llms
1.0.0
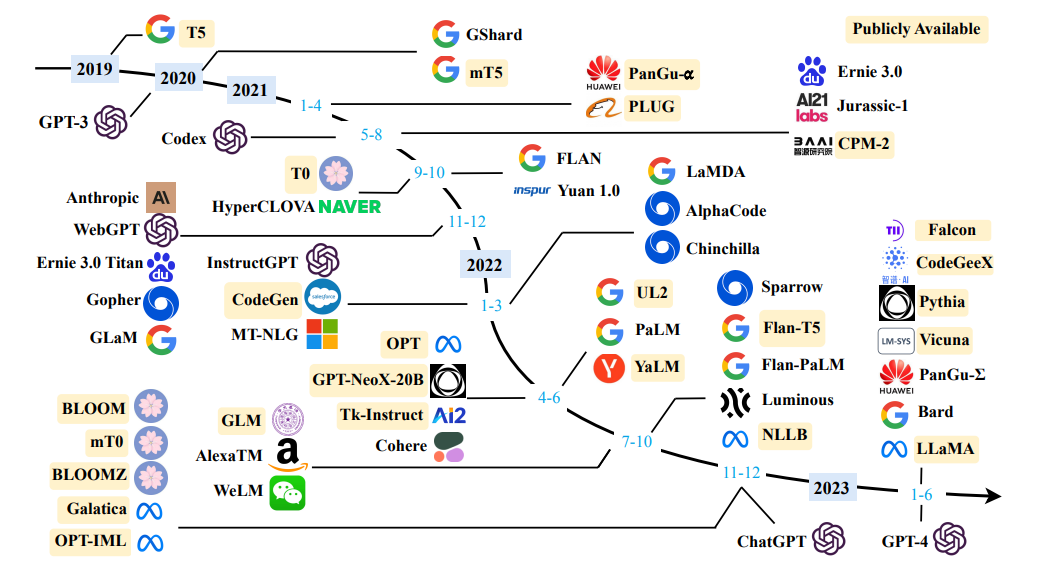 Source une enquête sur des modèles de grandes langues
Source une enquête sur des modèles de grandes langues
Définition simple: la modélisation du langage est la tâche de prédire quel mot vient ensuite.
"Le chien joue dans le ..."
L'objectif principal des modèles de langue est d'attribuer une probabilité à une phrase, pour distinguer les phrases les plus probables et les moins probables.
Pour la reconnaissance vocale, nous utilisons non seulement le modèle d'acoustique (le signal de la parole), mais aussi un modèle de langue. De même, pour la reconnaissance optique des caractères (OCR), nous utilisons à la fois un modèle de vision et un modèle de langue. Les modèles linguistiques sont très importants pour de tels systèmes de reconnaissance.
Parfois, vous entendez ou lisez une phrase qui n'est pas claire, mais en utilisant votre modèle linguistique, vous pouvez toujours le reconnaître à haute précision malgré la vision bruyante de la vision / la parole.
Le modèle de langue calcule l'un ou l'autre:
La modélisation du langage est un sous-composant de nombreuses tâches PNL, en particulier celles impliquant la génération de texte ou l'estimation de la probabilité de texte.
La règle de la chaîne:
$ P (le, eau, est, donc, clair) = p (le) × p (eau | le) × p (est | le, eau) × p (donc | L'eau, est) × p (clair | L'eau, est, donc) $
Que vient-il de se passer? La règle de la chaîne est appliquée pour calculer la probabilité conjointe de mots dans une phrase.
En utilisant une grande quantité de texte (corpus tel que Wikipedia), nous collectons des statistiques sur la fréquence des mots différents et les utilisons pour prédire le mot suivant. Par exemple, la probabilité qu'un mot w vienne après que ces trois mots que les élèves aient ouverts puissent être estimés comme suit:
L'exemple ci-dessus est un modèle à 4 grammes. Et nous pouvons obtenir:
Nous pouvons conclure que le mot «livres» est plus probable que les «voitures» dans ce contexte.
Nous avons ignoré le contexte précédent avant que "les étudiants ouverts le leur"
En conséquence, le texte arbitraire peut être généré à partir d'un modèle de langue donné (s) de départ (s), en échantillonnant à partir de la distribution de probabilité de sortie du mot suivant, etc.
Nous pouvons entraîner un LM sur n'importe quel type de texte, puis générer du texte dans ce style (Harry Potter, etc.).
Nous pouvons nous étendre aux trigrammes, 4 grammes, 5 grammes et n-grammes.
En général, il s'agit d'un modèle de langue insuffisant car la langue a des dépendances à longue distance. Cependant, dans la pratique, ces 3,4 grammes fonctionnent bien pour la plupart des applications.
Les modèles N-gram de Google vous appartiennent: Google Research a utilisé des modèles Word N-gram pour une variété de projets de R&D. Google N-Gram a traité 1 024 908 267 229 mots de texte en cours d'exécution et publié les dénombrements pour toutes les séquences de 1 176 470 663 mots qui apparaissent au moins 40 fois.
Les dénombrements de texte du Linguistics Data Consortium LDC sont les suivants:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
Ce qui suit est un exemple des données de 4 grammes dans ce corpus:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
Par exemple, la séquence des quatre mots «servir d'indication» a été observée dans le corpus 72 fois.
Parfois, nous n'avons pas suffisamment de données pour estimer. L'augmentation de N aggrave les problèmes de rareté. En règle générale, nous ne pouvons pas avoir N plus grand que 5.
NLM (mais pas toujours) utilise un RNN pour apprendre des séquences de mots (phrases, paragraphes,… etc.) et peut donc prédire le mot suivant.
Avantages:
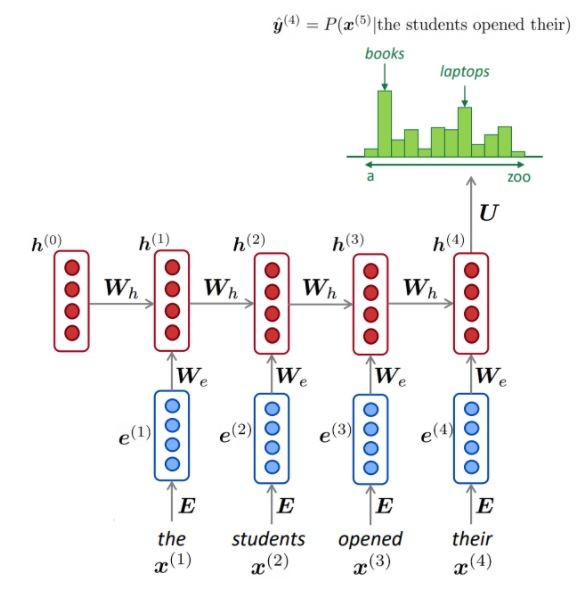
Comme illustré, à chaque étape, nous avons une distribution de probabilité du mot suivant sur le vocabulaire.
Formation d'un NLM:
Exemple d'apprentissage de la séquence longue:
Inconvénients:
LM peut être utilisé pour générer des conditions de texte sur l'entrée (discours, image (OCR), texte, etc.) sur différentes applications telles que: reconnaissance de la parole, traduction machine, résumé, etc.
