llms
1.0.0
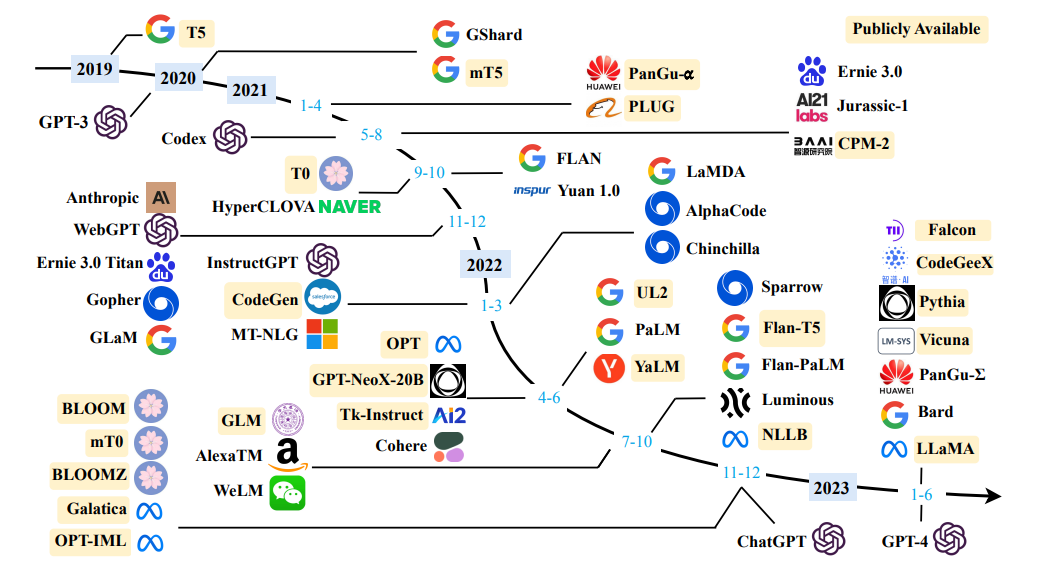 采购大型语言模型的调查
采购大型语言模型的调查
简单的定义:语言建模是预测接下来哪个单词的任务。
“那只狗在……在……”
语言模型的主要目的是将概率分配给句子,以区分较小的句子和较小的句子。
为了进行语音识别,我们不仅使用声学模型(语音信号),还使用语言模型。同样,对于光学特征识别(OCR),我们同时使用视觉模型和语言模型。语言模型对于此类识别系统非常重要。
有时,您会听到或阅读尚不清楚的句子,但是使用您的语言模型,尽管有嘈杂的视觉/语音输入,但您仍然可以很高的精度识别它。
语言模型计算以下任意:
语言建模是许多NLP任务的子组件,尤其是涉及生成文本或估算文本概率的任务。
链条规则:
$ p(,水为,,so,so clear)= p(the)×p(wath | the | the)×p(is | the,wath)×p(so | | |,水,is)×p(clear | the | the | the | the,水是,so)$
刚刚发生了什么?链条规则用于计算句子中单词的关节概率。
使用大量文本(例如Wikipedia等语料库),我们收集有关不同单词的频率的统计信息,并使用它们来预测下一个单词。例如,一个单词w的可能性是在学生打开以下三个单词打开他们的三个单词之后的概率,如下所示:
上面的示例是4克模型。我们可能会得到:
我们可以得出结论,在这种情况下,“书”一词比“汽车”更有可能。
在“学生打开他们的”之前,我们忽略了以前的上下文
因此,可以从给定单词的语言模型,通过从下一个单词的输出概率分布进行采样等语言模型生成任意文本。
我们可以在任何类型的文本上训练LM,然后以这种样式(Harry Potter等)生成文本。
我们可以扩展到Trigram,4克,5克和N-Grams。
通常,这是语言模型不足,因为该语言具有长途依赖性。但是,实际上,这3,4克对于大多数应用程序都可以很好地工作。
Google的N-Gram模型属于您:Google Research一直在为各种研发项目使用Word N-Gram模型。 Google n-gram处理了1,024,908,267,229单词,并发布了所有1,176,470,663个五字序列的计数,这些序列至少出现了40次。
语言学数据联盟的文本计数如下:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
以下是此语料库中4克数据的示例:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
例如,在语料库中已经看到了四个单词“用作指示”的序列72次。
有时我们没有足够的数据来估计。增加n使稀疏性问题变得更糟。通常,我们不能拥有大于5的n。
NLM通常(但并非总是)使用RNN来学习单词序列(句子,段落等),因此可以预测下一个单词。
优点:
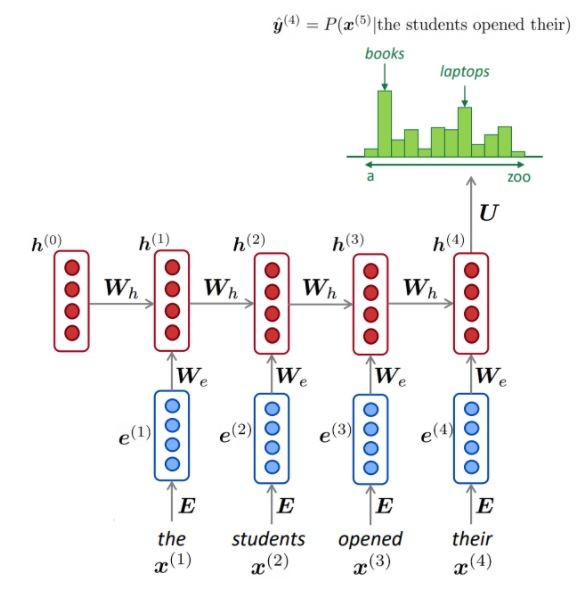
如图所示,在每个步骤中,我们在词汇上都有下一个单词的概率分布。
培训NLM:
长序列学习的示例:
缺点:
LM可用于在不同应用程序上生成输入(语音,图像(OCR),文本等)上的文本条件,例如:语音识别,机器翻译,摘要等。
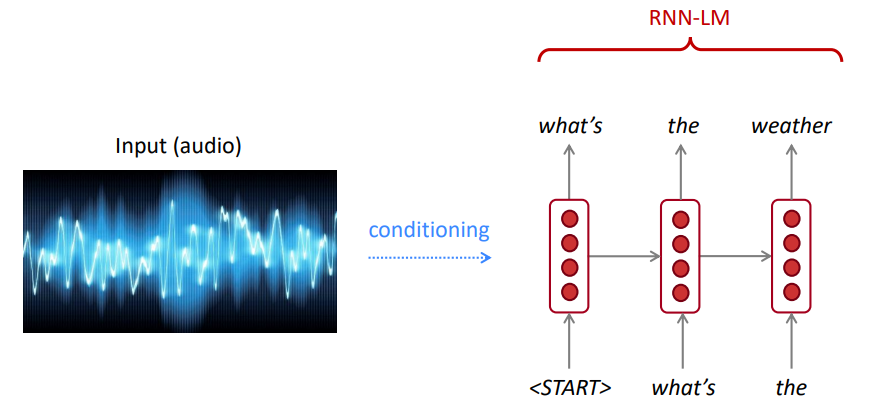
我们的语言模型比不良句子更喜欢好(可能)句子吗?
