritma 2 di koran.quantease_outlier : Algoritma quantease outlier-sadar dengan implementasi yang dipercepat mengikuti algoritma 3 di koran.rtn : Algoritma bundar ke-ke-kediaman awal.gptq_quantease : Algoritma gabungan GPTQ + Quantease. Diinisialisasi dengan GPTQ dalam iterasi pertama, dan kemudian lakukan kuantase di atasnya untuk optimasi kinerja lebih lanjut. data .models di bawah QuantEase Root Dir dan unduh model HuggingFace untuk dikuantisasi di dalamnya dengan nama yang Anda sukai.pip3 install -r requirements.txttorch : Diuji pada v2.0.0+Cu118transformers : Diuji pada v4.35.0scipy : Diuji pada v1.11.3einops : Diuji pada v0.7.0datasets : Diuji pada v2.14.7scikit-learn : diuji pada v1.4.0sacrebleu : Diuji pada v2.3.1auto-gptq : Diuji pada v0.5.0 (digunakan untuk mengemas model saja), jika Anda ingin mengemas dan mengekspor model terkuantisasi, silakan ikuti instruksi pada halaman Autogptq untuk menginstal https://github.com/panqiwei/autogptqSemua skrip telah diuji dengan mesin GPU A100 NVIDIA tunggal dengan versi API driver CUDA 12.0 dan versi API runtime 11.2.
Kami saat ini mendukung kuantisasi tiga keluarga model: Bloom, Opt, Falcon, Mistral-7b, Llama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name : misalnya, bloom-560m , opt-350m dan falcon-7b , dll. skrip kami akan secara otomatis memilih jenis model / konfigurasi yang sesuai berdasarkan nama modelalgorithm_name : Pilih dari quantease , rtn dan gptq_quantease Untuk mengaktifkan algoritma outlier-achare, berikan argumen tambahan: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : pilih dari spqr dan quantease . Catatan: Argumen outlier untuk kuantase menunjukkan persentase bobot yang akan dipilih sebagai outlier dari setiap lapisan tetapi untuk metode SPQR, itu mengacu pada outlier_relative_threshold yang seringkali lebih besar dari rasio outlier yang sebenarnya, silakan merujuk ke kode kertas asli dan kertas untuk pengaturan hyperparamter yang lebih rinci. Untuk mengaktifkan kuantisasi outlier terstruktur untuk kuantase, silakan tambahkan --structure-outlier dalam perintah berjalan.--compute-quantization-recon-error : Kesalahan rekonstruksi tampilan untuk setiap lapisan selama kuantisasi untuk tujuan debugging. Lebih banyak waktu dan memori diperlukan jika diaktifkan.--groupsize : Kelompokkan yang digunakan untuk kuantisasi; Default menggunakan baris penuh.--act-order : Apakah akan menerapkan urutan aktivasi heuristik GPTQ, ini adalah fitur baru dalam basis kode GPTQ yang terbukti berkinerja baik dalam banyak kasus dan mengurangi masalah numerik selama kuantisasi.--save <path_to_save_the_model_and_results> : Mengaktifkan Hasil Perplexity yang disimpan dalam JSON dan pengemasan/penghematan model terkuantisasi. Pastikan Anda menginstal paket auto-gptq untuk memanfaatkan lapisan kuantlinear dan kernel CUDA untuk membantu mengemas dan menyimpan model.--num-layers-to-quantize : Berapa banyak blok untuk dikuantisasi dari atas ke bawah (terutama digunakan untuk tujuan debugging). Entri Biblatex:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdin berkontribusi pada pekerjaan ini ketika ia masih magang di LinkedIn selama musim panas 2023. Pekerjaan ini bukan bagian dari penelitian MIT -nya. Rahul Mazumder berkontribusi pada pekerjaan ini ketika ia menjadi konsultan untuk LinkedIn (sesuai dengan kebijakan kegiatan profesional luar MIT). Pekerjaan ini bukan bagian dari penelitian MIT -nya.


