QuantEase
1.0.0
พื้นที่เก็บข้อมูลนี้มีรหัสสำหรับปริมาณกระดาษ: การเพิ่มประสิทธิภาพเชิงปริมาณสำหรับแบบจำลองภาษา - อัลกอริทึมที่มีประสิทธิภาพและใช้งานง่าย
ด้วยความนิยมที่เพิ่มขึ้นของแบบจำลองภาษาขนาดใหญ่ (LLMS) มีความสนใจเพิ่มขึ้นในเทคนิคการบีบอัดสำหรับการปรับใช้ที่มีประสิทธิภาพ การศึกษาครั้งนี้มุ่งเน้นไปที่การหาปริมาณหลังการฝึกอบรมสำหรับ LLMS แนะนำ quantease ซึ่งเป็นกรอบการหาปริมาณแบบเลเยอร์ที่ชาญฉลาดซึ่งแต่ละชั้นได้รับการหาปริมาณแยกต่างหาก การกำหนดกรอบปัญหาเป็นการเพิ่มประสิทธิภาพแบบไม่ต่อเนื่องแบบไม่ต่อเนื่องงานงานของเราพัฒนาเทคนิคการประสานงานด้วยการเสนอโซลูชั่นคุณภาพสูงโดยไม่จำเป็นต้องใช้เมทริกซ์ผกผันหรือการสลายตัว นอกจากนี้เรายังสำรวจตัวแปรที่ตระหนักถึงค่าผิดปกติรักษาน้ำหนักที่สำคัญด้วยความแม่นยำที่สมบูรณ์ ข้อเสนอของเราบรรลุประสิทธิภาพที่ล้ำสมัยในการประเมินเชิงประจักษ์ใน LLM และชุดข้อมูลต่างๆโดยมีการปรับปรุงมากถึง 15% มากกว่าวิธีการเช่น GPTQ ด้วยการเพิ่มประสิทธิภาพพีชคณิตเชิงเส้นอย่างระมัดระวัง quantease ปริมาณแบบจำลองเช่น Falcon-180b บน Nvidia A100 GPU เดียวในเวลาประมาณสามชั่วโมง อัลกอริทึมที่รับรู้ที่รับรู้นั้นได้รับปริมาณใกล้เคียงหรือย่อย 3 บิตด้วยการลดลงของความแม่นยำที่ยอมรับได้วิธีที่ดีกว่า SPQR มากถึงสองครั้งในแง่ของความงุนงง
เลือกผลลัพธ์ที่น่าพิศวงของ Wikitext2 สำหรับครอบครัว Bloom, Opt และ Falcon โดยไม่ต้องจัดกลุ่ม:
| ชื่อนางแบบ | FP16 | 4 บิต | 3 บิต | 3 บิตโครงสร้างที่มีโครงสร้าง (1%) | 3 บิตที่ไม่มีโครงสร้างที่มีโครงสร้าง (1%) |
|---|---|---|---|---|---|
| opt -1.3b | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| opt-13b | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Bloom-1b7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7b1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| Falcon-7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| Falcon-40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