语言模型的标准评估度量是困惑的困惑是测试集的反可能性,由单词数量归一化
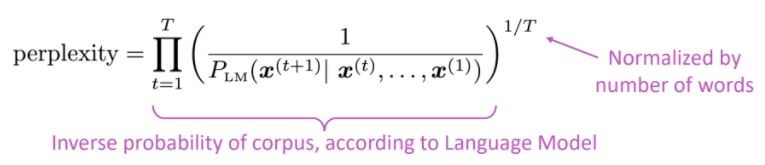
较低的困惑=更好的模型
困惑与分支因素有关:平均而言,接下来可能发生多少件事。
我们使用注意力而不是RNN,让我们使用大型预培训模型
问题是什么?自然语言处理(NLP)最大的挑战之一是缺乏许多不同任务的培训数据。但是,现代深度学习的NLP模型在接受带注释的培训示例的数百万或数十亿培训时会有所改善。
预训练是解决方案:为了帮助缩小这一差距,已经开发了多种技术,用于使用大量未注释的文本训练通用语言表示模型。然后,可以在较小的数据上微调预训练的模型,以进行不同的任务,例如答案和情感分析,从而与从头开始的这些数据集进行培训相比,可以提高准确的准确性。
在纸张注意中提出了变压器体系结构,您需要全部使用,用于神经机器翻译任务(NMT),由:
如论文中所述:
“我们提出了一种新的简单网络体系结构,即变压器,仅基于注意机制,完全以复发和卷积的方式分配”
正如Openai的文章中提到的那样,可以总结注意力的主要思想:
“ ...每个输出元素都连接到每个输入元素,并且它们之间的权重是根据情况动态计算的,一个称为注意的过程。 ”
基于此体系结构(香草变压器!),可以单独使用编码器或解码器组件来启用大量的预训练的通用模型,这些模型可以进行微调,以用于下游任务,例如文本分类,翻译,摘要,问题答案等。例如:例如:
例如,BERT和GPT这些模型可以视为NLP的Imagenet。
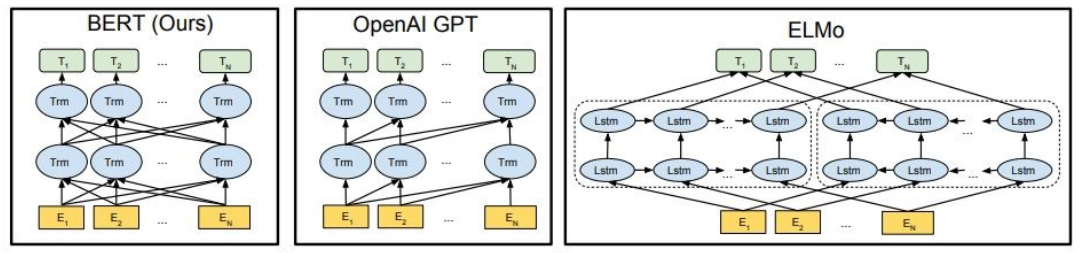
如图所示,Bert是双向的,Openai GPT是单向的,Elmo是双向的。
预训练的表示可能是:
上下文语言模型可以是:
在这一部分中,我们将使用不同的大语模型
GPT2(GPT的继任者)是使用因果语言建模( CLM )目标的英语培训模型,经过培训,仅需预测40GB Internet文本中的下一个单词即可。它首先在此页面上发布。 GPT2显示了一系列功能,包括生成条件合成文本样本的能力。关于问题回答,阅读理解,摘要和翻译等语言任务,GPT2开始从原始文本中学习这些任务,没有使用特定于任务的培训数据。 Distilgpt2是GPT2的蒸馏版本,它旨在用于类似用例,其功能增加的功能比基本模型更小,更易于运行。
在这里,我们加载了预训练的GPT2模型,要求GPT2模型继续我们的输入文本(提示),最后,从DistilGPT2模型中提取嵌入式功能。
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
伯特(Bert)是一种以自我监督的方式对大量英语数据进行预训练的变形金刚模型。这意味着它仅在原始文本上进行了预先训练,没有人类以任何方式标记它们,以自动过程来生成这些文本的输入和标签。更确切地说,它是有两个目标鉴定的:
在此示例中,我们将使用预先训练的BERT模型进行情感分析任务。
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4ALL是一个生态系统,可以培训和部署在消费级CPU上本地运行的功能强大和定制的大型语言模型。
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
尝试以下模型:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM是TII的大型语言模型的旗舰系列,使用自定义数据管道和分布式培训从头开始构建。 Falcon-7b/40b型号的尺寸是最先进的,在NLP基准测试上的其他大多数模型都优于其他大多数型号。开源的许多文物:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
Llama2是Meta今天发布的最先进的开放式大型语言模型的家族,我们很高兴能以全面的融合在拥抱面孔中充分支持发射。 Llama 2具有非常宽松的社区许可证,可用于商业用途。今天发布的代码,预估计的型号和微调模型都将发布
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
CODET5+是一个开放代码大型语言模型的新家族,具有编码器编码器体系结构,可以以不同的模式灵活地操作(即仅编码,仅解码器和编码器编码器),以支持广泛的代码理解和生成任务。
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
对于更多模型,请检查Salesforce的CODETF,这是一个基于Python Transformer的代码大型语言模型(代码LLM)和代码智能的库,提供了一个无缝接口的接口,用于培训和推断代码智能任务,例如代码汇总,翻译,代码生成等。
与开放的大语模型聊天
✅梁搜索始终会找到比贪婪搜索更高的输出序列,但不能保证找到最可能的输出。
在变压器中,我们只需将参数num_return_ sequences设置为应返回的最高评分梁的数量即可。确保num_return_sequences <= num_beams!
