llms
1.0.0
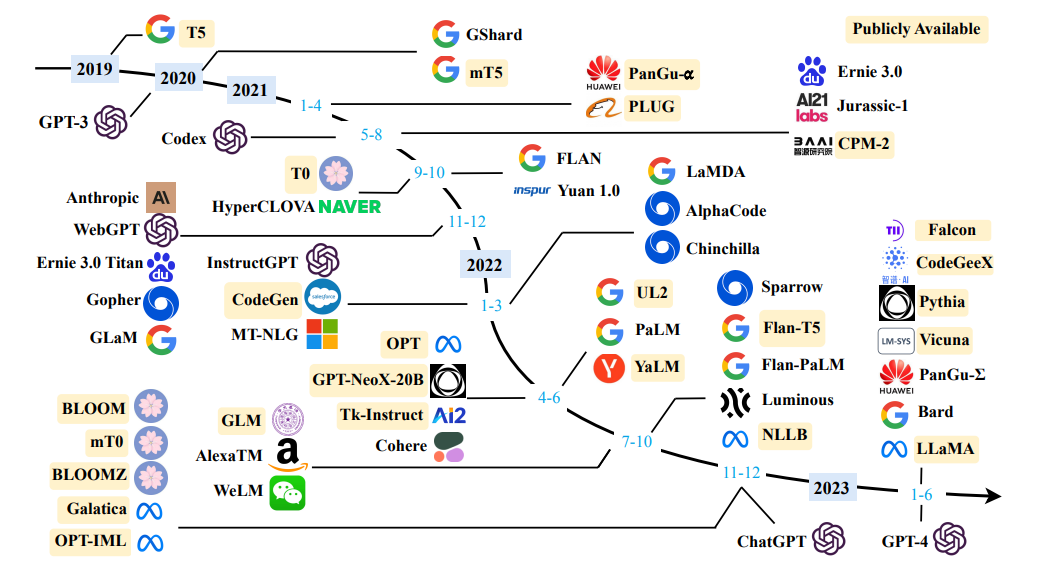 큰 언어 모델에 대한 설문 조사를 소스하십시오
큰 언어 모델에 대한 설문 조사를 소스하십시오
간단한 정의 : 언어 모델링은 다음에 어떤 단어가 오는지 예측하는 작업입니다.
"개는 ...에서 놀고있다 ..."
언어 모델 의 주요 목적은 문장에 확률을 할당하여 가능성이 높을 가능성이 높고 문장이 줄어 듭니다.
음성 인식을 위해, 우리는 음향 모델 (음성 신호)뿐만 아니라 언어 모델도 사용합니다. 마찬가지로 광학 문자 인식 (OCR)의 경우 비전 모델과 언어 모델을 모두 사용합니다. 언어 모델은 이러한 인식 시스템에 매우 중요합니다.
때때로, 당신은 명확하지 않은 문장을 듣거나 읽으십시오. 그러나 당신의 언어 모델을 사용하면 시끄러운 비전/음성 입력에도 불구하고 여전히 높은 정확도로 그것을 인식 할 수 있습니다.
언어 모델은 다음 중 하나를 계산합니다.
언어 모델링은 많은 NLP 작업의 하위 구성 요소, 특히 텍스트를 생성하거나 텍스트 확률을 추정하는 작업의 하위 구성 요소입니다.
체인 규칙 :
$ P (The, Water, is, is, so, clear) = p (The) × P (물 | the) × p (is | the, water) × p (so | the, water, is) × p (clear | the, water, is, so) $
방금 무슨 일이 있었나요? 체인 규칙은 문장에서 단어의 공동 확률을 계산하기 위해 적용됩니다.
많은 양의 텍스트 (Wikipedia와 같은 코퍼스)를 사용하여 단어가 얼마나 자주 얼마나 자주 있는지에 대한 통계를 수집하고이를 사용하여 다음 단어를 예측합니다. 예를 들어,이 세 단어가 열린 후 단어 W 가 올 확률은 다음과 같이 추정 될 수 있습니다.
위의 예는 4 그램 모델입니다. 그리고 우리는 다음을 얻을 수 있습니다.
우리는이 맥락에서 "책"이라는 단어가 "자동차"보다 가능성이 높다고 결론을 내릴 수 있습니다.
우리는 "학생들이 그들의 학생들을 열기 전에"이전 상황을 무시했습니다.
따라서, 다음 단어의 출력 확률 분포에서 샘플링하여 시작 단어가 주어진 언어 모델에서 임의의 텍스트를 생성 할 수 있습니다.
우리는 모든 종류의 텍스트로 LM을 훈련시킨 다음 해당 스타일 (Harry Potter 등)으로 텍스트를 생성 할 수 있습니다.
우리는 트리 그램, 4 그램, 5 그램 및 N- 그램으로 확장 할 수 있습니다.
일반적으로 언어는 장거리 종속성을 갖기 때문에 언어 모델입니다. 그러나 실제로이 3,4 그램은 대부분의 응용 분야에서 잘 작동합니다.
Google의 N-Gram 모델은 귀하에게 속합니다 : Google Research는 다양한 R & D 프로젝트에 Word N-Gram 모델을 사용하고 있습니다. Google N-Gram은 1,024,908,267,229 텍스트를 실행중인 단어로 처리했으며 40 번 이상 나타나는 1,176,470,663 개의 5 단어 시퀀스에 대해 카운트를 게시했습니다.
언어학 데이터 컨소시엄 LDC의 텍스트 수는 다음과 같습니다.
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
다음은이 코퍼스의 4 그램 데이터의 예입니다.
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
예를 들어, 네 단어의 "표시로 사용"의 순서는 코퍼스에서 72 번 나타났습니다.
때때로 우리는 추정 할 데이터가 충분하지 않습니다. N을 증가 시키면 희소성 문제가 악화됩니다. 일반적으로 우리는 5보다 큰 N을 가질 수 없습니다.
NLM은 일반적으로 (항상 아님) RNN을 사용하여 단어 시퀀스 (문장, 단락 등)를 학습하므로 다음 단어를 예측할 수 있습니다.
장점 :
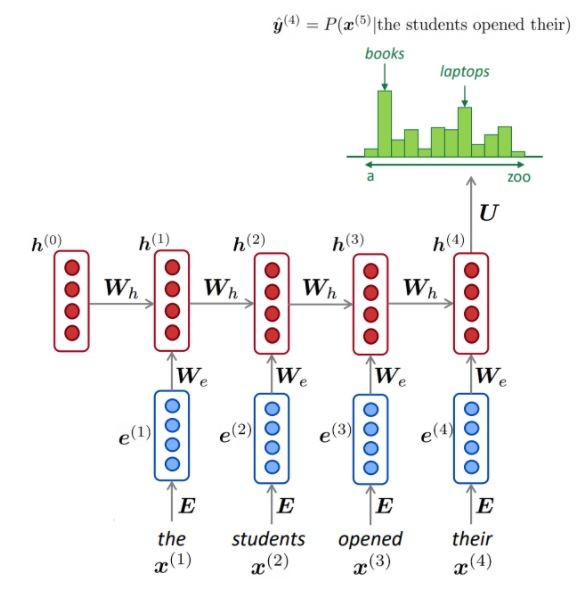
묘사 된 바와 같이, 각 단계에서, 우리는 어휘에 대한 다음 단어의 확률 분포가 있습니다.
NLM 교육 :
긴 시퀀스 학습의 예 :
단점 :
LM은 음성 인식, 기계 번역, 요약 등과 같은 다양한 응용 분야에서 입력 (Speech, Image (OCR), 텍스트 등의 텍스트 조건을 생성하는 데 사용될 수 있습니다.