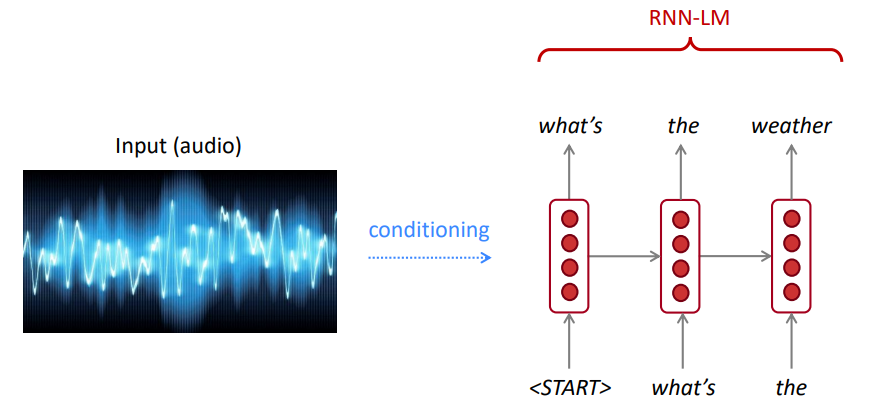
Notre modèle de langue préfère-t-il de bonnes (probablement) phrases à de mauvaises?
La métrique d'évaluation standard pour les modèles de langage est la perplexité que la perplexité est la probabilité inverse de l'ensemble de tests, normalisé par le nombre de mots
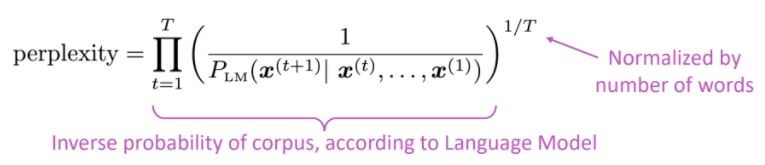
Cerplexité inférieure = meilleur modèle
La perplexité est liée au facteur de branche: en moyenne, combien de choses pourraient se produire ensuite.
Au lieu de RNN, utilisons l'attention utilisons de grands modèles pré-formés
Quel est le problème? L'un des plus grands défis du traitement du langage naturel (PNL) est la pénurie de données de formation pour de nombreuses tâches distinctes. Cependant, les modèles NLP modernes basés sur l'apprentissage en profondeur s'améliorent lorsqu'ils sont formés à des millions, ou à des milliards d'exemples de formation annotés.
La pré-formation est la solution: pour aider à combler cet écart, une variété de techniques ont été développées pour la formation de modèles de représentation du langage à usage général en utilisant l'énorme quantité de texte non annoté. Le modèle pré-formé peut ensuite être affiné sur de petites données pour différentes tâches telles que la réponse aux questions et l'analyse des sentiments, entraînant des améliorations de précision substantielles par rapport à la formation sur ces ensembles de données à partir de zéro.
L'architecture du transformateur a été proposée dans l'attention du papier est tout ce dont vous avez besoin, utilisé pour la tâche de traduction de la machine (NMT), consistant en:
Comme mentionné dans le document:
" Nous proposons une nouvelle architecture de réseau simple, le transformateur, basé uniquement sur les mécanismes d'attention, en distribuant entièrement de récidive et de convolutions "
L'idée principale de l'attention peut être résumé comme mentionné dans l'article d'Openai:
" ... Chaque élément de sortie est connecté à chaque élément d'entrée, et les pondérations entre elles sont calculées dynamiquement en fonction des circonstances , un processus appelé attention. "
Sur la base de cette architecture (les transformateurs de vanille!), Des composants d'encodeur ou de décodeur peuvent être utilisés seuls pour permettre des modèles génériques pré-formés massifs qui peuvent être affinés pour les tâches en aval telles que la classification du texte, la traduction, le résumé, la réponse aux questions, etc. Par exemple: par exemple:
Ces modèles, Bert et GPT, par exemple, peuvent être considérés comme l'imageNet de la PNL.
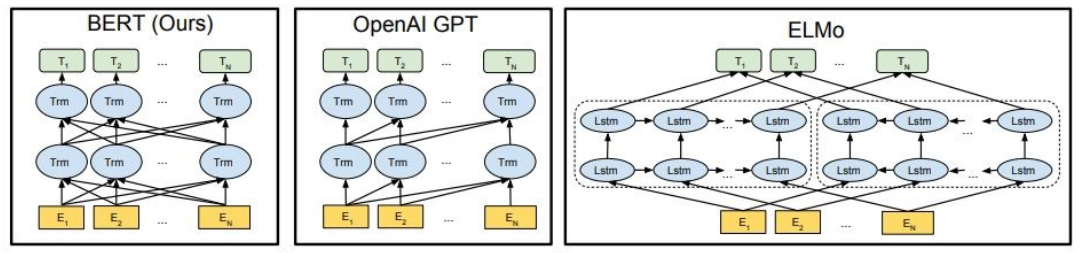
Comme indiqué, Bert est profondément bidirectionnel, Openai GPT est unidirectionnel et Elmo est peu profonde bidirectionnel.
Les représentations pré-formées peuvent être:
Les modèles de langage contextuel peuvent être:
Dans cette partie, nous allons utiliser différents modèles de langues grands
GPT2 (un successeur de GPT) est un modèle pré-formé sur la langue anglaise à l'aide d'un objectif de modélisation de la langue causale ( CLM ), formé simplement pour prédire le mot suivant dans 40 Go de texte Internet. Il a été publié pour la première fois sur cette page. GPT2 affiche un large ensemble de capacités, y compris la possibilité de générer des échantillons de texte synthétique conditionnels. Sur les tâches linguistiques comme la réponse aux questions, la compréhension de la lecture, le résumé et la traduction, GPT2 commence à apprendre ces tâches du texte brut, en utilisant aucune donnée de formation spécifique à la tâche. Distilgpt2 est une version distillée de GPT2, elle est destinée à être utilisée pour des cas d'utilisation similaires avec la fonctionnalité accrue de la plus petite et plus facile à exécuter que le modèle de base.
Ici, nous chargeons un modèle GPT2 pré-formé, demandons au modèle GPT2 de continuer notre texte d'entrée (invite), et enfin, extraire les fonctionnalités embarquées du modèle Distilgpt2.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Bert est un modèle Transformers pré-formé sur un grand corpus de données anglaises de manière auto-supervisée. Cela signifie qu'il a été formé uniquement sur les textes bruts, sans les humains les étiquetant en aucune façon avec un processus automatique pour générer des entrées et des étiquettes à partir de ces textes. Plus précisément, il était pré-entraîné avec deux objectifs:
Dans cet exemple, nous allons utiliser un modèle Bert pré-formé pour la tâche d'analyse des sentiments.
