llms
1.0.0
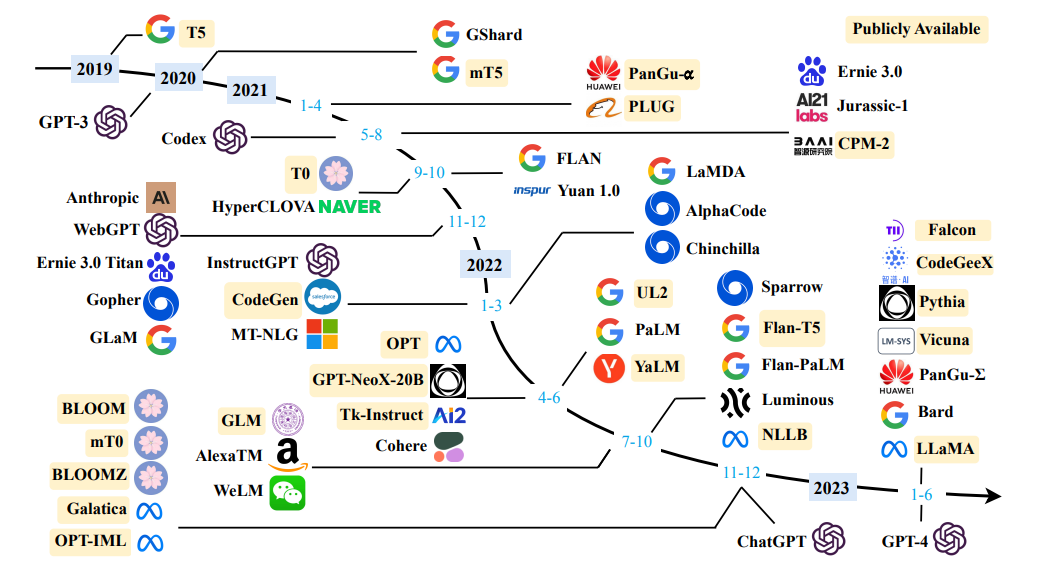 Поиск обследования моделей крупных языков
Поиск обследования моделей крупных языков
Простое определение: Языковое моделирование - это задача прогнозирования того, какое слово придет дальше.
"Собака играет в ..."
Основная цель языковых моделей состоит в том, чтобы назначить вероятность предложения, чтобы различить более вероятные и менее вероятные предложения.
Для распознавания речи мы используем не только модель акустики (речевой сигнал), но и языковую модель. Точно так же для распознавания оптического символа (OCR) мы используем как модель зрения, так и языковую модель. Языковые модели очень важны для таких систем распознавания.
Иногда вы слышите или читаете предложение, которое неясно, но, используя свою языковую модель, вы все равно можете распознать его с высокой точностью, несмотря на шумный вход зрения/речи.
Языковая модель вычисляет любое из:
Языковое моделирование является подкомпонентом многих задач NLP, особенно тех, которые включают генерирование текста или оценку вероятности текста.
Правило цепи:
$ P (The, Water, IS, So, ясная) = P (The) × p (вода |) × p (is | the, вода) × p (так |, вода, есть) × p (clear | the, вода, так) $
Что только что случилось? Правило цепи применяется для вычисления совместной вероятности слов в предложении.
Используя большое количество текста (такого корпуса, как Википедия), мы собираем статистику о том, как часто разные слова, и используем их для прогнозирования следующего слова. Например, вероятность того, что слово w появится после того, как эти три слова, которые студенты открыли, можно оценить следующим образом:
Приведенный выше пример-модель 4 грамма. И мы можем получить:
Мы можем сделать вывод, что в этом контексте слово «книги» более вероятно, чем «автомобили».
Мы проигнорировали предыдущий контекст, прежде чем «студенты открыли свои»
Соответственно, произвольный текст может быть сгенерирован из языковой модели с учетом исходного слова (ов), отбора проб из распределения вероятности вывода следующего слова и так далее.
Мы можем обучить LM на любой текст, а затем генерировать текст в этом стиле (Гарри Поттер и т. Д.).
Мы можем распространяться на триграммы, 4 грамма, 5 граммов и N-граммы.
В целом, это недостаточная модель языка, потому что язык имеет зависимости на расстоянии. Однако на практике эти 3,4 грамма работают хорошо для большинства приложений.
Модели Google N-Gram принадлежат вам: Google Research использует модели Word N-Gram для различных проектов НИОКР. Google N-грамм обработал 1 024 908 267 229 слов запуска текста и опубликовал счет для всех 1176 470 663 последовательностей из пяти слов, которые появляются не менее 40 раз.
Подсчет текста из консорциума лингвистических данных LDC заключаются в следующем:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
Ниже приведен пример 4-граммовых данных в этом корпусе:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
Например, последовательность четырех слов «служит индикацией», была замечена в корпусе 72 раза.
Иногда у нас не хватает данных, чтобы оценить. Увеличение n усугубляет проблемы с разрешением хуже. Как правило, у нас не может быть n больше 5.
NLM обычно (но не всегда) использует RNN для изучения последовательностей слов (предложений, параграфов и т. Д.) И, следовательно, может предсказать следующее слово.
Преимущества:
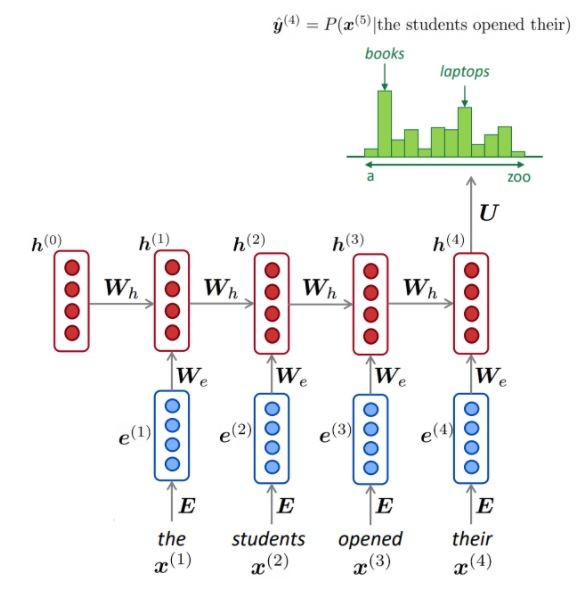
Как изображено, на каждом шаге у нас есть вероятность распределения следующего слова по словарному запасу.
Обучение NLM:
Пример обучения длинным последовательностям:
Недостатки:
LM может использоваться для создания текстовых условий при вводе (речи, изображения (OCR), текста и т. Д.) В различных приложениях, таких как: распознавание речи, машинный перевод, суммирование и т. Д.
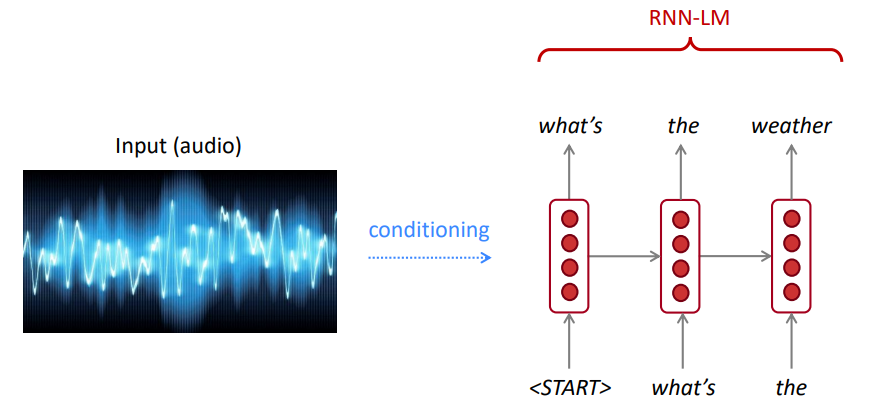
Предпочитает ли наша языковая модель хороших (вероятных) предложений плохим?