✅梁搜索在所需生成的长度或多或少可预测的任务中可以很好地工作,就像机器翻译或摘要一样。但是,对于开放式一代而言,这不是这种情况,所需的输出长度可以很大变化,例如对话和故事生成。梁搜索严重遭受重复产生。作为人类,我们希望生成的文本使我们感到惊讶,而不是无聊/可预测(?梁搜索不那么令人惊讶)
在变形金刚中,我们通过top_k = 0设置do_sample = true = true和停用top-k采样(稍后再进行)。
??? - ? ????? GPT2采用了此抽样方案。
??? - ? ?????????:不是仅从最可能的k单词中取样,而是从顶部Pampling中从最小可能的单词组中选择,其累积概率超过概率p的最小单词。然后将概率质量重新分布在这组单词之间。在设置P = 0.92的情况下,Top-P采样选择最小单词数量超过了概率质量的92%。
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅尽管Top-P似乎比TOUP-K更优雅,但两种方法在实践中都很好。 TOP-P也可以与TOUP-K结合使用,TOUP-K可以避免排名非常低的单词,同时允许进行一些动态选择。
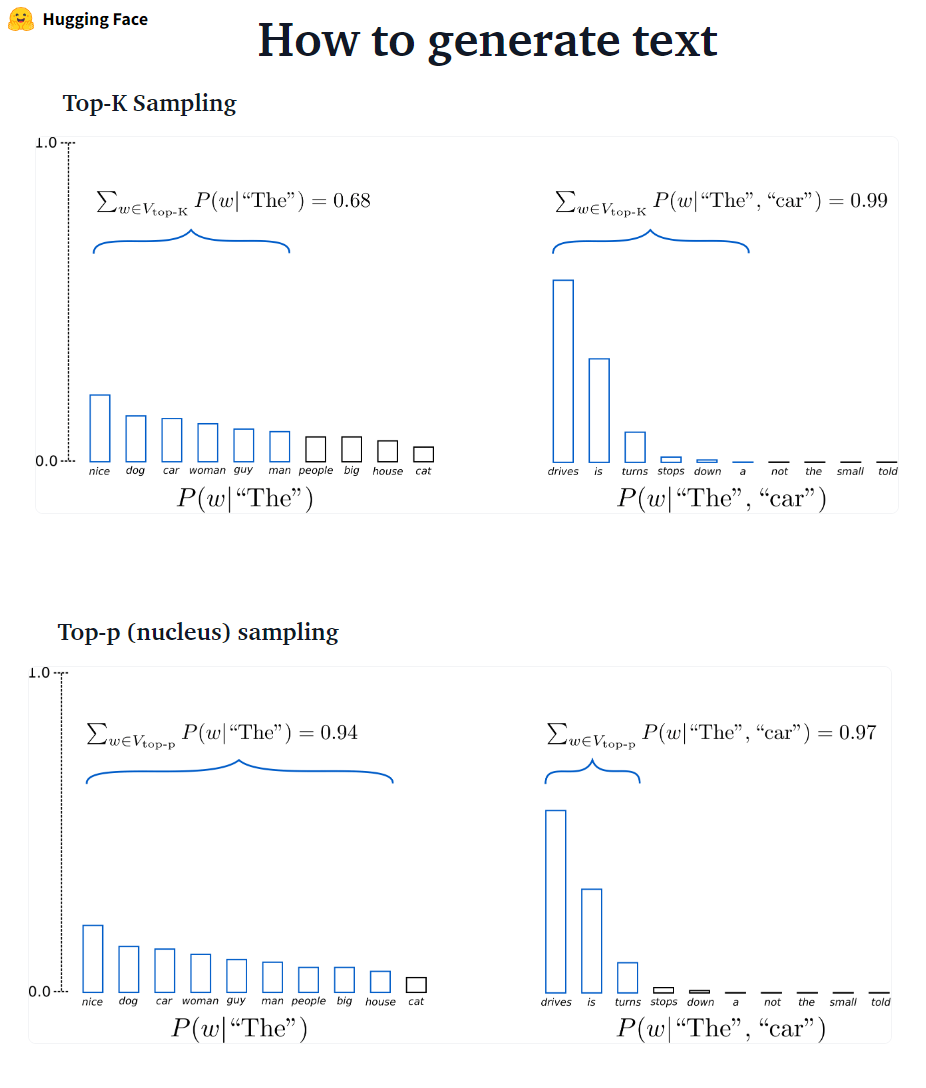
✅作为临时解码方法,TOP-P和TOP-K采样似乎比传统的贪婪产生的文本更流利 - 并且在开放式语言生成上搜索了光束搜索。
及时工程是设计提示(文本输入)以生成所需输出的过程。及时工程涉及选择适当的关键字,提供上下文,清晰明确,以指导语言模型行为实现所需响应的方式。通过及时的工程,我们可以控制模型的音调,样式,长度等,而无需微调。
零拍摄的学习涉及要求模型进行预测而不提供任何示例(零射击),例如:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
当零射击不够好时,建议通过在提示中提供示例来帮助模型,从而导致很少的提示。
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
除了迅速的工程外,我们还可以考虑更多选择:
有关更多及时的工程信息,请参阅包含所有最新论文,学习指南,讲座,参考和工具的及时工程指南。
与使用预告片的LLMS相比,下游数据集上的微调LLMS可在巨大的性能增长(例如,零摄像推理)。但是,随着模型越来越大,对消费者硬件进行培训变得不可行。此外,为每个下游任务独立存储和部署微调模型变得非常昂贵,因为微型模型的大小与原始预告片的型号相同。参数有效的微调(PEFT)方法旨在解决这两个问题! PEFT方法使您能够获得与完整的微调相当的性能,而仅具有少量可训练的参数。例如:
及时调整:学习“软提示”以调节冷冻语言模型以执行特定下游任务的简单而有效的机制。就像工程文本的提示一样,软提示会加入输入文本。但是,软提示的“代币”不是从现有词汇项目中选择的,而是可学习的矢量。这意味着可以通过培训数据集优化软提示,如下所示: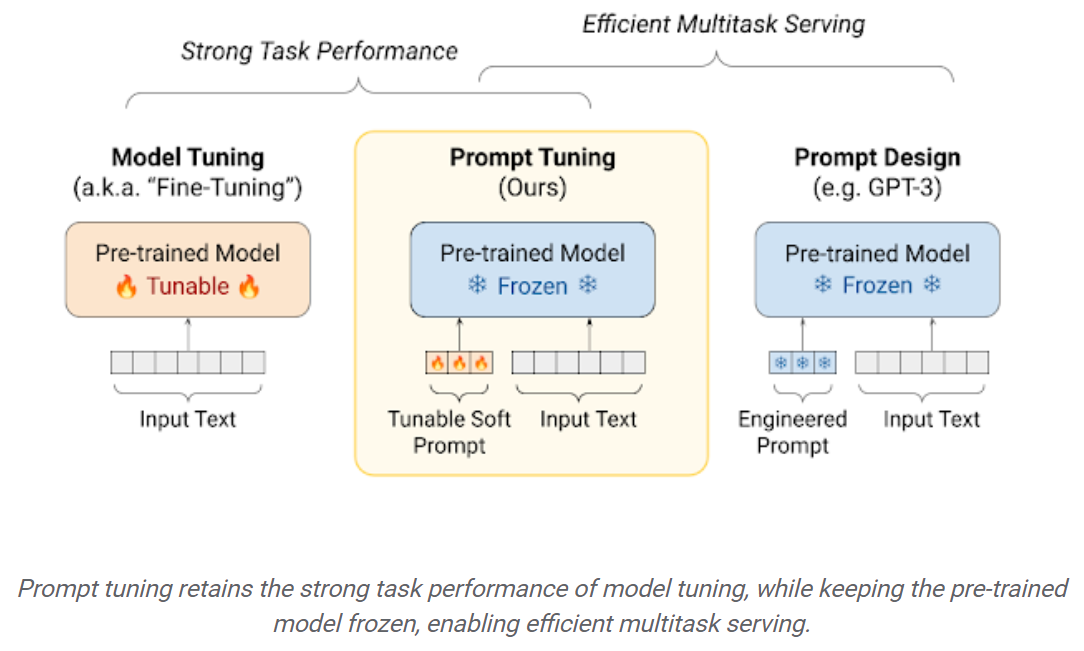
LLMS的LORA低级适应性是一种冻结预验证的模型权重,并注入了可训练的秩分解矩阵中的每一层。大大减少了下游任务的可训练参数的数量。下面的图,从本视频中解释了主要思想: 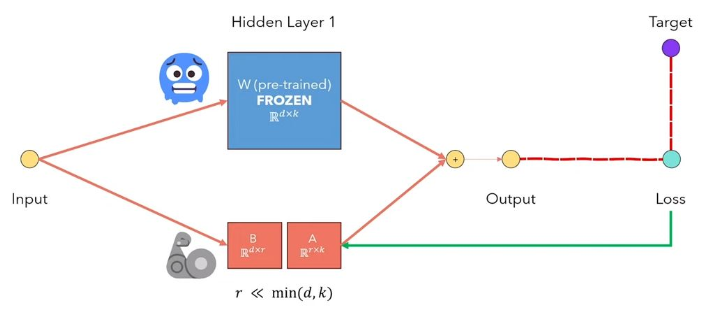
大型语言模型通常是通用的,对于特定领域的任务效率较低。但是,可以在某些任务(例如情感分析)上进行微调。对于需要外部知识的更复杂的TAK,可以构建一个基于语言模型的系统,该系统访问外部知识源以完成所需的任务。这样可以提高事实准确性,并有助于减轻“幻觉”的问题。如下图所示:
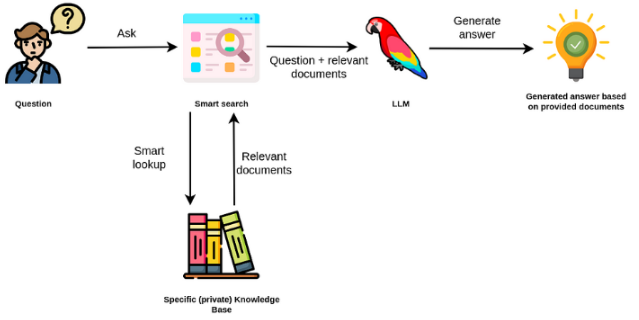
在这种情况下,我们将LLM用作外部知识的自然语言接口,而不是使用LLM来访问其内部知识。第一步是将文档和任何用户查询转换为兼容格式,以执行相关搜索(将文本转换为向量或嵌入)。然后将原始用户提示附加在外部知识源(作为上下文)中的相关 /类似文档。然后,该模型根据提供的外部上下文回答问题。
大型语言模型(LLM)正在作为一种变革性技术。但是,将这些LLM隔离使用通常不足以创建真正强大的应用程序。 Langchain旨在协助开发此类应用程序。
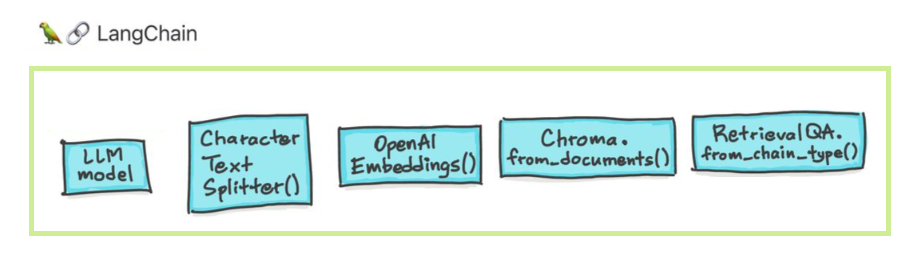
Langchain旨在帮助您有六个主要领域。这些是越来越复杂的顺序:
这包括提示管理,及时优化,所有LLM的通用接口以及与LLMS合作的通用实用程序。 LLM和聊天模型巧妙,但重要的是不同。 Langchain中的LLM是指纯文本完成模型。他们包装的API以字符串提示为输入并输出字符串完成。 OpenAI的GPT-3作为LLM实施。聊天模型通常由LLMS支持,但专门针对进行对话。
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
您还可以访问返回的提供商的特定信息。此信息不是在提供商之间标准化的。
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
