llms
1.0.0
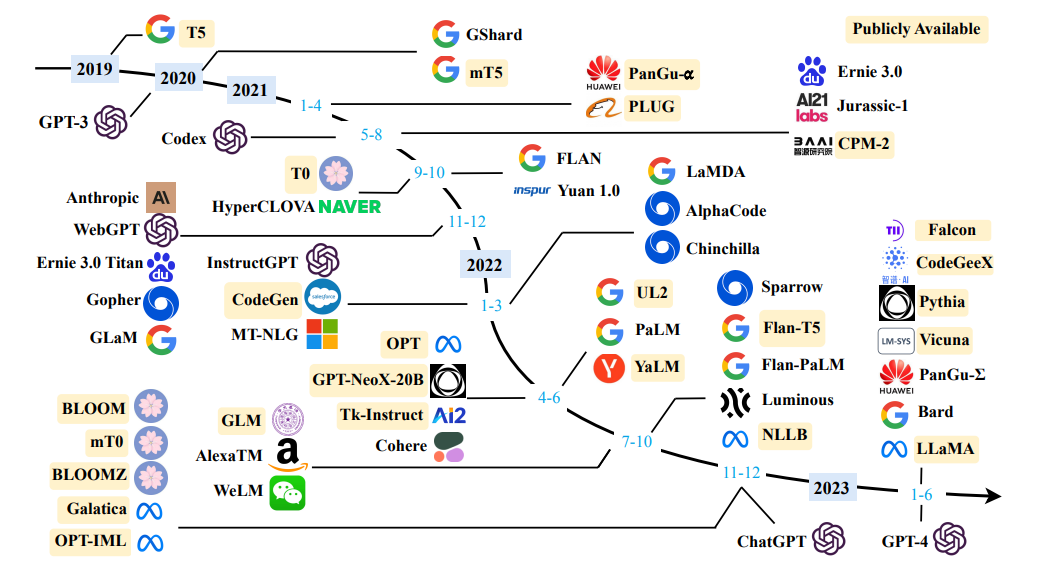 Fuente una encuesta de modelos de idiomas grandes
Fuente una encuesta de modelos de idiomas grandes
Definición simple: el modelado de idiomas es la tarea de predecir qué palabra viene a continuación.
"El perro está jugando en el ..."
El objetivo principal de los modelos de idiomas es asignar una probabilidad a una oración, para distinguir entre las oraciones más probables y menos probables.
Para el reconocimiento de voz, utilizamos no solo el modelo de acústica (la señal de habla), sino también un modelo de lenguaje. Del mismo modo, para el reconocimiento de caracteres ópticos (OCR), utilizamos un modelo de visión y un modelo de lenguaje. Los modelos de idiomas son muy importantes para tales sistemas de reconocimiento.
A veces, escucha o lee una oración que no está clara, pero utilizando su modelo de idioma, aún puede reconocerla con una alta precisión a pesar de la ruidosa entrada de visión/voz.
El modelo de idioma calcula cualquiera de:
El modelado de idiomas es un subcomponente de muchas tareas de PNL, especialmente aquellas que involucran a la generación de texto o estimando la probabilidad de texto.
La regla de la cadena:
$ P (el agua, es, así, claro) = p (el) × p (agua | el) × p (es | el agua) × p (entonces | el agua, es) × p (claro | el agua, es, así) $
¿Qué acaba de pasar? La regla de la cadena se aplica para calcular la probabilidad conjunta de palabras en una oración.
Usando una gran cantidad de texto (corpus como Wikipedia), recopilamos estadísticas sobre cuán frecuentemente son diferentes palabras, y las usamos para predecir la siguiente palabra. Por ejemplo, la probabilidad de que una palabra W viene después de estas tres palabras que los estudiantes abren las suyas se pueden estimar de la siguiente manera:
El ejemplo anterior es un modelo de 4 gramos. Y podemos obtener:
Podemos concluir que la palabra "libros" es más probable que los "autos" en este contexto.
Ignoramos el contexto anterior antes de que "los estudiantes abrieran su"
En consecuencia, el texto arbitrario se puede generar a partir de un modelo de lenguaje dado las palabras iniciales, mediante el muestreo de la distribución de probabilidad de salida de la siguiente palabra, y así sucesivamente.
Podemos entrenar un LM en cualquier tipo de texto, luego generar texto en ese estilo (Harry Potter, etc.).
Podemos extender a trigramas, 4 gramos, 5 gramos y N-gramos.
En general, este es un modelo de lenguaje insuficiente porque el lenguaje tiene dependencias de larga distancia. Sin embargo, en la práctica, estos 3,4 gramos funcionan bien para la mayoría de las aplicaciones.
Los modelos N-Gram de Google le pertenecen: Google Research ha estado utilizando modelos Word N-Gram para una variedad de proyectos de I + D. Google N-Gram procesó 1.024,908,267,229 palabras de texto en ejecución y publicó los recuentos para todas las 1,176,470,663 secuencias de cinco palabras que aparecen al menos 40 veces.
Los recuentos de texto del consorcio de datos de lingüística LDC son los siguientes:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
El siguiente es un ejemplo de los datos de 4 gramos en este corpus:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
Por ejemplo, la secuencia de las cuatro palabras "servir como indicación" se ha visto en el corpus 72 veces.
A veces no tenemos suficientes datos para estimar. El aumento de N empeoran los problemas de escasez. Por lo general, no podemos tener N más de 5.
NLM generalmente (pero no siempre) usa un RNN para aprender secuencias de palabras (oraciones, párrafos, ... etc.) y, por lo tanto, puede predecir la siguiente palabra.
Ventajas:
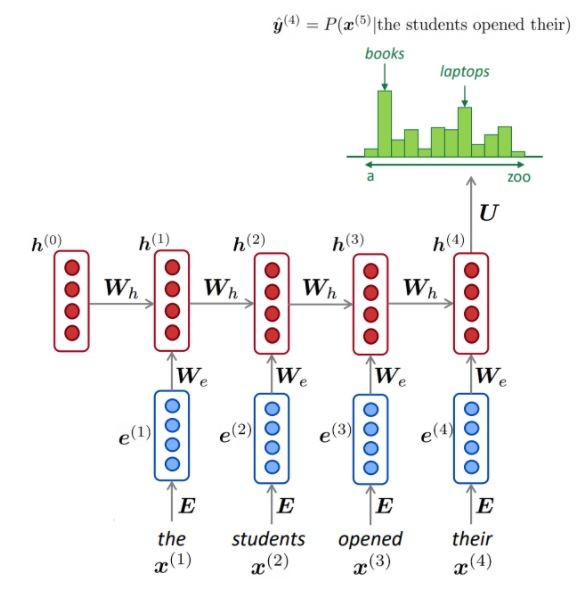
Como se muestra, en cada paso, tenemos una distribución de probabilidad de la siguiente palabra sobre el vocabulario.
Entrenamiento de un NLM:
Ejemplo de aprendizaje de secuencia larga:
Desventajas:
LM se puede utilizar para generar condiciones de texto en entrada (habla, imagen (OCR), texto, etc.) en diferentes aplicaciones, como: reconocimiento de voz, traducción automática, resumen, etc.