Стандартная метрика оценки для языковых моделей - это недоумение, что смущением является обратная вероятность тестового набора, нормализованного по количеству слов
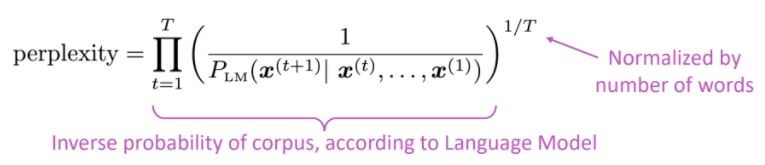
Более низкая недоумение = лучшая модель
Смущение связано с фактором ветви: в среднем, сколько вещей может произойти дальше.
Вместо RNN, давайте используем внимание, давайте использовать большие предварительно обученные модели
В чем проблема? Одной из самых больших проблем в обработке естественного языка (NLP) является нехватка учебных данных для многих различных задач. Тем не менее, современные модели NLP на основе глубокого обучения улучшаются при обучении на миллионах или миллиардах аннотированных примеров обучения.
Предварительное обучение является решением: Чтобы помочь закрыть этот пробел, было разработано различные методы для обучения моделей представления языка в общем назначении с использованием огромного количества нездорового текста. Предварительно обученная модель может затем быть точно настроена на небольшие данные для различных задач, таких как ответный ответ на вопросы и анализ настроений, что приводит к существенным повышению точности по сравнению с обучением на этих наборах данных с нуля.
Архитектура трансформатора была предложена в документе. Внимание - все, что вам нужно, используется для задачи перевода нейронной машины (NMT), состоящая из:
Как упомянуто в газете:
« Мы предлагаем новую простую сетевую архитектуру, трансформатор, основанный исключительно на механизмах внимания, полностью отказался от рецидива и свертков »
Основная идея внимания может быть обобщена, как упомянуто в статье Openai:
« ... Каждый выходной элемент подключен к каждому входному элементу, а весы между ними динамически рассчитываются на основе обстоятельств , процесс, который призывал внимание».
Основываясь на этой архитектуре (ванильные трансформаторы!), Кодеры энкодера или декодера могут использоваться в отдельности для обеспечения массивных предварительно обученных общих моделей, которые могут быть точно настроены для нисходящих задач, таких как классификация текста, перевод, суммирование, ответ на вопросы и т. Д. Например:: Например::
Эти модели, например, BERT и GPT, могут рассматриваться как NLP ImageNet.
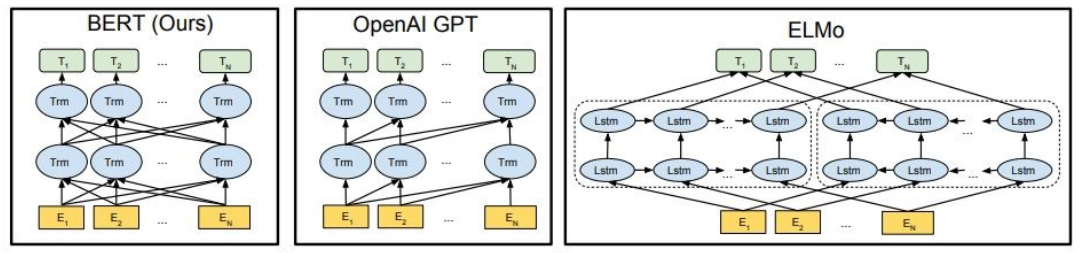
Как показано, Берт глубоко двунаправлен, Openai GPT является однонаправленным, а Эльмо неглубокий двунаправленный.
Предварительно обученные представления могут быть:
Контекстные языковые модели могут быть:
В этой части мы собираемся использовать разные крупные языковые модели
GPT2 (преемник GPT)-это предварительно обученная модель на английском языке с использованием объектива причинно-следственного языка ( CLM ), обученная просто предсказать следующее слово в 40 ГБ интернет-текста. Впервые он был выпущен на этой странице. GPT2 отображает широкий набор возможностей, в том числе способность генерировать условные образцы синтетического текста. Что касается языковых задач, таких как ответ на вопрос, понимание прочитанного, суммирование и перевод, GPT2 начинает изучать эти задачи из необработанного текста, используя никакие данные обучения, специфичные для задачи. Distilgpt2 является дистиллированной версией GPT2, предназначен для использования для аналогичных вариантов использования с повышенной функциональностью меньше и проще в запуске, чем базовая модель.
Здесь мы загружаем предварительно обученную модель GPT2 , попросим модель GPT2 продолжить наш входной текст (приглашение) и, наконец, извлеките встроенные функции из модели Distilgpt2.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Берт-это модель трансформаторов, предварительно обученная на большом корпусе английских данных самоподобными способом. Это означает, что он был предварительно обучен только на необработанных текстах, и никто не маркировал их каким-либо образом с помощью автоматического процесса для генерации входов и ярлыков из этих текстов. Точнее, это было предварительно проведено с двумя целями:
В этом примере мы собираемся использовать предварительно обученную модель BERT для задачи анализа настроений.
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4ALL - это экосистема для обучения и развертывания мощных и индивидуальных крупных языковых моделей, которые локально работают на процессорах потребительского уровня.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
Попробуйте следующие модели:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM является флагманской серией крупных языковых моделей TII, созданной с нуля с использованием пользовательского конвейера данных и распределенного обучения. Модели Falcon-7B/40B являются современными для их размера, опережая большинство других моделей на тестах NLP. Открытый ряд артефактов:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
Llama2-это семейство самых современных широких языковых моделей с открытым доступом, выпущенных Meta Today, и мы рады полностью поддержать запуск с комплексной интеграцией в обнимающееся лицо. Llama 2 выпускается с очень разрешающей лицензией сообщества и доступна для коммерческого использования. Код, предварительно подготовленные модели и тонкие модели выпускаются сегодня
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
Codet5+-это новое семейство моделей с большим языком с открытым кодом с архитектурой Decoder Encoder, которая может гибко работать в разных режимах (т.е. только энкодер, только декодер и энкодер-декодер) для поддержки широкого спектра задач понимания кода и генерации.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
Для получения дополнительных моделей проверьте Codetf от Salesforce, библиотеки на основе трансформатора Python для кода больших языковых моделей (Code LLMS) и интеллекта кода, предоставляя беспроблемный интерфейс для обучения и вывода по задачам интеллекта кода, таких как суммирование кода, перевод, генерация кода и т. Д.
? ️ Общаться с открытыми большими языковыми моделями
✅ Поиск луча всегда найдет выходную последовательность с более высокой вероятностью, чем жадный поиск, но не гарантированно найдет наиболее вероятный выход.
