llms
1.0.0
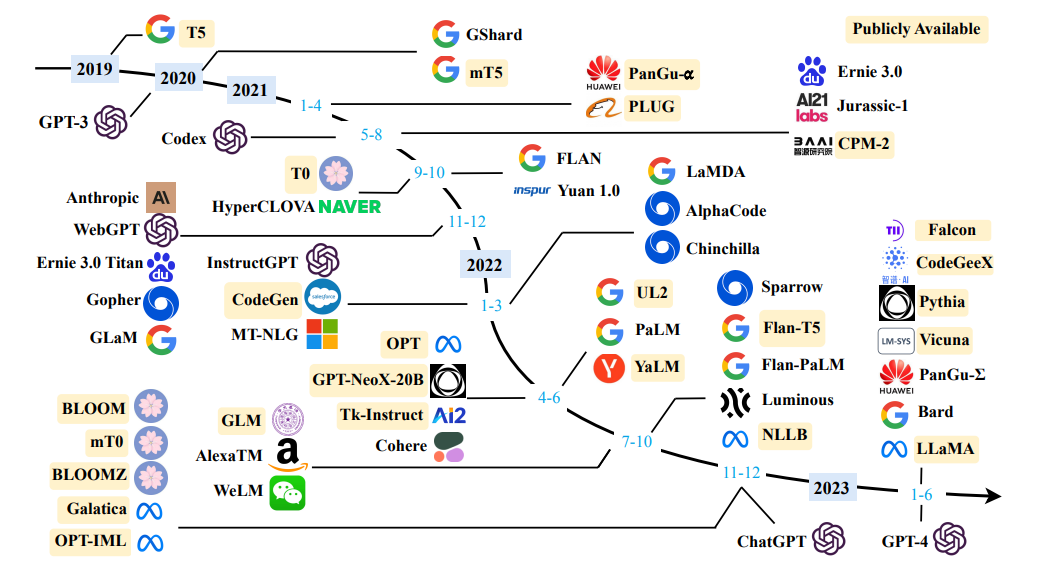 مصدر مسح لنماذج اللغة الكبيرة
مصدر مسح لنماذج اللغة الكبيرة
تعريف بسيط: نمذجة اللغة هي مهمة التنبؤ بالكلمة التي تأتي بعد ذلك.
"الكلب يلعب في ..."
الغرض الرئيسي من نماذج اللغة هو تعيين احتمال لجمل ، للتمييز بين الجمل الأكثر احتمالا والأقل احتمالا.
للتعرف على الكلام ، لا نستخدم فقط نموذج الصوتيات (إشارة الكلام) ، ولكن أيضًا نموذج لغة. وبالمثل ، بالنسبة للتعرف على الأحرف البصرية (OCR) ، نستخدم كل من نموذج الرؤية ونموذج اللغة. تعتبر نماذج اللغة مهمة جدًا لأنظمة التعرف هذه.
في بعض الأحيان ، تسمع أو تقرأ جملة غير واضحة ، ولكن باستخدام نموذج لغتك ، لا يزال بإمكانك التعرف عليها بدقة عالية على الرغم من مدخلات الرؤية/الكلام الصاخبة.
يحسب نموذج اللغة أي من:
نمذجة اللغة هي مكون فرعي للعديد من مهام NLP ، وخاصة تلك التي تتضمن توليد نص أو تقدير احتمال النص.
قاعدة السلسلة:
$ p (the ، water ، is ، so ، واضح) = p (the) × p (الماء | the) × p (هو |
ماذا حدث للتو؟ يتم تطبيق قاعدة السلسلة لحساب احتمال المفصل للكلمات في الجملة.
باستخدام كمية كبيرة من النص (Corpus مثل Wikipedia) ، نجمع إحصاءات حول مدى تواتر الكلمات المختلفة ، ونستخدمها للتنبؤ بالكلمة التالية. على سبيل المثال ، يمكن تقدير احتمال أن تكون كلمة "W" بعد هذه الكلمات الثلاث التي فتحها الطلاب على النحو التالي:
المثال أعلاه هو نموذج 4 غرام. وقد نحصل على:
يمكننا أن نستنتج أن كلمة "الكتب" أكثر احتمالًا من "السيارات" في هذا السياق.
لقد تجاهلنا السياق السابق قبل "فتح الطلاب"
وفقًا لذلك ، يمكن إنشاء نص تعسفي من نموذج لغة يُعطى الكلمات (الكلمات) بدءًا ، عن طريق أخذ العينات من توزيع احتمال الإخراج للكلمة التالية ، وما إلى ذلك.
يمكننا تدريب LM على أي نوع من النص ، ثم إنشاء نص بهذا النمط (Harry Potter ، وما إلى ذلك).
يمكننا أن نمتد إلى trigrams ، 4 غرامات ، 5 غرامات ، و n-grams.
بشكل عام ، هذا نموذج غير كافٍ للغة لأن اللغة لها تبعيات لمسافات طويلة. ومع ذلك ، في الممارسة العملية ، تعمل هذه 3،4 غرام بشكل جيد بالنسبة لمعظم التطبيقات.
نماذج N-Gram من Google تنتمي إليك: تستخدم Google Research نماذج Word N-Gram لمجموعة متنوعة من مشاريع البحث والتطوير. تمت معالجة Google N-GRAM 1،024،908،267،229 كلمة من تشغيل النص ونشرت التهمات لجميع تسلسلات خمسة كلمات تصل إلى 40 مرة على الأقل 40 مرة.
تعداد النص من Consortium Consortium LDC اللغويات كما يلي:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
فيما يلي مثال على بيانات 4 غرام في هذه المجموعة:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
على سبيل المثال ، شوهد تسلسل الكلمات الأربع "بمثابة مؤشر" في Corpus 72 مرة.
في بعض الأحيان ليس لدينا بيانات كافية لتقديرها. زيادة n تجعل مشاكل التباين أسوأ. عادة لا يمكننا الحصول على أكبر من 5.
عادةً ما تستخدم NLM (ولكن ليس دائمًا) RNN لتعلم تسلسل الكلمات (الجمل ، الفقرات ، ... إلخ) وبالتالي يمكن أن تتنبأ بالكلمة التالية.
المزايا:
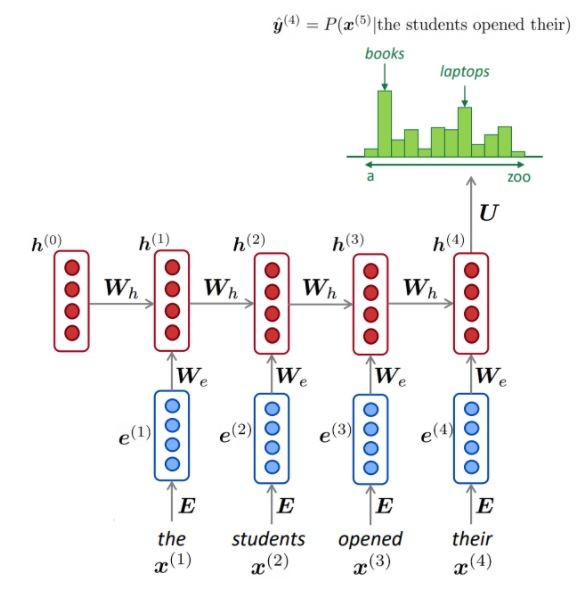
كما هو موضح ، في كل خطوة ، لدينا توزيع احتمال للكلمة التالية على المفردات.
تدريب NLM:
مثال على تعلم التسلسل الطويل:
عيوب:
يمكن استخدام LM لإنشاء ظروف نصية على الإدخال (الكلام ، الصورة (OCR) ، النص ، إلخ) عبر تطبيقات مختلفة مثل: التعرف على الكلام ، الترجمة الآلية ، تلخيص ، إلخ.