提示聊天模型是聊天消息的列表。每个聊天消息与内容相关联,还有一个称为角色的附加参数。例如,在OpenAI聊天完成API中,聊天消息可以与AI助手,人类或系统角色相关联。
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
链条超越了单个LLM呼叫,涉及呼叫序列(无论是LLM还是其他实用程序)。 Langchain为链条提供了一个标准接口,与其他工具进行了大量集成以及常见应用的端到端链。链条非常普遍可以定义为对组件的调用序列,其中可能包括其他链条。
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
数据增强生成涉及特定类型的链条,这些链首先与外部数据源相互作用,以获取数据以用于生成步骤。示例包括对特定数据源的问题/回答。
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
相似性搜索
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
代理商涉及LLM做出决定要采取哪些行动,采取该行动,观察观察并重复此操作的决定,直到完成为止。 Langchain为代理提供了标准接口,可以选择的代理和端到端代理的示例。代理的核心思想是使用LLM选择一系列动作。在链条中,一系列动作是硬编码(在代码中)。在代理中,语言模型被用作推理引擎,以确定要采取哪些动作以及在哪个顺序中采取的行动。
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
内存是指链/代理的调用之间的持久状态。 Langchain提供了一个标准接口,用于内存,内存实现集合以及使用内存的链/代理的示例。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
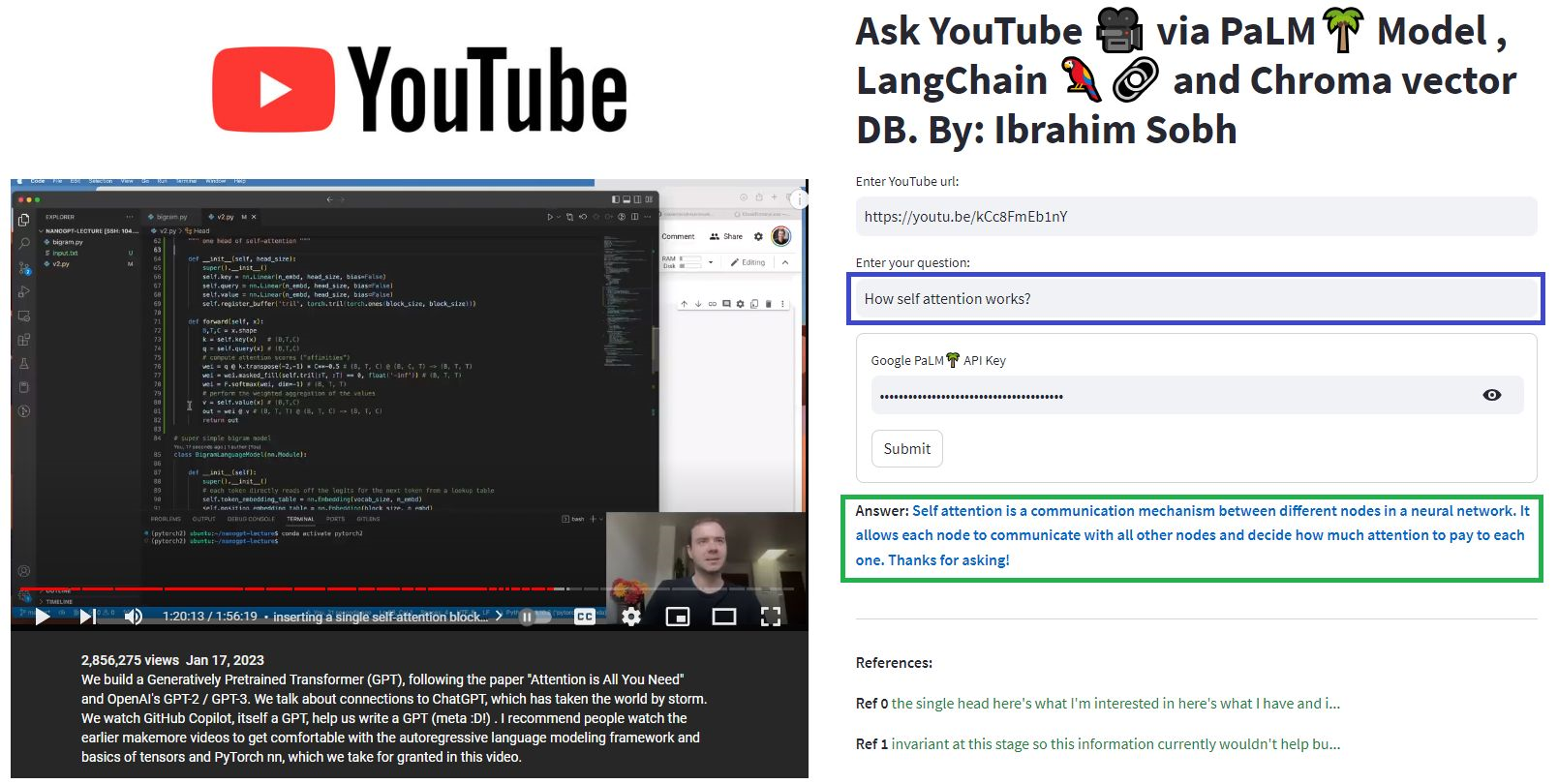
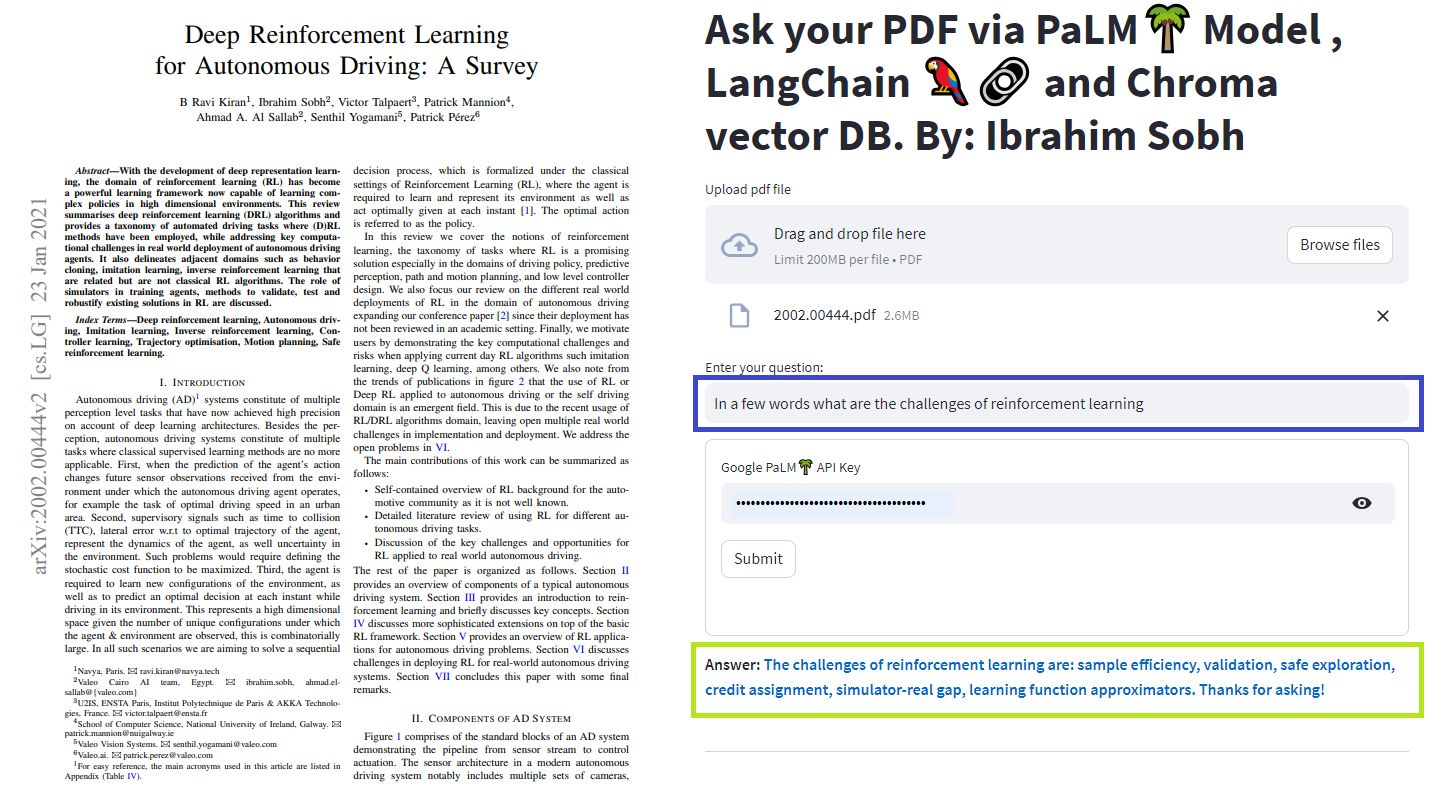
我们可以使用不同的方法与文档聊天。无需微调整个LLM,而是我们可以为预训练的模型提供正确的上下文以及我们的问题,然后根据我们提供的文档获得答案。
在这里,我们与这篇名为“不痛苦的变形金刚”的精美文章聊天?在利用Google强大的Palm模型和Langchain框架的同时,询问与变形金刚,注意力,编码器码头等有关的问题,用于开发由语言模型提供支持的应用程序。
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
问题: ? “这些文件是什么?”
