llms
1.0.0
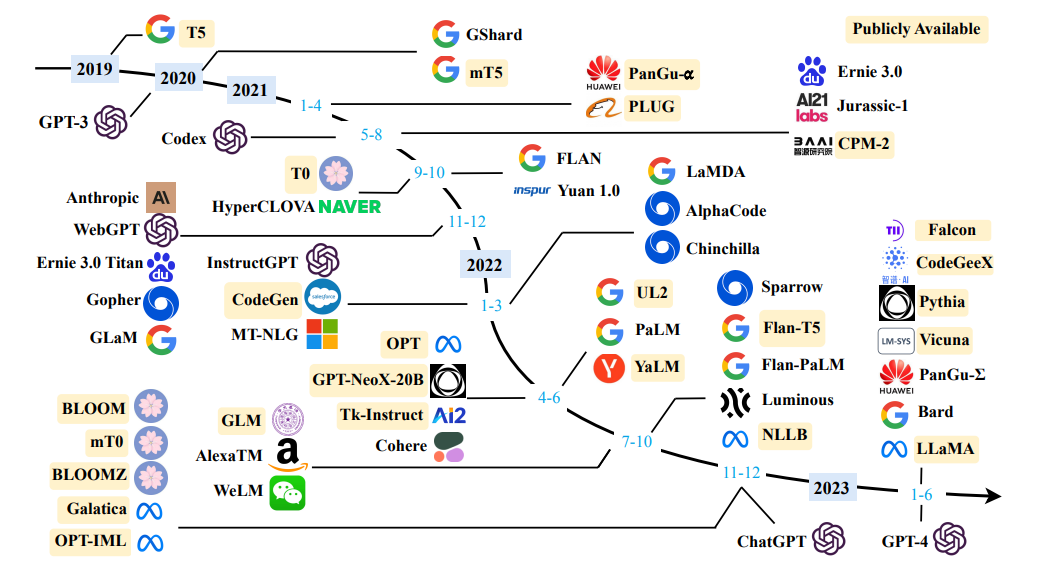 แหล่งที่มา การสำรวจแบบจำลองภาษาขนาดใหญ่
แหล่งที่มา การสำรวจแบบจำลองภาษาขนาดใหญ่
คำจำกัดความง่าย ๆ : การสร้างแบบจำลองภาษาเป็นหน้าที่ของการทำนายคำว่าคำใดต่อไป
"สุนัขกำลังเล่นอยู่ใน ... "
วัตถุประสงค์หลักของ แบบจำลองภาษา คือการกำหนดความน่าจะเป็นให้กับประโยคเพื่อแยกแยะระหว่างประโยคที่มีแนวโน้มมากขึ้นและประโยคที่มีโอกาสน้อยกว่า
สำหรับการจดจำคำพูดเราไม่เพียงใช้โมเดลอะคูสติก (สัญญาณเสียงพูด) แต่ยังเป็นแบบจำลองภาษา ในทำนองเดียวกันสำหรับการจดจำอักขระออพติคอล (OCR) เราใช้ทั้งแบบจำลองการมองเห็นและแบบจำลองภาษา แบบจำลองภาษามีความสำคัญมากสำหรับระบบการจดจำดังกล่าว
บางครั้งคุณได้ยินหรืออ่านประโยคที่ไม่ชัดเจน แต่การใช้แบบจำลองภาษาของคุณคุณยังสามารถจดจำได้ด้วยความแม่นยำสูงแม้จะมีการมองเห็น/การพูดที่มีเสียงดัง
รูปแบบภาษาคำนวณอย่างใดอย่างหนึ่งของ:
การสร้างแบบจำลองภาษาเป็นส่วนประกอบย่อยของงาน NLP จำนวนมากโดยเฉพาะอย่างยิ่งผู้ที่เกี่ยวข้องกับการสร้างข้อความหรือการประเมินความน่าจะเป็นของข้อความ
กฎโซ่:
$ P (The, Water, Is, So, Clear) = P (The) × P (น้ำ | the) × P (IS | THE, WATER) × P (SO | THE, WATER, IS) × P (ใส | น้ำ, น้ำ, ดังนั้น) $) $) $) $) $)
เกิดอะไรขึ้น? กฎโซ่ถูกนำไปใช้ในการคำนวณความน่าจะเป็นร่วมของคำในประโยค
การใช้ข้อความจำนวนมาก (คลังข้อมูลเช่น Wikipedia) เรารวบรวมสถิติเกี่ยวกับคำที่แตกต่างกันบ่อยแค่ไหนและใช้สิ่งเหล่านี้เพื่อทำนายคำต่อไป ตัวอย่างเช่นความน่าจะเป็นที่คำ W มาหลังจากคำทั้งสามนี้ นักเรียนเปิด สามารถประมาณได้ดังนี้:
ตัวอย่างข้างต้นคือโมเดล 4 กรัม และเราอาจได้รับ:
เราสามารถสรุปได้ว่าคำว่า "หนังสือ" มีความเป็นไปได้มากกว่า "รถยนต์" ในบริบทนี้
เราเพิกเฉยต่อบริบทก่อนหน้านี้ก่อน "นักเรียนเปิด"