В трансформаторах мы просто устанавливаем параметр num_return_sesecences на количество лучших баллов, которые следует возвращать. Однако убедитесь, что NUM_RETURN_SECENTENCES <= num_beams!
✅ Поиск луча может очень хорошо работать в задачах, где длина желаемой генерации более или менее предсказуем, как в машинном переводе или суммировании. ? Но это не так для открытого поколения, где желаемая длина вывода может сильно различаться, например, диалоговое окно и генерацию истории. Поиск луча сильно страдает от повторяющейся поколения. Как люди, мы хотим, чтобы сгенерированный текст удивил нас и не был скучным/предсказуемым (? Поиск луча менее удивителен)
В трансформаторах мы устанавливаем do_sample = true и деактивируем выборку TOP-K (подробнее об этом позже) через Top_K = 0.
???-? ??????? GPT2 принял эту схему отбора проб.
???-? ?????? Затем масса вероятности перераспределяется среди этого набора слов. Установив P = 0,92, отборочная выборка Top-P выбирает минимальное количество слов, чтобы превышать 92% от вероятности массы.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ Хотя Top-P кажется более элегантным, чем Top-K, оба метода хорошо работают на практике. Top-P также может использоваться в сочетании с Top-K, который может избежать очень низких ранжированных слов, одновременно позволяя для некоторого динамического выбора.
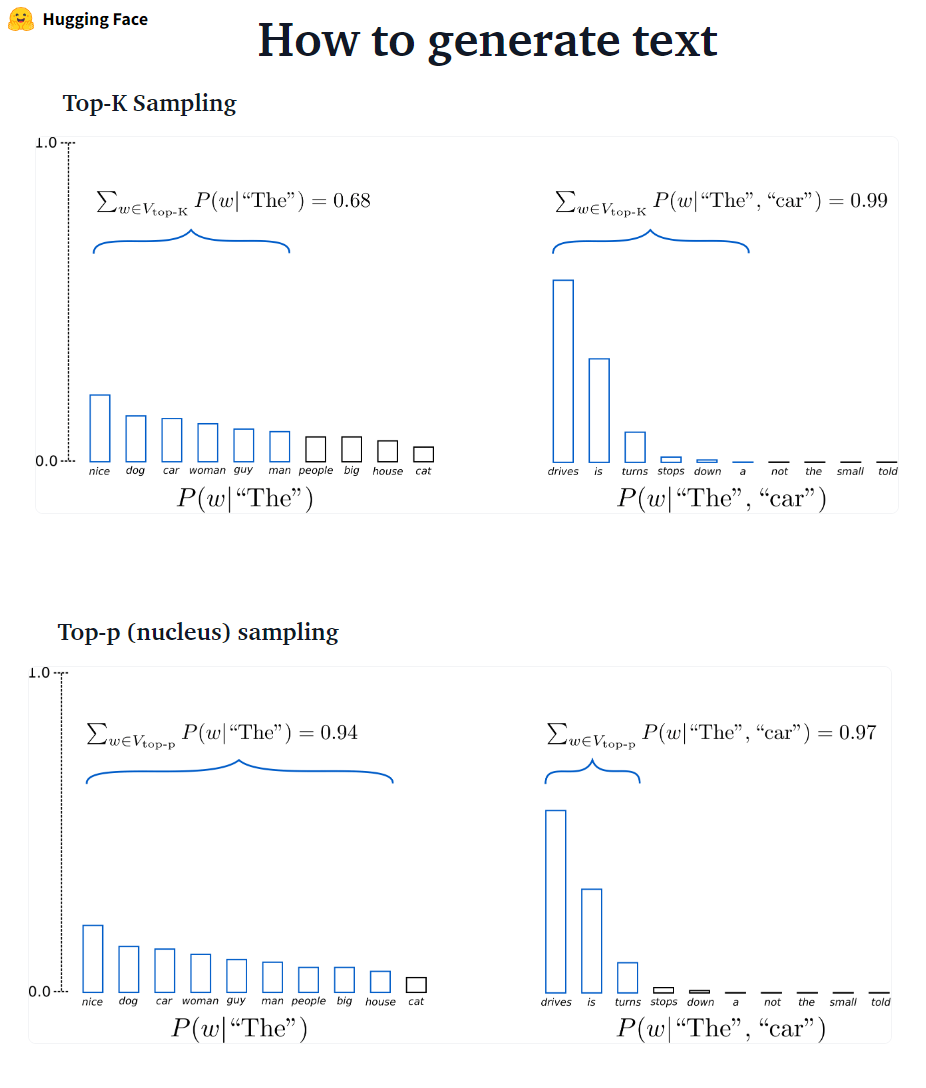
✅ Как специальные методы декодирования, выборка Top-P и Top-K, по-видимому, дает более свободно текст, чем традиционный жадный и лучевой поиск на открытом поколении языка.
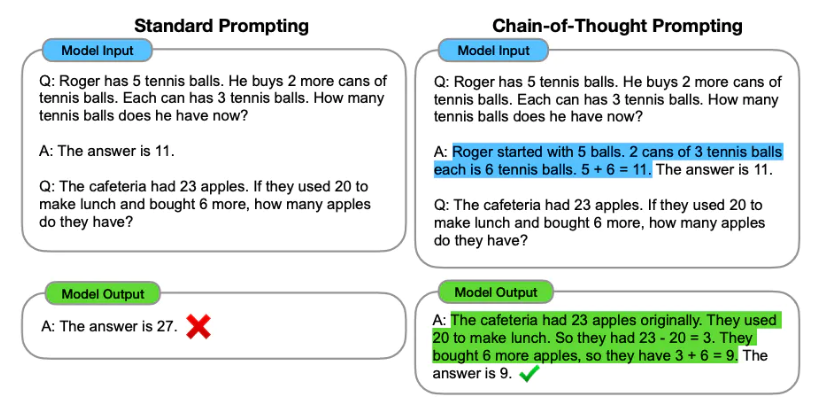
Обратная техника - это процесс разработки подсказок (текстовый вход) для языковой модели для создания требуемого вывода. Обратная техническая инженерия включает в себя выбор подходящих ключевых слов, предоставление контекста, четкое и специфическое таким образом, чтобы направлять языковое поведение, достигающее желаемых ответов. Благодаря быстрому проектированию мы можем контролировать тон, стиль, длина и т. Д. Модели без точной настройки.
Обучение с нулевым выстрелом включает в себя запрос модели делать прогнозы без каких-либо примеров (нулевой выстрел), например:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
Когда нулевой выстрел недостаточно хорош, рекомендуется помочь модели, предоставляя примеры в подсказке, что приводит к нескольким выстрелу.
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
В дополнение к быстрой инженерии , мы можем рассмотреть больше вариантов:
Для получения более быстрой инженерной информации см. Руководство по быстрого инженера, которое содержит все последние документы, руководства по обучению, лекции, ссылки и инструменты.