ความแม่นยำแบบไม่มีการยิงบนเกณฑ์มาตรฐาน Lambada สำหรับปริมาณ 3 บิตและ 4 บิต: 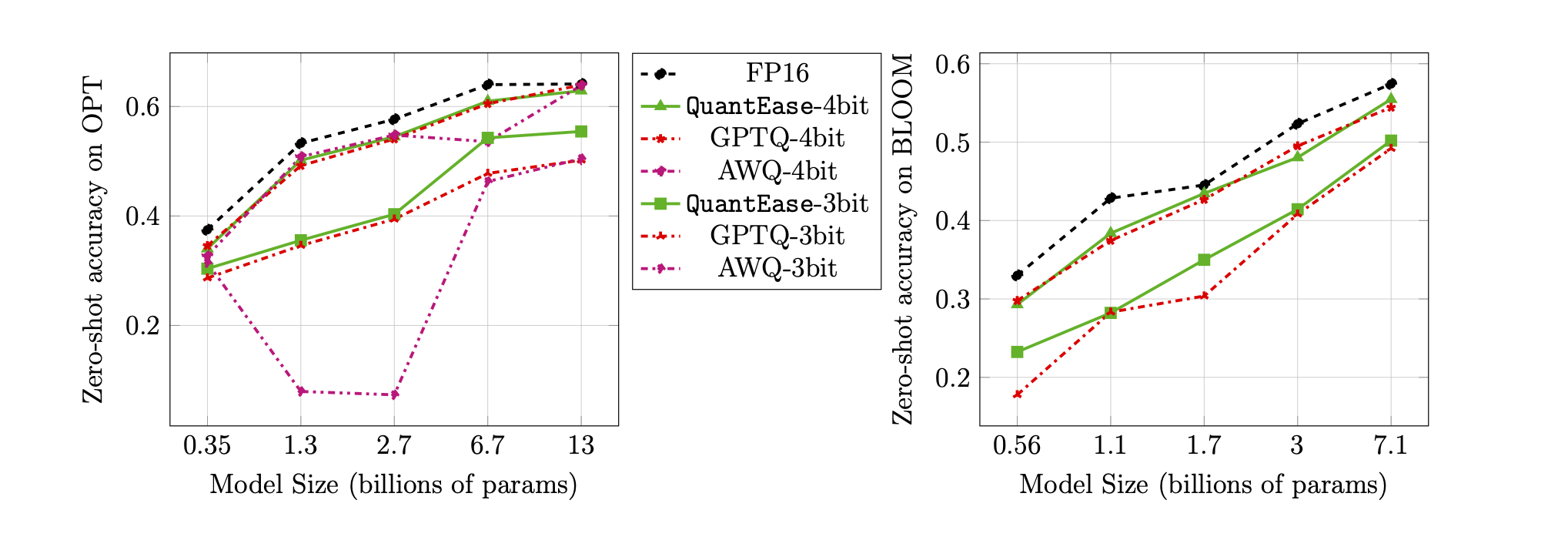
quantease : อัลกอริทึมปริมาณพื้นฐานที่เสนอพร้อมการดำเนินการเร่งความเร็วตามอัลกอริทึม 2 ในกระดาษquantease_outlier : อัลกอริทึมปริมาณที่รับรู้ที่รับรู้ด้วยการใช้งานแบบเร่งรัดตามอัลกอริทึม 3 ในกระดาษrtn : อัลกอริทึมพื้นฐานไปยังที่ใกล้เคียงที่สุดgptq_quantease : อัลกอริทึมรวมของ GPTQ + ปริมาณ เริ่มต้นด้วย GPTQ ในการทำซ้ำครั้งแรกจากนั้นทำการหาปริมาณที่ด้านบนเพื่อเพิ่มประสิทธิภาพประสิทธิภาพเพิ่มเติม datamodels ภายใต้ QuantEase Root Dir และดาวน์โหลดโมเดล HuggingFace ที่จะหาปริมาณด้วยชื่อที่คุณต้องการpip3 install -r requirements.txttorch : ทดสอบบน v2.0.0+Cu118transformers : ทดสอบบน v4.35.0scipy : ทดสอบเมื่อ v1.11.3einops : ทดสอบเมื่อ v0.7.0datasets : ทดสอบบน v2.14.7scikit-learn : ทดสอบใน v1.4.0sacrebleu : ทดสอบใน v2.3.1auto-gptq : ทดสอบบน v0.5.0 (ใช้สำหรับบรรจุโมเดลเท่านั้น) หากคุณต้องการแพ็คและส่งออกโมเดลเชิงปริมาณโปรดทำตามคำแนะนำในหน้า AutogptQ เพื่อติดตั้ง https://github.com/panqiwei/autogptqสคริปต์ทั้งหมดได้รับการทดสอบด้วยเครื่อง A100 NVIDIA GPU เดียวกับ CUDA 12.0 Driver API เวอร์ชันและรุ่น API 11.2 Runtime API
ขณะนี้เราสนับสนุนการหาปริมาณของสามตระกูลโมเดล: Bloom, Opt, Falcon, Mistral-7b, Llama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name : เช่น bloom-560m , opt-350m และ falcon-7b ฯลฯ สคริปต์ของเราจะเลือกประเภท / การกำหนดค่ารุ่นที่สอดคล้องกันโดยอัตโนมัติตามชื่อรุ่นโดยอัตโนมัติalgorithm_name : เลือกจาก quantease , rtn และ gptq_quantease