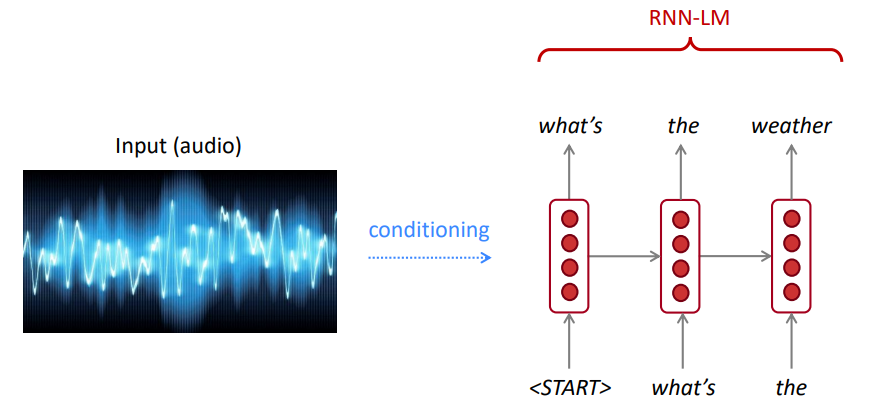
هل يفضل نموذج لغتنا الجمل الجيدة (المحتملة) على الجمل السيئة؟
إن مقياس التقييم القياسي لنماذج اللغة هو الحيرة في الحيرة هو الاحتمال العكسي لمجموعة الاختبار ، التي تم تطبيعها بعدد الكلمات
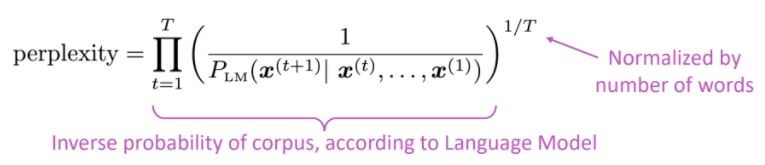
انخفاض الحيرة = نموذج أفضل
يرتبط الحيرة بعامل الفرع: في المتوسط ، كم عدد الأشياء التي يمكن أن تحدث بعد ذلك.
بدلاً من RNN ، دعونا نستخدم الانتباه ، دعنا نستخدم نماذج كبيرة تم تدريبها مسبقًا
ما هي المشكلة؟ أحد أكبر التحديات في معالجة اللغة الطبيعية (NLP) هو نقص بيانات التدريب للعديد من المهام المتميزة. ومع ذلك ، تتحسن نماذج NLP العميقة الحديثة عندما تدربت على الملايين أو المليارات ، من أمثلة التدريب المشروحة.
ما قبل التدريب هو الحل: للمساعدة في سد هذه الفجوة ، تم تطوير مجموعة متنوعة من التقنيات لتدريب نماذج تمثيل اللغة للأغراض العامة باستخدام كمية هائلة من النص غير المُمثل. يمكن بعد ذلك ضبط النموذج الذي تم تدريبه مسبقًا على بيانات صغيرة لمهام مختلفة مثل الإجابة على الأسئلة وتحليل المشاعر ، مما يؤدي إلى تحسينات كبيرة في الدقة مقارنة بالتدريب على مجموعات البيانات هذه من نقطة الصفر.
تم اقتراح بنية المحولات في الاهتمام الورقي هو كل ما تحتاجه ، وتستخدم لمهمة الترجمة الآلية العصبية (NMT) ، التي تتكون من:
كما ذكر في الورقة:
" نقترح بنية شبكة بسيطة جديدة ، المحول ، يعتمد فقط على آليات الانتباه ، والتوزيع مع التكرار والتلوين بالكامل "
يمكن تلخيص الفكرة الرئيسية للانتباه كما هو مذكور في مقالة Openai:
" ... يتم توصيل كل عنصر إخراج بكل عنصر إدخال ، ويتم حساب الأوزان بينهما ديناميكيًا بناءً على الظروف ، ودعت العملية الانتباه. "
استنادًا إلى هذه البنية (محولات الفانيليا!) ، يمكن استخدام مكونات التشفير أو وحدة فك الترميز بمفردها لتمكين نماذج عامة ضخمة تم تدريبها مسبقًا والتي يمكن ضبطها بشكل جيد للمهام المصب مثل تصنيف النص ، والترجمة ، والتلخيص ، والرد على الأسئلة ، وما إلى ذلك: على سبيل المثال:
هذه النماذج ، Bert و GPT على سبيل المثال ، يمكن اعتبارها ImageNet NLP.
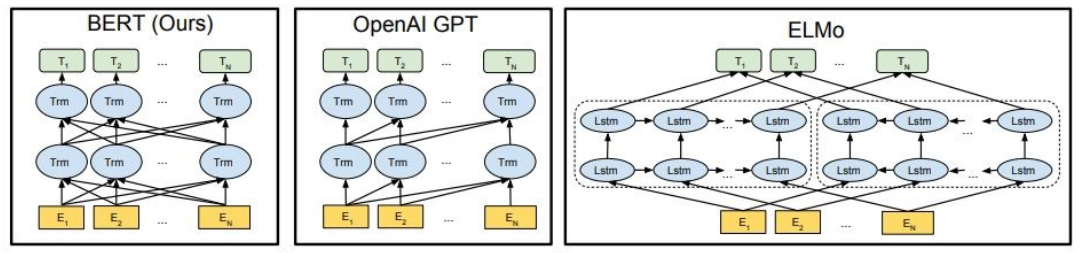
كما هو موضح ، يكون Bert ثنائي الاتجاه بعمق ، Openai GPT غير الاتجاهي ، وإلمو ثنائي الاتجاه بشكل ضحل.
يمكن أن تكون التمثيلات المدربة مسبقًا:
يمكن أن تكون نماذج اللغة السياقية:
في هذا الجزء ، سنستخدم نماذج لغة كبيرة مختلفة
GPT2 (خليفة لـ GPT) هو نموذج تدريب مسبقًا على اللغة الإنجليزية باستخدام هدف نمذجة اللغة السببية ( CLM ) ، مدرب ببساطة على التنبؤ بالكلمة التالية في نص الإنترنت 40 جيجابايت. تم إصداره لأول مرة في هذه الصفحة. يعرض GPT2 مجموعة واسعة من القدرات ، بما في ذلك القدرة على إنشاء عينات نصية اصطناعية مشروطة. فيما يتعلق بمهام اللغة مثل الإجابة على الأسئلة ، وفهم القراءة ، والتلخيص ، والترجمة ، يبدأ GPT2 في تعلم هذه المهام من النص الخام ، باستخدام أي بيانات تدريب خاصة بالمهمة. Distilgpt2 هو نسخة مقطرة من GPT2 ، ويهدف إلى استخدامها لحالات الاستخدام المماثلة مع زيادة وظائف كونها أصغر وأسهل في التشغيل من النموذج الأساسي.
نحن هنا نقوم بتحميل نموذج GPT2 الذي تم تدريبه مسبقًا ، واطلب من طراز GPT2 متابعة نص الإدخال الخاص بنا (موجه) ، وأخيراً ، استخراج الميزات المضمنة من نموذج Distilgpt2.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Bert هو نموذج Transformers تم تدريبه مسبقًا على مجموعة كبيرة من البيانات الإنجليزية بطريقة خاضعة للإشراف ذاتيًا. هذا يعني أنه تم تدريبه مسبقًا على النصوص الأولية فقط ، مع عدم وجود أي من البشر ووصفهم بأي شكل من الأشكال مع عملية تلقائية لإنشاء مدخلات وعلامات من تلك النصوص. بتعبير أدق ، تم تجهيزه بهدفين:
في هذا المثال ، سنستخدم نموذج BERT الذي تم تدريبه مسبقًا لمهمة تحليل المشاعر.