回答: ? “这些文档是关于变形金刚的,这是一种成功用于自然语言处理和计算机视觉任务的神经网络。”
问题: ? “变形金刚的主要思想是什么?”
回答: ? “变形金刚的主要思想是使用注意机制以序列建模远程依赖性。”
问题: ? “什么是位置编码?”
回答: ? “位置编码是一种用于表示顺序中单词顺序的技术。”
问题: ? “如何使用查询,键和值向量?”
回答: ? '查询向量用于通过键计算值的加权总和。具体来说:Q点产品所有键,然后softmax获得权重,最后使用这些权重计算值的加权总和。
问题: ? “如何开始使用变压器?”
回答: ? '要开始使用变形金刚,您可以使用HuggingFace Transformers库。该库提供了数千个审慎的模型,以用100多种语言进行分类,信息提取,摘要,翻译,文本生成等文本执行任务。
您可以尝试自己的文档和问题!
在这些简单的教程中:如何使用Chroma Vector Database,Google的Palm LLM以及Langchain的问答链从文本文档, PDF文件,甚至YouTube视频中获取答案。最后,使用简化来开发和托管Web应用程序。您将需要使用Google_api_key(可以从Google获得一个)。 THS系统体系结构如下:
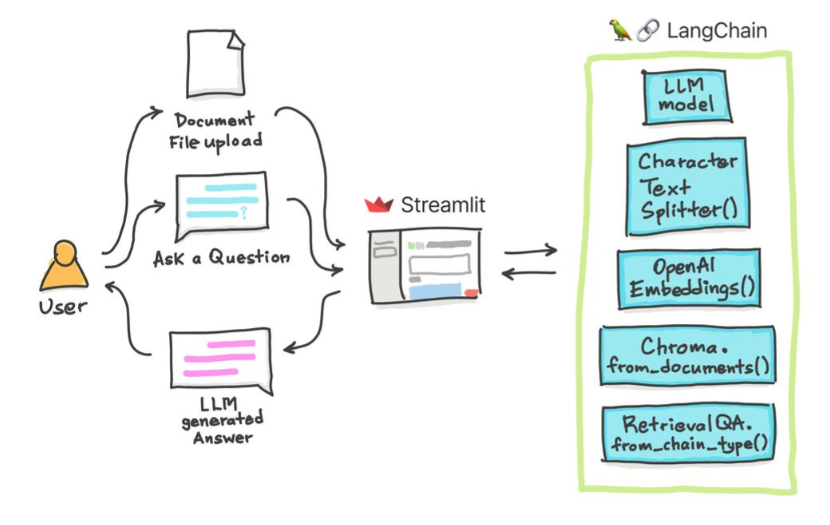
评估LLM与评估基于LLM的系统之间是有区别的。通常在通用预训练后,在标准基准上评估LLM:
LLMS系统可以总结文本,进行问答,找到文本的情感,可以进行翻译等等。基于系统,评估可以如下:
例如,如果要问答系统,我们需要在评估集中成对的问题和答案。我们可以使用人类注释来手动创建金色标准的问题和答案。但是,这是昂贵且耗时的。创建此类数据集的一种可行方法是利用LLM。
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
使用LLM查找预测与给定两个文本(真实和预测答案)的真实答案相比,LLM可以从理论上找到它们是否在语义上相同。 Langchain有一个链条称为
此外,我们可以使用标准指标进行评估,例如召回,精度和F1分数。
一旦有了一个EDAT数据集,就可以将Hyper参数优化方法构成SENS,并且可以在不同的模型,提示等上应用。