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4ALL est un écosystème pour former et déployer des modèles de langage puissants puissants et personnalisés qui s'exécutent localement sur des processeurs grand public.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
Essayez les modèles suivants:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM est la série phare de modèles de grande langue de TII, construite à partir de zéro à l'aide d'un pipeline de données personnalisé et d'une formation distribuée. Les modèles FALCON-7B / 40B sont à la pointe de leur taille, surpassant la plupart des autres modèles sur les références NLP. Open d'un certain nombre d'artefacts:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
LLAMA2 est une famille de modèles de grande langue à l'accès ouvert de pointe publiés par Meta Today, et nous sommes ravis de soutenir pleinement le lancement avec une intégration complète dans Hugging Face. LLAMA 2 est publiée avec une licence communautaire très permissive et est disponible pour un usage commercial. Le code, les modèles pré-entraînés et les modèles affinés sont tous publiés aujourd'hui
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
CODET5 + est une nouvelle famille de modèles de langue de grand code ouverts avec une architecture d'encodeur-décodeur qui peut fonctionner de manière flexible dans différents modes (c'est-à-dire encodeur uniquement, décodeur uniquement et encodeur encodeur) pour prendre en charge un large éventail de tâches de compréhension du code et de génération.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
Pour plus de modèles, vérifiez CodeTF de Salesforce, une bibliothèque basée sur un transformateur Python pour les modèles de linguisses de code (code LLMS) et de Code Intelligence, fournissant une interface transparente pour la formation et l'inférence sur les tâches d'intelligence de code comme la résumé de code, la traduction, la génération de code, etc.
? ️ discuter avec des modèles de grande langue ouverts
✅ La recherche de faisceau trouvera toujours une séquence de sortie avec une probabilité plus élevée que la recherche gourmand, mais n'est pas garantie pour trouver la sortie la plus probable.
Dans Transformers, nous définissons simplement le paramètre num_return_sencences au nombre de faisceaux de score les plus élevés qui doivent être retournés. Assurez-vous cependant que NUM_RETURN_SERDENCES <= num_beams!
✅ La recherche de faisceau peut très bien fonctionner dans les tâches où la longueur de la génération souhaitée est plus ou moins prévisible comme dans la traduction machine ou le résumé. ? Mais ce n'est pas le cas pour la génération ouverte où la longueur de sortie souhaitée peut varier considérablement, par exemple le dialogue et la génération d'histoires. La recherche de faisceau souffre fortement d'une génération répétitive. En tant qu'êtres humains, nous voulons que le texte généré nous surprend et ne soit pas ennuyeux / prévisible (? La recherche de faisceau est moins surprenante)
Dans Transformers, nous définissons DO_SAMPLE = TRUE et désactivez l'échantillonnage TOP-K (plus à ce sujet plus tard) via top_k = 0.
??? -? ????????: Le K est probablement le prochain mots filtrés et la masse de probabilité est redistribuée parmi ces K suivants. GPT2 a adopté ce schéma d'échantillonnage.
??? -? ????????: Au lieu de l'échantillonnage uniquement à partir des K les plus probables, dans l'échantillonnage Top-P choisit parmi le plus petit ensemble de mots possible dont la probabilité cumulative dépasse la probabilité p. La masse de probabilité est ensuite redistribuée parmi cet ensemble de mots. Après avoir réglé P = 0,92, l'échantillonnage Top-P choisit le nombre minimum de mots pour dépasser ensemble 92% de la masse de probabilité.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ Bien que Top-P semble plus élégant que Top-K, les deux méthodes fonctionnent bien dans la pratique. Le Top-P peut également être utilisé en combinaison avec Top-K, ce qui peut éviter les mots très faibles tout en permettant une sélection dynamique.
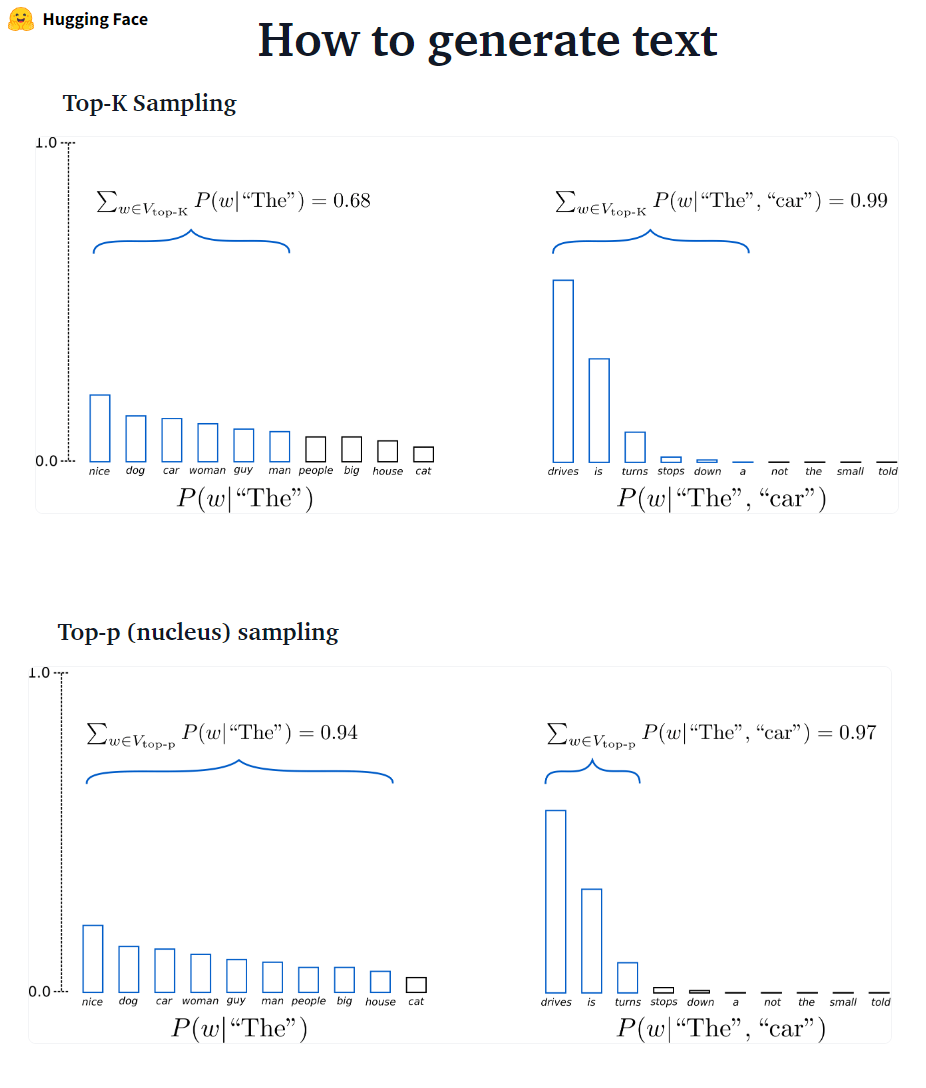
✅ En tant que méthodes de décodage ad hoc, l'échantillonnage TOP-P et TOP-K semble produire du texte plus fluide que la recherche gourmand traditionnelle - et la recherche de faisceau sur la génération de langage ouverte.
L'ingénierie rapide est le processus de conception des invites (entrée de texte) pour un modèle de langue pour générer la sortie requise. L'ingénierie rapide consiste à sélectionner des mots clés appropriés, à fournir un contexte, à être clair et spécifique d'une manière qui dirige le comportement du modèle de langue en réalisant les réponses souhaitées. Grâce à l'ingénierie rapide, nous pouvons contrôler le ton, le style, le style, la longueur, etc. d'un modèle sans réglage fin.
L'apprentissage zéro-shot implique de demander au modèle de faire des prédictions sans fournir d'exemples (Zero Shot), par exemple:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
Lorsque zéro-shot n'est pas suffisant, il est recommandé d'aider le modèle en fournissant des exemples dans l'invite qui conduit à une invitation à quelques coups.