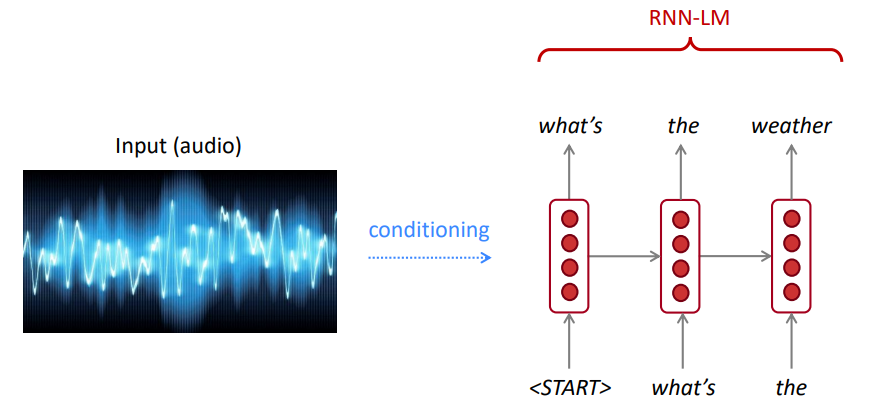
¿Nuestro modelo de idioma prefiere oraciones buenas (probablemente) a las malas?
La métrica de evaluación estándar para los modelos de lenguaje es la perplejidad de la perplejidad es la probabilidad inversa del conjunto de pruebas, normalizada por el número de palabras
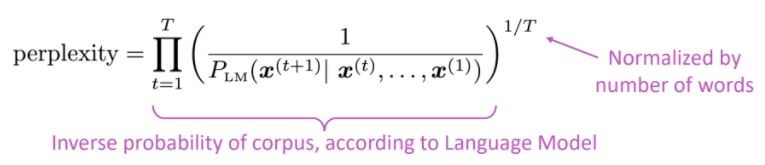
Menor perplejidad = mejor modelo
La perplejidad está relacionada con el factor de rama: en promedio, cuántas cosas podrían ocurrir a continuación.
En lugar de RNN, usemos la atención. Usemos grandes modelos previamente capacitados
¿Cuál es el problema? Uno de los mayores desafíos en el procesamiento del lenguaje natural (PNL) es la escasez de datos de capacitación para muchas tareas distintas. Sin embargo, los modernos modelos de PNL basados en el aprendizaje profundo mejoran cuando se entrenan en millones o miles de millones de ejemplos de capacitación anotada.
El entrenamiento previo es la solución: para ayudar a cerrar esta brecha, se han desarrollado una variedad de técnicas para capacitar a los modelos de representación del lenguaje de uso general utilizando la enorme cantidad de texto no anotado. El modelo previamente capacitado se puede ajustar en pequeños datos para diferentes tareas, como la respuesta a las preguntas y el análisis de sentimientos, lo que resulta en mejoras de precisión sustanciales en comparación con la capacitación en estos conjuntos de datos desde cero.
La arquitectura del transformador se propuso en la atención del papel es todo lo que necesita, utilizada para la Tarea de Traducción del Autor Neural (NMT), que consiste en:
Como se menciona en el documento:
" Proponemos una nueva arquitectura de red simple, el transformador, basado únicamente en mecanismos de atención, dispensando por completo la recurrencia y las convoluciones "
La idea principal de atención se puede resumir como se menciona en el artículo de OpenAI:
" ... Cada elemento de salida está conectado a cada elemento de entrada, y las ponderaciones entre ellos se calculan dinámicamente en función de las circunstancias , un proceso llamó la atención".
Basado en esta arquitectura (¡los transformadores de vainilla!), Los componentes de codificadores o decodificadores se pueden usar solos para habilitar modelos genéricos masivos previamente capacitados que se pueden ajustar para tareas aguas abajo, como la clasificación de texto, la traducción, el resumen, la respuesta de preguntas, etc. Por ejemplo:
Estos modelos, BERT y GPT, por ejemplo, pueden considerarse como el Imagenet de la PNL.
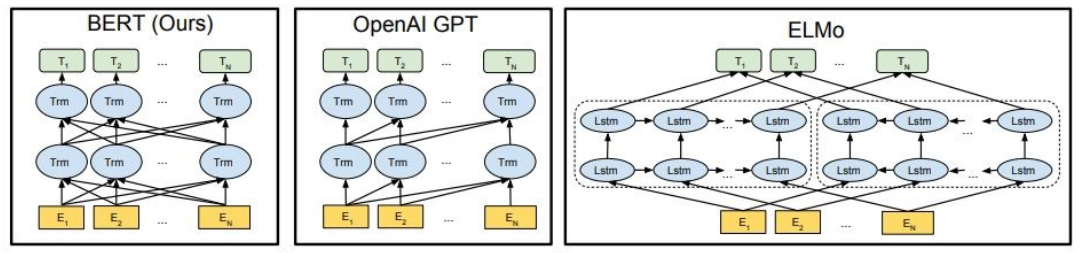
Como se muestra, Bert es profundamente bidireccional, OpenAi GPT es unidireccional, y Elmo es superficialmente bidireccional.
Las representaciones previamente capacitadas pueden ser:
Los modelos de lenguaje contextual pueden ser:
En esta parte, vamos a usar diferentes modelos de idiomas grandes
GPT2 (un sucesor de GPT) es un modelo previamente capacitado en el idioma inglés que utiliza un objetivo de modelado de idioma causal ( CLM ), capacitado simplemente para predecir la siguiente palabra en 40 GB de texto de Internet. Fue lanzado por primera vez en esta página. GPT2 muestra un amplio conjunto de capacidades, incluida la capacidad de generar muestras de texto sintéticas condicionales. En tareas de lenguaje, como respuesta a las preguntas, comprensión de lectura, resumen y traducción, GPT2 comienza a aprender estas tareas del texto sin procesar, utilizando datos de capacitación específicos de tareas. DistilPPT2 es una versión destilada de GPT2, está destinada a usarse para casos de uso similares con la mayor funcionalidad de ser más pequeño y más fácil de ejecutar que el modelo base.
Aquí cargamos un modelo GPT2 previamente capacitado, le pedimos al modelo GPT2 que continúe nuestro texto de entrada (aviso) y, finalmente, extraiga características incrustadas del modelo DistilPPT2.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Bert es un modelo de transformadores previamente entrenado en un gran corpus de datos ingleses de una manera auto-supervisada. Esto significa que fue priorizado solo en los textos sin procesar, sin humanos que los etiqueten de ninguna manera con un proceso automático para generar entradas y etiquetas de esos textos. Más precisamente, estaba provocado con dos objetivos:
En este ejemplo, vamos a utilizar un modelo Bert previamente entrenado para la tarea de análisis de sentimientos.
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4All es un ecosistema para entrenar y implementar modelos de lenguaje grandes y personalizados que se ejecutan localmente en las CPU de grado de consumo.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
Pruebe los siguientes modelos:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM es la serie insignia de TII de modelos de idiomas grandes, construidos desde cero utilizando una tubería de datos personalizada y capacitación distribuida. Los modelos Falcon-7B/40B son de última generación para su tamaño, superando a la mayoría de los otros modelos en puntos de referencia de PNL. De origen abierto Varios artefactos:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
LLAMA2 es una familia de modelos de idiomas grandes de acceso abierto de última generación lanzados por Meta Today, y estamos entusiasmados de apoyar completamente el lanzamiento con integración integral en la cara de abrazo. Llama 2 se lanzará con una licencia comunitaria muy permisiva y está disponible para uso comercial. El código, los modelos previos a la aparición y los modelos ajustados se están lanzando hoy
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
Codet5+ es una nueva familia de modelos de lenguaje de código abierto con una arquitectura de codificador codificador que puede operar de manera flexible en diferentes modos (es decir, solo codificador, solo decodificador y decodificador de codificadores) para admitir una amplia gama de tareas de comprensión y generación de código.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
Para obtener más modelos, consulte Codetf desde Salesforce, una biblioteca basada en transformador de Python para modelos de idiomas grandes (LLMS) e inteligencia de código, proporcionando una interfaz perfecta para capacitación e inferencia en tareas de inteligencia de código como resumen de código, traducción, generación de códigos, etc.