Тонко настраивающие LLMS в нижестоящих наборах данных приводят к огромному повышению производительности по сравнению с использованием предварительно проведенного LLMS вне коробки (например, вывод с нулевым выстрелом). Однако, поскольку модели становятся все больше и больше, полная точная настройка становится невозможной для обучения на потребительском оборудовании. Кроме того, хранение и развертывание тонких настраиваемых моделей независимо для каждой нисходящей задачи становится очень дорогим, потому что тонкие модели имеют такой же размер, что и исходная предварительно предварительно проведенная модель. Параметр-эффективные подходы с точной настройкой (PEFT) предназначены для решения обеих проблем! Подходы PEFT позволяют вам получить производительность, сравнимую с полной точной настройкой, имея лишь небольшое количество обучаемых параметров. Например:
Обратная настройка: простой, но эффективный механизм для изучения «мягких подсказок» для обучения замороженных языковых моделей для выполнения определенных нижестоящих задач. Так же, как инженерные текстовые подсказки, мягкие подсказки объединяются с входным текстом. Но вместо того, чтобы выбирать из существующих словарных предметов, «токены» мягкой подсказки являются обучаемыми векторами. Это означает, что мягкая подсказка может быть оптимизирована сквозной по сравнению с набором данных, как показано ниже: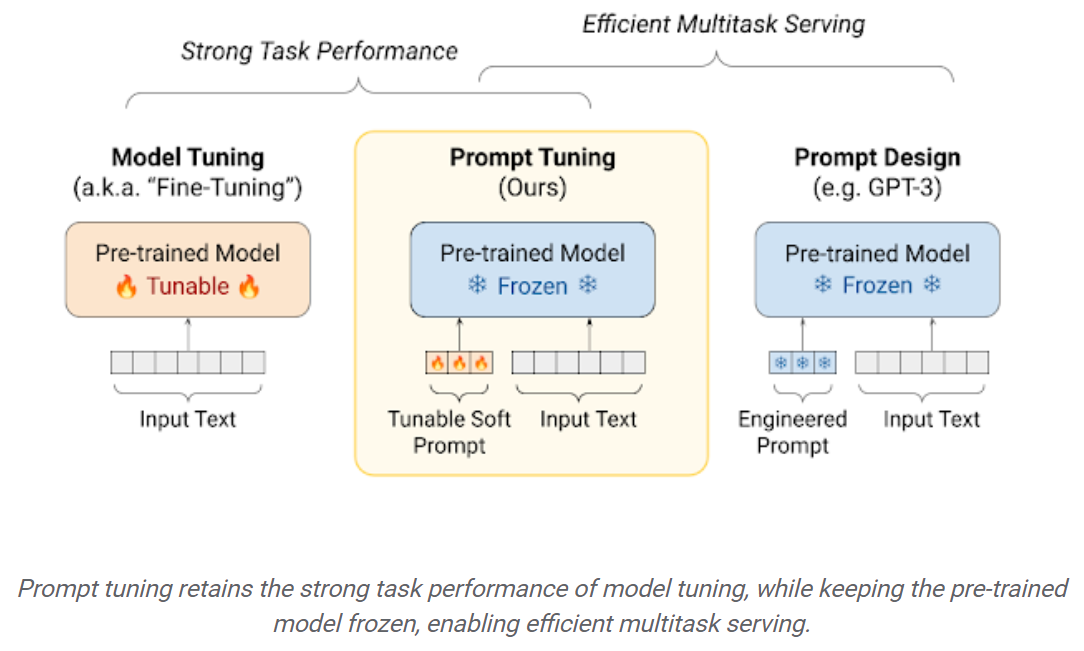
Низкая адаптация LORA LLMS-это метод, который замораживает предварительно проведенные веса модели и внедряет матрицы декомпозиции обучения в каждый слой архитектуры трансформатора. Значительно сокращение количества обучаемых параметров для нижестоящих задач. Рисунок ниже, из этого видео, исследовательская идея: основная идея: 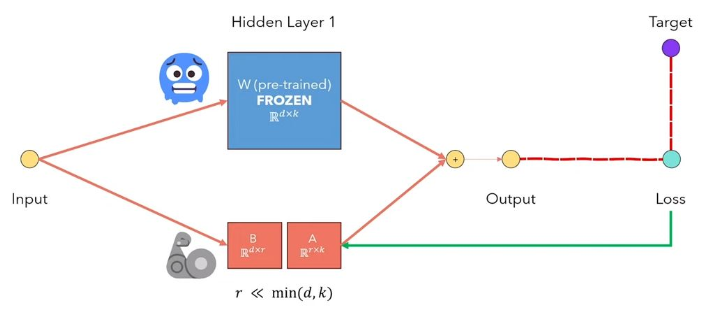
Большие языковые модели, как правило, являются общими, менее эффективными для конкретных доменных задач. Тем не менее, они могут быть точно настроены на некоторые задачи, такие как анализ настроений. Для более сложных TAK, которые требуют внешних знаний, можно создать систему на основе языковой модели, которая обращается к внешним источникам знаний для выполнения необходимых задач. Это обеспечивает более фактическую точность и помогает смягчить проблему «галлюцинации». Как показано в фигуре ниже:
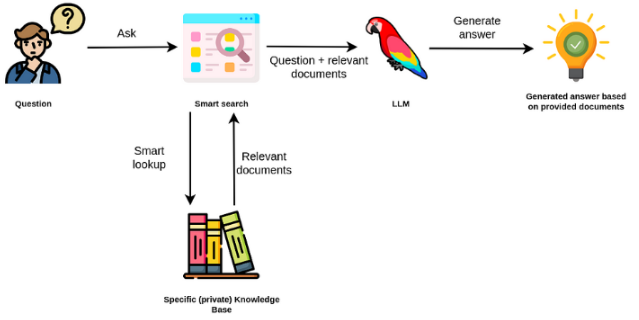
В этом случае вместо использования LLMS для доступа к его внутренним знаниям мы используем LLM в качестве интерфейса естественного языка для наших внешних знаний. Первым шагом является преобразование документов и любых пользовательских запросов в совместимый формат для выполнения поиска релевантности (преобразование текста в векторы или встраивания). Исходная подсказка пользователя затем добавляется с соответствующими / аналогичными документами в источнике внешнего знания (в качестве контекста). Затем модель отвечает на вопросы на основе предоставленного внешнего контекста.
Большие языковые модели (LLM) становятся трансформирующими технологиями. Однако использование этих LLMS в изоляции часто недостаточно для создания действительно мощных приложений. Лангхейн стремится помочь в разработке таких приложений.