ดังนั้นข้อความโดยพลการสามารถสร้างได้จากรูปแบบภาษาที่กำหนดคำเริ่มต้นโดยการสุ่มตัวอย่างจากการแจกแจงความน่าจะเป็นเอาต์พุตของคำถัดไปและอื่น ๆ
เราสามารถฝึก LM บนข้อความทุกประเภทจากนั้นสร้างข้อความในสไตล์นั้น (Harry Potter ฯลฯ )
เราสามารถขยายไปถึง trigrams, 4 กรัม, 5 กรัมและ N-grams
โดยทั่วไปนี่เป็นรูปแบบภาษาที่ไม่เพียงพอเนื่องจากภาษามีการพึ่งพาทางไกล อย่างไรก็ตามในทางปฏิบัติ 3,4 กรัมเหล่านี้ทำงานได้ดีสำหรับแอปพลิเคชันส่วนใหญ่
โมเดล N-Gram ของ Google เป็นของคุณ: Google Research ใช้โมเดล Word N-GRAM สำหรับโครงการ R&D ที่หลากหลาย Google N-GRAM ประมวลผล 1,024,908,267,229 คำในการเรียกใช้ข้อความและเผยแพร่จำนวนสำหรับ 1,176,470,663 ลำดับห้าคำที่ปรากฏอย่างน้อย 40 ครั้ง
จำนวนข้อความจาก LINGATIONS Consortium LDC มีดังนี้:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
ต่อไปนี้เป็นตัวอย่างของข้อมูล 4 กรัม ในคลังข้อมูลนี้:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
ตัวอย่างเช่นลำดับของสี่คำว่า "ทำหน้าที่เป็นตัวบ่งชี้" ได้รับการเห็นในคอร์ปัส 72 ครั้ง
บางครั้งเรามีข้อมูลไม่เพียงพอที่จะประเมิน การเพิ่ม n ทำให้ปัญหา Sparsity แย่ลง โดยทั่วไปแล้วเราไม่สามารถใหญ่กว่า 5 ได้
NLM มักจะใช้ RNN เพื่อเรียนรู้ลำดับของคำ (ประโยค, ย่อหน้า, … ฯลฯ ) และด้วยเหตุนี้จึงสามารถทำนายคำต่อไปได้
ข้อดี:
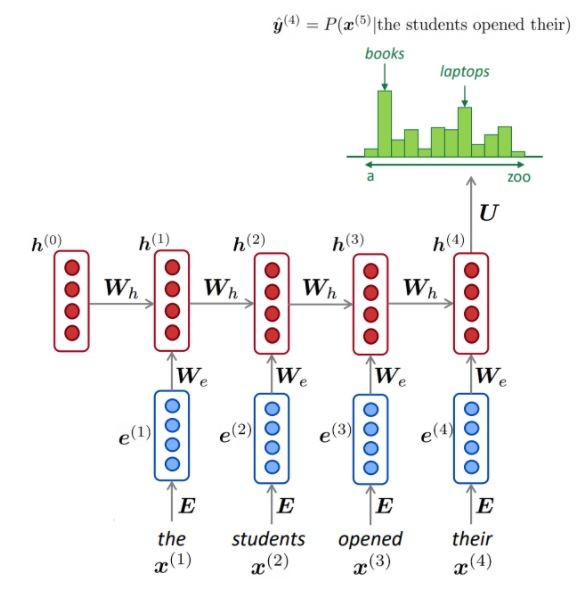
ตามที่ปรากฎในแต่ละขั้นตอนเรามีการกระจายความน่าจะเป็นของคำต่อไปผ่านคำศัพท์
การฝึกอบรม NLM:
ตัวอย่างของการเรียนรู้ลำดับยาว:
ข้อเสีย:
LM สามารถใช้ในการสร้างเงื่อนไขข้อความบนอินพุต (คำพูด, ภาพ (OCR), ข้อความ, ฯลฯ ) ในแอปพลิเคชันที่แตกต่างกันเช่น: การรู้จำเสียงการแปลการแปลของเครื่อง, การสรุป ฯลฯ
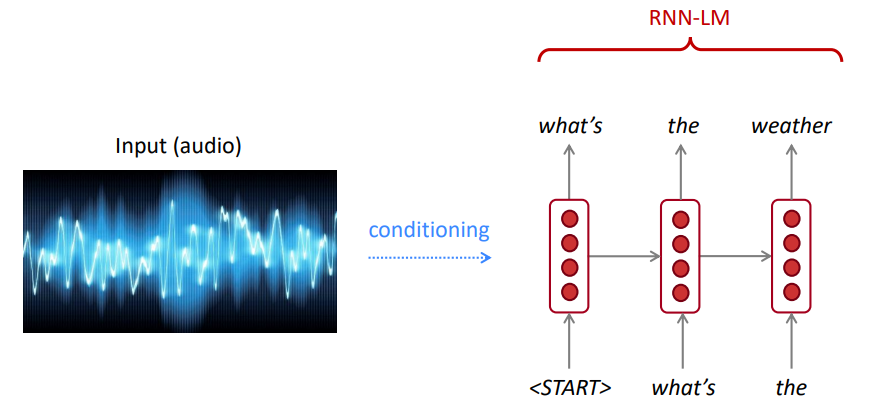