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
En plus de l'ingénierie rapide , nous pouvons considérer plus d'options:
Pour plus d'informations d'ingénierie rapide, consultez le guide d'ingénierie rapide qui contient tous les derniers articles, guides d'apprentissage, conférences, références et outils.
Les LLM à réglage fin sur les ensembles de données en aval entraînent d'énormes gains de performances par rapport à l'utilisation des LLM pré-entraînés à l'extérieur de la boîte (inférence zéro, par exemple). Cependant, à mesure que les modèles deviennent de plus en plus grands, le réglage fin complet devient irréalisable pour s'entraîner sur le matériel des consommateurs. De plus, le stockage et le déploiement de modèles affinés indépendamment pour chaque tâche en aval devient très coûteux, car les modèles affinés sont de la même taille que le modèle d'origine pré-entraîné. Les approches de réglage fin et efficaces par les paramètres (PEFT) sont destinées à résoudre les deux problèmes! Les approches de PEFT vous permettent d'obtenir des performances comparables à la réglage fin complet tout en n'ayant qu'un petit nombre de paramètres formables. Par exemple:
Taponnage rapide: un mécanisme simple mais efficace pour apprendre les «invites souples» pour conditionner les modèles de langage congelé pour effectuer des tâches en aval spécifiques. Tout comme les invites de texte d'ingénierie, les invites souples sont concaténées au texte d'entrée. Mais plutôt que de sélectionner parmi les éléments de vocabulaire existants, les «jetons» de l'invite douce sont des vecteurs apprenables. Cela signifie qu'une invite douce peut être optimisée de bout en bout sur un ensemble de données de formation, comme indiqué ci-dessous: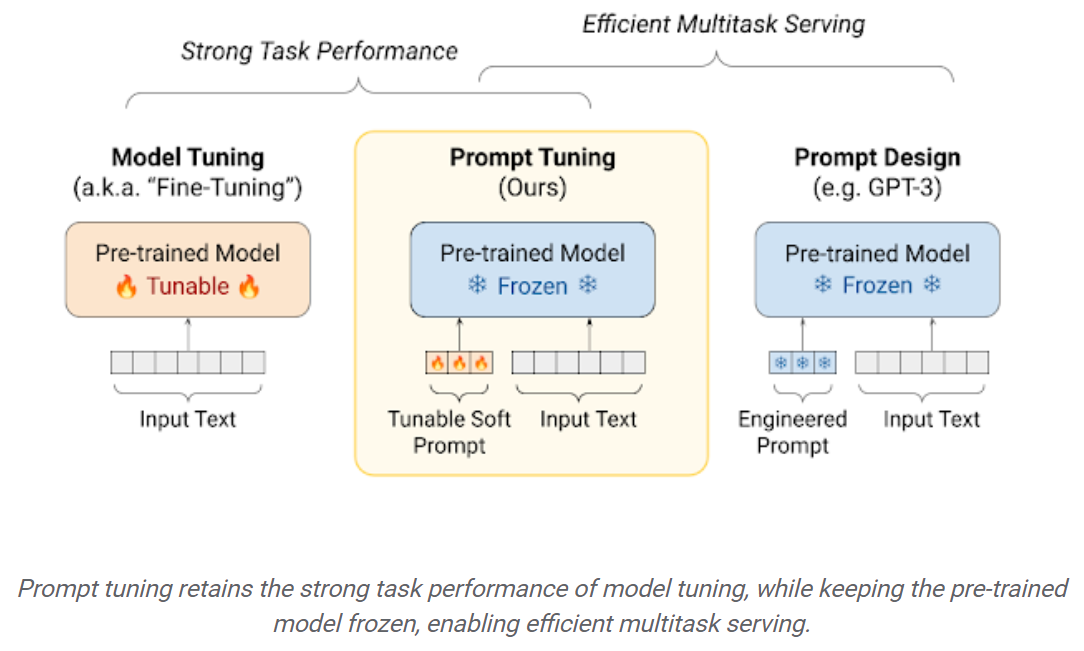
L'adaptation de LORA à faible rang des LLMS est une méthode qui gèle les poids du modèle prétrainés et injecte des matrices de décomposition de rang entraînant dans chaque couche de l'architecture du transformateur. Réduire considérablement le nombre de paramètres formables pour les tâches en aval. La figure ci-dessous, à partir de cette vidéo, explique l'idée principale: 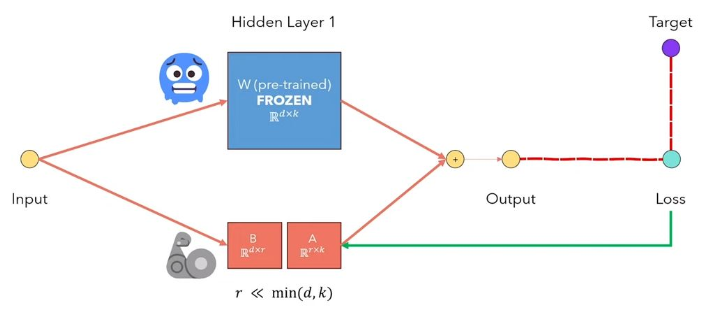
Les modèles de grandes langues sont généralement à des fins générales, moins efficaces pour les tâches spécifiques au domaine. Cependant, ils peuvent être affinés sur certaines tâches telles que l'analyse des sentiments. Pour les Taks plus complexes qui nécessitent des connaissances externes, il est possible de créer un système basé sur un modèle de langue qui accède aux sources de connaissances externes pour effectuer les tâches requises. Cela permet une plus grande précision factuelle et aide à atténuer le problème de «l'hallucination». Comme indiqué dans le Figuer ci-dessous:
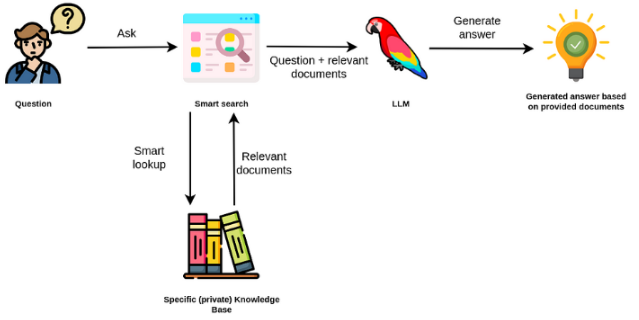
Dans ce cas, au lieu d'utiliser des LLM pour accéder à ses connaissances internes, nous utilisons le LLM comme interface en langage naturel à nos connaissances externes. La première étape consiste à convertir les documents et toutes les requêtes utilisateur en format compatible pour effectuer la recherche de pertinence (convertir le texte en vecteurs ou incorporer). L'invite utilisateur d'origine est ensuite ajoutée avec des documents pertinents / similaires dans la source de connaissances externes (comme contexte). Le modèle répond ensuite aux questions basées sur le contexte externe fourni.
Les modèles de grands langues (LLM) émergent comme une technologie transformatrice. Cependant, l'utilisation de ces LLMs isolément est souvent insuffisante pour créer des applications vraiment puissantes. Langchain vise à aider au développement de ces applications.