? ️ Chatear con modelos de lenguaje grande abierto
✅ La búsqueda del haz siempre encontrará una secuencia de salida con mayor probabilidad que la búsqueda codiciosa, pero no se garantiza que encuentre el resultado más probable.
En Transformers, simplemente establecemos el parámetro num_return_sequences en el número de vigas de puntuación más altas que deben devolverse. ¡Asegúrese de que num_return_sequences <= num_beams!
✅ La búsqueda del haz puede funcionar muy bien en las tareas donde la longitud de la generación deseada es más o menos predecible como en la traducción o resumen automático. ? Pero este no es el caso de la generación abierta, donde la longitud de salida deseada puede variar mucho, por ejemplo, diálogo y generación de historias. La búsqueda de haz sufre mucho de generación repetitiva. Como humanos, queremos que el texto generado nos sorprenda y no sea aburrido/predecible (la búsqueda de haz es menos sorprendente)
En Transformers, establecemos do_sample = true y desactivamos el muestreo Top-K (más sobre esto más tarde) a través de top_k = 0.
???-? ???????? GPT2 adoptó este esquema de muestreo.
???-? ????????: En lugar de muestrear solo a las palabras K más probables, en el muestreo TOP-P elige del conjunto de palabras más pequeño posible cuya probabilidad acumulativa excede la probabilidad p. La masa de probabilidad se redistribuye entre este conjunto de palabras. Habiendo establecido P = 0.92, el muestreo TOP-P elige el número mínimo de palabras que exceden juntas el 92% de la masa de probabilidad.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ Si bien Top-P parece más elegante que Top-K, ambos métodos funcionan bien en la práctica. Top-P también se puede usar en combinación con Top-K, lo que puede evitar palabras de muy bajo rango al tiempo que permite una selección dinámica.
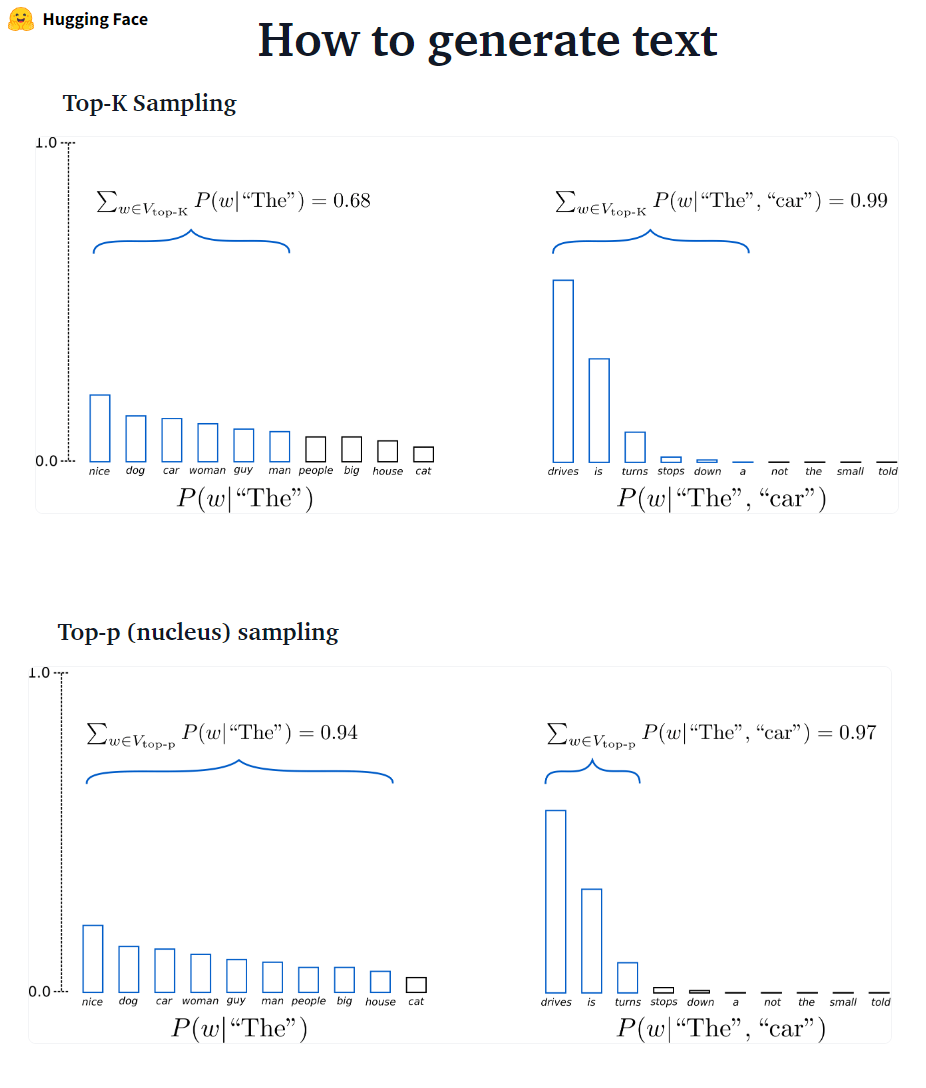
✅ Como métodos de decodificación ad-hoc, el muestreo Top-P y Top-K parece producir un texto más fluido que la búsqueda tradicional de haz, y la búsqueda de haz en la generación de idiomas abiertos.
La ingeniería rápida es el proceso de diseño de las indicaciones (entrada de texto) para que un modelo de idioma genere la salida requerida. La ingeniería rápida implica seleccionar palabras clave apropiadas, proporcionar contexto, ser claro y específico de una manera que dirija el comportamiento del modelo de idioma que logre las respuestas deseadas. A través de ingeniería inmediata, podemos controlar el tono, el estilo, la longitud, etc. de un modelo sin ajustar.
El aprendizaje de disparo cero implica pedirle al modelo que haga predicciones sin proporcionar ejemplos (disparo cero), por ejemplo:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
Cuando cero-shot no es lo suficientemente bueno, se recomienda ayudar al modelo proporcionando ejemplos en el aviso que conduce a pocas solicitudes de disparo.
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
Además de la ingeniería rápida , podemos considerar más opciones:
Para obtener más información rápida de ingeniería, consulte la guía de ingeniería rápida que contiene los últimos documentos, guías de aprendizaje, conferencias, referencias y herramientas.