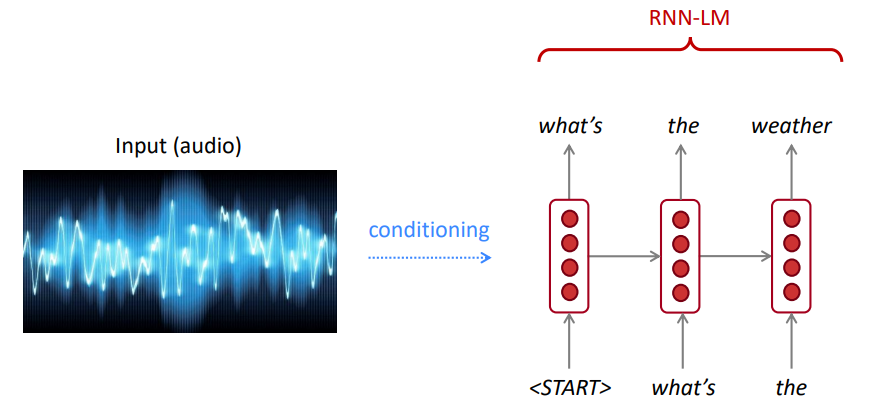
우리의 언어 모델은 나쁜 문장보다 좋은 문장을 선호합니까?
언어 모델의 표준 평가 메트릭은 당혹감이라는 것은 단어 수에 의해 정규화 된 테스트 세트의 역 확률입니다.
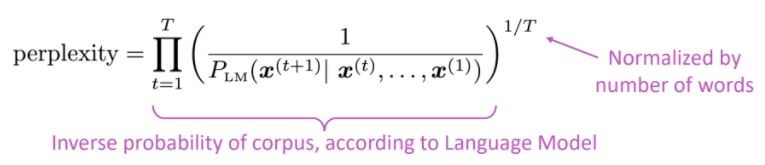
낮은 당황 = 더 나은 모델
당황은 분기 요인과 관련이 있습니다. 평균적으로 다음에 몇 가지 일이 발생할 수 있습니다.
RNN 대신 주목을 받자 큰 미리 훈련 된 모델을 사용해 봅시다.
문제는 무엇입니까? NLP (Natural Language Processing)에서 가장 큰 과제 중 하나는 많은 고유 한 작업에 대한 교육 데이터 부족입니다. 그러나 현대적인 딥 러닝 기반 NLP 모델은 수백만 명 또는 수십억 달러의 주석이 달린 교육 예제에 대해 교육을받을 때 향상됩니다.
사전 훈련은 해결책입니다. 이러한 격차를 해소하는 데 도움을주기 위해, 엄청난 양의 미확인 텍스트를 사용하여 일반 목적 언어 표현 모델을 훈련하기위한 다양한 기술이 개발되었습니다. 그런 다음 사전 훈련 된 모델은 질문 답변 및 감정 분석과 같은 다른 작업에 대해 작은 데이터에 미세 조정 될 수 있으며,이 데이터 세트에 대한 교육과 비교하여 실질적인 정확도가 향상됩니다.
트랜스포머 아키텍처는 신경 기계 번역 작업 (NMT)에 사용되는 종이주의에 필요한 모든 것입니다.
논문에서 언급했듯이 :
" 우리는 새로운 간단한 네트워크 아키텍처 인 Transformer를 제안합니다.주의 메커니즘 만 기반으로 재발 및 컨볼 루션으로 전적으로 분배됩니다 ."
주목 의 주요 아이디어는 Openai의 기사에서 언급 한 바와 같이 요약 될 수 있습니다.
" ... 모든 출력 요소는 모든 입력 요소에 연결되어 있으며, 그 사이의 가중치는 상황에 따라 동적으로 계산 됩니다.
이 아키텍처 (바닐라 변압기!)를 기반으로, 인코더 또는 디코더 구성 요소는 단독으로 사용하여 텍스트 분류, 번역, 요약, 질문 응답 등과 같은 다운 스트림 작업에 미세 조정할 수있는 대규모 미리 훈련 된 일반 모델을 가능하게 할 수 있습니다.
예를 들어 Bert 및 GPT 모델은 NLP의 Imagenet으로 간주 될 수 있습니다.
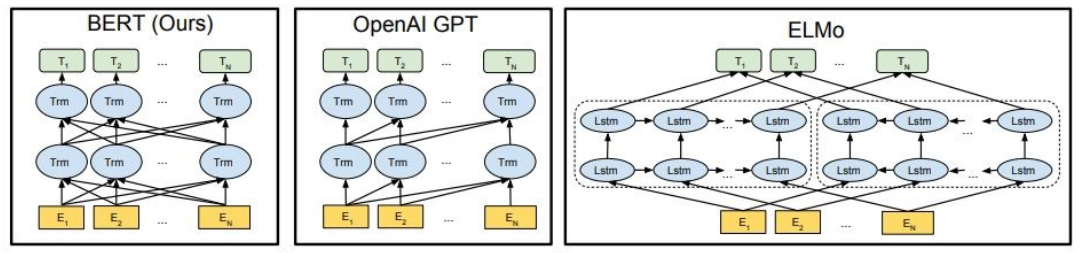
도시 된 바와 같이, Bert는 깊이 양방향이며, Openai GPT는 단방향이며 Elmo는 얕게 양방향입니다.
미리 훈련 된 표현은 다음과 같습니다.
상황에 맞는 언어 모델은 다음과 같습니다.
이 부분에서는 다른 큰 언어 모델을 사용할 것입니다.
GPT2 (GPT의 후임자)는 인과 언어 모델링 ( CLM ) 목표를 사용하여 영어에 대한 미리 훈련 된 모델이며, 40GB의 인터넷 텍스트에서 다음 단어를 예측하도록 훈련되었습니다. 이 페이지에서 처음 출시되었습니다. GPT2는 조건부 합성 텍스트 샘플을 생성하는 기능을 포함하여 광범위한 기능 세트를 표시합니다. 질문 답변, 독해, 요약 및 번역과 같은 언어 작업에서 GPT2는 작업 별 교육 데이터를 사용하여 원시 텍스트에서 이러한 작업을 배우기 시작합니다 . DistilGPT2는 증류 된 버전의 GPT2이며, 기본 모델보다 작고 쉽게 실행할 수있는 기능이 증가함에 따라 유사한 사용 사례에 사용됩니다.
여기에 미리 훈련 된 GPT2 모델을로드하고 GPT2 모델에 입력 텍스트 (프롬프트)를 계속하도록 요청하고 마지막으로 DistilGPT2 모델에서 임베디드 기능을 추출합니다.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Bert는 스스로 감독 된 방식으로 영어 데이터의 큰 코퍼스에서 미리 훈련 된 변압기 모델입니다. 이는 원시 텍스트에만 미리 훈련 된 것을 의미하며, 인간은 해당 텍스트에서 입력과 레이블을 생성하기 위해 자동 프로세스로 어떤 식 으로든 라벨을 붙이지 않았습니다. 더 정확하게는 두 가지 목표로 사전에 사전했습니다.
이 예에서는 감정 분석 작업에 미리 훈련 된 버트 모델을 사용합니다.
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4ALL은 소비자 등급 CPU에서 로컬로 실행되는 강력하고 맞춤형 대형 언어 모델을 훈련하고 배포하는 생태계입니다.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
다음 모델을 시도하십시오.
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM은 맞춤형 데이터 파이프 라인 및 분산 교육을 사용하여 처음부터 구축 된 TII의 대형 대형 언어 모델 시리즈입니다. Falcon-7B/40B 모델은 크기에 대한 최신 기술이며 NLP 벤치 마크에서 대부분의 다른 모델을 능가합니다. 오픈 소스 수많은 인공물 :
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
LLAMA2는 오늘 Meta에서 발표 한 최첨단 개방형 대형 언어 모델의 제품군이며, 포옹 얼굴에 포괄적 인 통합으로 출시를 완전히 지원하게되어 기쁩니다. LLAMA 2는 매우 허용되는 커뮤니티 라이센스로 출시되며 상업용으로 사용할 수 있습니다. 코드, 사전 처리 된 모델 및 미세 조정 모델이 모두 오늘 출시됩니다.