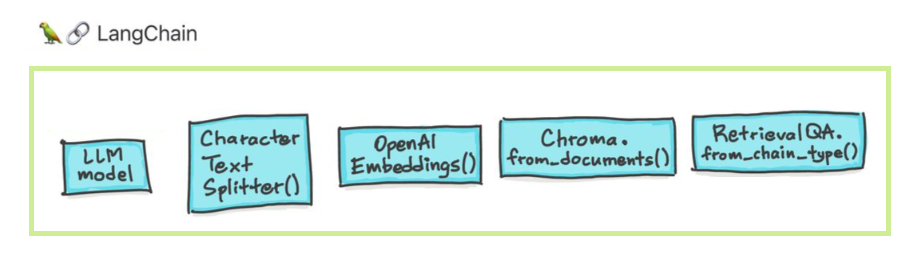
Il y a six domaines principaux avec lesquels Langchain est conçu pour aider. Ce sont, par ordre croissant de complexité:
Cela inclut une gestion rapide, une optimisation rapide, une interface générique pour tous les LLM et des utilitaires communs pour travailler avec LLMS. Les LLM et les modèles de chat sont subtilement mais surtout différents. Les LLM à Langchain se réfèrent aux modèles de complétion de texte pur. Les API qu'ils enveloppent prennent une invite de chaîne en entrée et sortent une fin de chaîne. Le GPT-3 d'OpenAI est mis en œuvre en tant que LLM. Les modèles de chat sont souvent soutenus par LLMS mais réglés spécifiquement pour avoir des conversations.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
Vous pouvez également accéder aux informations spécifiques du fournisseur qui sont renvoyées. Ces informations ne sont pas standardisées entre les prestataires.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
L'invite pour les modèles de chat est une liste de messages de chat. Chaque message de chat est associé au contenu et un paramètre supplémentaire appelé rôle. Par exemple, dans l'API Openai Chat Completion, un message de chat peut être associé à un assistant d'IA, à un rôle humain ou système.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
Les chaînes vont au-delà d'un seul appel LLM et impliquent des séquences d'appels (que ce soit à un LLM ou à un utilitaire différent). Langchain fournit une interface standard pour les chaînes, de nombreuses intégrations avec d'autres outils et des chaînes de bout en bout pour les applications courantes. La chaîne très générique peut être définie comme une séquence d'appels aux composants, qui peuvent inclure d'autres chaînes.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
La génération augmentée des données implique des types spécifiques de chaînes qui interagissent d'abord avec une source de données externe pour récupérer des données à utiliser dans l'étape de génération. Les exemples incluent la question / la réponse sur des sources de données spécifiques.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
Recherche de similitude
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
Les agents impliquent une LLM qui prend des décisions sur les actions à prendre, à prendre cette mesure, à voir une observation et à répéter cela jusqu'à ce que ce soit fait. Langchain fournit une interface standard pour les agents, une sélection d'agents à choisir et des exemples d'agents de bout en bout. L'idée principale des agents est d'utiliser un LLM pour choisir une séquence d'actions à prendre. Dans les chaînes, une séquence d'actions est codée en dur (en code). Dans les agents, un modèle de langue est utilisé comme moteur de raisonnement pour déterminer les actions à prendre et dans quel ordre.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
La mémoire fait référence à l'état persistant entre les appels d'une chaîne / agent. Langchain fournit une interface standard pour la mémoire, une collection d'implémentations de mémoire et des exemples de chaînes / agents qui utilisent la mémoire.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
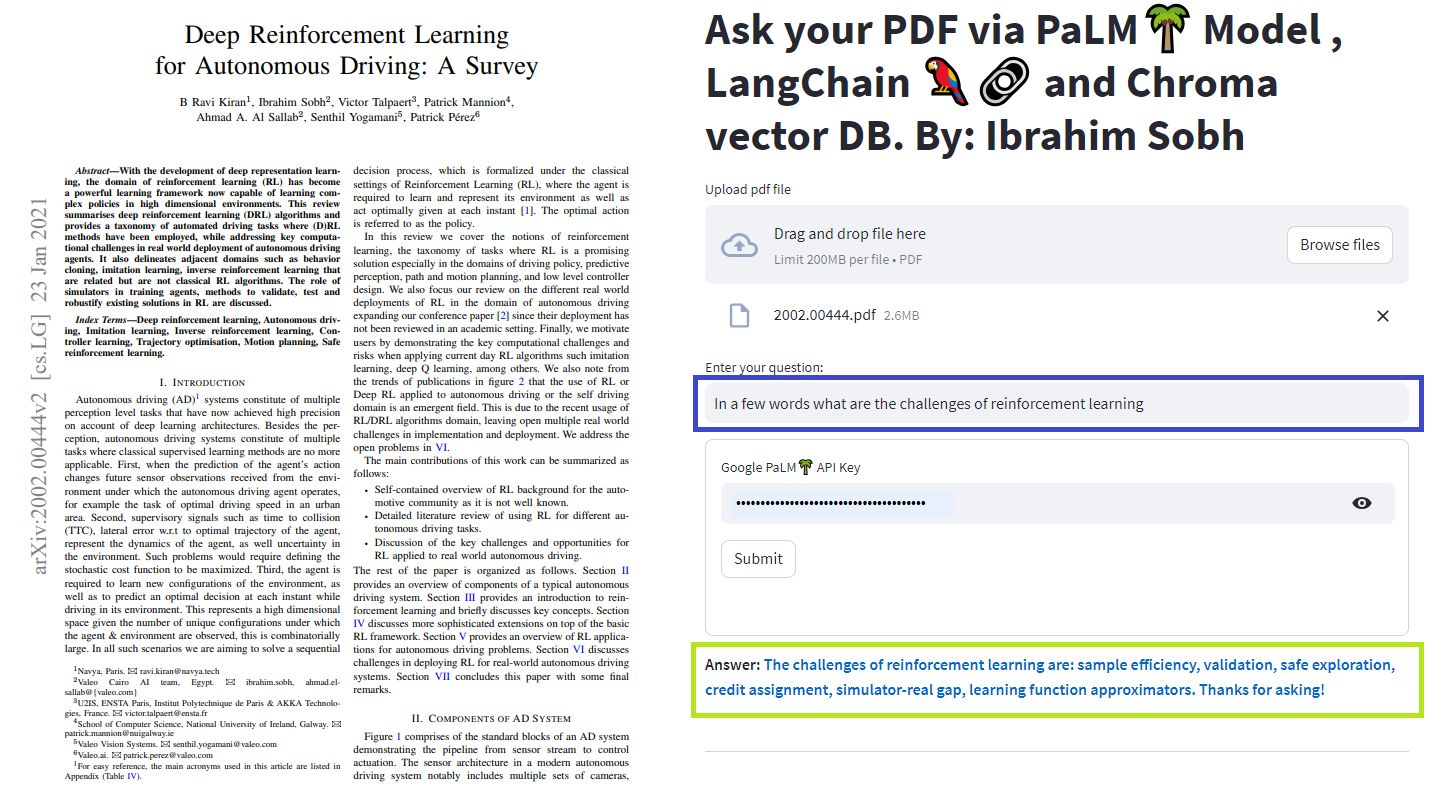
Nous pouvons utiliser différentes méthodes pour discuter avec nos documents. Pas besoin d'affiner l'ensemble du LLM, nous pouvons plutôt fournir le bon contexte avec notre question au modèle pré-formé et simplement obtenir les réponses en fonction de nos documents fournis.