El ajuste de LLMS en conjuntos de datos aguas abajo da como resultado grandes ganancias de rendimiento en comparación con el uso de los LLM previos a la caja (inferencia de disparo cero, por ejemplo). Sin embargo, a medida que los modelos se vuelven cada vez más grandes, el ajuste completo completo se vuelve inviable para entrenar en el hardware del consumidor. Además, almacenar e implementar modelos ajustados de forma independiente para cada tarea aguas abajo se vuelve muy costoso, porque los modelos ajustados son del mismo tamaño que el modelo original previamente. ¡Los enfoques de ajuste fino (PEFT) de parámetros están destinados a abordar ambos problemas! Los enfoques de PEFT le permiten obtener el rendimiento comparable al ajuste completo completo, mientras que solo tiene un pequeño número de parámetros entrenables. Por ejemplo:
Ajuste rápido: un mecanismo simple pero efectivo para aprender "indicaciones suaves" que condicionen modelos de lenguaje congelado para realizar tareas específicas aguas abajo. Al igual que las indicaciones de texto diseñadas, las indicaciones suaves se concatenan al texto de entrada. Pero en lugar de seleccionar de los elementos de vocabulario existentes, los "tokens" de la solicitud suave son los vectores aprendizables. Esto significa que un aviso suave puede optimizarse de extremo a extremo a través de un conjunto de datos de entrenamiento, como se muestra a continuación: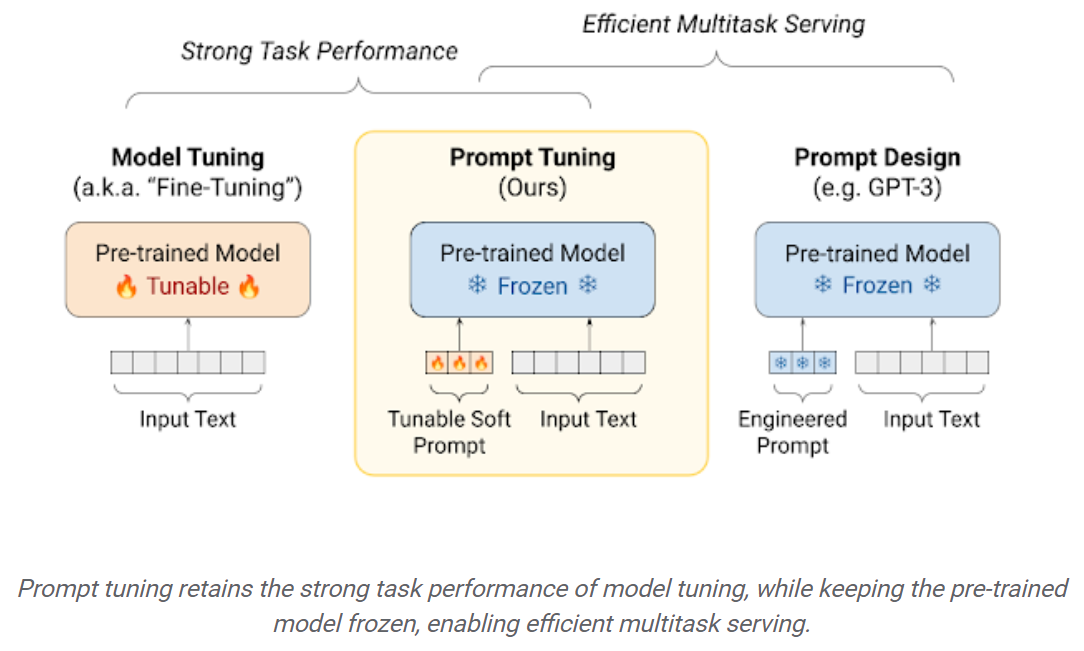
La adaptación de bajo rango de Lora de LLM es un método que congela los pesos del modelo previamente e inyecta matrices de descomposición de rango entrenable en cada capa de la arquitectura del transformador. Reduciendo en gran medida el número de parámetros capacitables para las tareas aguas abajo. La siguiente figura, de este video, explica la idea principal: 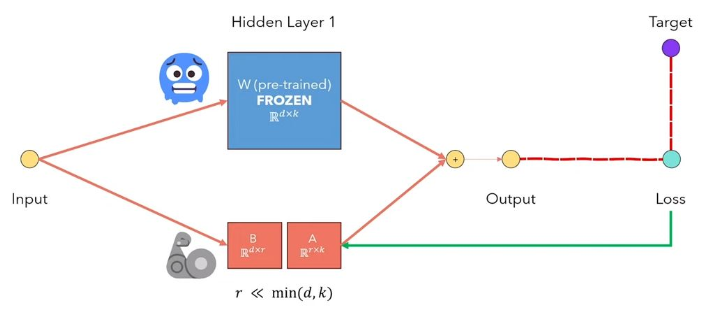
Los modelos de idiomas grandes suelen ser de propósito general, menos efectivos para tareas específicas del dominio. Sin embargo, se pueden ajustar en algunas tareas, como el análisis de sentimientos. Para Taks más complejos que requieren un conocimiento externo, es posible construir un sistema basado en modelos de idiomas que acceda a fuentes de conocimiento externas para completar las tareas requeridas. Esto permite una mayor precisión objetiva y ayuda a mitigar el problema de la "alucinación". Como se muestra en el Figuer a continuación:
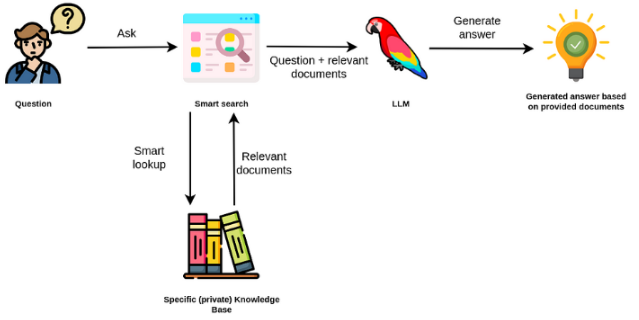
En este caso, en lugar de usar LLM para acceder a su conocimiento interno, utilizamos la LLM como interfaz de lenguaje natural para nuestro conocimiento externo. El primer paso es convertir los documentos y cualquier consulta de usuario en un formato compatible para realizar una búsqueda de relevancia (convertir texto en vectores o incrustaciones). El mensaje del usuario original se adjunta con documentos relevantes / similares dentro de la fuente de conocimiento externo (como un contexto). Luego, el modelo responde las preguntas basadas en el contexto externo proporcionado.
Los modelos de idiomas grandes (LLM) están surgiendo como una tecnología transformadora. Sin embargo, el uso de estos LLM aislados a menudo es insuficiente para crear aplicaciones verdaderamente poderosas. Langchain tiene como objetivo ayudar en el desarrollo de tales aplicaciones.