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
Codet5+는 다양한 모드 (즉, 인코더 전용, 디코더 전용 및 인코더 디코더)로 유연하게 작동하여 광범위한 코드 이해 및 생성 작업을 지원할 수있는 인코더 디코더 아키텍처를 갖춘 새로운 오픈 코드 대형 언어 모델 패밀리입니다.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
더 많은 모델을 보려면 코드 대형 언어 모델 (코드 LLM) 및 코드 인텔리전스 용 파이썬 변압기 기반 라이브러리 인 Salesforce에서 CodETF를 확인하여 코드 요약, 번역, 코드 생성 등과 같은 코드 인텔리전스 작업에 대한 교육 및 추론을위한 완벽한 인터페이스를 제공합니다.
? 닐 열린 큰 언어 모델과 채팅
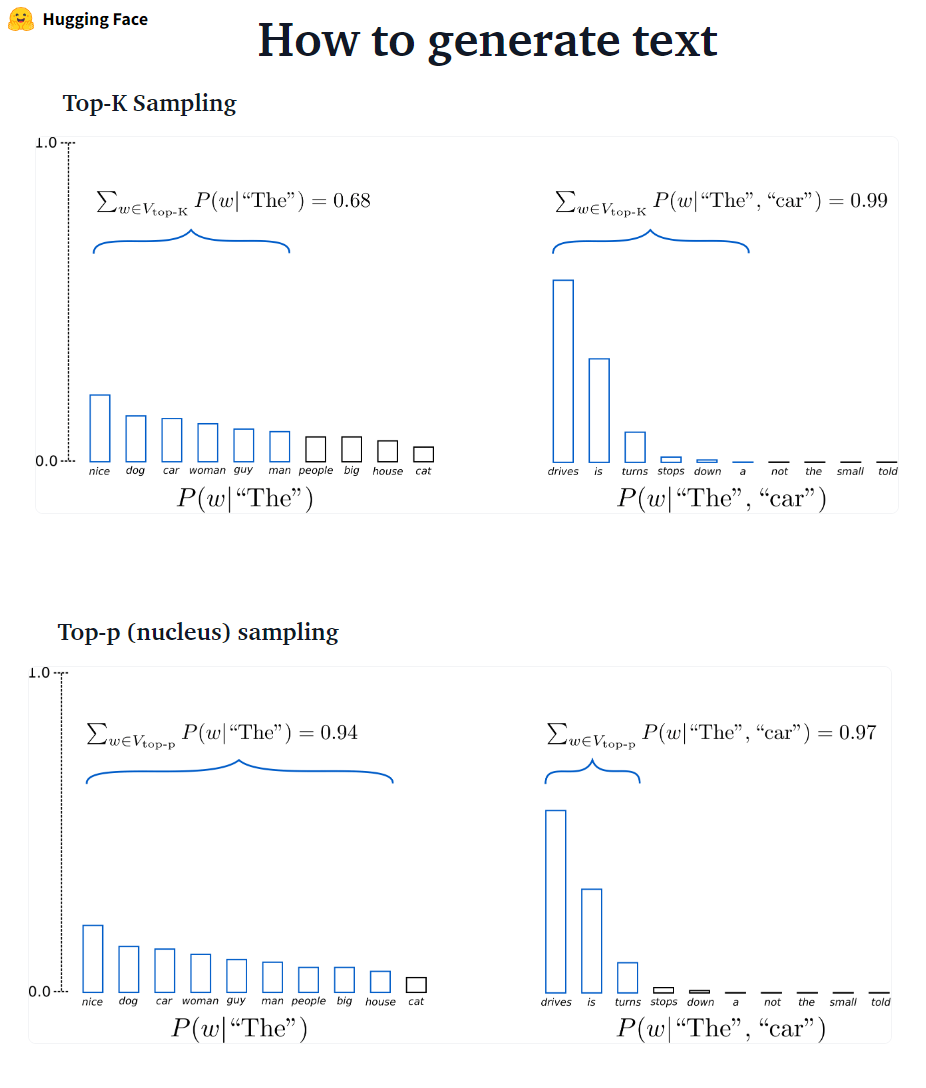
beam 빔 검색은 항상 욕심 많은 검색보다 확률이 높은 출력 시퀀스를 찾을 수 있지만 가장 가능성이 높은 출력을 찾을 수는 없습니다.
Transformers에서는 단순히 Num_return_Sequences 매개 변수를 반환 해야하는 최고 점수 빔의 수로 설정합니다. Num_return_Sequences <= num_beams를 확인하십시오!
beam 빔 검색은 원하는 생성의 길이가 기계 번역 또는 요약에서와 같이 다소 예측할 수있는 작업에서 매우 잘 작동 할 수 있습니다. ? 그러나 이것은 원하는 출력 길이가 크게 다를 수있는 개방형 세대의 경우가 아닙니다. 예를 들어 대화 및 스토리 생성. 빔 검색은 반복적 인 생성으로 크게 고통받습니다. 인간으로서, 우리는 우리를 놀라게하고 지루하거나 예측할 수 없도록 생성 된 텍스트를 원합니다 (? 빔 검색은 덜 놀랍습니다)
Transformers에서는 top_k = 0을 통해 do_sample = true 및 top-k 샘플링 (나중에 더 자세히 설명)을 설정합니다.
???-? ??????? GPT2는이 샘플링 체계를 채택했습니다.
???-? ??????? 그런 다음 확률 질량 이이 단어 세트 사이에 재배포됩니다. p = 0.92를 설정 한 상단 P 샘플링은 최소 단어 수를 선택하여 확률 질량의 92%를 초과합니다.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
top-P는 Top-K보다 우아하게 보이지만 두 방법 모두 실제로 잘 작동합니다. Top-P는 또한 Top-K와 함께 사용될 수 있으며, 이는 매우 낮은 순위 단어를 피하면서 동적 선택을 허용 할 수 있습니다.
Ad-Hoc 디코딩 방법으로서, Top-P 및 Top-K 샘플링은 기존의 탐욕과 개방형 언어 생성에 대한 빔 검색보다 더 유창한 텍스트를 생성하는 것으로 보입니다.
프롬프트 엔지니어링은 언어 모델의 프롬프트 (텍스트 입력)를 설계하여 필요한 출력을 생성하는 프로세스입니다. 프롬프트 엔지니어링에는 적절한 키워드를 선택하고 컨텍스트를 제공하며 원하는 응답을 달성하는 언어 모델 동작을 지시하는 방식으로 명확하고 구체적입니다. 신속한 엔지니어링을 통해 미세 조정없이 모델의 톤, 스타일, 길이 등을 제어 할 수 있습니다.
제로 샷 학습은 예를 들어 예제 (제로 샷)를 제공하지 않고 모델에 예측을하도록 요청하는 것입니다.
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
Zero-Shot이 충분하지 않으면 프롬프트에 예제를 제공하여 모델을 돕는 것이 좋습니다.
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
신속한 엔지니어링 외에도 더 많은 옵션을 고려할 수 있습니다.
보다 신속한 엔지니어링 정보는 모든 최신 논문, 학습 안내서, 강의, 참조 및 도구가 포함 된 신속한 엔지니어링 안내서를 참조하십시오.