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4ALL هو نظام بيئي لتدريب ونشر نماذج لغة كبيرة قوية ومخصصة تعمل محليًا على وحدات المعالجة المركزية لدرجة المستهلك.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
جرب النماذج التالية:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM هي سلسلة TII الرائدة من نماذج اللغة الكبيرة ، التي تم تصميمها من نقطة الصفر باستخدام خط أنابيب بيانات مخصص والتدريب الموزعة. تعتبر نماذج Falcon-7B/40B حديثة لحجمها ، حيث تتفوق على معظم النماذج الأخرى على معايير NLP. مفتوح المصدر عدد من القطع الأثرية:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
LLAMA2 هي عائلة من نماذج اللغة الكبيرة التي تم الوصول إليها على أحدث طراز تصدرها META اليوم ، ونحن متحمسون لدعم الإطلاق تمامًا مع التكامل الشامل في وجه المعانقة. يتم إصدار Llama 2 بترخيص مجتمعي متاح للغاية وهو متاح للاستخدام التجاري. يتم إصدار الكود ، والنماذج المسبقة ، والنماذج التي يتم ضبطها بالكامل اليوم
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
CODET5+ هي عائلة جديدة من نماذج اللغة المفتوحة ذات الرمز المفتوح مع بنية ترميز تشفير يمكن أن تعمل بمرونة في أوضاع مختلفة (أي تشفير فقط ، ودلو المشفر فقط ، والتشفير المشفر) لدعم مجموعة واسعة من فهم التعليمات البرمجية ومهام توليدها.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
لمزيد من النماذج ، تحقق من CODETF من Salesforce ، وهي مكتبة تستند إلى محول Python لنماذج اللغة الكبيرة (CODE LLMS) وذكاء التعليمات البرمجية ، وتوفير واجهة سلسة للتدريب والاستنتاج على مهام ذكاء الكود مثل تلخيص الكود ، والترجمة ، وتوليد الرمز ، وما إلى ذلك.
️ الدردشة مع نماذج لغة كبيرة مفتوحة
✅ سيجد البحث عن شعاع دائمًا تسلسل إخراج مع احتمال أعلى من البحث الجشع ، ولكن ليس مضمونًا للعثور على الإخراج الأكثر احتمالًا.
في Transformers ، نقوم ببساطة بتعيين المعلمة num_return_sexences على عدد من أعلى حزم التسجيل التي يجب إرجاعها. تأكد على الرغم من أن num_return_quareces <= num_beams!
✅ يمكن أن يعمل البحث عن الشعاع بشكل جيد للغاية في المهام التي يكون فيها طول الجيل المطلوب إلى حد ما يمكن التنبؤ به كما هو الحال في الترجمة الآلية أو التلخيص. لكن هذا ليس هو الحال بالنسبة للجيل المفتوح حيث يمكن أن يختلف طول الإخراج المطلوب اختلافًا كبيرًا ، مثل الحوار وتوليد القصة. بحث شعاع يعاني بشدة من الجيل المتكرر. كبشر ، نريد نصًا تم إنشاؤه يفاجئنا ولا نكون مملًا/يمكن التنبؤ به (؟ البحث عن الشعاع أقل إثارة للدهشة)
في المحولات ، قمنا بتعيين do_sample = true و deactivate top-k أخذ العينات (المزيد على هذا لاحقًا) عبر top_k = 0.
؟؟؟-؟ ؟؟؟؟؟؟؟؟؟ اعتمد GPT2 مخطط أخذ العينات هذا.
؟؟؟-؟ ؟؟؟؟؟؟؟؟: بدلاً من أخذ العينات فقط من الكلمات K على الأرجح ، في أخذ أخذ العينات من أعلى P يختار من أصغر مجموعة من الكلمات التي يتجاوز احتمالها التراكمي احتمال p. ثم يتم إعادة توزيع كتلة الاحتمال بين هذه المجموعة من الكلمات. بعد تعيين P = 0.92 ، يختار أخذ العينات TOP-P الحد الأدنى لعدد الكلمات لتجاوز 92 ٪ من كتلة الاحتمال.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ في حين أن Top-P يبدو أكثر أناقة من Top-K ، فإن كلتا الطريقتين تعمل بشكل جيد في الممارسة العملية. يمكن أيضًا استخدام Top-P مع Top-K ، والتي يمكن أن تتجنب الكلمات المنخفضة للغاية في المرتبة مع السماح ببعض الاختيار الديناميكي.
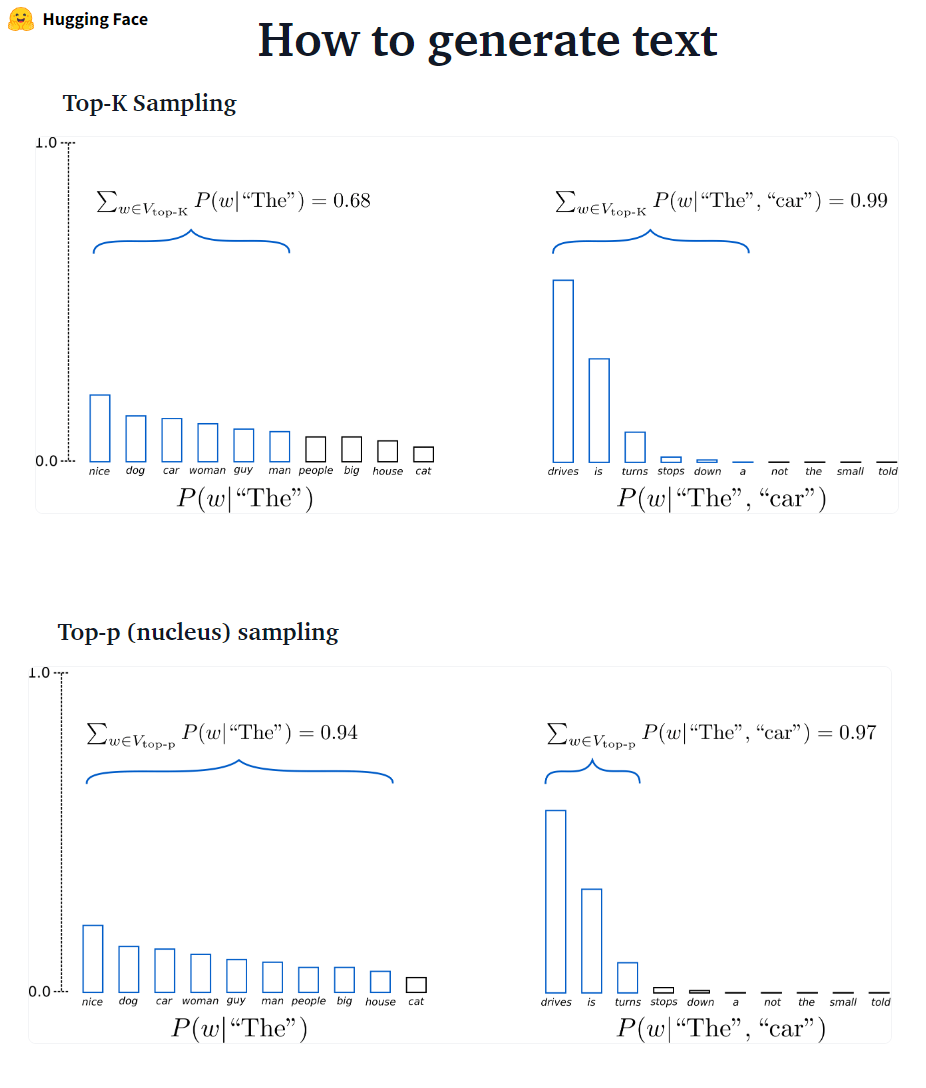
✅ كطرق فك التشفير المخصصة ، يبدو أن أخذ العينات العلوية والأخذ في أعلى K ينتجون نصًا أكثر بطلاقة من البحث الجشع التقليدي-والبحث عن شعاع على توليد اللغة المفتوحة.
الهندسة المطالبة هي عملية تصميم المطالبات (إدخال النص) لنموذج اللغة لإنشاء الإخراج المطلوب. تتضمن الهندسة المطالبة اختيار الكلمات الرئيسية المناسبة ، وتوفير السياق ، والواضح والمحدد بطريقة توجه سلوك نموذج اللغة الذي يحقق الاستجابات المطلوبة. من خلال الهندسة السريعة ، يمكننا التحكم في نغمة الطراز وأسلوبه وطوله وما إلى ذلك دون ضبطه.