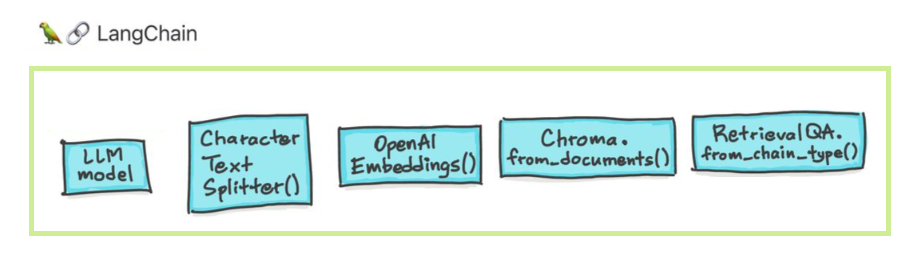
Есть шесть основных областей, с которыми Langchain предназначен для помощи. Это в растущем порядке сложности:
Это включает в себя быстрое управление, быстрое оптимизацию, общий интерфейс для всех LLMS и общие утилиты для работы с LLMS. LLM и модели чата тонко, но важно отличаться. LLM в Лангхейне относятся к моделям завершения чистого текста. API, которые они обертывают, принимают подсказку строки в качестве ввода и выводят завершение строки. GPT-3 OpenAI реализован как LLM. Модели чата часто поддерживаются LLMS, но настроены специально для разговоров.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
Вы также можете получить доступ к конкретной информации поставщика, которая возвращается. Эта информация не стандартизирована между поставщиками.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
Подсказка для чата - это список сообщений чата. Каждое сообщение в чате связано с содержанием, и дополнительный параметр, называемый ролью. Например, в API завершения чата Openai обратное сообщение в чате может быть связано с помощником ИИ, человеческой или системой.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
Цепи выходят за рамки одного вызова LLM и включают последовательности вызовов (будь то LLM или другая утилита). Langchain предоставляет стандартный интерфейс для цепей, множество интеграций с другими инструментами и сквозные цепочки для общих приложений. Цепь очень общая, можно определить как последовательность вызовов для компонентов, которые могут включать другие цепочки.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