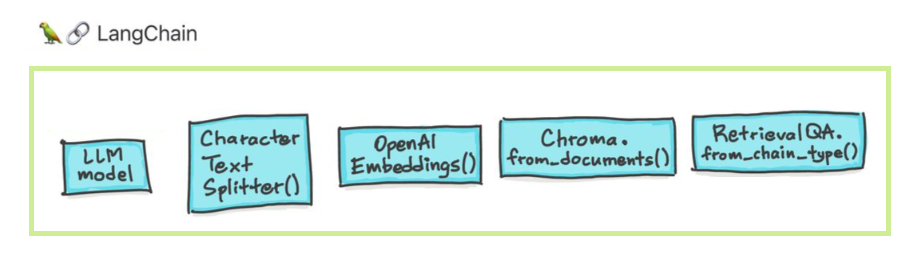
Hay seis áreas principales con las que Langchain está diseñada para ayudar. Estos son, en un orden creciente de complejidad:
Esto incluye administración inmediata, optimización rápida, una interfaz genérica para todos los LLM y utilidades comunes para trabajar con LLM. Los modelos de LLMS y Chat son sutiles, pero más importantes, diferentes. Los LLM en Langchain se refieren a los modelos de finalización de texto puro. Las API que envuelven toman un indicador de cadena como entrada y salida de una completación de cadena. El GPT-3 de Openai se implementa como un LLM. Los modelos de chat a menudo están respaldados por LLM, pero se ajustan específicamente para tener conversaciones.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
También puede acceder a la información específica del proveedor que se devuelve. Esta información no está estandarizada entre los proveedores.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
La solicitud de los modelos de chat es una lista de mensajes de chat. Cada mensaje de chat está asociado con el contenido y un parámetro adicional llamado rol. Por ejemplo, en la API de finalización de chat de Operai, un mensaje de chat puede asociarse con un asistente de IA, un papel humano o un sistema.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
Las cadenas van más allá de una sola llamada LLM e involucran secuencias de llamadas (ya sea a un LLM o una utilidad diferente). Langchain proporciona una interfaz estándar para cadenas, muchas integraciones con otras herramientas y cadenas de extremo a extremo para aplicaciones comunes. La cadena muy genéricamente se puede definir como una secuencia de llamadas a los componentes, que pueden incluir otras cadenas.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