يتضمن التعلم الصفري لطرح طلقة من النموذج تقديم تنبؤات دون تقديم أي أمثلة (صفر لقطة) ، على سبيل المثال:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
عندما لا تكون الصفر بشكل جيد بما فيه الكفاية ، يوصى بمساعدة النموذج من خلال تقديم أمثلة في المطالبة التي تؤدي إلى ظهور قليلة.
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
بالإضافة إلى الهندسة السريعة ، قد ننظر في المزيد من الخيارات:
لمزيد من المعلومات الهندسية السريعة ، راجع دليل الهندسة السريعة التي تحتوي على جميع أحدث الأوراق ، وأدلة التعلم ، والمحاضرات ، والمراجع ، والأدوات.
ينتج عن LLMs لضرب LLMS على مجموعات البيانات المصب مكاسب ضخمة في الأداء عند مقارنتها باستخدام LLMS المسبق خارج الصندوق (استنتاج صفري ، على سبيل المثال). ومع ذلك ، مع تزايد النماذج وأكبر ، يصبح التثبيت الكامل غير ممكن للتدريب على أجهزة المستهلك. بالإضافة إلى ذلك ، يصبح تخزين ونشر النماذج التي يتم ضبطها بشكل مستقل لكل مهمة مصب مكلفة للغاية ، لأن النماذج التي يتم ضبطها هي بنفس حجم النموذج الأصلي المسبق. تهدف مقاربات الصقل الدقيق (PEFT) الموفرة للمعلمة إلى معالجة كلتا المشكلتين! تمكنك أساليب PEFT من الحصول على أداء مماثل للضوء الكامل مع وجود عدد صغير فقط من المعلمات القابلة للتدريب. على سبيل المثال:
الضبط السريع: آلية بسيطة ولكنها فعالة لتعلم "المطالبات اللينة" لتكوين نماذج اللغة المجمدة لأداء مهام محددة. تمامًا مثل مطالبات النص المهندسة ، يتم تسلسل المطالبات الناعمة إلى نص الإدخال. ولكن بدلاً من الاختيار من عناصر المفردات الحالية ، فإن "الرموز" للمطالبة الناعمة هي متجهات قابلة للتعلم. هذا يعني أنه يمكن تحسين مطالبة ناعمة على مجموعة بيانات التدريب ، كما هو موضح أدناه: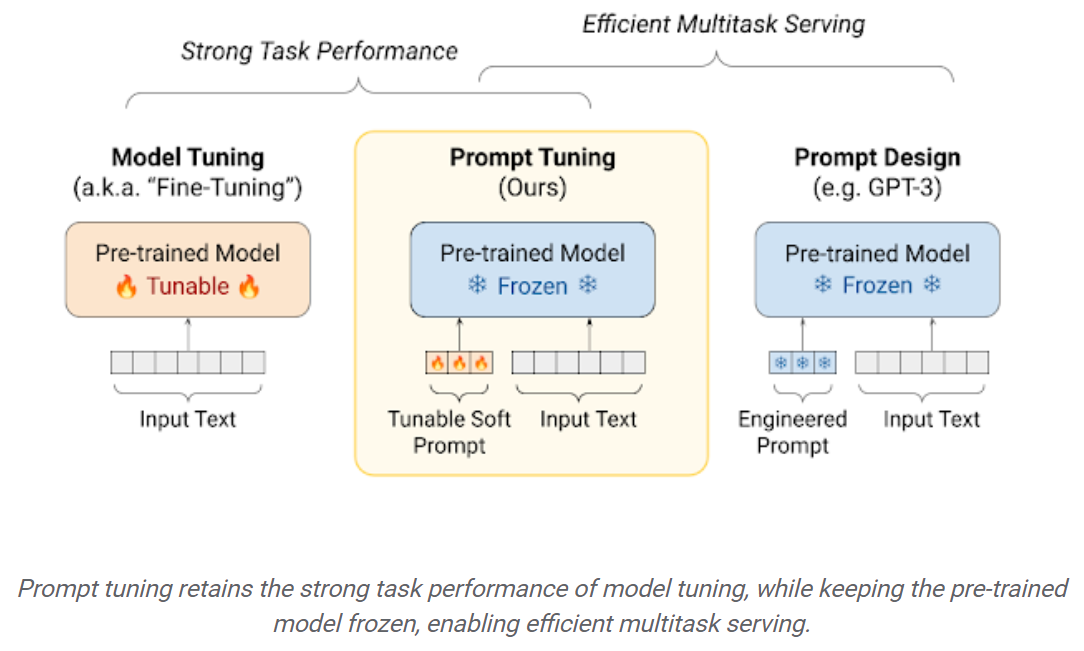
يعد تكيف Lora LLMS منخفضًا لـ LLMS طريقة تجمد أوزان النموذج المسبق وحقن مصفوفات تحلل المرتبة القابلة للتدريب في كل طبقة من بنية المحول. مما يقلل بشكل كبير من عدد المعلمات القابلة للتدريب لمهام المصب. يشرح الشكل أدناه ، من هذا الفيديو ، الفكرة الرئيسية: 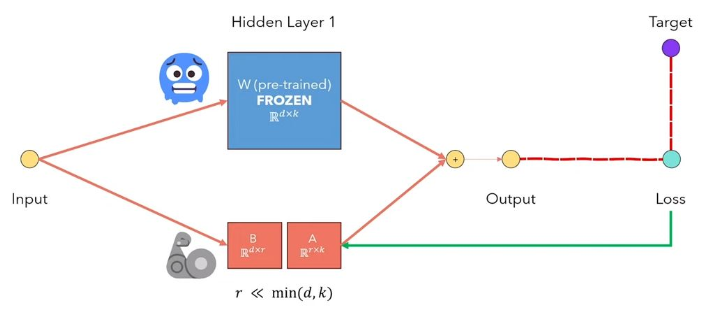
نماذج اللغة الكبيرة عادة ما تكون غرضًا عامًا ، وأقل فعالية للمهام الخاصة بالمجال. ومع ذلك ، يمكن ضبطها في بعض المهام مثل تحليل المشاعر. بالنسبة إلى TAK أكثر تعقيدًا تتطلب معرفة خارجية ، من الممكن إنشاء نظام قائم على نموذج اللغة يصل إلى مصادر المعرفة الخارجية لإكمال المهام المطلوبة. وهذا يتيح المزيد من الدقة الواقعية ، ويساعد على تخفيف مشكلة "الهلوسة". كما هو موضح في فيغرير أدناه:
في هذه الحالة ، بدلاً من استخدام LLMs للوصول إلى معرفتها الداخلية ، نستخدم LLM كواجهة لغة طبيعية لمعرفتنا الخارجية. تتمثل الخطوة الأولى في تحويل المستندات وأي استفسارات مستخدم إلى تنسيق متوافق لأداء البحث عن الصلة (تحويل النص إلى متجهات ، أو تضمينات). ثم يتم إلحاق موجه المستخدم الأصلي بمستندات ذات صلة / مشابهة ضمن مصدر المعرفة الخارجي (كسياق). ثم يجيب النموذج على الأسئلة بناءً على السياق الخارجي المقدم.
نماذج اللغة الكبيرة (LLMs) تظهر كتقنية تحويلية. ومع ذلك ، فإن استخدام LLMs هذه في العزلة غالبًا ما يكون غير كافٍ لإنشاء تطبيقات قوية حقًا. يهدف Langchain إلى المساعدة في تطوير مثل هذه التطبيقات.