다운 스트림 데이터 세트의 미세 조정 LLM은 사전에 사전 된 LLM을 사용하여 상자 (예 : 제로 샷 추론)를 사용하는 것과 비교할 때 성능이 큰 이점을 얻습니다. 그러나 모델이 점점 커짐에 따라 완전 미세 조정은 소비자 하드웨어를 훈련시키는 데 불가능 해집니다. 또한, 미세 조정 모델이 원래 전기 모델과 같은 크기이기 때문에 각 다운 스트림 작업에 대해 독립적으로 미세 조정 모델을 독립적으로 저장 및 배포하는 것은 매우 비싸집니다. 매개 변수 효율적인 미세 조정 (PEFT) 접근법은 두 문제를 모두 해결하기위한 것입니다! PEFT 접근 방식을 사용하면 완전 미세 조정과 비교하여 성능을 얻을 수 있으며 소수의 훈련 가능한 매개 변수 만 있으면됩니다. 예를 들어:
프롬프트 튜닝 : 냉동 언어 모델을 조정하여 특정 다운 스트림 작업을 수행하기 위해 "소프트 프롬프트"를 학습하는 간단하면서도 효과적인 메커니즘. 엔지니어링 된 텍스트 프롬프트와 마찬가지로 소프트 프롬프트가 입력 텍스트에 연결됩니다. 그러나 기존 어휘 항목에서 선택하는 대신 소프트 프롬프트의 "토큰"은 학습 가능한 벡터입니다. 이것은 다음과 같이 교육 데이터 세트를 통해 소프트 프롬프트를 최적화 할 수 있음을 의미합니다.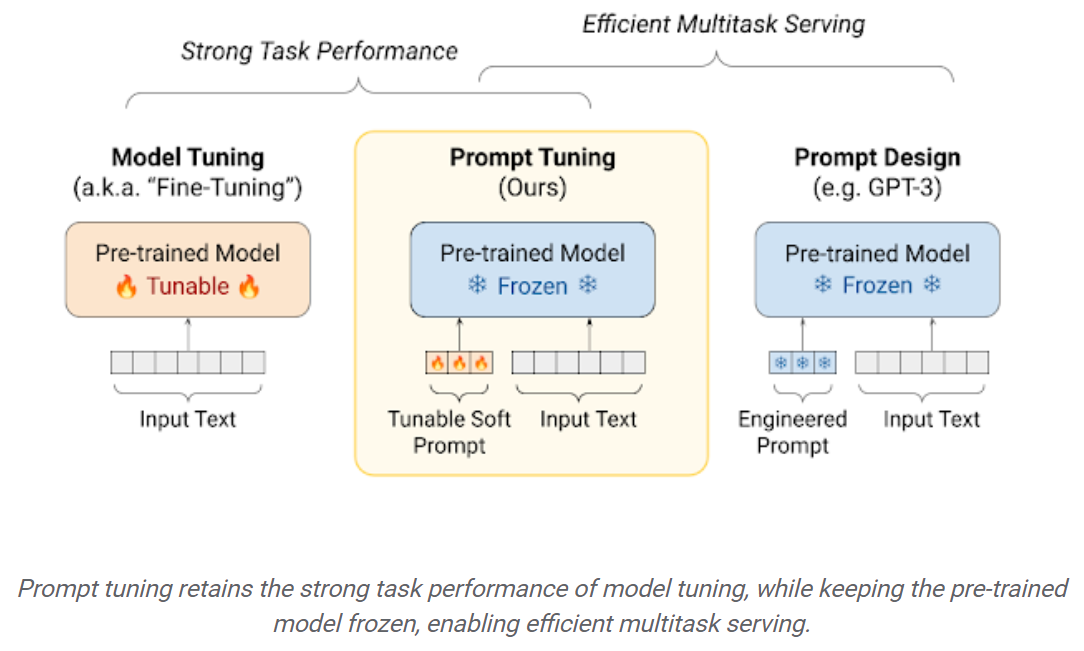
LLM의 LORA 저 순위 적응은 사전에 걸린 모델 가중치를 동결시키고 트랜스 트랜스포머 아키텍처의 각 층에 훈련 가능한 순위 분해 행렬을 주입하는 방법입니다. 다운 스트림 작업을위한 훈련 가능한 매개 변수 수를 크게 줄입니다. 이 비디오에서 아래 그림은 주요 아이디어를 설명합니다. 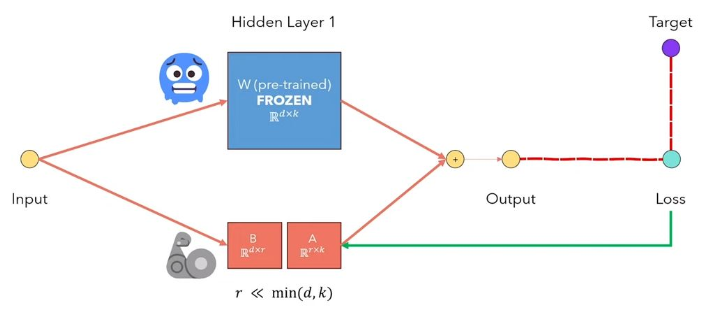
대형 언어 모델은 일반적으로 범용이며 도메인 별 작업에는 덜 효과적입니다. 그러나 감정 분석과 같은 일부 작업에서 미세 조정할 수 있습니다. 외부 지식이 필요한보다 복잡한 TAK의 경우 외부 지식 소스에 액세스하여 필요한 작업을 완료하는 언어 모델 기반 시스템을 구축 할 수 있습니다. 이를 통해보다 사실적인 정확성을 가능하게하고 "환각"문제를 완화하는 데 도움이됩니다. 아래의 피지어에서 볼 수 있듯이 :
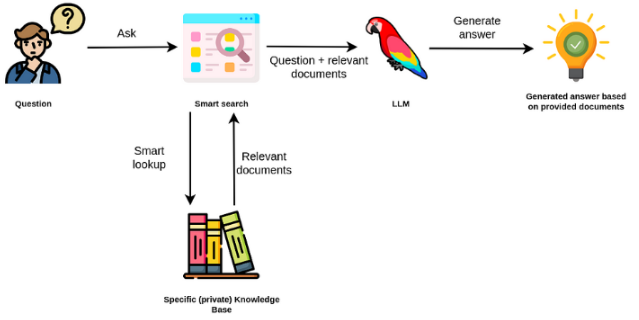
이 경우 LLM을 사용하여 내부 지식에 액세스하는 대신 LLM을 외부 지식의 자연어 인터페이스로 사용합니다. 첫 번째 단계는 문서와 모든 사용자 쿼리를 호환 형식으로 변환하여 관련 검색을 수행하는 것입니다 (텍스트를 벡터 또는 임베딩으로 변환). 그런 다음 원래 사용자 프롬프트는 외부 지식 출처 (컨텍스트) 내의 관련 / 유사한 문서와 함께 추가됩니다. 그런 다음이 모델은 제공된 외부 컨텍스트를 기반으로 질문에 답변합니다.
대형 언어 모델 (LLM)은 변형 기술로 떠오르고 있습니다. 그러나 이러한 LLM을 분리하여 사용하는 것은 종종 강력한 응용 프로그램을 만들기에 충분하지 않습니다. Langchain은 이러한 응용 프로그램의 개발을 지원하는 것을 목표로합니다.
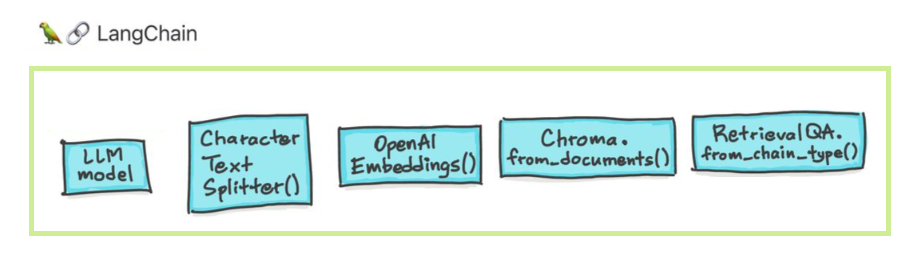
Langchain이 도움을주기 위해 설계된 6 가지 주요 영역이 있습니다. 이것들은 복잡성의 순서가 증가합니다.
