QuantEase
1.0.0
Этот репозиторий содержит коды для измерения бумаги: квантование на основе оптимизации для языковых моделей - эффективный и интуитивно понятный алгоритм
С растущей популярностью крупных языковых моделей (LLMS), существует все больше интереса к методам сжатия для их эффективного развертывания. Это исследование фокусируется на квантовании после обучения для LLM, введении количественного, структуру квантования по слону, где отдельные слои подвергаются отдельному квантованию. Создавая проблему как дискретную не-конъюментальную оптимизацию, наша работа разрабатывает методы координатного спуска, предлагая высококачественные решения без необходимости инверсии или разложения матрицы. Мы также исследуем вариант с учетом выбросов, сохраняя значительные веса с полной точностью. Наше предложение достигает современной эффективности в эмпирических оценках по различным LLMS и наборам данных, с улучшением до 15% по сравнению с такими методами, как GPTQ. При тщательной линейной оптимизации алгебры Countease определяет такие модели, как Falcon-180b на одном графическом процессоре Nvidia A100 примерно за три часа. Алгоритм с учетом выбросов достигает квантования вблизи или 3-битного квантования с приемлемым падением точности, превзойдя методы, такие как SPQR, на срок до двух раз с точки зрения недоумения.
Выбранные результаты озадачивания Wikitext2 для семейства Bloom, Opt и Falcon Model без группировки:
| Название модели | FP16 | 4 -бит | 3 бит | 3-битный структурированный выброс (1%) | 3BT-UNStructuretured Outlier (1%) |
|---|---|---|---|---|---|
| OPT-1.3b | 14.62 | 15.28 | 21.30 | 18.51 | 16.25 |
| OPT-13B | 10.13 | 10.32 | 12.41 | 12.07 | 10.37 |
| Блум-1B7 | 15.39 | 16.11 | 20.03 | 18.89 | 17.06 |
| Bloom-7b1 | 11.37 | 11.69 | 13.43 | 12.97 | 12.03 |
| Falcon-7b | 6.59 | 6.92 | 8.83 | 8.56 | 7.14 |
| Falcon-40b | 5.23 | 5.46 | 6.20 | 5.99 | 5.51 |
Точность нулевого выстрела на эталоне Lambada для 3-битной и 4-битной квантования: 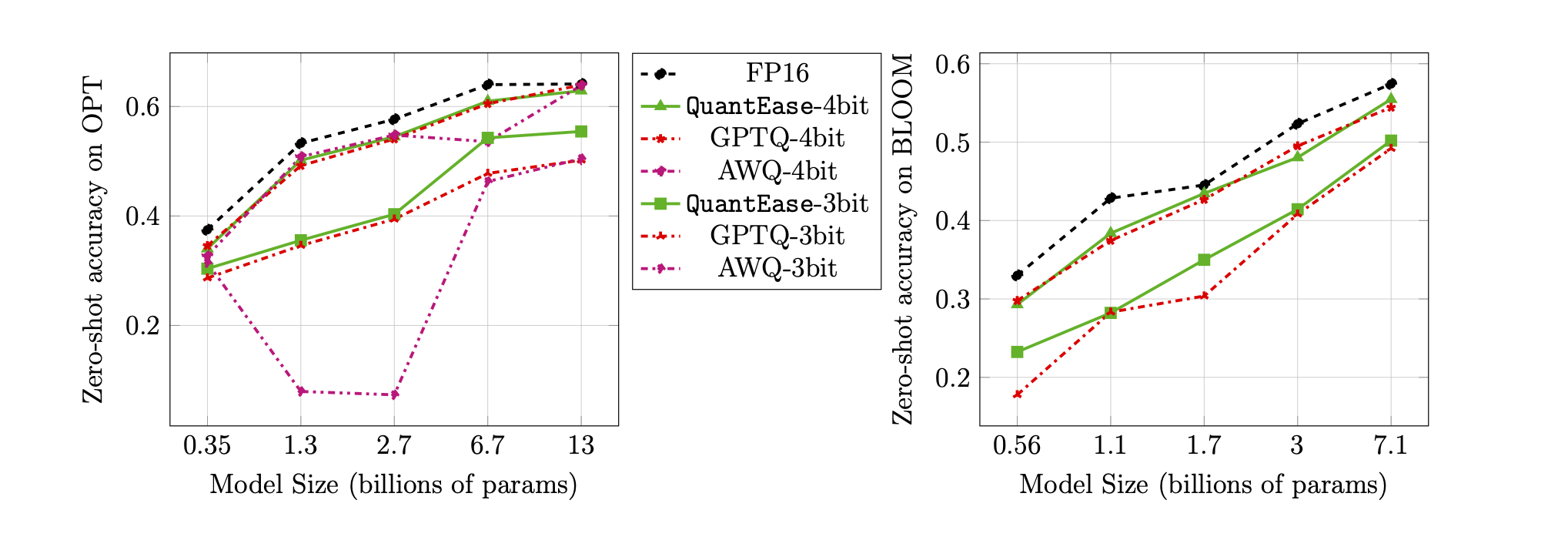
quantease : предложенный базовый алгоритм количественного уровня с ускоренной реализацией после алгоритма 2 в статье.quantease_outlier : Алгоритм количественного анализа выбросов с ускоренной реализацией после алгоритма 3 в статье.rtn : базовый круг-по-прежний алгоритм.gptq_quantease : комбинированный алгоритм GPTQ + количественного. Инициализируется с помощью GPTQ в первой итерации, а затем сделайте количественный к нему для дальнейшей оптимизации производительности. data .models в QuantEase ROOT DIR и загрузите модели HUGGINGFACE, которые будут квантовать в ней с помощью предпочтительного имени, которое вы предпочитаете.pip3 install -r requirements.txttorch : протестирован на v2.0.0+cu118transformers : протестировано на V4.35.0scipy : протестирован на v1.11.3einops : протестировано на v0.7.0datasets : протестированы на v2.14.7scikit-learn : протестирован на v1.4.0sacrebleu : протестирован на V2.3.1auto-gptq : протестирован на V0.5.0 (используется только для упаковки моделей), если вы хотите упаковать и экспортировать квантовую модель, следуйте инструкции на странице AutoGPTQ для установки https://github.com/panqiwei/autogptqВсе сценарии были протестированы с помощью одной машины A100 NVIDIA GPU с версией API драйвера CUDA 12.0 и версией API среды 11,2.