รูปแบบภาษาของเราชอบประโยคที่ดี (น่าจะเป็น) เป็นคำที่ไม่ดีหรือไม่?
ตัวชี้วัดการประเมินมาตรฐานสำหรับแบบจำลองภาษาคือความงงงวยที่น่างงงวยคือความน่าจะเป็นแบบผกผันของชุดทดสอบซึ่งเป็นมาตรฐานตามจำนวนคำ
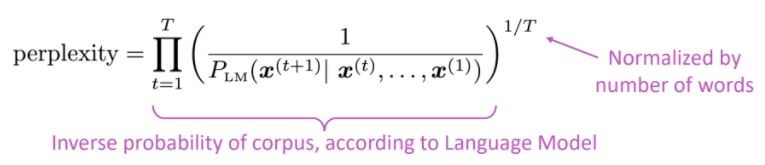
ต่ำกว่าความงุนงง = รุ่นที่ดีกว่า
ความงุนงงเกี่ยวข้องกับปัจจัยสาขา: โดยเฉลี่ยแล้วมีกี่สิ่งที่จะเกิดขึ้นต่อไป
แทนที่จะใช้ RNN ลองใช้ความสนใจมาใช้รุ่นที่ผ่านการฝึกอบรมมาก่อน
ปัญหาคืออะไร? หนึ่งในความท้าทายที่ยิ่งใหญ่ที่สุดในการประมวลผลภาษาธรรมชาติ (NLP) คือการขาดแคลนข้อมูลการฝึกอบรมสำหรับงานที่แตกต่างกันมากมาย อย่างไรก็ตามโมเดล NLP ที่ใช้การเรียนรู้ลึกสมัยใหม่ปรับปรุงเมื่อได้รับการฝึกฝนเกี่ยวกับหลายล้านหรือหลายพันล้านตัวอย่างการฝึกอบรมที่มีคำอธิบายประกอบ
การฝึกอบรมก่อนเป็นวิธีแก้ปัญหา: เพื่อช่วยปิดช่องว่างนี้มีการพัฒนาเทคนิคที่หลากหลายสำหรับการฝึกอบรมแบบจำลองการแสดงภาษาที่มีวัตถุประสงค์ทั่วไปโดยใช้ข้อความที่ไม่ได้บันทึกจำนวนมหาศาล แบบจำลองที่ผ่านการฝึกอบรมมาก่อนสามารถปรับแต่งข้อมูลขนาดเล็กสำหรับงานที่แตกต่างกันเช่นการตอบคำถามและการวิเคราะห์ความเชื่อมั่นส่งผลให้เกิดการปรับปรุงความแม่นยำอย่างมากเมื่อเทียบกับการฝึกอบรมในชุดข้อมูลเหล่านี้ตั้งแต่เริ่มต้น
สถาปัตยกรรมหม้อแปลงถูกเสนอในความสนใจของกระดาษคือสิ่งที่คุณต้องการใช้สำหรับงานแปลเครื่องประสาท (NMT) ประกอบด้วย::
ดังที่ได้กล่าวไว้ในกระดาษ:
" เราเสนอสถาปัตยกรรมเครือข่ายอย่างง่ายใหม่หม้อแปลงซึ่งใช้กลไกความสนใจเพียงอย่างเดียวการจ่ายด้วยการเกิดซ้ำและการโน้มน้าวใจทั้งหมด "
แนวคิดหลักของ ความสนใจ สามารถสรุปได้ตามที่กล่าวไว้ในบทความของ OpenAI:
" ... องค์ประกอบเอาต์พุตทุกชิ้นเชื่อมต่อกับองค์ประกอบอินพุตทุกรายการและน้ำหนักระหว่างพวกเขาจะ ถูกคำนวณแบบไดนามิกตามสถานการณ์ กระบวนการที่เรียกว่าความสนใจ "