Данные, дополненные генерацией, включают в себя конкретные типы цепочек, которые сначала взаимодействуют с внешним источником данных, чтобы получить данные для использования на шаге генерации. Примеры включают вопрос/ответ на конкретные источники данных.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
Поиск сходства
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
Агенты включают LLM, принимающий решения о том, какие действия предпринять, предпринять это действие, видя наблюдения и повторяя это до тех пор, пока они не сделаны. Langchain предоставляет стандартный интерфейс для агентов, выбор агентов на выбор и примеры сквозных агентов. Основная идея агентов состоит в том, чтобы использовать LLM для выбора последовательности действий. В цепях последовательность действий жестко кодируется (в коде). У агентов языковая модель используется в качестве механизма рассуждений, чтобы определить, какие действия предпринять и в каком порядке.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Память относится к постоянному состоянию между вызовами цепочки/агента. Langchain предоставляет стандартный интерфейс для памяти, набор реализаций памяти и примеры цепочек/агентов, которые используют память.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
Мы можем использовать разные методы для общения с нашими документами. Нет необходимости точно настроить весь LLM, вместо этого мы можем предоставить правильный контекст вместе с нашим вопросом для предварительно обученной модели и просто получить ответы на основе наших предоставленных документов.
Здесь мы общаемся с этой хорошей статьей под названием «Трансформеры без боли»? Задавать вопросы, связанные с трансформаторами, вниманием, энкодером-декодером и т. Д. При использовании мощной модели пальмы Google и Langchain Framework для разработки приложений, основанных на языковых моделях.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
Вопрос : ? «О чем эти документы?»
Отвечать : ? «Документы о трансформаторах, которые представляют собой тип нейронной сети, которая успешно использовалась при обработке естественного языка и задачах компьютерного зрения».
Вопрос : ? «Какова основная идея трансформаторов?»
Отвечать : ? «Основная идея трансформаторов-использовать механизмы внимания для моделирования дальних зависимостей в последовательностях».
Вопрос : ? «Что такое позиционное кодирование?»
Отвечать : ? «Позиционное кодирование - это метод, используемый для представления порядка слов в последовательности».
Вопрос : ? «Как используются векторы запроса, ключа и значение?»
Отвечать : ? «Вектор запросов используется для вычисления взвешенной суммы значений через ключи. В частности: Q Dot Product Все клавиши, затем Softmax, чтобы получить вес и, наконец, использовать эти веса для вычисления взвешенной суммы значений ».
Вопрос : ? «Как начать использовать трансформаторы?»
Отвечать : ? «Чтобы начать использовать трансформаторы, вы можете использовать библиотеку Trangingface Transformers. Эта библиотека предоставляет тысячи предварительных моделей для выполнения задач по таким текстам, как классификация, извлечение информации, ответ на вопросы, суммирование, перевод, генерация текста и т. Д. На 100+ языках ».
Вы можете попробовать свои собственные документы и вопросы!
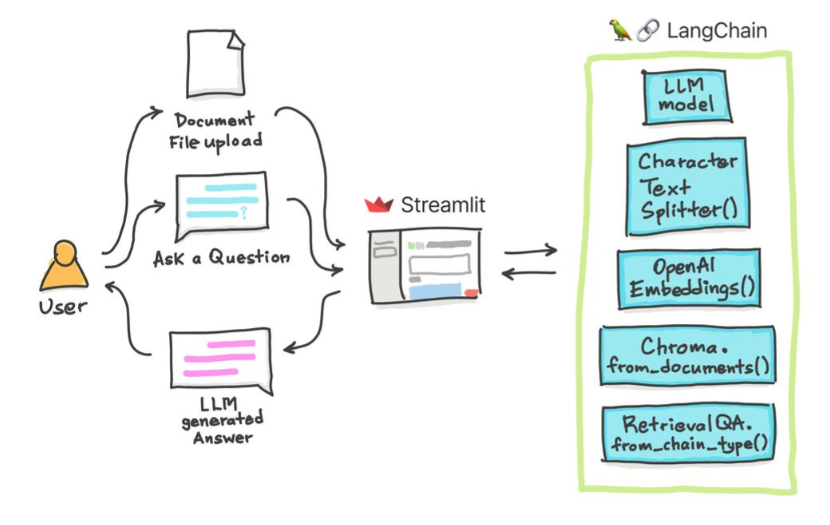