La generación aumentada de datos implica tipos específicos de cadenas que primero interactúan con una fuente de datos externa para obtener datos para su uso en el paso de generación. Los ejemplos incluyen preguntas/respuesta sobre fuentes de datos específicas.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
Búsqueda de similitud
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
Los agentes involucran a una LLM tomando decisiones sobre qué acciones tomar, tomando esa acción, viendo una observación y repitiendo eso hasta que se haga. Langchain proporciona una interfaz estándar para agentes, una selección de agentes para elegir y ejemplos de agentes de extremo a extremo. La idea central de los agentes es usar un LLM para elegir una secuencia de acciones a tomar. En las cadenas, una secuencia de acciones está codificada (en código). En los agentes, se utiliza un modelo de idioma como motor de razonamiento para determinar qué acciones tomar y en qué orden.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
La memoria se refiere al estado persistente entre las llamadas de una cadena/agente. Langchain proporciona una interfaz estándar para la memoria, una colección de implementaciones de memoria y ejemplos de cadenas/agentes que usan la memoria.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
Podemos usar diferentes métodos para chatear con nuestros documentos. No es necesario ajustar todo el LLM, en su lugar, podemos proporcionar el contexto correcto junto con nuestra pregunta al modelo previamente capacitado y simplemente obtener las respuestas basadas en nuestros documentos proporcionados.