여기에는 신속한 관리, 신속한 최적화, 모든 LLM을위한 일반 인터페이스 및 LLMS 작업을위한 일반적인 유틸리티가 포함됩니다. LLM 및 채팅 모델은 미묘하지만 중요하게 다릅니다. Langchain의 LLM은 순수한 텍스트 완성 모델을 나타냅니다. 그들이 랩하는 API는 입력으로 문자열 프롬프트를 취하고 문자열 완료를 출력합니다. OpenAi의 GPT-3은 LLM으로 구현됩니다. 채팅 모델은 종종 LLM에 의해 뒷받침되지만 대화를 나누기 위해 특별히 조정됩니다.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
반환 된 제공자 특정 정보에 액세스 할 수도 있습니다. 이 정보는 제공자 전체에 걸쳐 표준화되지 않습니다.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
채팅 모델의 프롬프트는 채팅 메시지 목록입니다. 각 채팅 메시지는 컨텐츠 및 역할이라는 추가 매개 변수와 관련이 있습니다. 예를 들어, OpenAI 채팅 완료 API에서 채팅 메시지는 AI 조수, 인간 또는 시스템 역할과 관련 될 수 있습니다.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
체인은 단일 LLM 호출을 넘어서 일련의 통화 (LLM 또는 다른 유틸리티에 관계없이)를 포함합니다. Langchain은 체인을위한 표준 인터페이스, 다른 도구와의 많은 통합 및 일반적인 응용 프로그램을위한 엔드 투 엔드 체인을 제공합니다. 체인은 매우 일반적으로 다른 체인을 포함 할 수있는 성분에 대한 일련의 호출로 정의 될 수 있습니다.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
데이터 증강 생성에는 먼저 외부 데이터 소스와 상호 작용하여 생성 단계에서 사용하기 위해 데이터를 가져 오는 특정 유형의 체인이 포함됩니다. 예로는 특정 데이터 소스에 대한 질문/답변이 포함됩니다.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
유사성 검색
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
에이전트에는 LLM이 취해야 할 조치, 그 행동을 취하고 관찰을보고, 끝까지 반복하는 것에 대한 결정을 내립니다. Langchain은 에이전트를위한 표준 인터페이스, 선택할 수있는 에이전트 선택 및 엔드 투 엔드 에이전트의 예를 제공합니다. 에이전트의 핵심 아이디어는 LLM을 사용하여 일련의 행동을 선택하는 것입니다. 체인에서는 일련의 행동이 하드 코딩됩니다 (코드). 에이전트에서 언어 모델은 추론 엔진으로 사용되어 어떤 작업을 수행 해야하는지 결정합니다.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
메모리는 체인/에이전트의 호출 사이의 지속 상태를 말합니다. Langchain은 메모리를위한 표준 인터페이스, 메모리 구현 모음 및 메모리를 사용하는 체인/에이전트의 예를 제공합니다.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
우리는 다른 방법을 사용하여 문서와 채팅 할 수 있습니다. 전체 LLM을 미세 조정할 필요가 없으며 대신에 우리의 질문과 함께 사전 훈련 된 모델에 대한 올바른 컨텍스트를 제공하고 제공된 문서를 기반으로 답변을 얻을 수 있습니다.
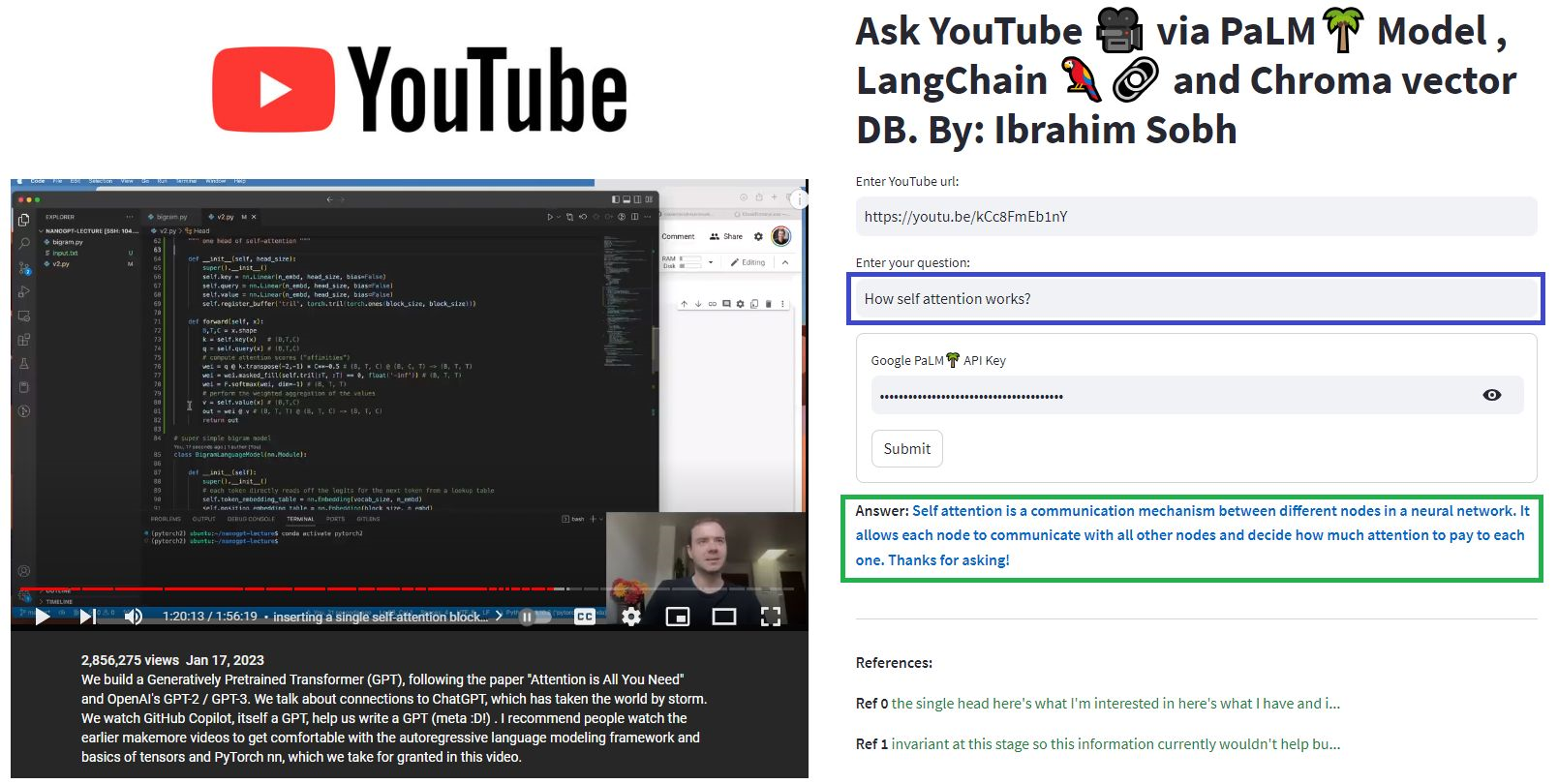
여기서 우리는 Transformers없이 통증이없는이 멋진 기사와 대화합니까? 트랜스포머,주의, 인코더 디코더 등과 관련된 질문을하는 동안 Google의 강력한 Palm 모델을 활용하면서 Langchain Framework는 언어 모델로 구동되는 응용 프로그램을 개발합니다.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
질문 : ? '이 문서는 무엇입니까?'
답변 : ? '문서는 자연어 처리 및 컴퓨터 비전 작업에 성공적으로 사용 된 신경망의 한 유형 인 변압기에 관한 것입니다.'