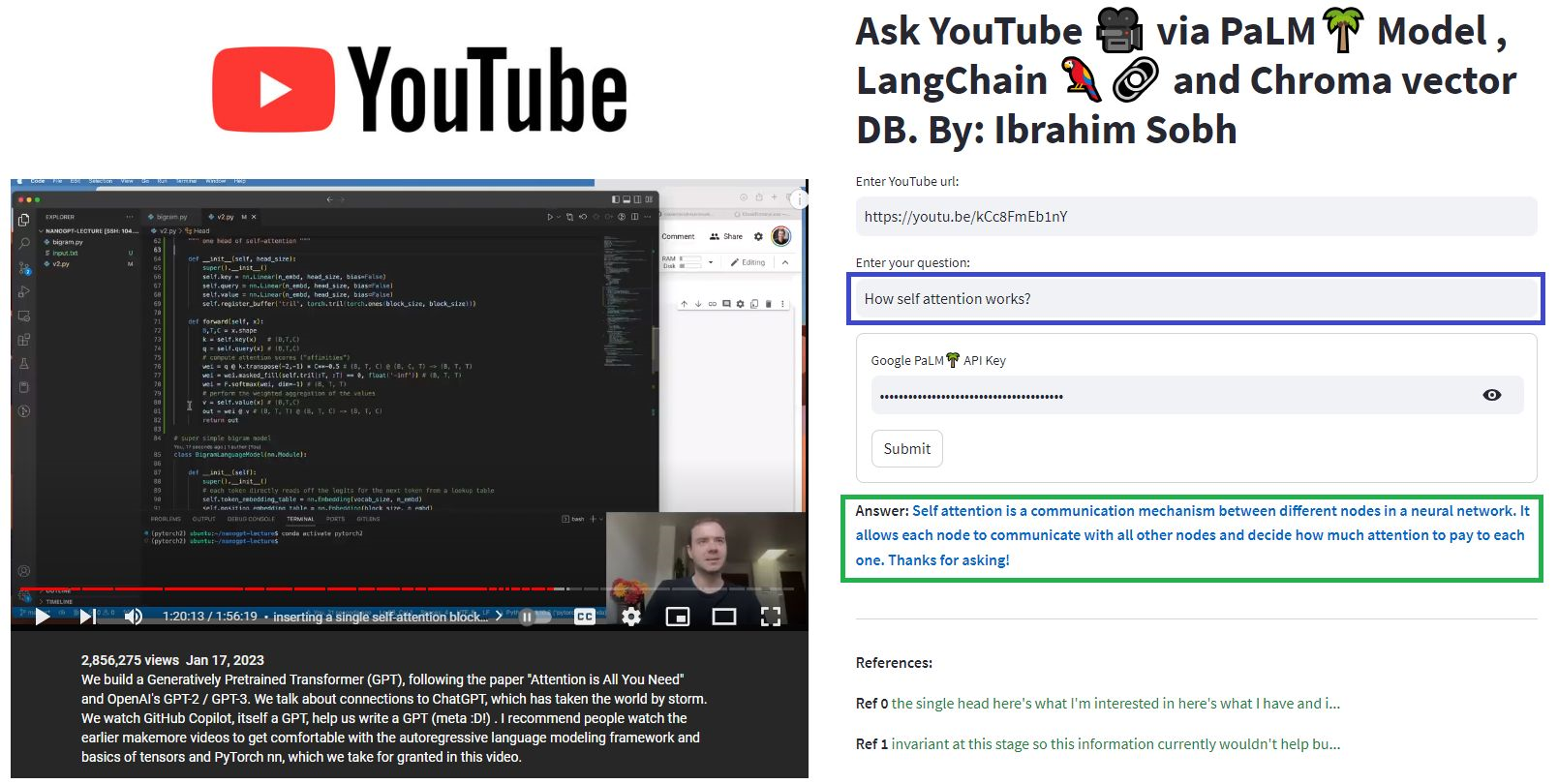
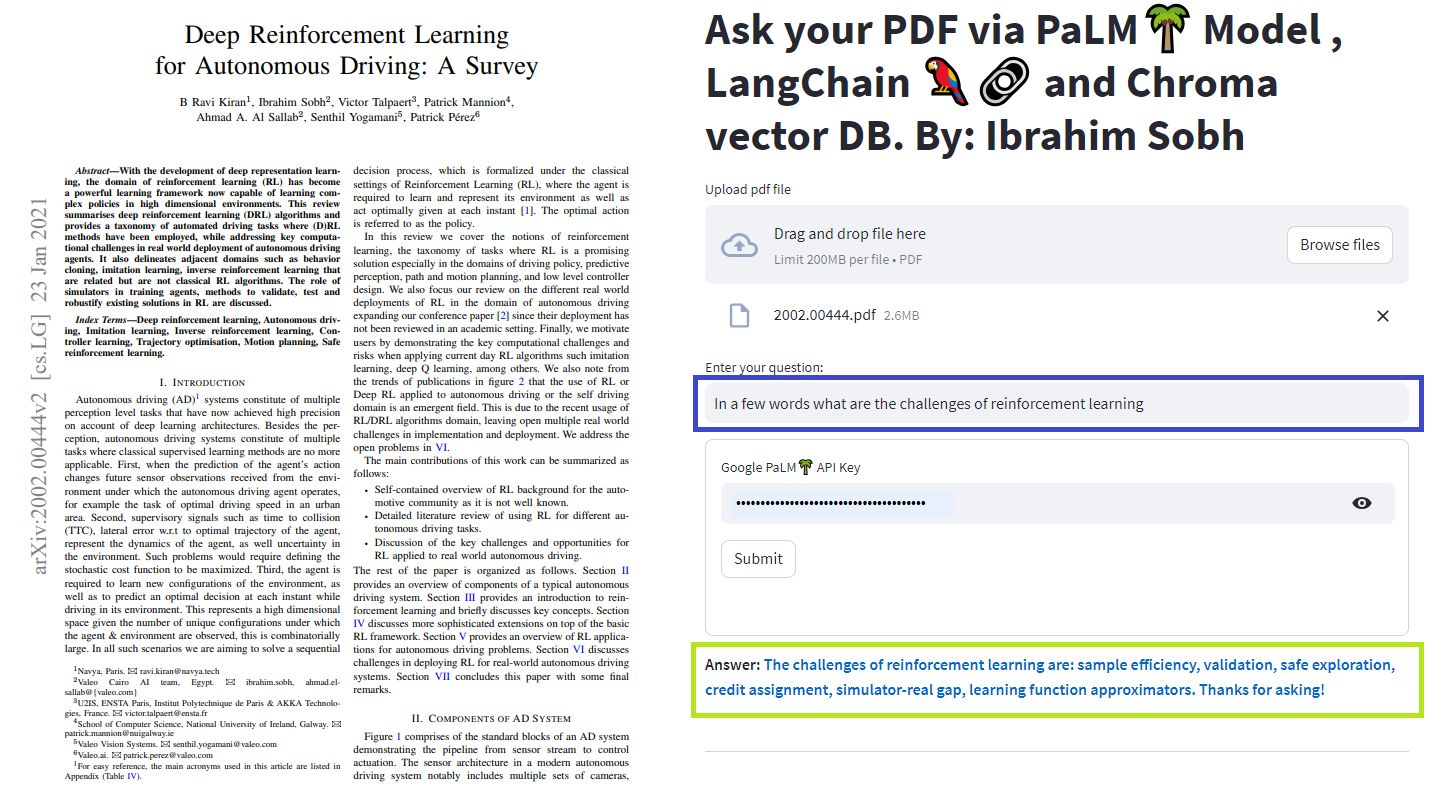
В этих простых учебных пособиях: как получить ответы из текстовых документов, файлов PDF и даже видео на YouTube с использованием базы данных Vector Croma, Palm LLM от Google, и ответная цепочка для вопросов из Langchain. Наконец, используйте Streamlit для разработки и размещения веб -приложения. Вам нужно будет использовать свой google_api_key (вы можете получить один от Google). Архитектура системы заключается в следующем:
Существует разница между оценкой LLM и оценкой системы на основе LLM. Как правило, после общего предварительного обучения LLM оцениваются на стандартных тестах:
Системы LLMS могут суммировать текст, выполнять вопросы, отвечающие вопросам, найти настроение текста, можно сделать перевод и многое другое. На основании системы оценка может быть следующей:
Например, в случае системы ответа на вопросы нам нужны пары вопросов и ответов в нашем наборе оценки. Мы можем использовать человеческие аннотаторы для создания золотых пар вопросов и ответов вручную. However, it is costly and time-consuming. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
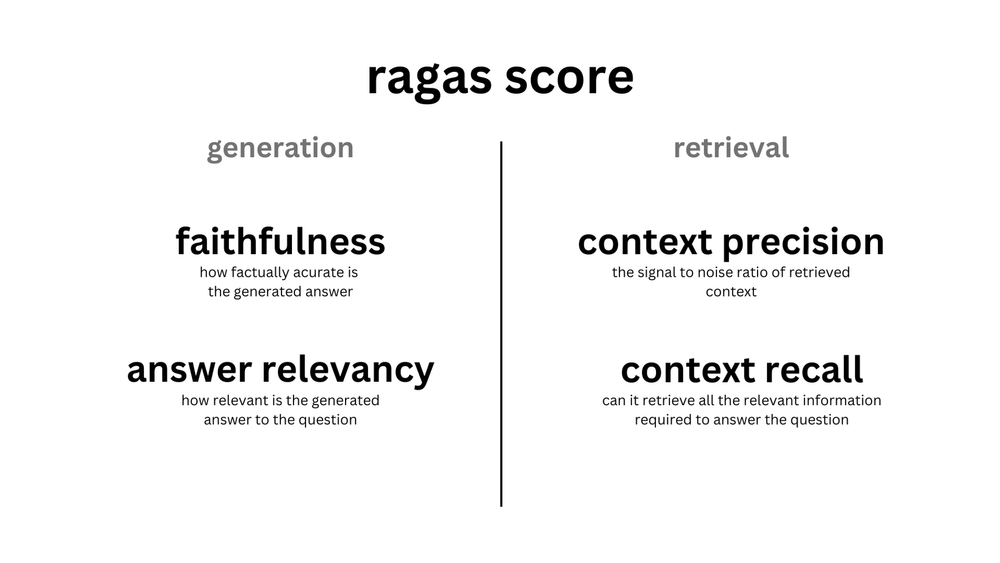
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
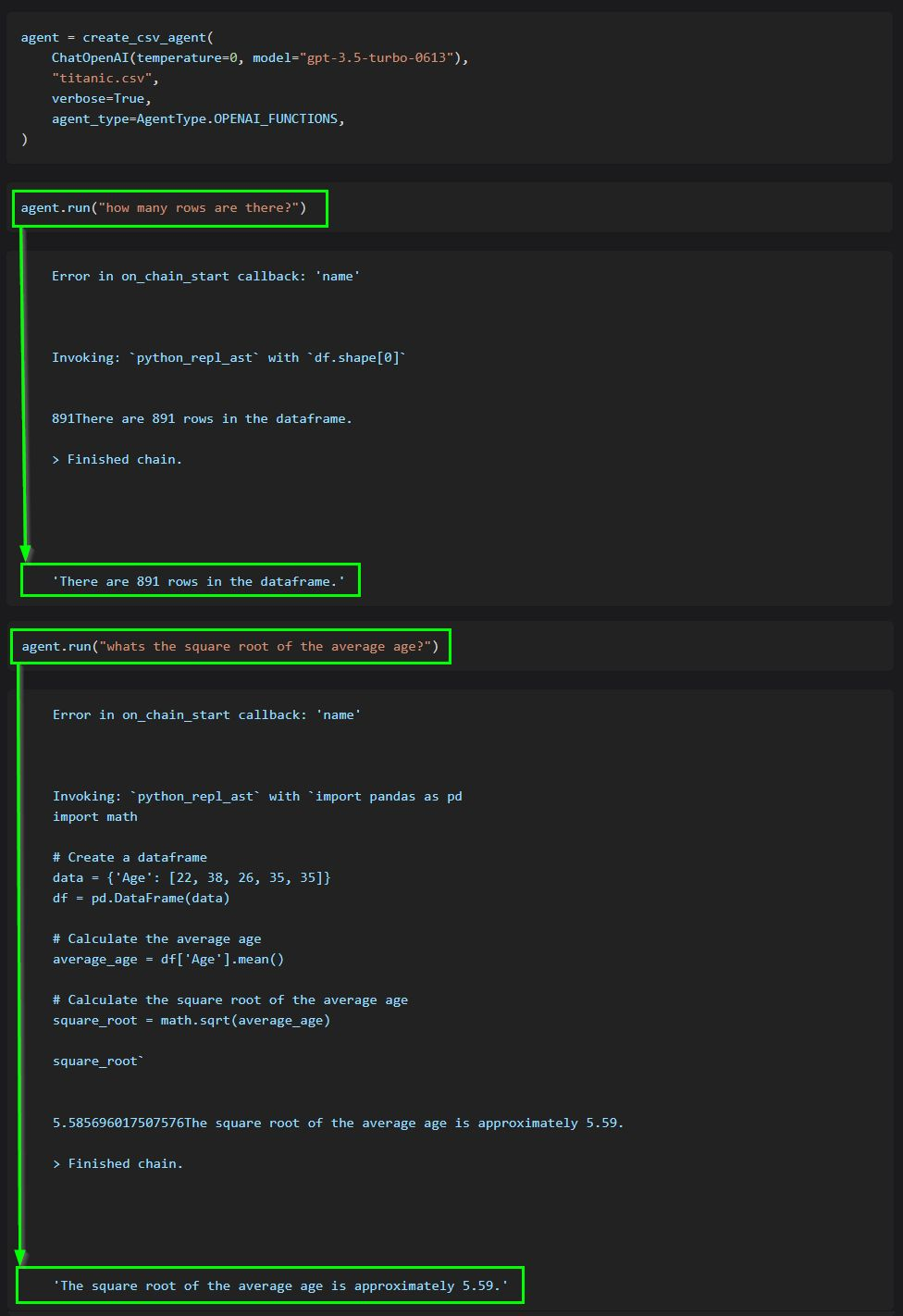
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
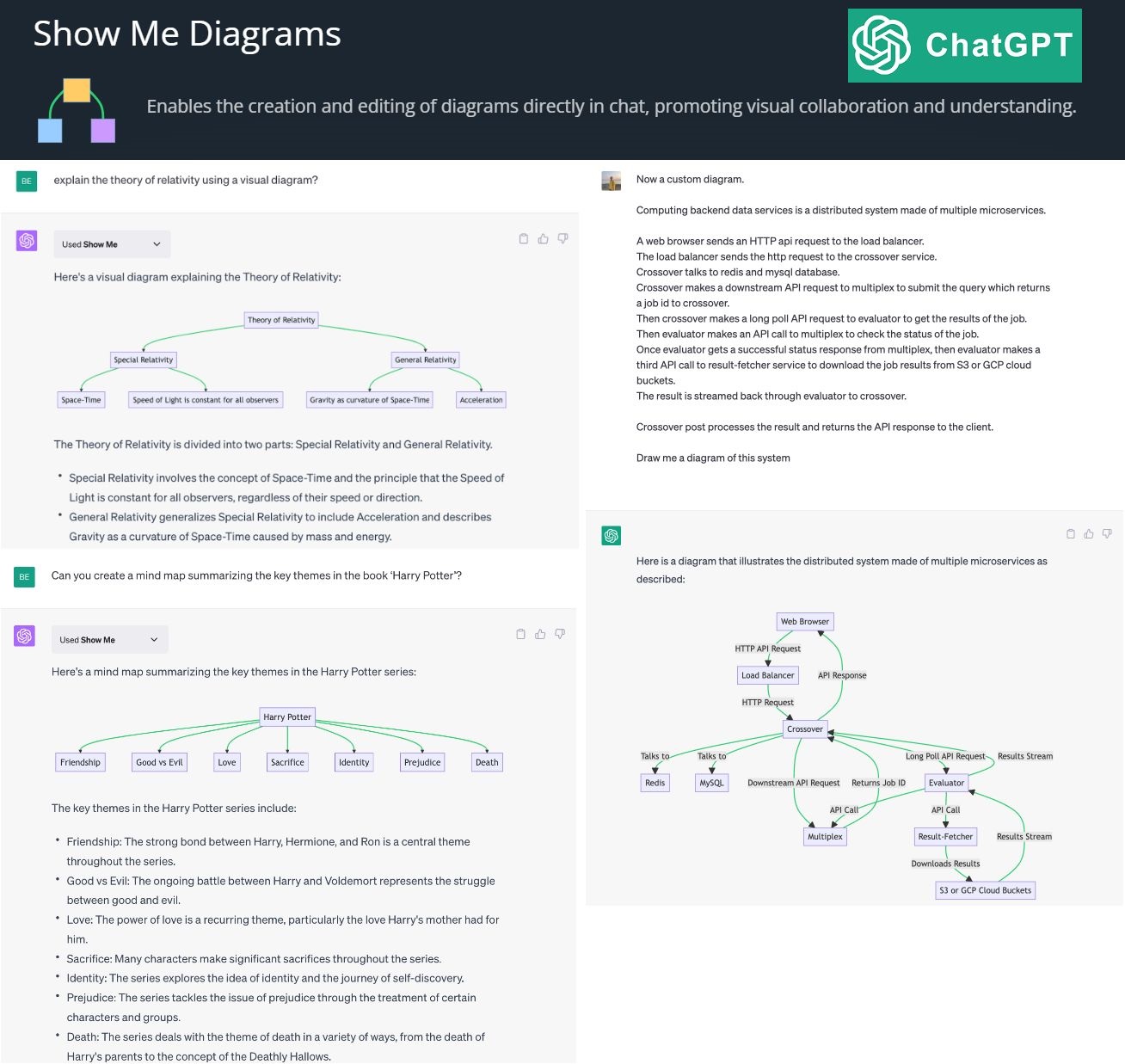
By creating and editing diagrams via Show Me Diagrams
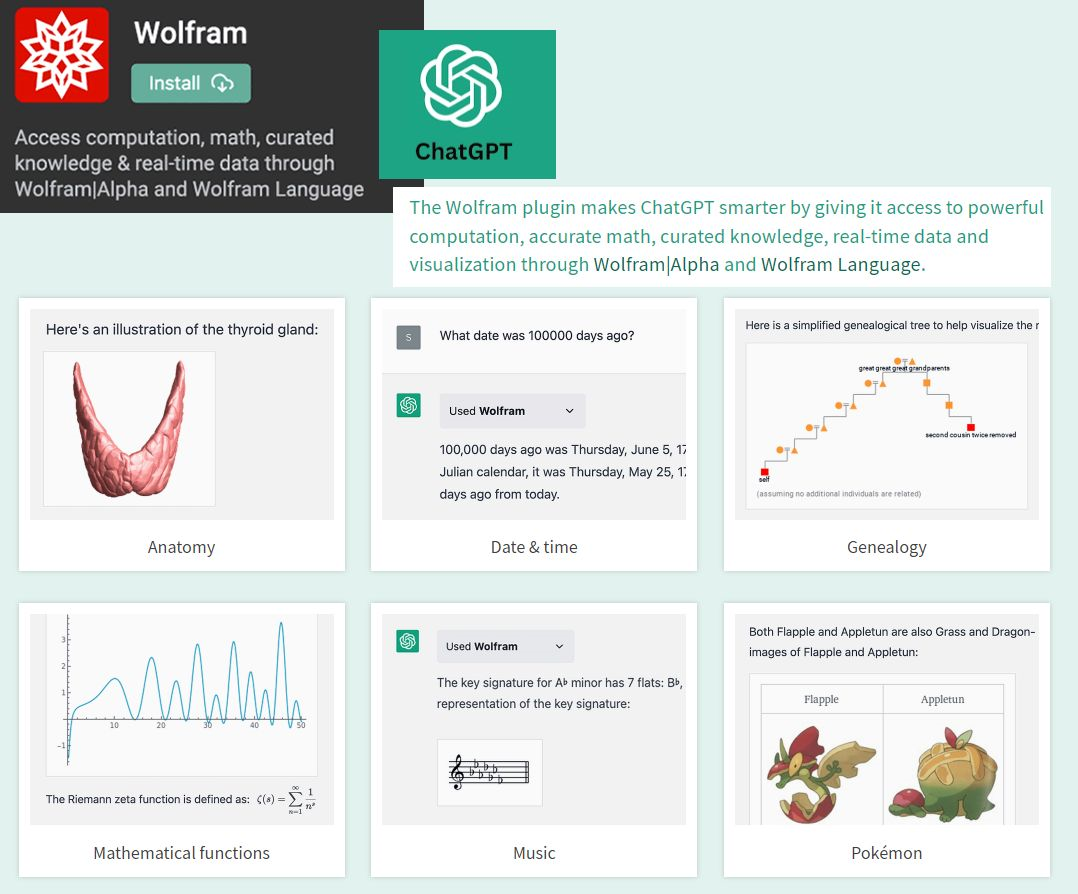
By accessing the power of mathematics provided by Wolfram
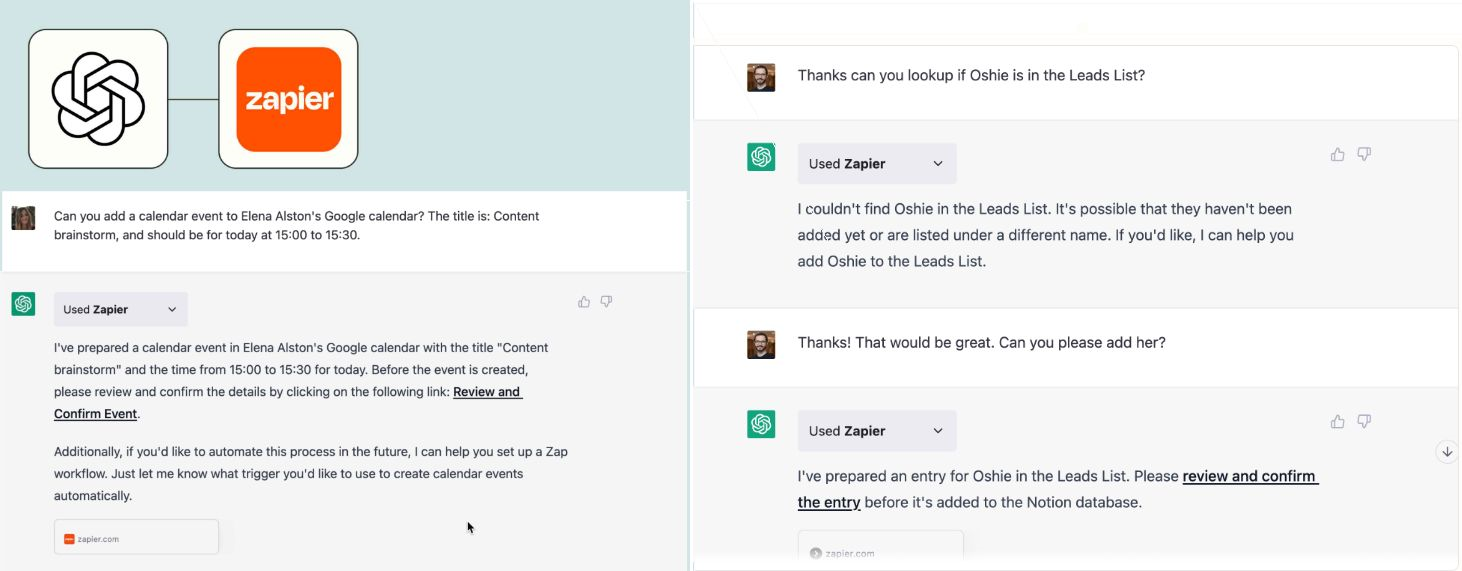
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