ขึ้นอยู่กับสถาปัตยกรรมนี้ (หม้อแปลงวานิลลา!) ส่วนประกอบของ ตัวเข้ารหัสหรือตัวถอดรหัส สามารถใช้เพียงอย่างเดียวเพื่อเปิดใช้งานโมเดลทั่วไปที่ผ่านการฝึกอบรมมาก่อนซึ่งสามารถปรับแต่งได้อย่างละเอียดสำหรับงานดาวน์สตรีมเช่นการจำแนกประเภทข้อความการแปลการสรุปการตอบคำถาม ฯลฯ
โมเดลเหล่านี้เช่น Bert และ GPT ถือได้ว่าเป็น ImageNet ของ NLP
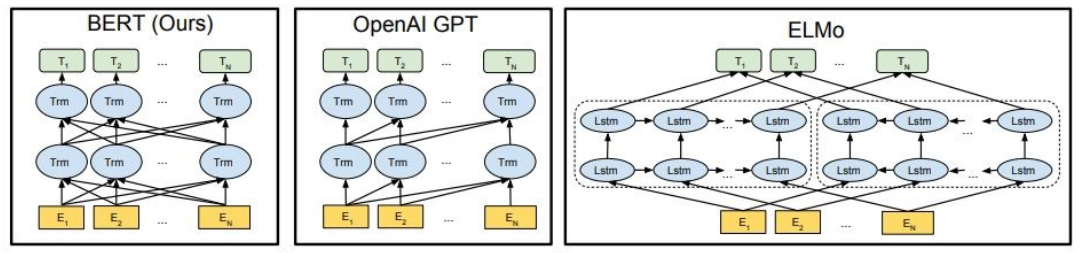
ดังที่แสดงให้เห็นว่าเบิร์ตเป็นแบบสองทิศทาง Openai GPT เป็นทิศทางเดียวและ Elmo เป็นสองทิศทางตื้น
การเป็นตัวแทนที่ผ่านการฝึกอบรมมาก่อนสามารถ:
แบบจำลองภาษาตามบริบทสามารถ:
ในส่วนนี้เราจะใช้แบบจำลองภาษาขนาดใหญ่ที่แตกต่างกัน
GPT2 (ผู้สืบทอดต่อ GPT) เป็นรูปแบบที่ผ่านการฝึกอบรมมาก่อนเกี่ยวกับภาษาอังกฤษโดยใช้วัตถุประสงค์การสร้างแบบจำลองภาษาเชิงสาเหตุ ( CLM ) ซึ่งได้รับการฝึกฝนเพียงเพื่อทำนายคำต่อไปในข้อความอินเทอร์เน็ต 40GB มันถูกปล่อยออกมาครั้งแรกในหน้านี้ GPT2 แสดงความสามารถในวงกว้างรวมถึงความสามารถในการสร้างตัวอย่างข้อความสังเคราะห์ตามเงื่อนไข ในงานภาษาเช่นการตอบคำถามการอ่านความเข้าใจการสรุปและการแปล GPT2 เริ่ม เรียนรู้งานเหล่านี้จากข้อความดิบโดยไม่ต้องใช้ข้อมูลการฝึกอบรมเฉพาะงาน DistilGPT2 เป็นรุ่นกลั่นของ GPT2 มันมีจุดประสงค์เพื่อใช้สำหรับกรณีการใช้งานที่คล้ายกันกับฟังก์ชั่นที่เพิ่มขึ้นของการใช้งานที่เล็กลงและทำงานง่ายกว่ารุ่นฐาน
ที่นี่เราโหลดรุ่น GPT2 ที่ผ่านการฝึกอบรมมาก่อนขอให้โมเดล GPT2 ดำเนินการต่อข้อความอินพุตของเรา (พรอมต์) และในที่สุดก็แยกคุณสมบัติฝังตัวจากรุ่น DistilGPT2
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
เบิร์ตเป็นรุ่นหม้อแปลงที่ได้รับการฝึกฝนไว้ล่วงหน้าบนคลังข้อมูลภาษาอังกฤษขนาดใหญ่ในรูปแบบที่ดูแลตนเอง ซึ่งหมายความว่ามันได้รับการฝึกอบรมล่วงหน้าในตำราดิบเท่านั้นโดยไม่มีมนุษย์ติดฉลากพวกเขาในทางใดทางหนึ่งด้วยกระบวนการอัตโนมัติเพื่อสร้างอินพุตและฉลากจากข้อความเหล่านั้น แม่นยำยิ่งขึ้นมันได้รับการปรับแต่งด้วยวัตถุประสงค์สองประการ:
ในตัวอย่างนี้เราจะใช้แบบจำลอง Bert ที่ผ่านการฝึกอบรมมาก่อนสำหรับงานวิเคราะห์ความเชื่อมั่น
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4ALL เป็นระบบนิเวศในการฝึกอบรมและปรับใช้โมเดลภาษาขนาดใหญ่ที่ทรงพลังและปรับแต่งซึ่งทำงานในท้องถิ่นบนซีพียูเกรดผู้บริโภค
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
ลองใช้รุ่นต่อไปนี้:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM เป็นซีรี่ส์ชุดภาษาขนาดใหญ่ของ TII ซึ่งสร้างขึ้นจากศูนย์โดยใช้ไปป์ไลน์ข้อมูลที่กำหนดเองและการฝึกอบรมแบบกระจาย โมเดล Falcon-7b/40b นั้นล้ำสมัยสำหรับขนาดของพวกเขาซึ่งมีประสิทธิภาพสูงกว่ารุ่นอื่น ๆ ส่วนใหญ่ในเกณฑ์มาตรฐาน NLP เปิดแหล่งข้อมูลจำนวนมาก:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
LLAMA2 เป็นครอบครัวที่มีรูปแบบภาษาขนาดใหญ่ที่ล้ำสมัยที่เปิดตัวโดย Meta Today และเรารู้สึกตื่นเต้นที่จะสนับสนุนการเปิดตัวอย่างเต็มที่ด้วยการรวมเข้าด้วยกันในการกอดใบหน้า Llama 2 กำลังได้รับการปล่อยตัวด้วยใบอนุญาตชุมชนที่ได้รับอนุญาตมากและสามารถใช้งานได้ในเชิงพาณิชย์ รหัสโมเดลที่ผ่านการฝึกอบรมและรุ่นที่ปรับแต่งทั้งหมดได้รับการปล่อยตัวในวันนี้
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
Codet5+ เป็นตระกูลใหม่ของรหัสเปิดแบบจำลองภาษาขนาดใหญ่ที่มีสถาปัตยกรรมเครื่องเข้ารหัสที่สามารถทำงานได้อย่างยืดหยุ่นในโหมดที่แตกต่างกัน (เช่นเข้ารหัสอย่างเดียวตัวถอดรหัสเท่านั้นและตัวเข้ารหัสตัวพิมพ์) เพื่อรองรับการทำความเข้าใจรหัสและงานสร้างที่หลากหลาย
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