Aquí, ¿chateamos con este bonito artículo titulado Transformers sin dolor? Hacer preguntas relacionadas con transformadores, atención, codificador de codificadores, etc. mientras utiliza el poderoso modelo de palma de Google y el marco Langchain para desarrollar aplicaciones alimentadas por modelos de idiomas.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
Pregunta : ? '¿De qué tratan estos documentos?'
Respuesta : ? "Los documentos son sobre transformadores, que son un tipo de red neuronal que se ha utilizado con éxito en el procesamiento del lenguaje natural y las tareas de visión por computadora".
Pregunta : ? '¿Cuál es la idea principal de los transformadores?'
Respuesta : ? "La idea principal de los transformadores es usar mecanismos de atención para modelar dependencias de largo alcance en secuencias".
Pregunta : ? '¿Qué es la codificación posicional?'
Respuesta : ? "La codificación posicional es una técnica utilizada para representar el orden de las palabras en una secuencia".
Pregunta : ? '¿Cómo se utilizan los vectores de consulta, clave y valor?'
Respuesta : ? 'El vector de consulta se usa para calcular una suma ponderada de los valores a través de las claves. Específicamente: P Producto de P Dot todas las teclas, luego Softmax para obtener pesos y finalmente usa estos pesos para calcular una suma ponderada de los valores.
Pregunta : ? '¿Cómo comenzar a usar transformadores?'
Respuesta : ? 'Para comenzar a usar Transformers, puede usar la biblioteca Huggingface Transformers. Esta biblioteca proporciona miles de modelos previos a la realización para realizar tareas en textos como clasificación, extracción de información, respuesta a preguntas, resumen, traducción, generación de texto, etc. en más de 100 idiomas.
¡Puede probar sus propios documentos y preguntas!