ในการเปิดใช้งานอัลกอริทึมที่รับรู้ที่รับรู้โปรดระบุอาร์กิวเมนต์พิเศษ: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : เลือกจาก spqr และ quantease หมายเหตุ: อาร์กิวเมนต์ outlier สำหรับ Quantease ระบุเปอร์เซ็นต์ของน้ำหนักที่จะเลือกเป็นค่าผิดปกติจากแต่ละเลเยอร์ แต่สำหรับวิธี SPQR มันหมายถึง outlier_relative_threshold ซึ่งมักจะใหญ่กว่าอัตราส่วนค่าผิดปกติที่แท้จริงโปรดดูรหัสกระดาษต้นฉบับและกระดาษ หากต้องการเปิดใช้งานการหาปริมาณที่มีโครงสร้างค่าใช้จ่ายสำหรับ quantease โปรดเพิ่ม --structure-outlier ในคำสั่ง Running--compute-quantization-recon-error : แสดงข้อผิดพลาดในการสร้างใหม่สำหรับแต่ละเลเยอร์ในระหว่างการหาปริมาณเพื่อจุดประสงค์ในการดีบัก จำเป็นต้องใช้เวลาและหน่วยความจำมากขึ้นหากเปิดใช้งาน--groupsize : กลุ่มเพื่อใช้สำหรับการหาปริมาณ; ค่าเริ่มต้นใช้แถวเต็ม--act-order : ไม่ว่าจะใช้คำสั่งเปิดใช้งาน GPTQ ฮิวริสติกหรือไม่มันเป็นคุณสมบัติใหม่ใน GPTQ Codebase ที่แสดงให้เห็นว่าทำงานได้ดีในกรณีส่วนใหญ่และบรรเทาปัญหาเชิงตัวเลขในระหว่างการหาปริมาณ--save <path_to_save_the_model_and_results> : เปิดใช้งานผลลัพธ์ที่น่าประหลาดใจในการประหยัดใน JSON และการบรรจุ/บันทึกแบบจำลองเชิงปริมาณ ตรวจสอบให้แน่ใจว่าคุณติดตั้งแพ็คเกจ auto-gptq เพื่อใช้ประโยชน์จากเคอร์เนล Quantlinear Layer และ CUDA เพื่อช่วยแพ็คและบันทึกรุ่น--num-layers-to-quantize : จำนวนบล็อกในการหาปริมาณจากบนลงล่าง (ส่วนใหญ่ใช้เพื่อจุดประสงค์ในการดีบัก) รายการ BIBLATEX:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Kayhan Behdin สนับสนุนงานนี้ในขณะที่เขาเป็นผู้ฝึกงานที่ LinkedIn ในช่วงฤดูร้อนปี 2023 งานนี้ไม่ได้เป็นส่วนหนึ่งของการวิจัย MIT ของเขา Rahul Mazumder สนับสนุนงานนี้ในขณะที่เขาเป็นที่ปรึกษาของ LinkedIn (ปฏิบัติตามนโยบายกิจกรรมระดับมืออาชีพภายนอกของ MIT) งานนี้ไม่ได้เป็นส่วนหนึ่งของการวิจัย MIT ของเขา