질문 : ? '변압기의 주요 아이디어는 무엇입니까?'
답변 : ? '변압기의 주요 아이디어는주의 메커니즘을 사용하여 장거리 종속성을 순서대로 모델링하는 것입니다.'
질문 : ? '위치 인코딩이란 무엇입니까?'
답변 : ? '위치 인코딩은 단어 순서를 순서대로 표현하는 데 사용되는 기술입니다.'
질문 : ? '쿼리, 키 및 값 벡터가 어떻게 사용됩니까?'
답변 : ? '쿼리 벡터는 키를 통해 값의 가중 합계를 계산하는 데 사용됩니다. 구체적으로 : Q 모든 키를 닷컴, SoftMax에서 가중치를 얻고 최종적으로 무게를 사용하여 가중치의 값을 계산합니다. '
질문 : ? '변압기 사용을 시작하는 방법?'
답변 : ? 'Transformers 사용을 시작하려면 Huggingface Transformers 라이브러리를 사용할 수 있습니다. 이 라이브러리는 100 개 이상의 언어로 분류, 정보 추출, 질문 답변, 요약, 번역, 텍스트 생성 등과 같은 텍스트에서 작업을 수행하기 위해 수천 개의 사전 제한 모델을 제공합니다. '
자신의 문서와 질문을 시도 할 수 있습니다!
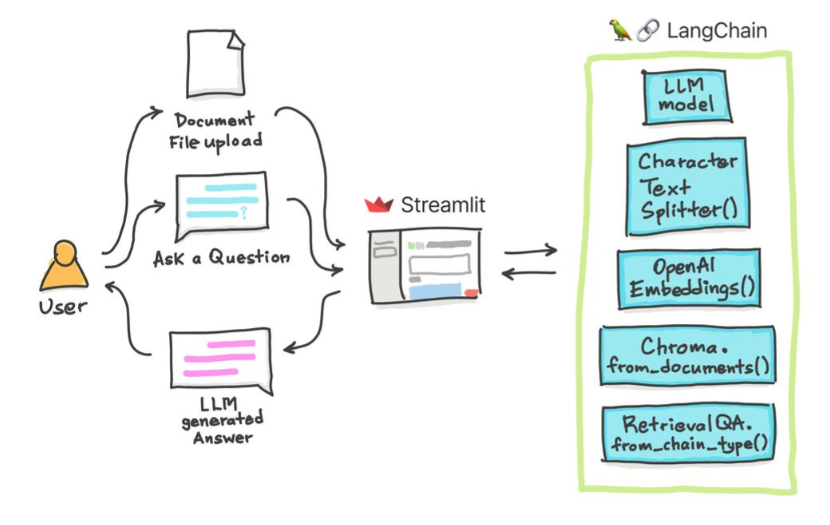
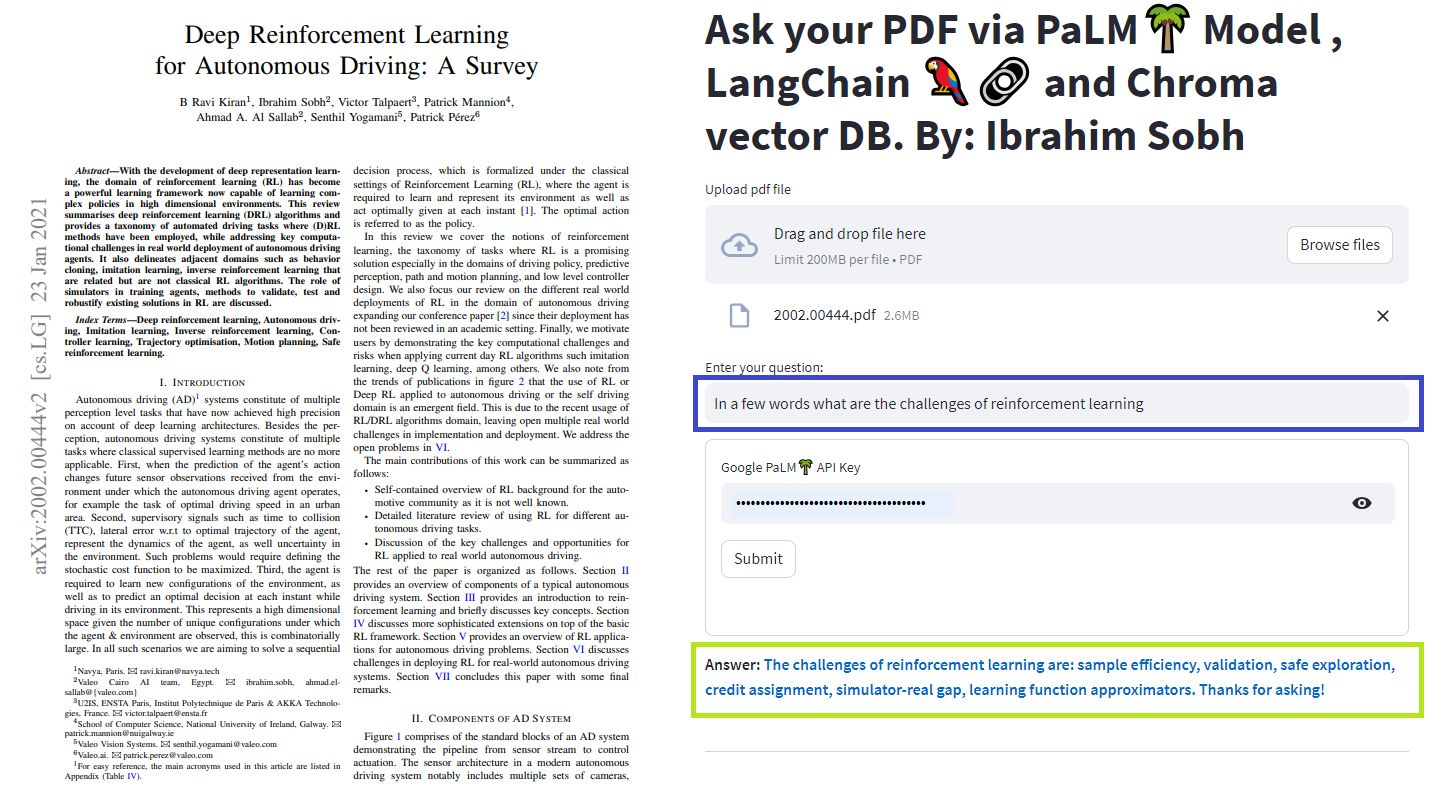
이 간단한 튜토리얼에서 : Chroma Vector Database, Google의 Palm LLM 및 Langchain의 질문 응답 체인을 사용하여 텍스트 문서, PDF 파일 및 YouTube 비디오에서 답을 얻는 방법. 마지막으로 Sleamlit을 사용하여 웹 응용 프로그램을 개발하고 호스팅하십시오. Google_api_key를 사용해야합니다 (Google에서 얻을 수 있음). Ths 시스템 아키텍처는 다음과 같습니다.
LLM 평가와 LLM 기반 시스템 평가에는 차이가 있습니다. 일반적으로 일반적인 사전 훈련 후 LLM은 표준 벤치 마크에서 평가됩니다.
LLMS 시스템은 텍스트를 요약하고, 질문 응답을하고, 텍스트의 감정을 찾고, 번역을 할 수 있습니다. 시스템을 기반으로 평가는 다음과 같습니다.