有关更多信息,本文提供了如何评估大型语言模型(LLM)系统的交互式介绍。
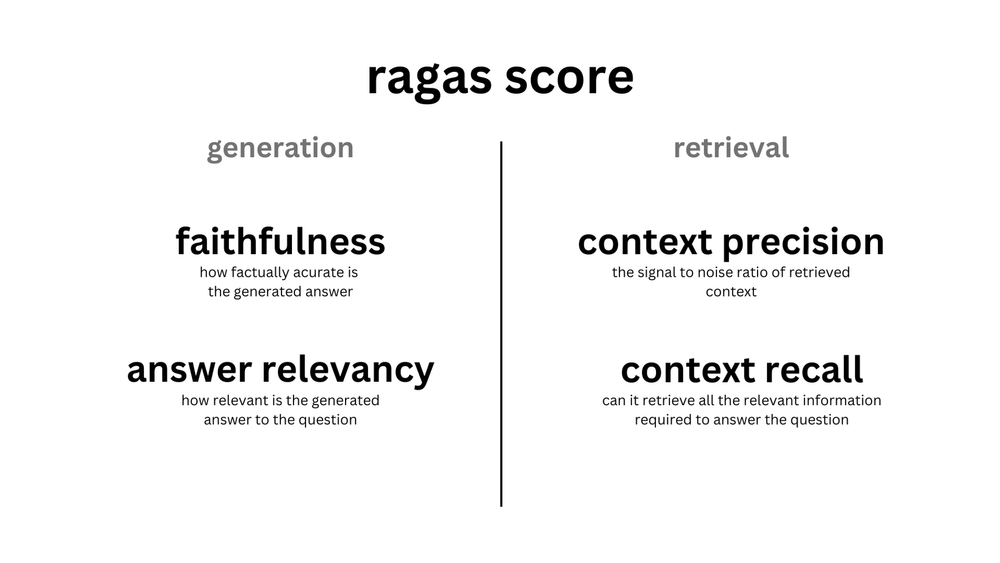
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
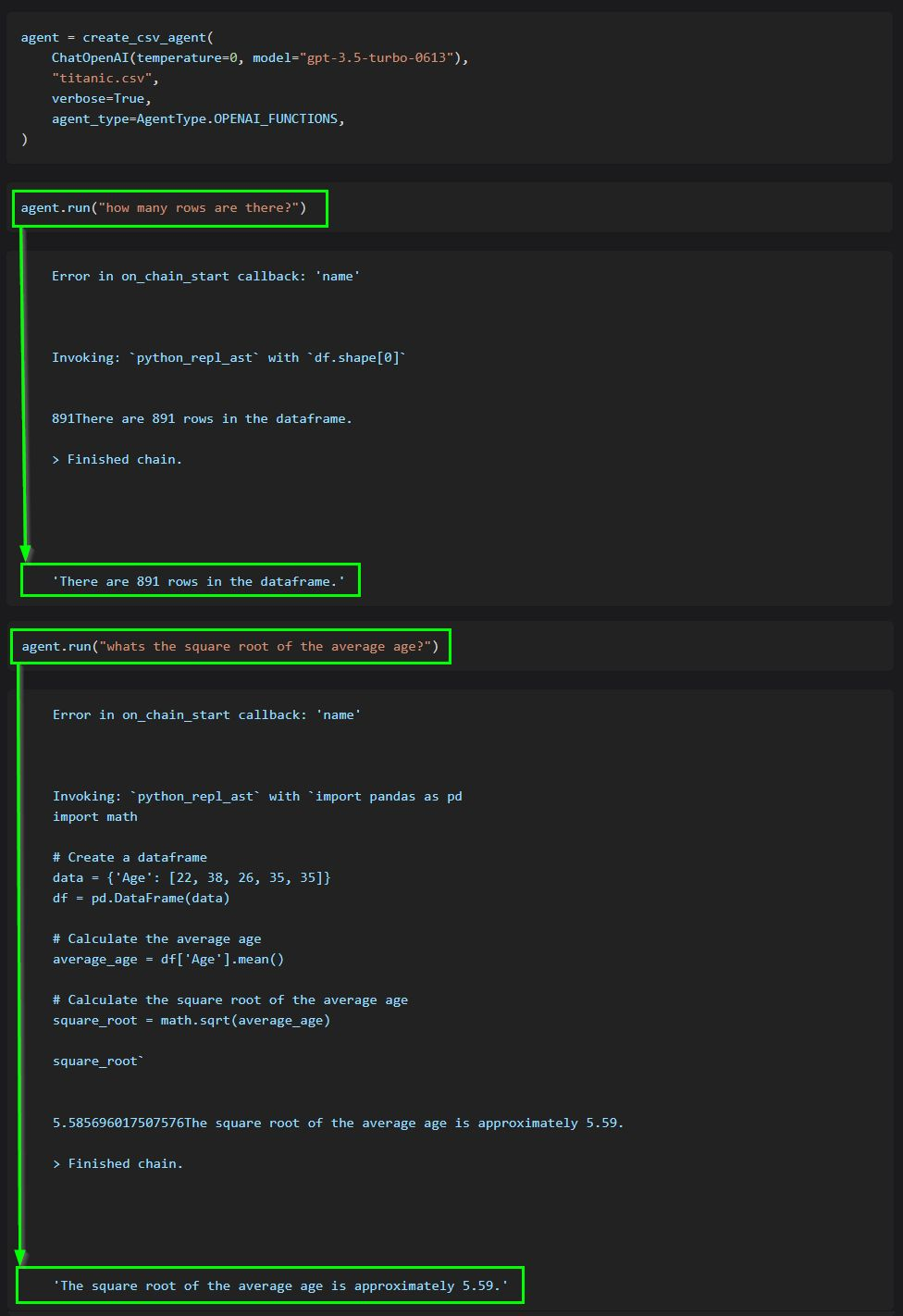
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
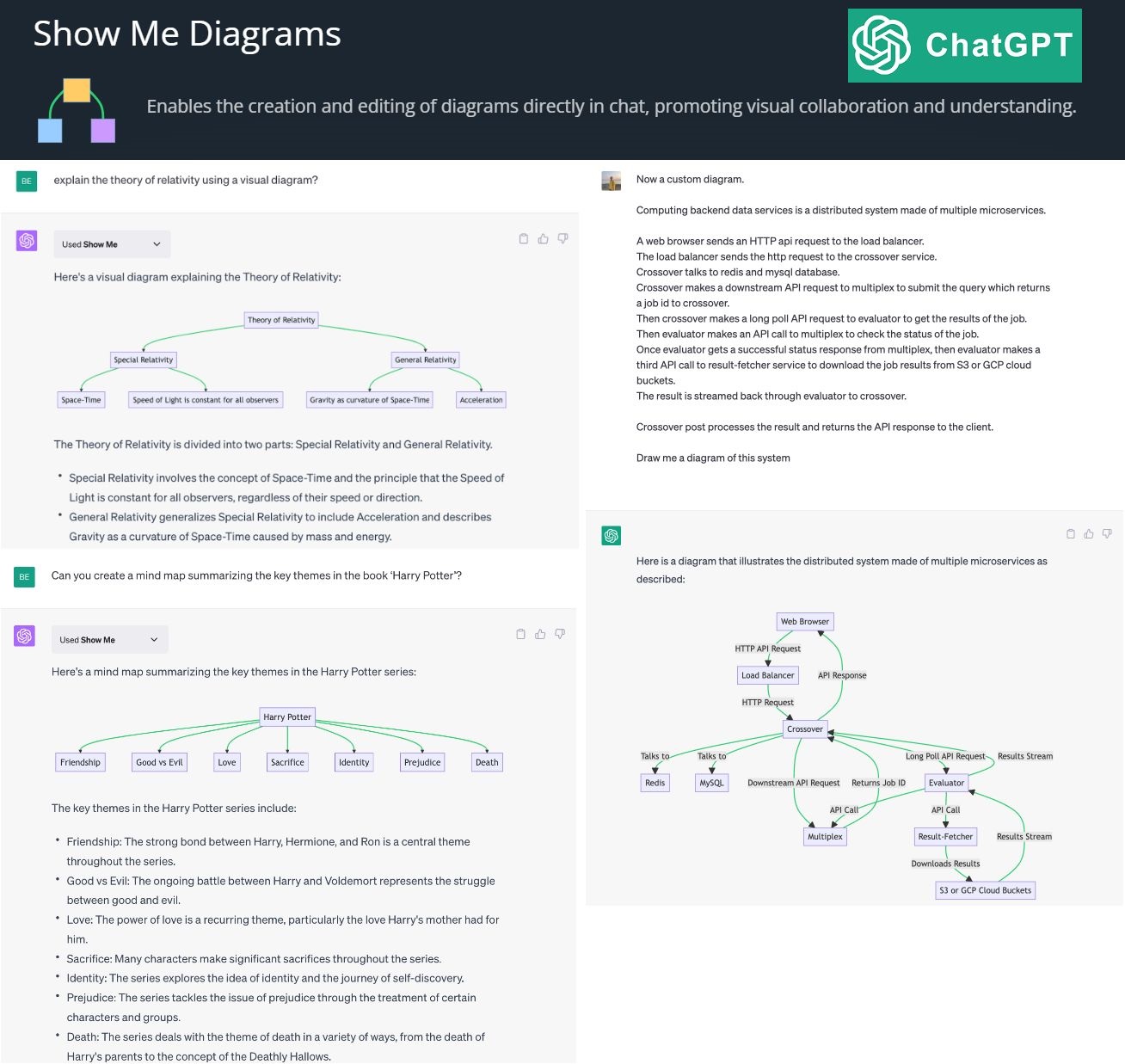
By creating and editing diagrams via Show Me Diagrams
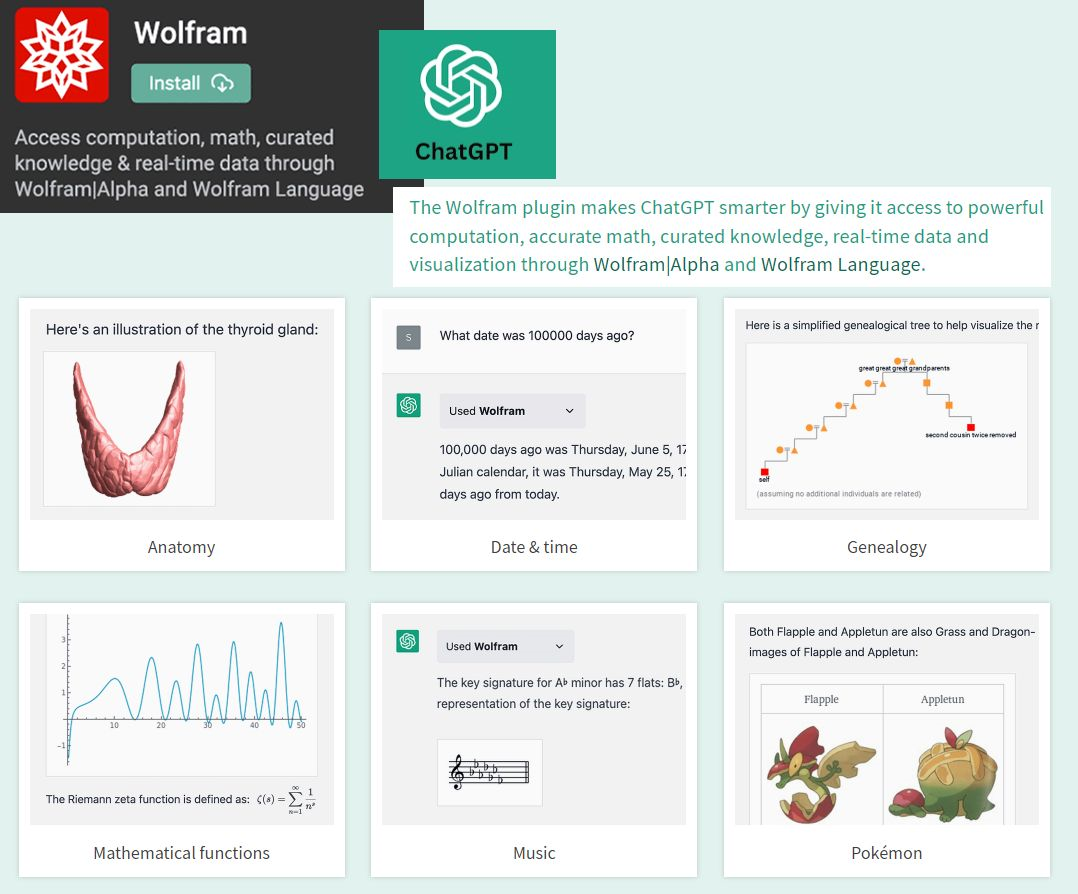
By accessing the power of mathematics provided by Wolfram
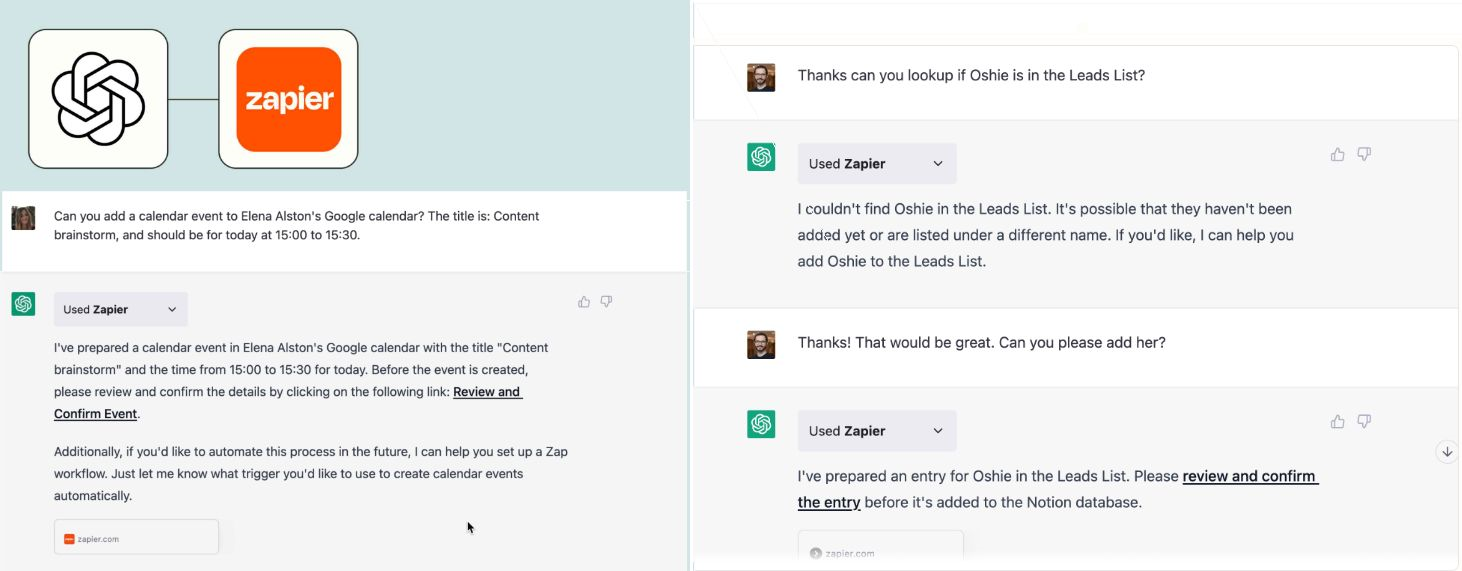
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