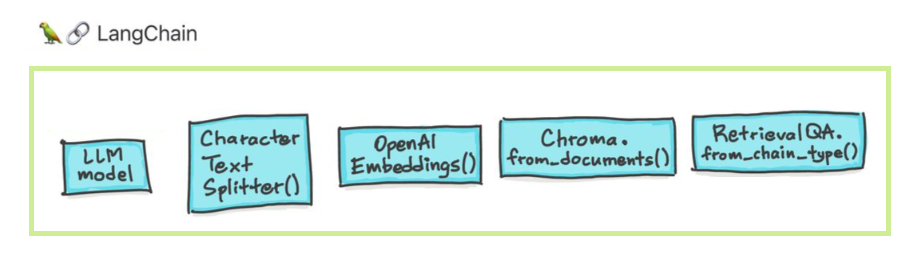
هناك ستة مجالات رئيسية تم تصميم Langchain للمساعدة. هذه ، في ترتيب متزايد للتعقيد:
ويشمل ذلك الإدارة المطالبة ، والتحسين السريع ، وواجهة عامة لجميع LLMs ، والمرافق المشتركة للعمل مع LLMs. LLMS ونماذج الدردشة هي بمهارة ولكنها مختلفة بشكل مهم. LLMS في Langchain تشير إلى نماذج إكمال النص النقي. واجهات برمجة التطبيقات التي يلفونها تأخذ مطالبة السلسلة كمدخلات وإخراج إكمال السلسلة. يتم تنفيذ GPT-3 من Openai كـ LLM. غالبًا ما يتم دعم نماذج الدردشة بواسطة LLMs ولكن تم ضبطها خصيصًا لإجراء محادثات.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
يمكنك أيضًا الوصول إلى معلومات محددة موفر يتم إرجاعها. هذه المعلومات ليست موحدة عبر مقدمي الخدمات.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
مطالبة نماذج الدردشة هي قائمة رسائل الدردشة. ترتبط كل رسالة دردشة بالمحتوى ، ومعلمة إضافية تسمى الدور. على سبيل المثال ، في واجهة برمجة تطبيقات Openai Chat Explies ، يمكن أن ترتبط رسالة الدردشة بمساعد منظمة العفو الدولية أو الإنسان أو دور النظام.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
تتجاوز السلاسل مكالمة LLM واحدة وتتضمن تسلسل المكالمات (سواء إلى LLM أو أداة مختلفة). يوفر Langchain واجهة قياسية للسلاسل ، والكثير من التكامل مع الأدوات الأخرى ، والسلاسل من طرف إلى طرف للتطبيقات الشائعة. يمكن تعريف السلسلة بشكل عام على أنها سلسلة من المكالمات للمكونات ، والتي يمكن أن تشمل سلاسل أخرى.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
يتضمن الجيل المعزز للبيانات أنواعًا محددة من السلاسل التي تتفاعل أولاً مع مصدر بيانات خارجي لجلب البيانات لاستخدامها في خطوة التوليد. ومن الأمثلة على ذلك السؤال/الإجابة على مصادر بيانات محددة.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
البحث عن التشابه
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
يتضمن الوكلاء قرارات LLM حول الإجراءات التي يجب اتخاذها ، واتخاذ هذا الإجراء ، ورؤية الملاحظة ، وتكرار ذلك حتى القيام به. يوفر Langchain واجهة قياسية للوكلاء ، ومجموعة مختارة من الوكلاء للاختيار من بينها ، وأمثلة من الوكلاء الشامل. تتمثل الفكرة الأساسية للوكلاء في استخدام LLM لاختيار سلسلة من الإجراءات التي يجب اتخاذها. في السلاسل ، يتم ترميز سلسلة من الإجراءات (في الكود). في الوكلاء ، يتم استخدام نموذج اللغة كمحرك تفكير لتحديد الإجراءات التي يجب اتخاذها وبأي ترتيب.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
تشير الذاكرة إلى الحالة المستمرة بين مكالمات سلسلة/وكيل. يوفر Langchain واجهة قياسية للذاكرة ، ومجموعة من تطبيقات الذاكرة ، وأمثلة من السلاسل/الوكلاء التي تستخدم الذاكرة.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
يمكننا استخدام طرق مختلفة للدردشة مع مستنداتنا. لا حاجة لضبط LLM بأكملها ، وبدلاً من ذلك يمكننا توفير السياق الصحيح مع سؤالنا إلى النموذج الذي تم تدريبه مسبقًا وببساطة الحصول على الإجابات بناءً على مستنداتنا المقدمة.
هنا ، نتحدث مع هذه المقالة الجميلة بعنوان Transformers بلا ألم؟ طرح الأسئلة المتعلقة بالمحولات والانتباه والرمز المشفر ، إلخ. أثناء استخدام نموذج النخيل القوي بواسطة Google وإطار Langchain لتطوير التطبيقات التي تعمل بنماذج اللغة.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
سؤال : ؟ "ما هي هذه الوثائق؟"
إجابة : ؟ "تدور المستندات حول المحولات ، وهي نوع من الشبكات العصبية التي تم استخدامها بنجاح في معالجة اللغة الطبيعية ومهام رؤية الكمبيوتر."
سؤال : ؟ "ما هي الفكرة الرئيسية للمحولات؟"
إجابة : ؟ "الفكرة الرئيسية للمحولات هي استخدام آليات الانتباه لنمذجة التبعيات طويلة المدى في التسلسلات."
سؤال : ؟ "ما هو الترميز الموضعي؟"
إجابة : ؟ "الترميز الموضعي هو تقنية تستخدم لتمثيل ترتيب الكلمات في تسلسل."
سؤال : ؟ "كيف يتم استخدام ناقلات الاستعلام والمفتاح والقيمة؟"
إجابة : ؟ "يتم استخدام متجه الاستعلام لحساب مجموع مرجح للقيم من خلال المفاتيح. على وجه التحديد: Q DOT المنتج جميع المفاتيح ، ثم SoftMax للحصول على الأوزان وأخيراً استخدام هذه الأوزان لحساب مجموع القيم الموزون. "
سؤال : ؟ "كيف تبدأ في استخدام المحولات؟"
إجابة : ؟ لبدء استخدام المحولات ، يمكنك استخدام مكتبة Huggingface Transformers. توفر هذه المكتبة الآلاف من النماذج المسبقة لأداء مهام على نصوص مثل التصنيف ، واستخراج المعلومات ، والإجابة على الأسئلة ، والتلخيص ، والترجمة ، وتوليد النص ، وما إلى ذلك في أكثر من 100 لغة.