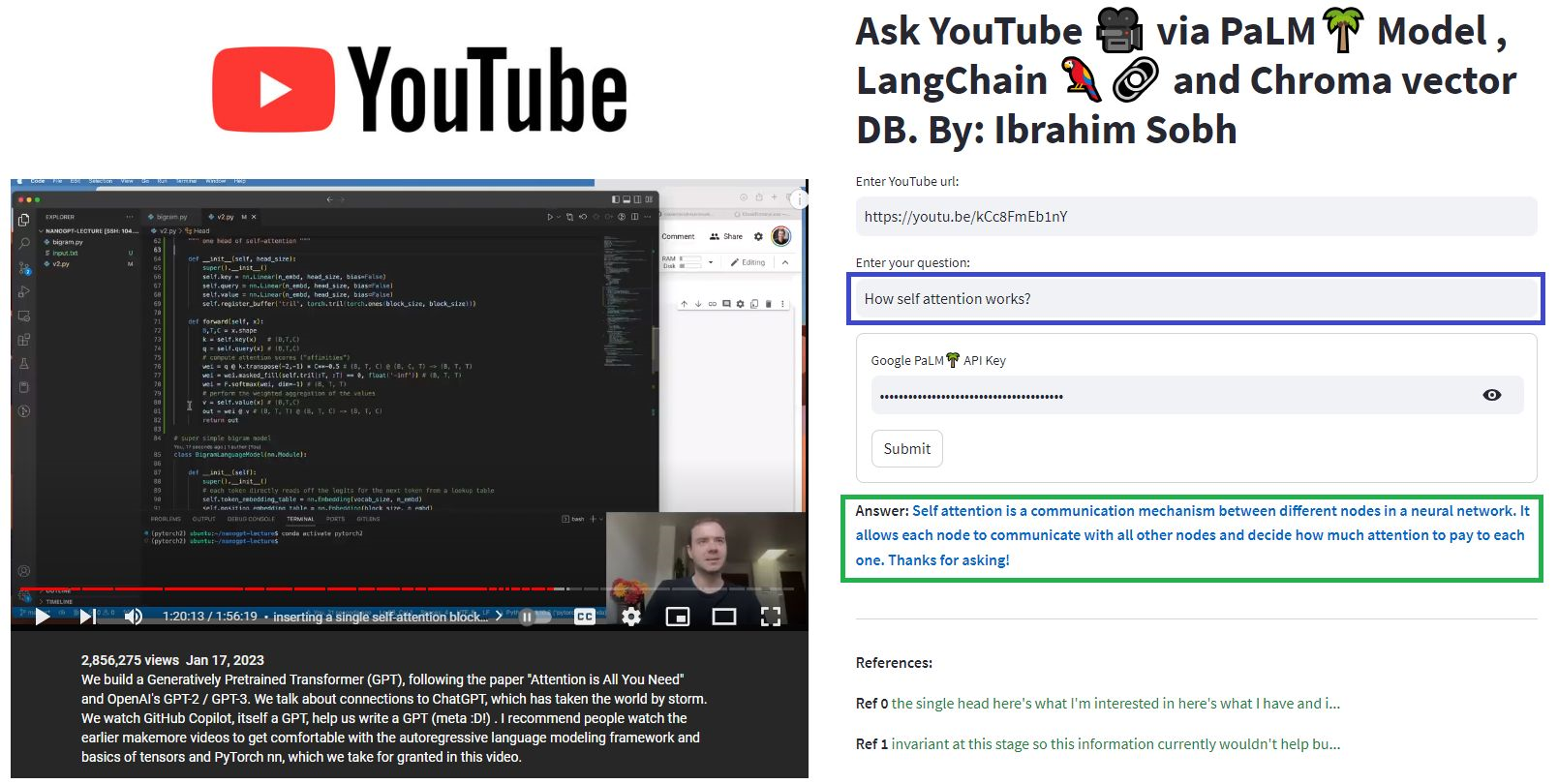
Ici, nous discutons avec ce bel article intitulé Transformers sans douleur? Poser des questions liées aux transformateurs, l'attention, le coder-décodeur, etc. tout en utilisant le puissant modèle de palme par Google et le cadre Langchain pour le développement d'applications alimentées par des modèles de langues.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
Question : ? «De quoi parlent ces documents?
Répondre : ? "Les documents concernent les transformateurs, qui sont un type de réseau neuronal qui a été utilisé avec succès dans le traitement du langage naturel et les tâches de vision par ordinateur."
Question : ? «Quelle est l'idée principale des transformateurs?
Répondre : ? «L'idée principale des transformateurs est d'utiliser des mécanismes d'attention pour modéliser les dépendances à long terme dans les séquences.»
Question : ? «Qu'est-ce que le codage positionnel?
Répondre : ? «L'encodage de position est une technique utilisée pour représenter l'ordre des mots dans une séquence.
Question : ? «Comment les vecteurs de requête, de clé et de valeur sont-ils utilisés?
Répondre : ? «Le vecteur de requête est utilisé pour calculer une somme pondérée des valeurs à travers les clés. Plus précisément: Q Dot Produit toutes les clés, puis Softmax pour obtenir des poids et enfin utiliser ces poids pour calculer une somme pondérée des valeurs.
Question : ? «Comment commencer à utiliser les transformateurs?
Répondre : ? «Pour commencer à utiliser Transformers, vous pouvez utiliser la bibliothèque de transformateurs Huggingface. Cette bibliothèque fournit des milliers de modèles pré-entraînés pour effectuer des tâches sur des textes tels que la classification, l'extraction d'informations, la réponse aux questions, le résumé, la traduction, la génération de texte, etc. dans plus de 100 langues.
Vous pouvez essayer vos propres documents et questions!