En estos tutoriales simples: cómo obtener respuestas de documentos de texto , archivos PDF e incluso videos de YouTube utilizando la base de datos de Chroma Vector, Palm LLM de Google y una cadena de contestadores de preguntas de Langchain. Finalmente, use Streamlit para desarrollar y alojar la aplicación web. Deberá usar su Google_api_Key (puede obtener uno de Google). La arquitectura del sistema es la siguiente:
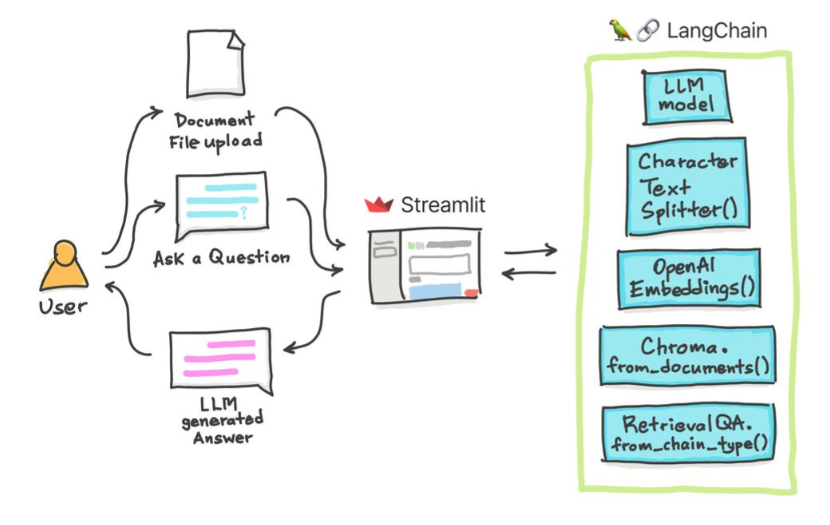
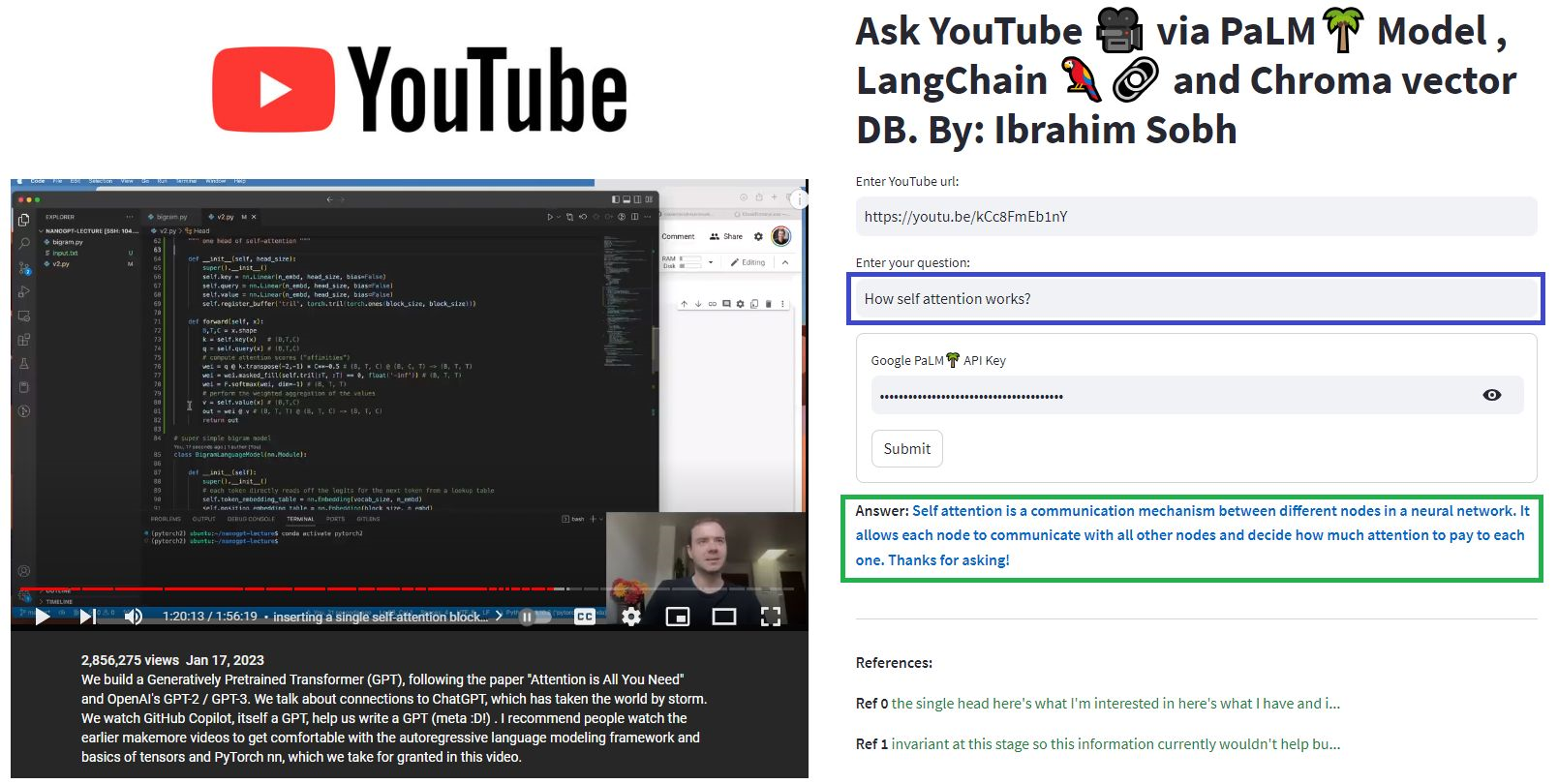
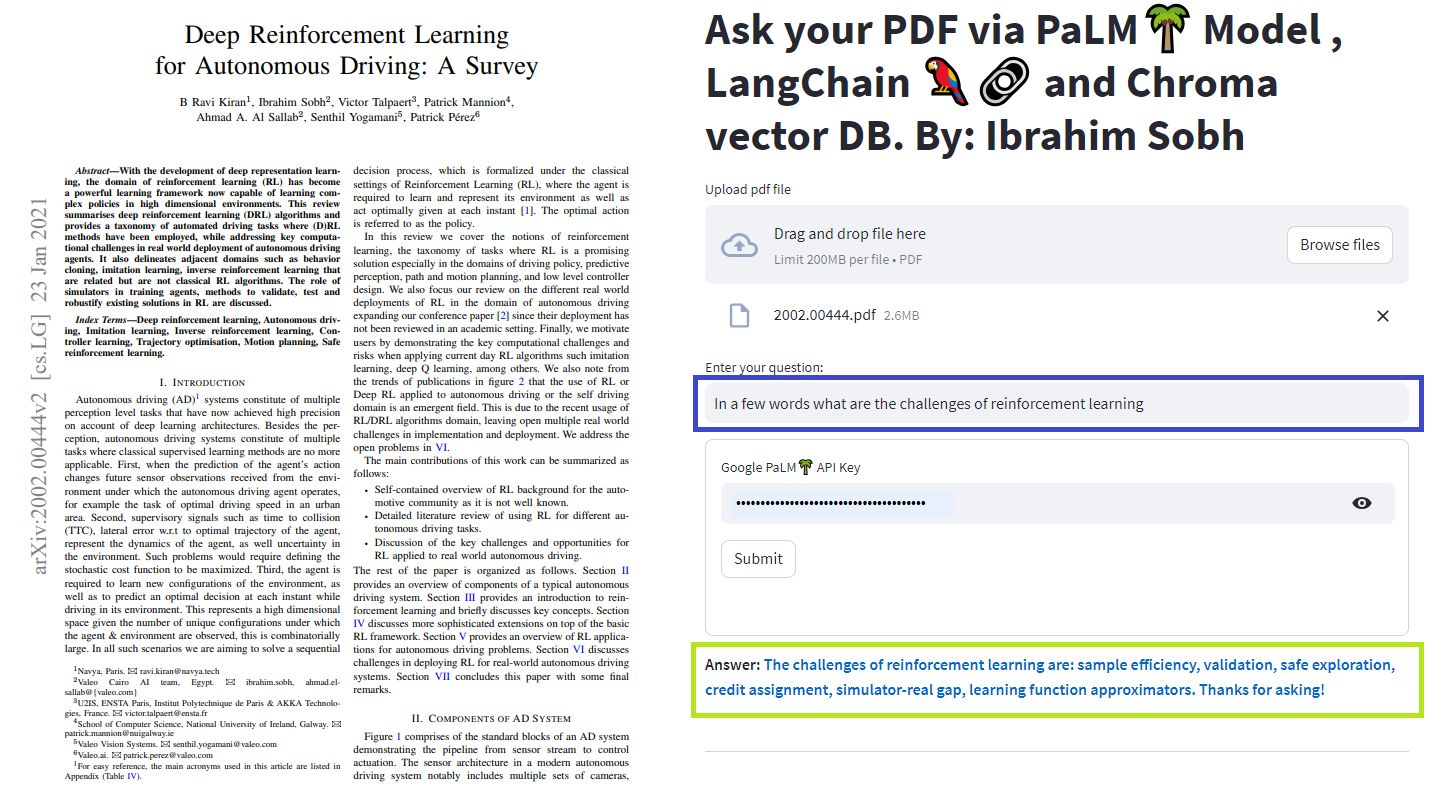
Hay una diferencia entre evaluar un LLM versus evaluar un sistema basado en LLM. Por lo general, después de la capacitación genérica , los LLM se evalúan en puntos de referencia estándar:
Los sistemas LLMS pueden resumir el texto, hacer preguntas sobre la pregunta, encontrar el sentimiento de un texto, puede hacer traducción y más. Según el sistema, la evaluación puede ser la siguiente:
Por ejemplo, en el caso del sistema de respuesta de preguntas , necesitamos pares de preguntas y respuestas en nuestro conjunto de evaluación. Podemos usar anotadores humanos para crear pares de preguntas y respuestas estándar de oro manualmente. Sin embargo, es costoso y requiere mucho tiempo. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
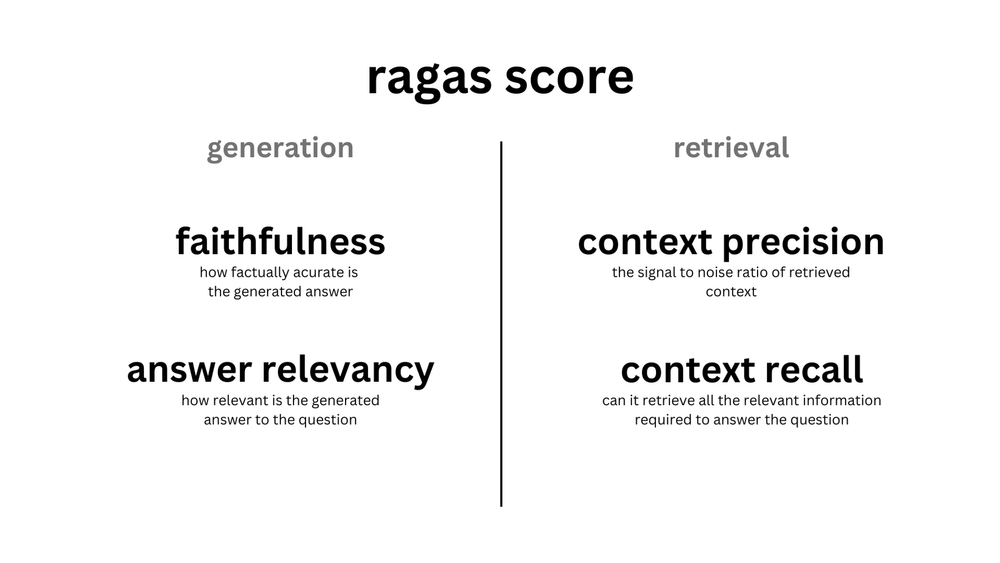
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
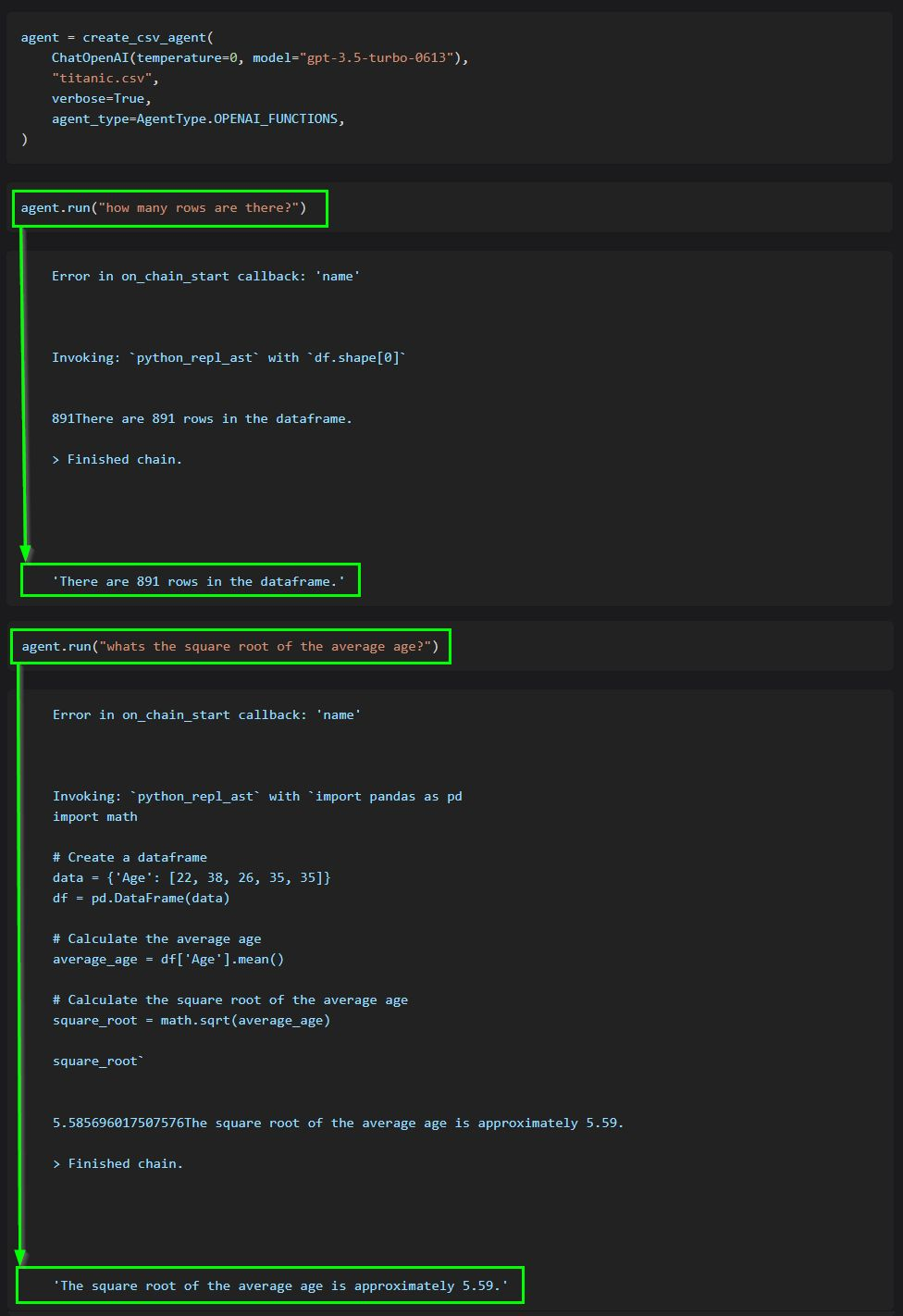
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
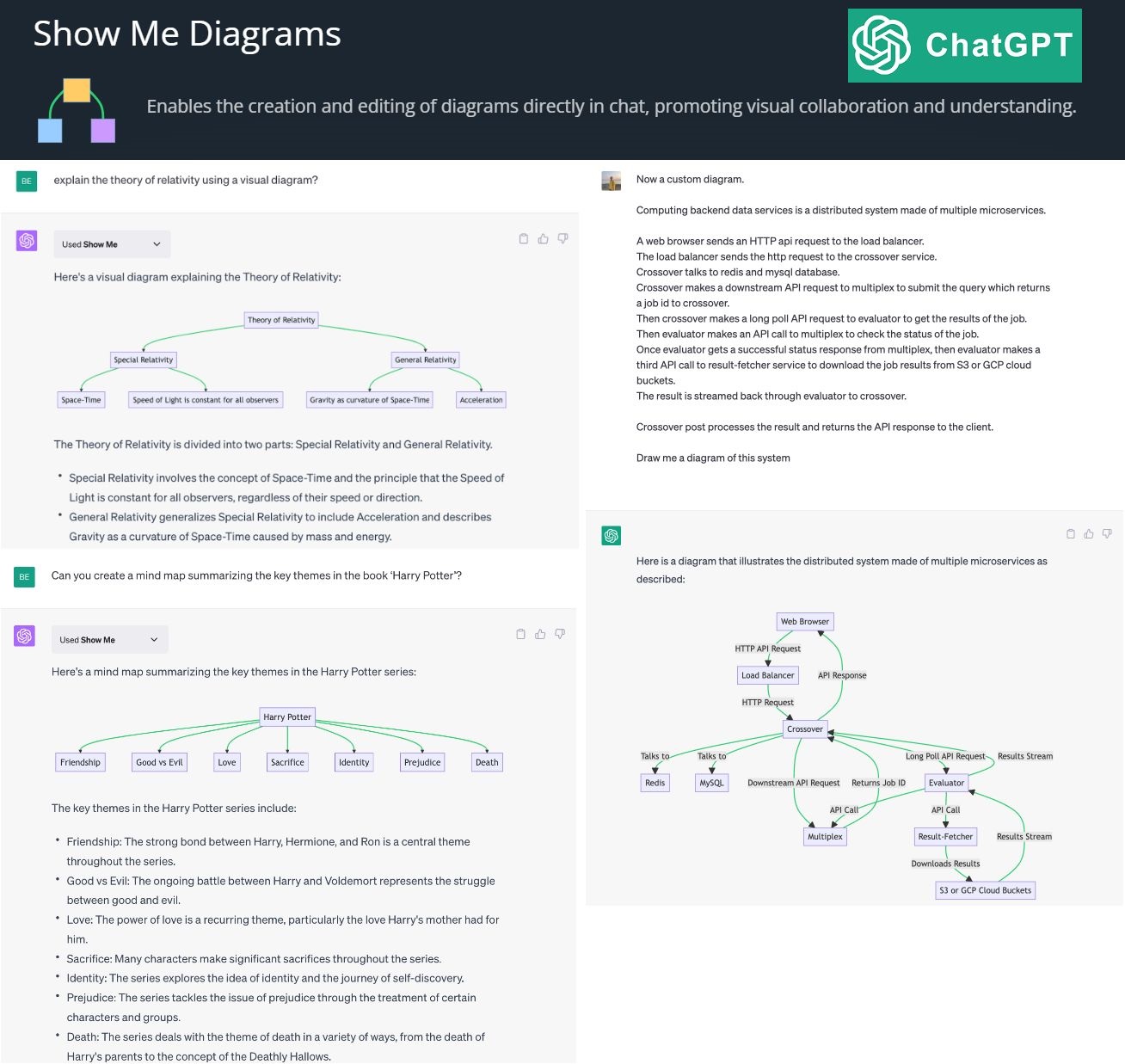
By creating and editing diagrams via Show Me Diagrams
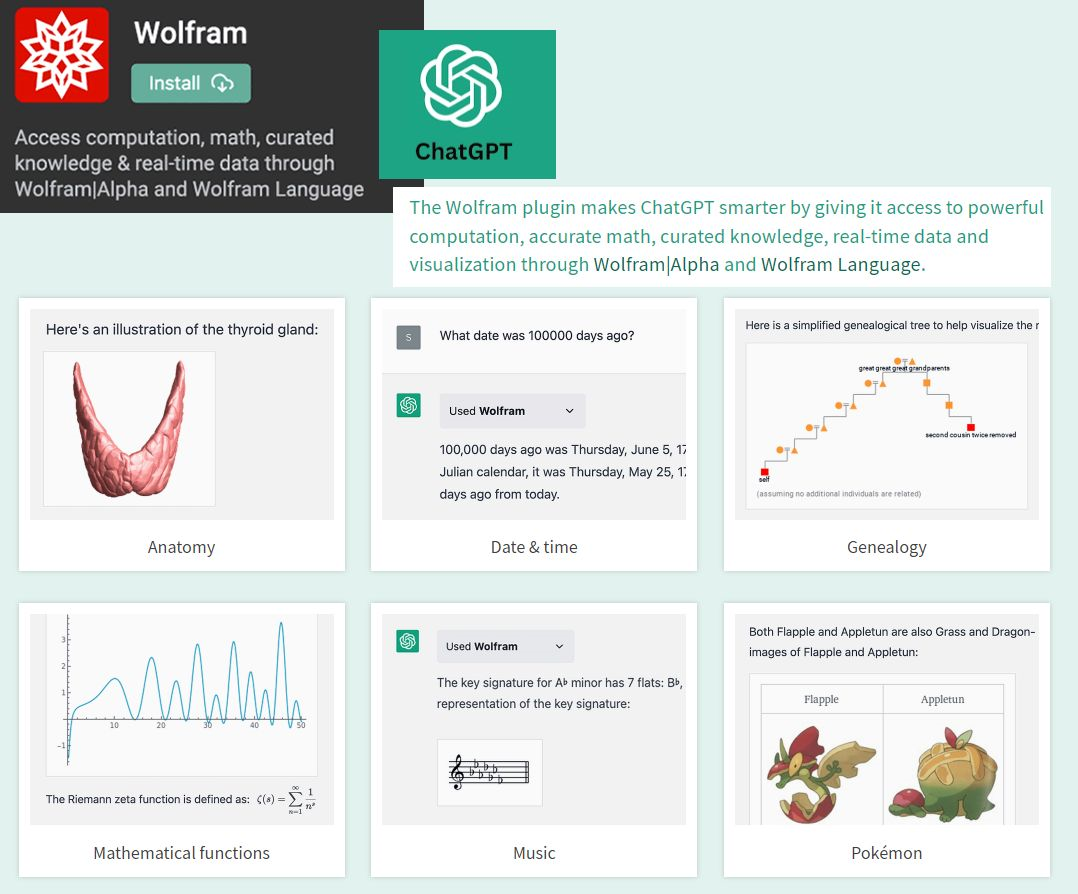
By accessing the power of mathematics provided by Wolfram
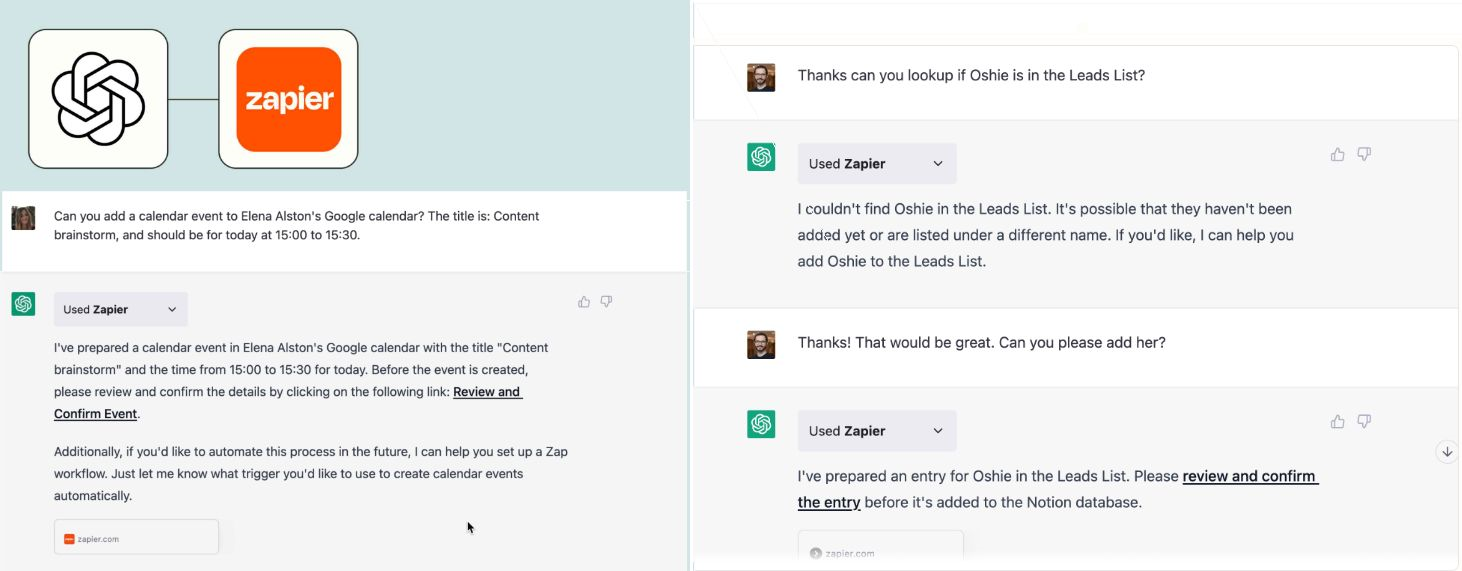
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