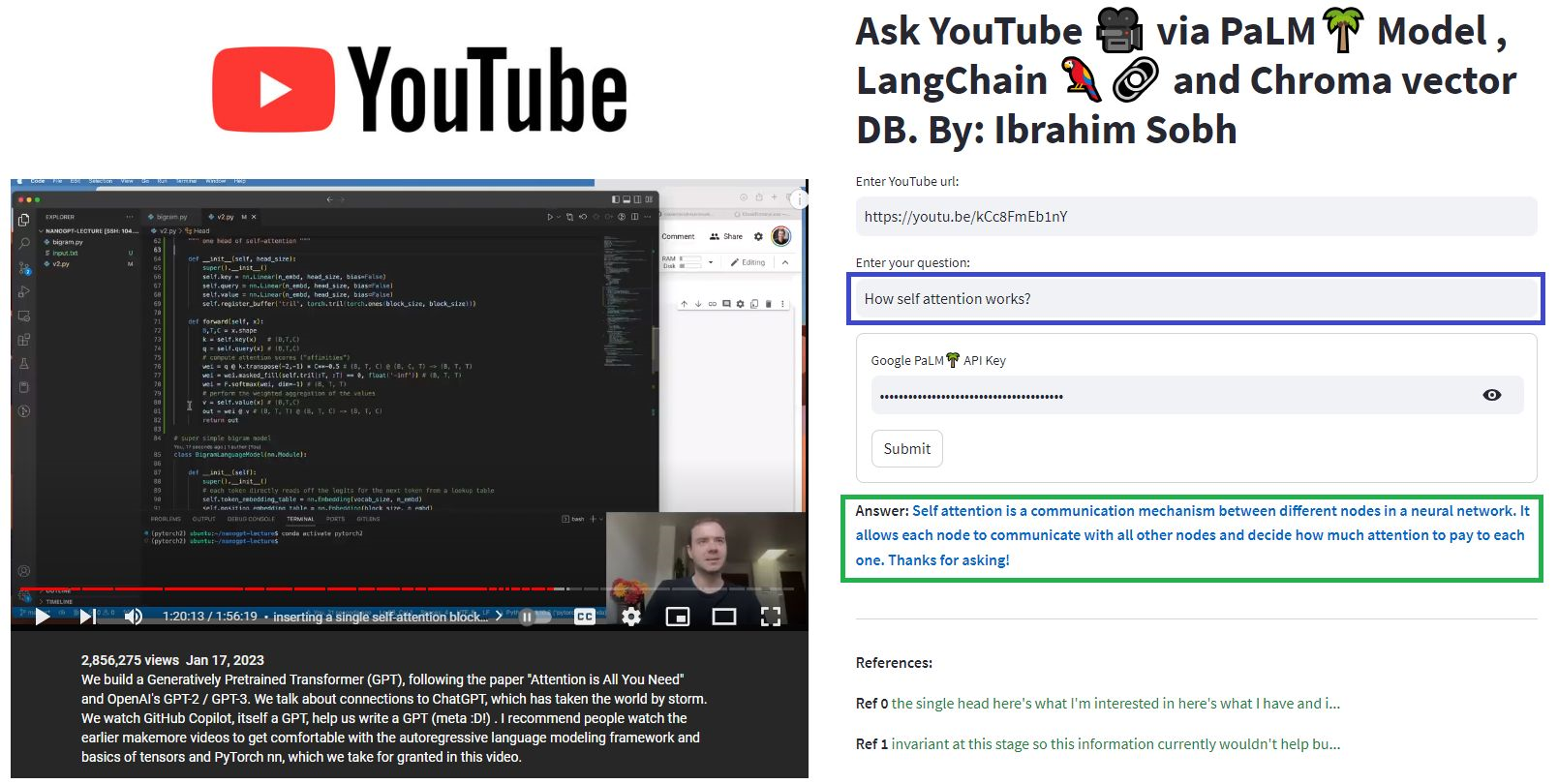
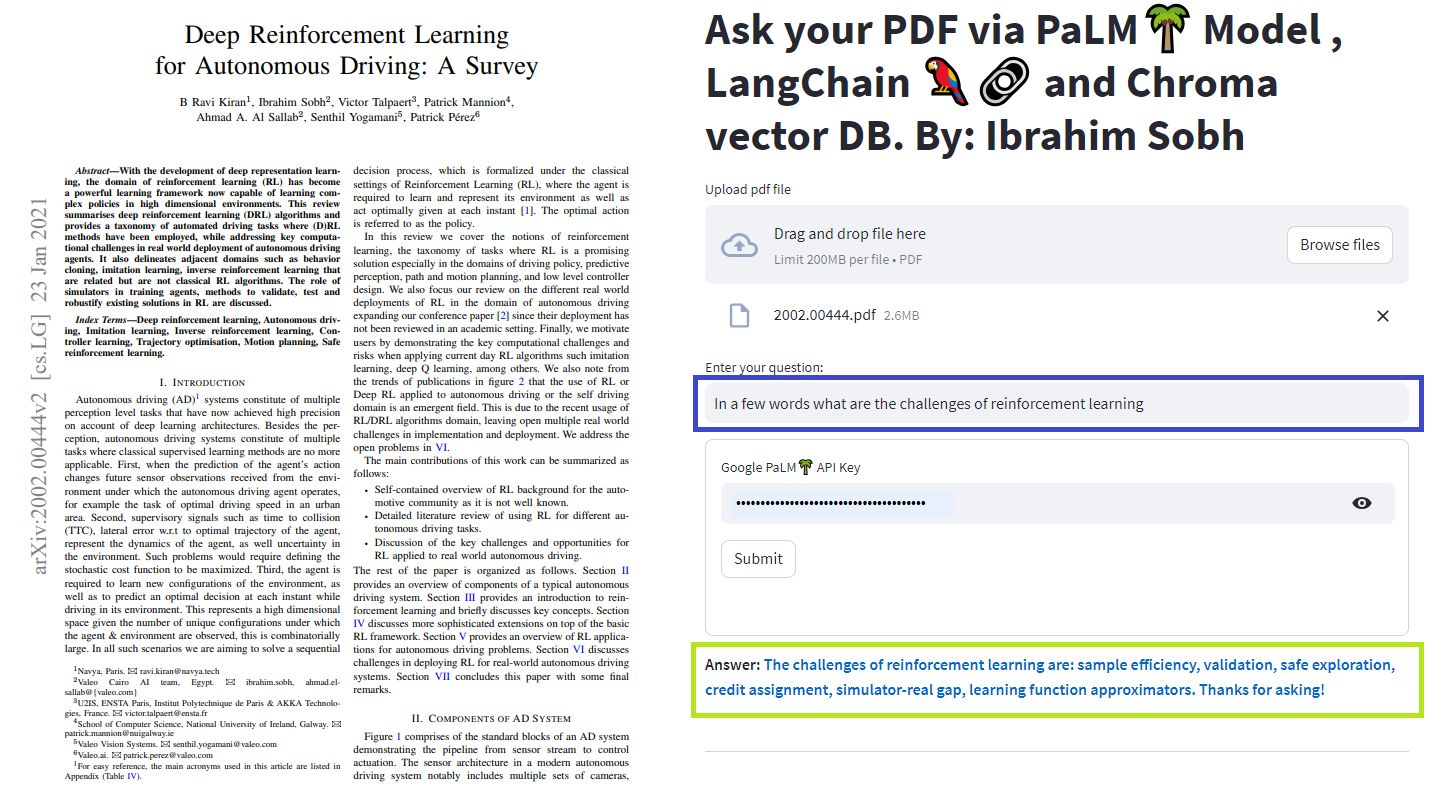
يمكنك تجربة المستندات والأسئلة الخاصة بك!