예를 들어 질문 응답 시스템 의 경우 평가 세트에 일련의 질문과 답변이 필요합니다. 우리는 인간 주석을 사용하여 골드 표준 쌍의 질문과 답변을 수동으로 만들 수 있습니다. 그러나 비용이 많이 들고 시간이 많이 걸립니다. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
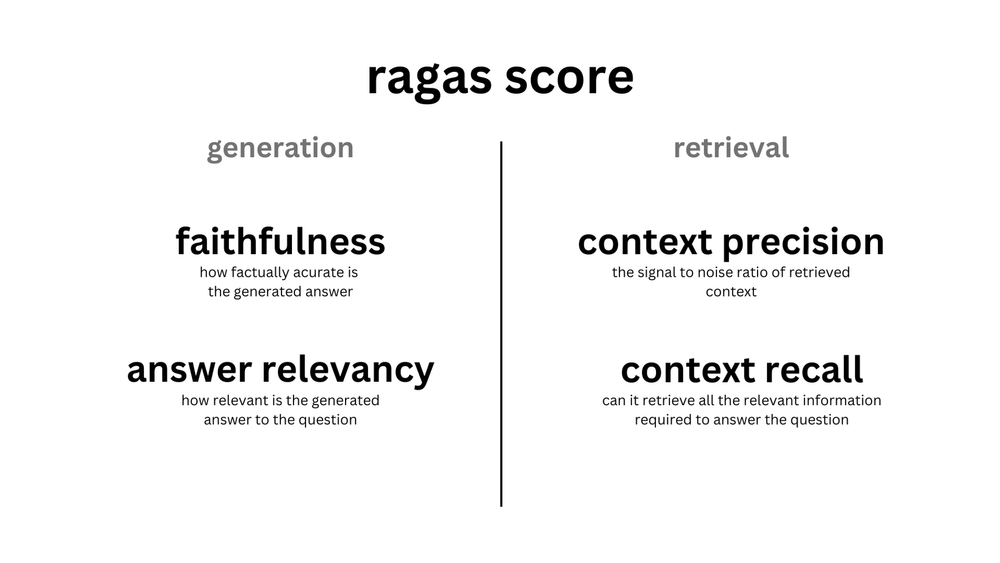
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
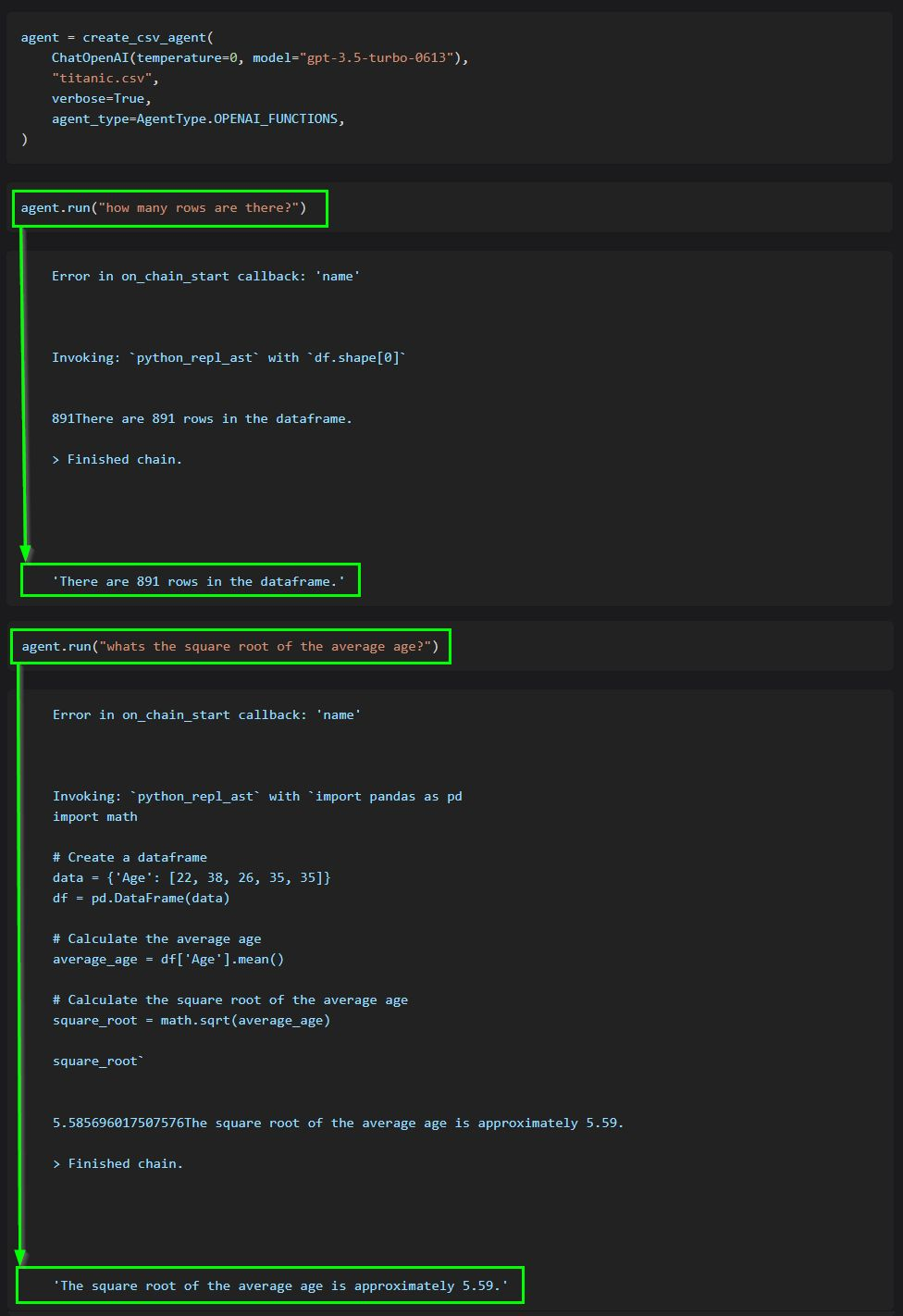