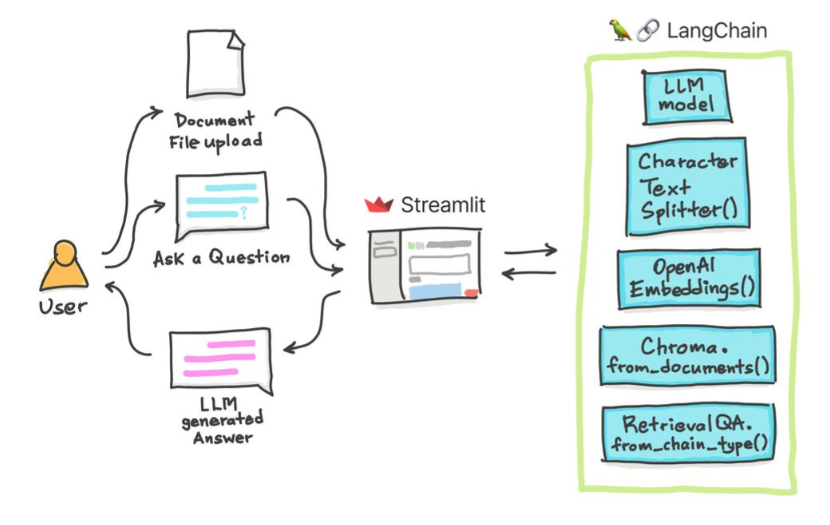
Dans ces didacticiels simples: comment obtenir des réponses à partir de documents texte , de fichiers PDF et même de vidéos YouTube à l'aide de la base de données de Vector ChroMA, Palm LLM par Google et une chaîne de réponses de questions de Langchain. Enfin, utilisez Streamlit pour développer et héberger l'application Web. Vous devrez utiliser votre Google_API_KEY (vous pouvez en obtenir un de Google). L'architecture du système est la suivante:
Il y a une différence entre l'évaluation d'un LLM par rapport à l'évaluation d'un système basé sur LLM. En règle générale, après la pré-formation générique , les LLM sont évaluées sur des repères standard:
Les systèmes LLMS peuvent résumer le texte, faire des questions, trouver le sentiment d'un texte, peut faire la traduction, etc. Sur la base du système, l'évaluation peut être la suivante:
Par exemple, en cas de réponse aux questions , nous avons besoin de paires de questions et de réponses dans notre ensemble d'évaluation. Nous pouvons utiliser des annotateurs humains pour créer manuellement des paires de questions et réponses standard. Cependant, il est coûteux et prend du temps. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
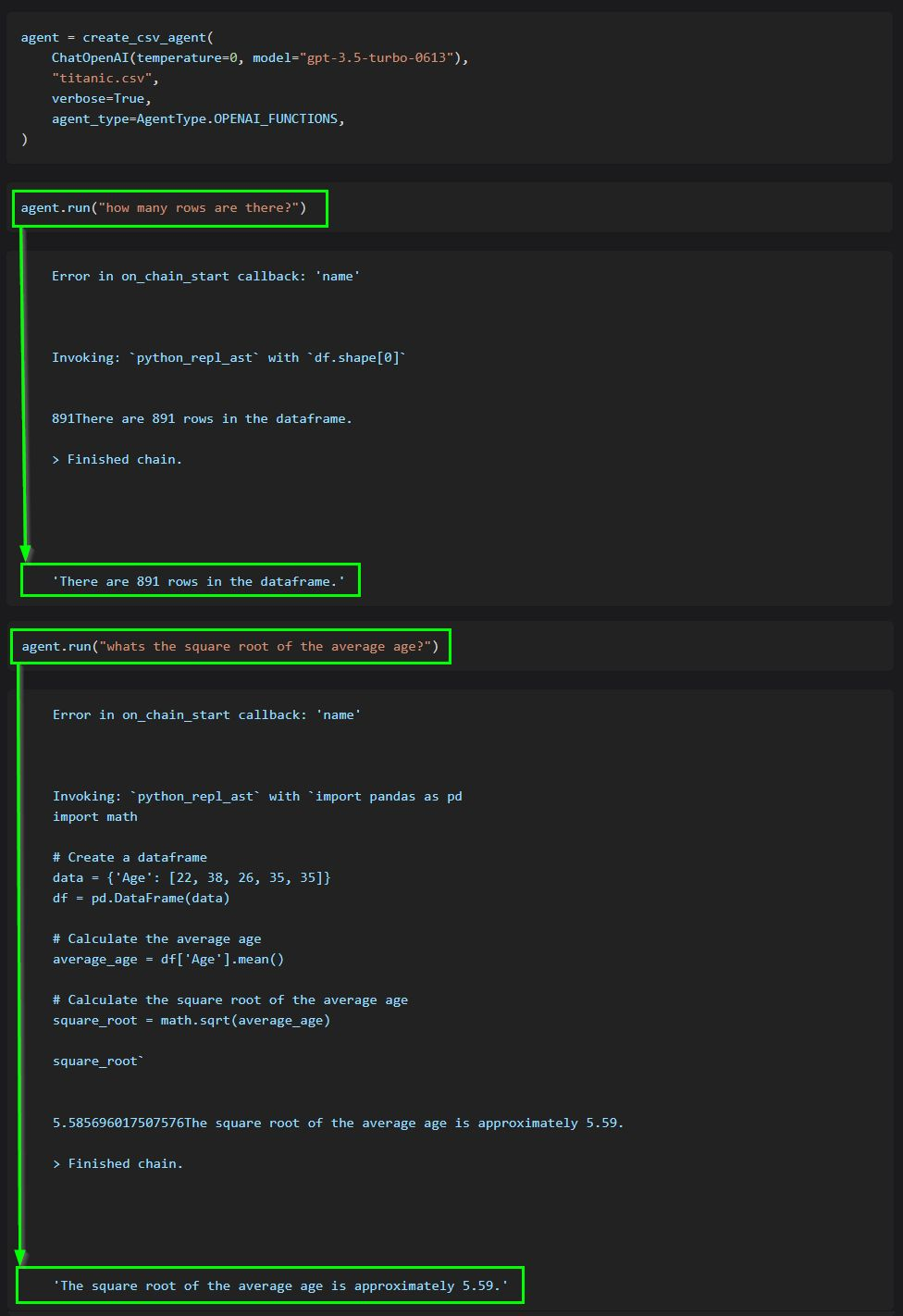
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
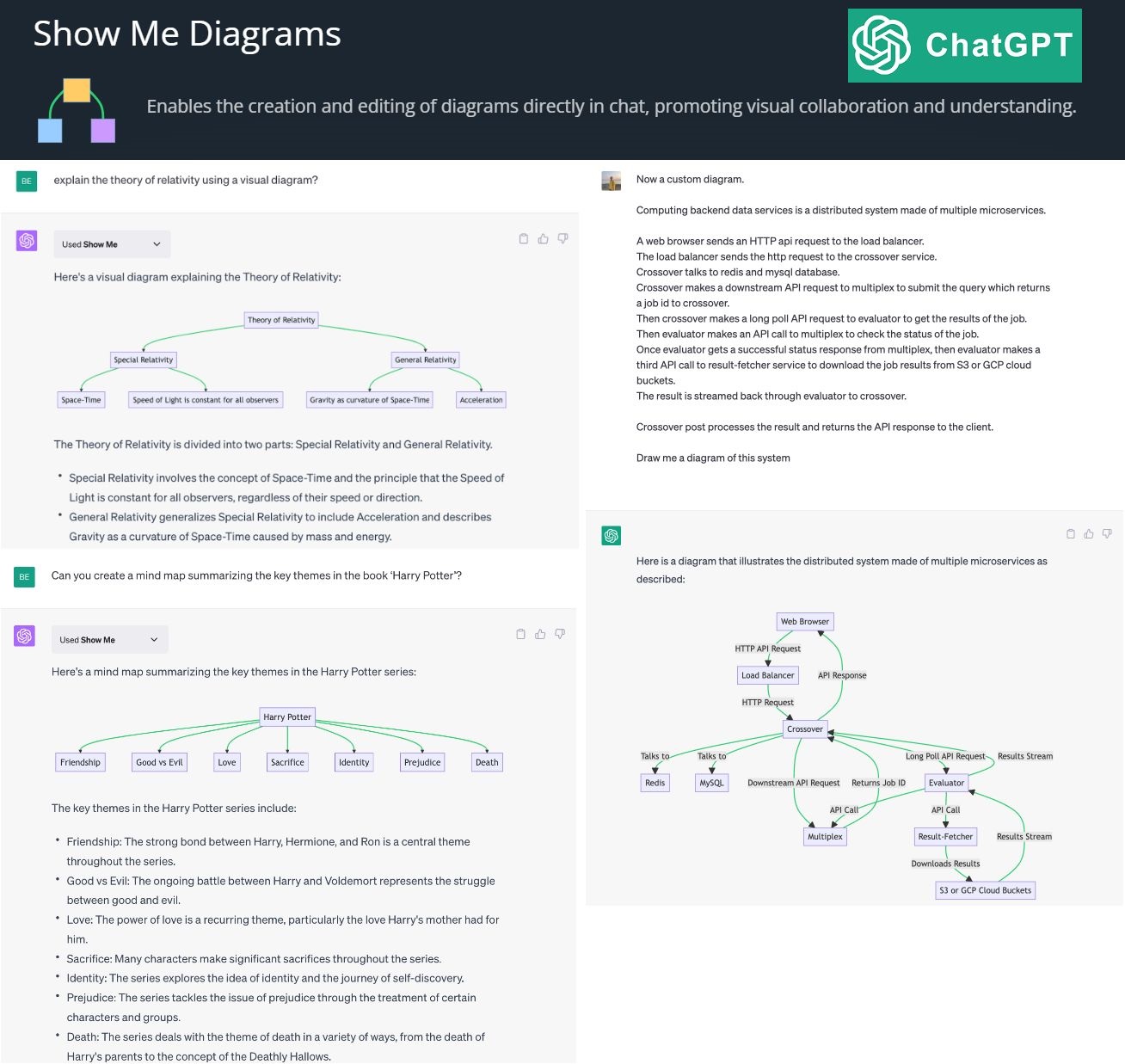
By creating and editing diagrams via Show Me Diagrams
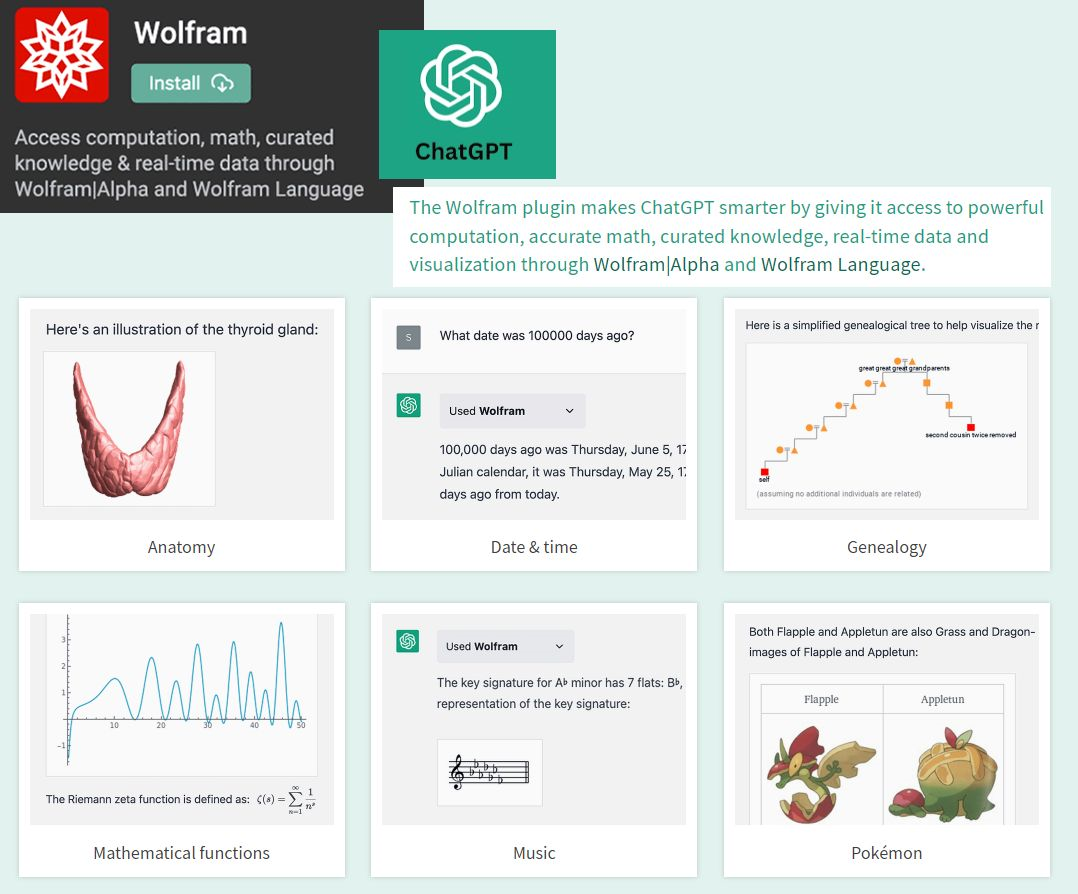
By accessing the power of mathematics provided by Wolfram
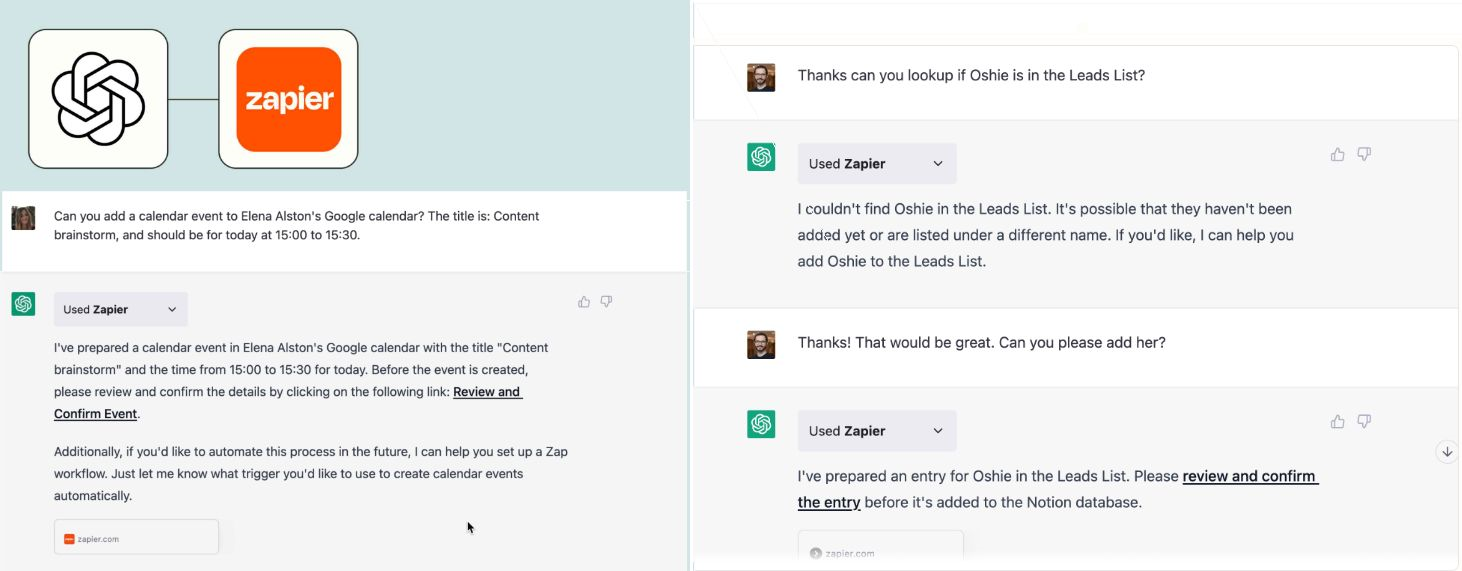
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