في هذه البرامج التعليمية البسيطة: كيفية الحصول على إجابات من المستندات النصية ، وملفات PDF ، وحتى مقاطع الفيديو على YouTube باستخدام قاعدة بيانات CHROMA Vector و Palm LLM بواسطة Google وسلسلة إجابة أسئلة من Langchain. أخيرًا ، استخدم SPERTELIT لتطوير واستضافة تطبيق الويب. ستحتاج إلى استخدام google_api_key الخاص بك (يمكنك الحصول على واحدة من Google). بنية نظام THS هي كما يلي:
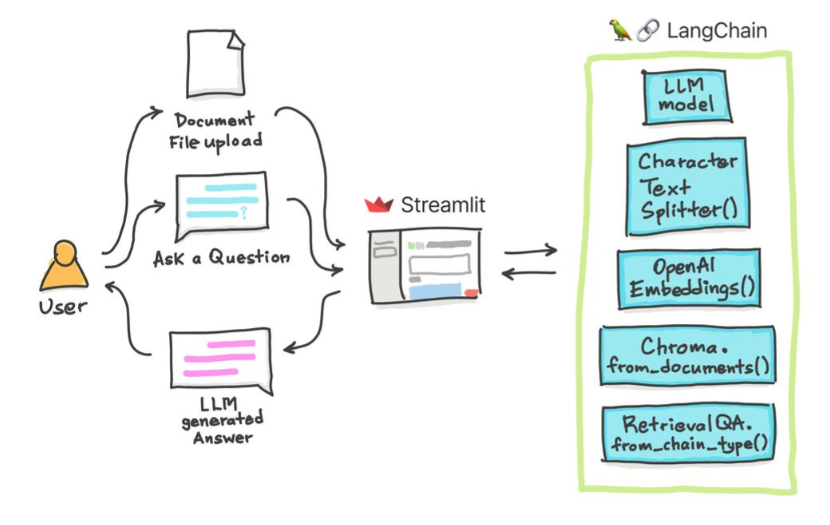
هناك فرق بين تقييم LLM مقابل تقييم نظام قائم على LLM. عادة بعد التدريب العام ، يتم تقييم LLMs على المعايير القياسية:
يمكن أن تقوم أنظمة LLMS بتلخيص النص ، وإلغاء الأسئلة ، والعثور على مشاعر النص ، ويمكنها القيام بالترجمة ، وأكثر من ذلك. بناءً على النظام ، يمكن أن يكون التقييم على النحو التالي:
على سبيل المثال في حالة نظام الإجابة على الأسئلة ، نحتاج إلى أزواج من الأسئلة والأجوبة في مجموعة التقييم الخاصة بنا. We can use human annotators to create gold-standard pairs of questions and answers manually. However, it is costly and time-consuming. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
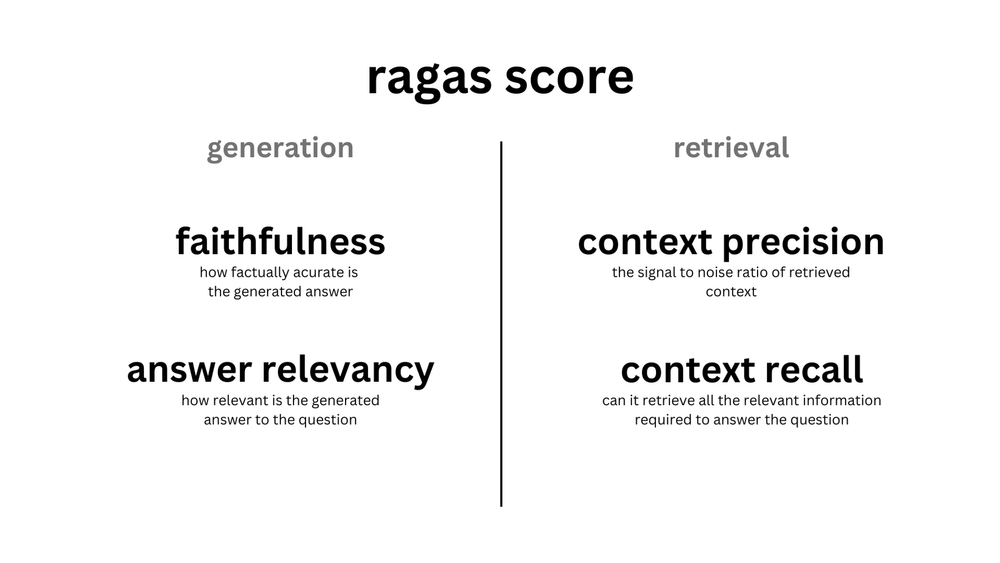
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
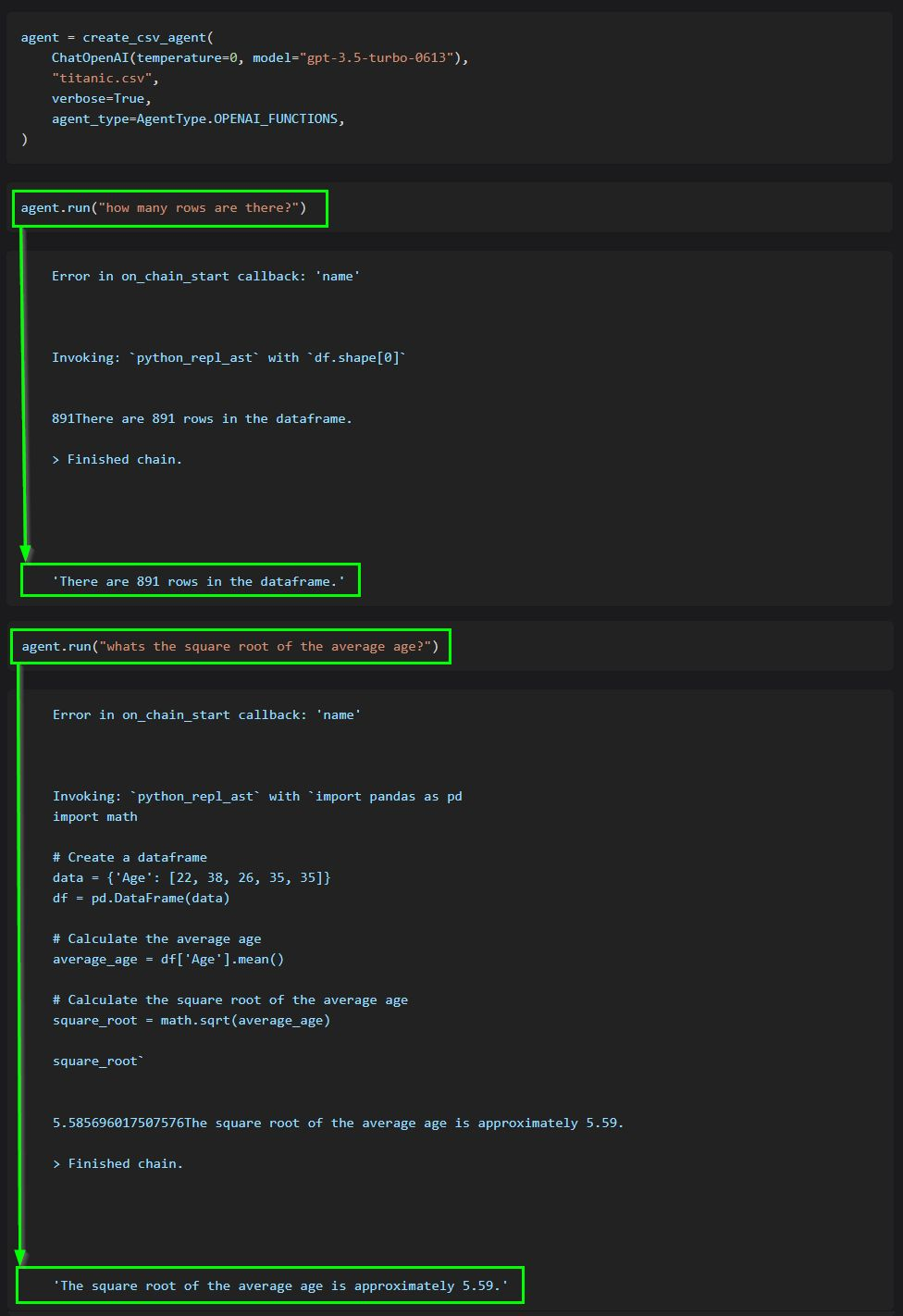
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
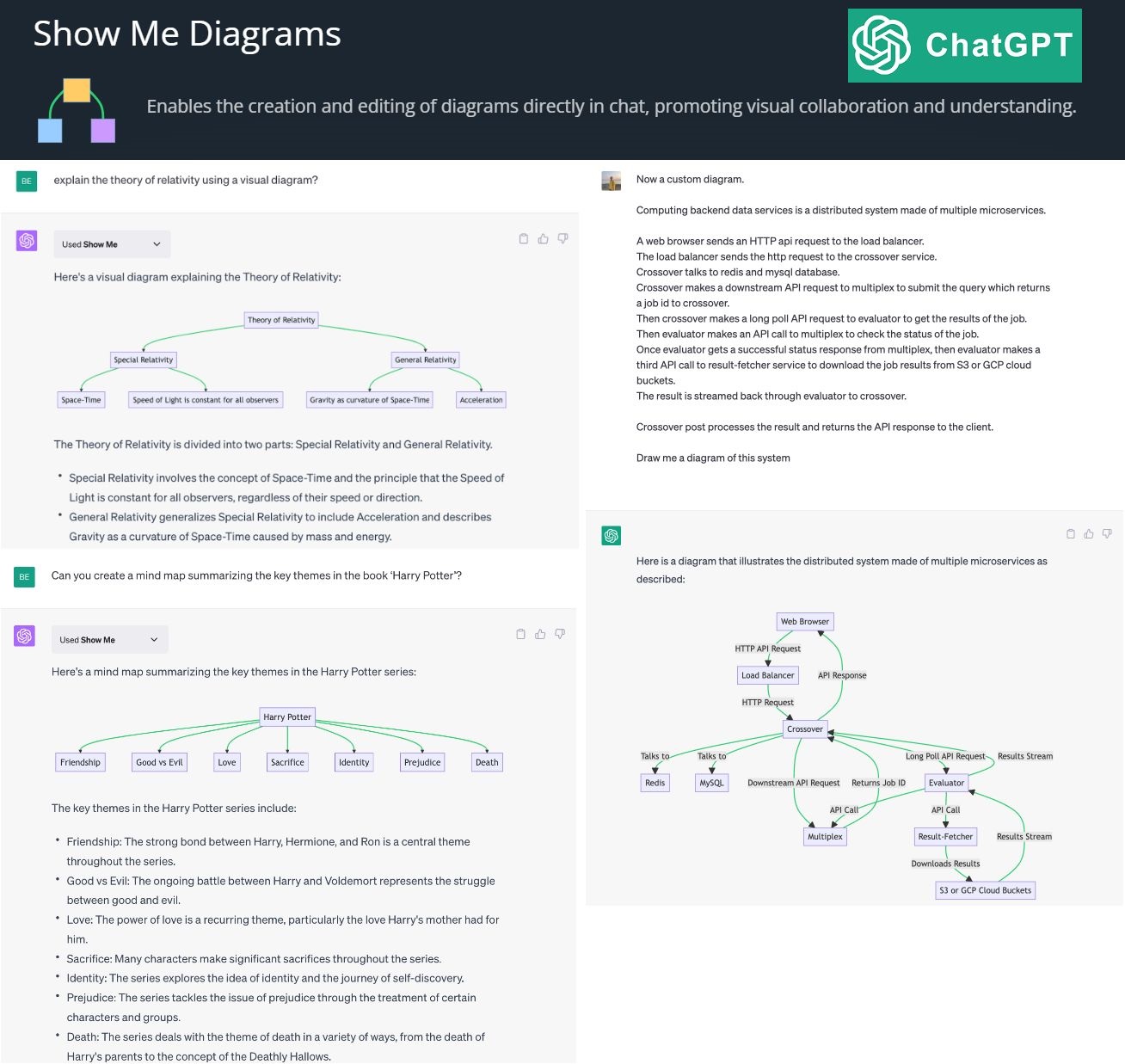
By creating and editing diagrams via Show Me Diagrams
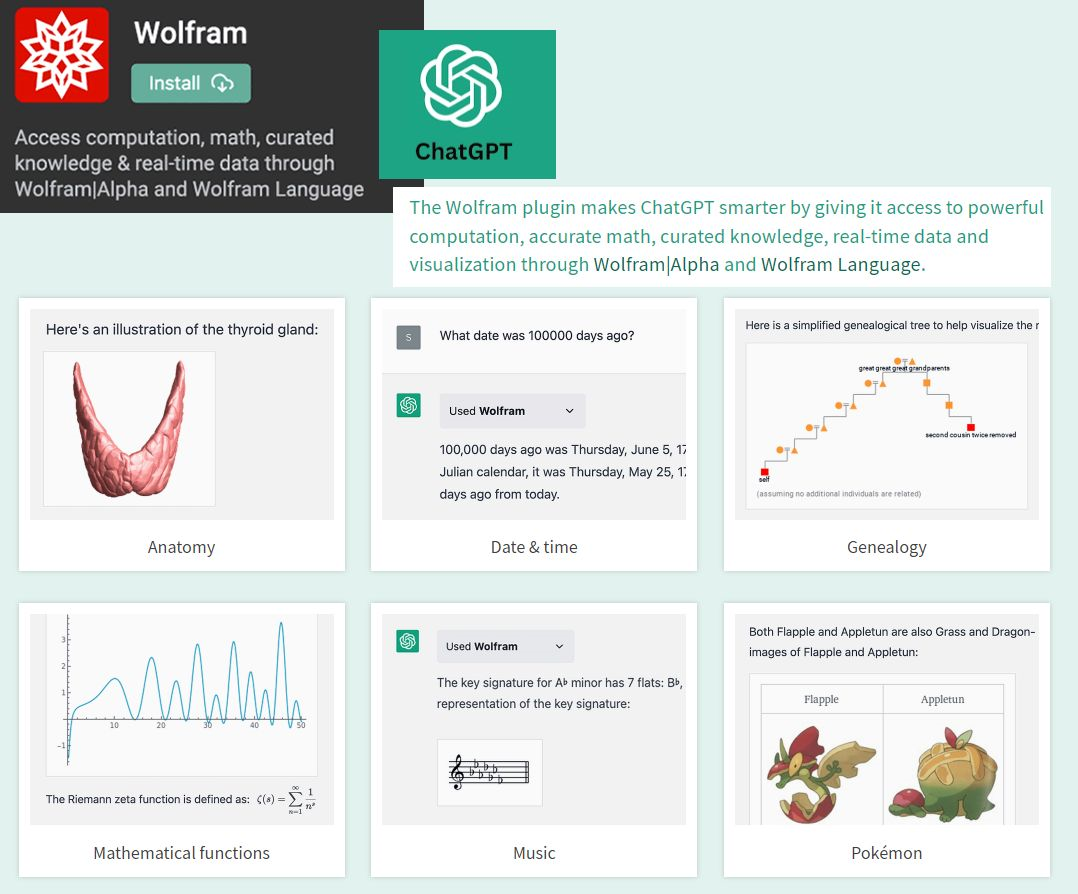
By accessing the power of mathematics provided by Wolfram
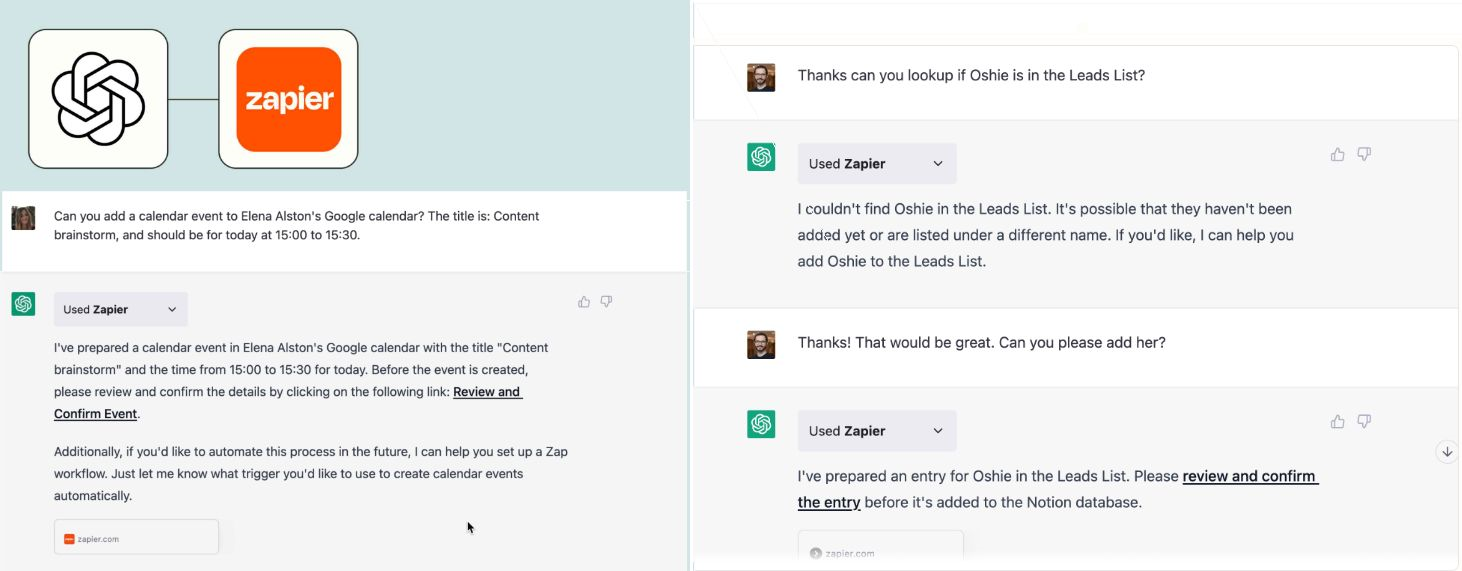
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
؟ AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