В настоящее время мы поддерживаем квантование трех модельных семей: Bloom, Opt, Falcon, Mistral-7b, Llama
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < algorithm_name >model_name : например, bloom-560m , opt-350m и falcon-7b и т. Д. Наш сценарий автоматически выберет соответствующий тип модели / конфигурация на основе имени моделиalgorithm_name : выберите из quantease , rtn и gptq_quantease Чтобы включить алгоритм с учетом выбросов, пожалуйста, предоставьте дополнительный аргумент: --outlier :
# within the `QuantEase` root folder run:
python3 model_quantizer.py --model ` models/ < model_name > ` --dataset c4 --wbits 4 --num-iter 30 --nsamples 128 --true-sequential --quantization-method < outlier_aware_algorithm_name > --outlier 0.01outlier_aware_algorithm_name : выберите из spqr и quantease . ПРИМЕЧАНИЕ. Аргумент outlier для количественного анализа указывает процент весов, которые будут выбранные в качестве выбросов из каждого уровня, но для метода SPQR он относится к outlier_relative_threshold , который часто больше, чем истинное отношение выбросов, см. Первоначальный код бумаги и бумагу для более подробной гиперпарамтерной установки. Чтобы включить структурированное квантование выбросов для количественного, добавьте --structure-outlier в команде Running.--compute-quantization-recon-error : отображать ошибки реконструкции для каждого уровня во время квантования для отладки. Больше времени и памяти необходимо, если включено.--groupsize : Grignize для использования для квантования; По умолчанию используется полная строка.--act-order : применять эвристику по порядку активации gptq, это новая функция в кодовой базе GPTQ, которая, как показано, хорошо работает в большинстве случаев и облегчает численную проблему во время квантования.--save <path_to_save_the_model_and_results> : включить сбережения результатов недоумения в JSON и квантовая упаковка/сохранение модели. Убедитесь, что вы установили пакет auto-gptq для использования квантового слоя и ядра CUDA, чтобы помочь упаковать и сохранить модель.--num-layers-to-quantize : сколько блоков для квантования сверху вниз (в основном используется для отладки). Вход Biblatex:
@article { behdin2023quantease ,
title = { QuantEase: Optimization-based Quantization for Language Models--An Efficient and Intuitive Algorithm } ,
author = { Behdin, Kayhan and Acharya, Ayan and Gupta, Aman and Keerthi, Sathiya and Mazumder, Rahul and Siyu, Zhu and Qingquan, Song } ,
journal = { arXiv preprint arXiv:2309.01885 } ,
year = { 2023 }
}Кайхан Бехдин внес свой вклад в эту работу, когда он был стажером в LinkedIn летом 2023 года. Эта работа не является частью его исследования MIT. Рахул Мазумдер внес свой вклад в эту работу, в то время как он был консультантом LinkedIn (в соответствии с политикой MO MIT по внешней профессиональной деятельности). Эта работа не является частью его исследования MIT.