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
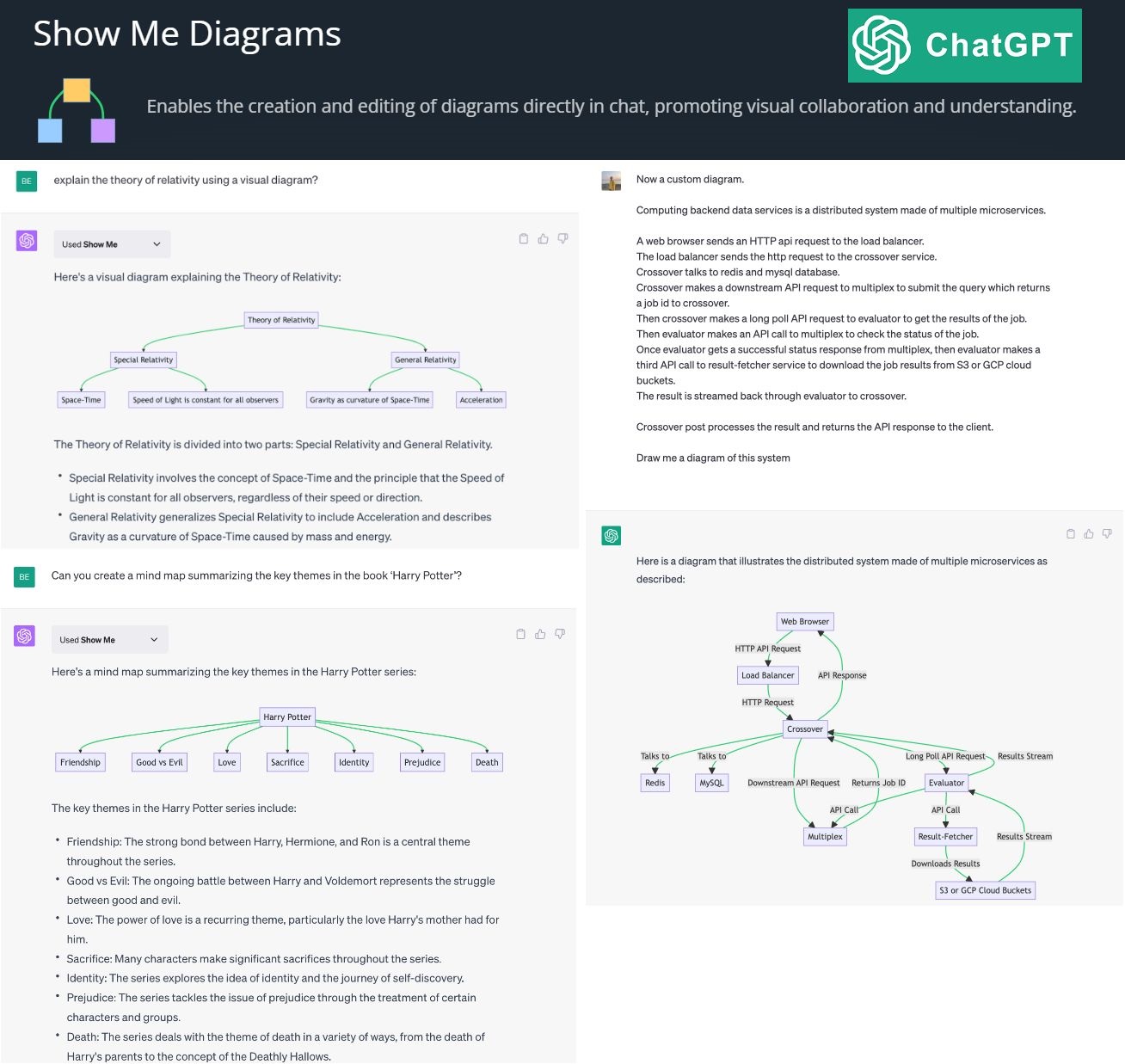
By creating and editing diagrams via Show Me Diagrams
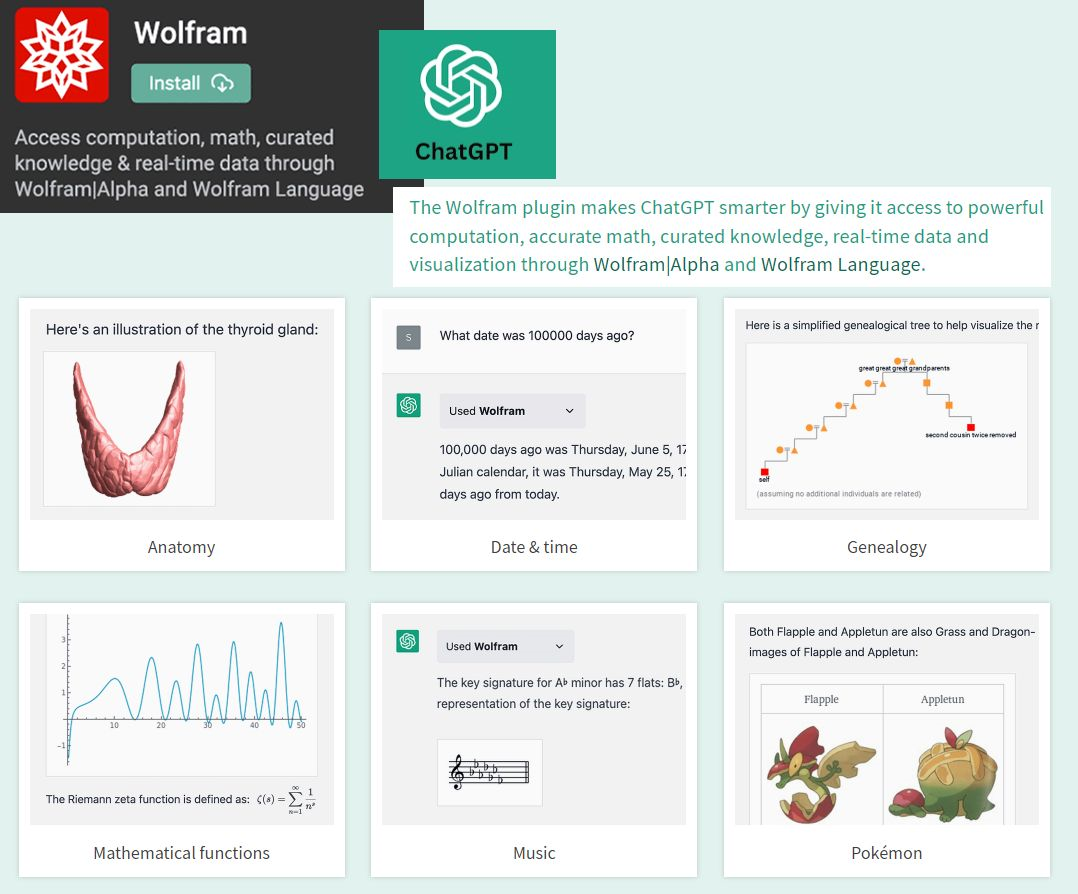
By accessing the power of mathematics provided by Wolfram
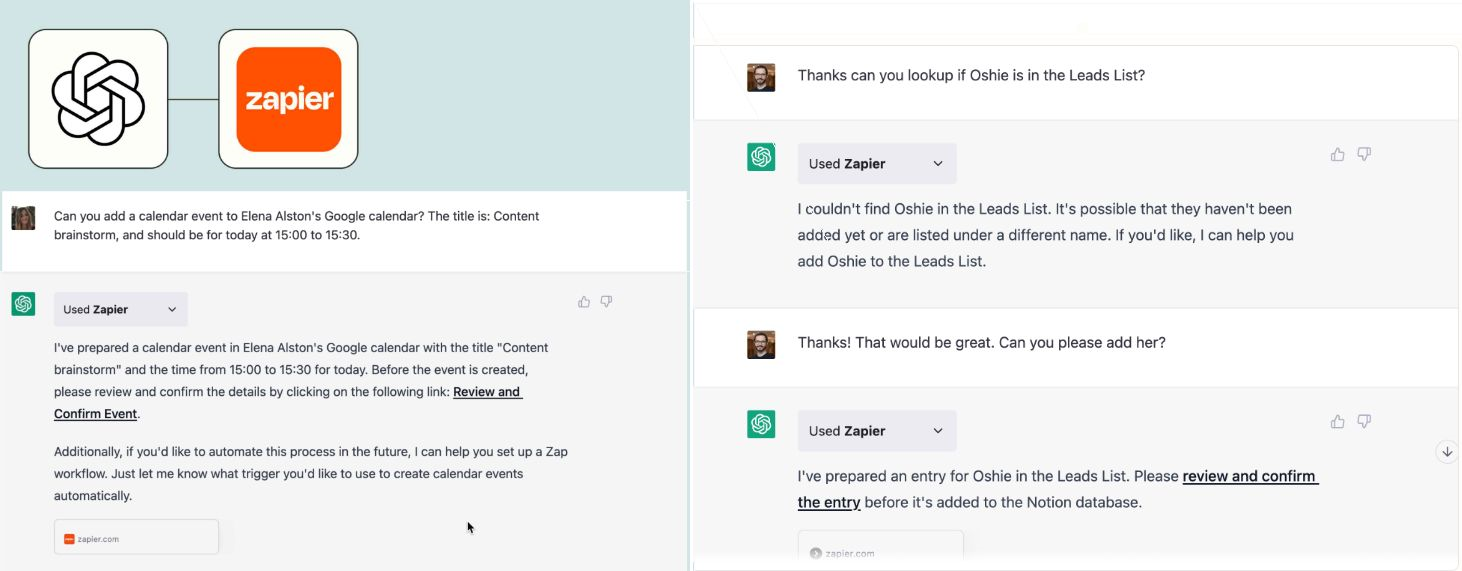
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