สำหรับรุ่นเพิ่มเติมให้ตรวจสอบ codetf จาก Salesforce ซึ่งเป็นไลบรารีที่ใช้ Python Transformer สำหรับรหัสโมเดลภาษาขนาดใหญ่ (รหัส LLMS) และรหัสข่าวกรองซึ่งให้อินเทอร์เฟซที่ราบรื่นสำหรับการฝึกอบรมและการอนุมานเกี่ยวกับงานข่าวกรองรหัสเช่นการสรุปรหัสการแปลการสร้างรหัสและอื่น ๆ
? ️แชทกับโมเดลภาษาขนาดใหญ่แบบเปิด
✅การค้นหาลำแสงมักจะพบลำดับผลลัพธ์ที่มีความน่าจะเป็นสูงกว่าการค้นหาโลภ แต่ไม่รับประกันว่าจะหาเอาต์พุตที่เป็นไปได้มากที่สุด
ในหม้อแปลงเราเพียงแค่ตั้งค่าพารามิเตอร์ num_return_equences เป็นจำนวนคานที่ให้คะแนนสูงสุดที่ควรส่งคืน ตรวจสอบให้แน่ใจว่า num_return_equences <= num_beams!
✅การค้นหาลำแสงสามารถทำงานได้ดีมากในงานที่ความยาวของรุ่นที่ต้องการสามารถคาดเดาได้มากหรือน้อยเช่นเดียวกับในการแปลหรือการสรุปของเครื่อง แต่นี่ไม่ใช่กรณีของรุ่นปลายเปิดที่ความยาวเอาต์พุตที่ต้องการสามารถแตกต่างกันอย่างมากเช่นกล่องโต้ตอบและการสร้างเรื่องราว การค้นหาลำแสงอย่างหนักจากการสร้างซ้ำ ในฐานะมนุษย์เราต้องการข้อความที่สร้างขึ้นเพื่อทำให้เราประหลาดใจและไม่น่าเบื่อ/คาดเดาได้ (? การค้นหาลำแสงนั้นน่าแปลกใจน้อยกว่า)
ใน Transformers เราตั้งค่า do_sample = true และปิดการสุ่มตัวอย่าง top-k (เพิ่มเติมในภายหลัง) ผ่าน top_k = 0
- ????????: K คำพูดต่อไปที่มีแนวโน้มมากที่สุดจะถูกกรองและมวลความน่าจะเป็นถูกแจกจ่ายซ้ำในคำต่อไปของ K เท่านั้น GPT2 นำรูปแบบการสุ่มตัวอย่างนี้มาใช้
- ? มวลความน่าจะเป็นจะถูกแจกจ่ายซ้ำในชุดคำนี้ เมื่อมีการตั้งค่า p = 0.92 การสุ่มตัวอย่างด้านบนจะเลือกจำนวนคำขั้นต่ำที่เกิน 92% ของมวลความน่าจะเป็น
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ในขณะที่ Top-P ดูสง่างามกว่า Top-K แต่ทั้งสองวิธีทำงานได้ดีในทางปฏิบัติ Top-P สามารถใช้ร่วมกับ Top-K ซึ่งสามารถหลีกเลี่ยงคำที่อยู่ในอันดับต่ำมากในขณะที่อนุญาตให้เลือกแบบไดนามิก
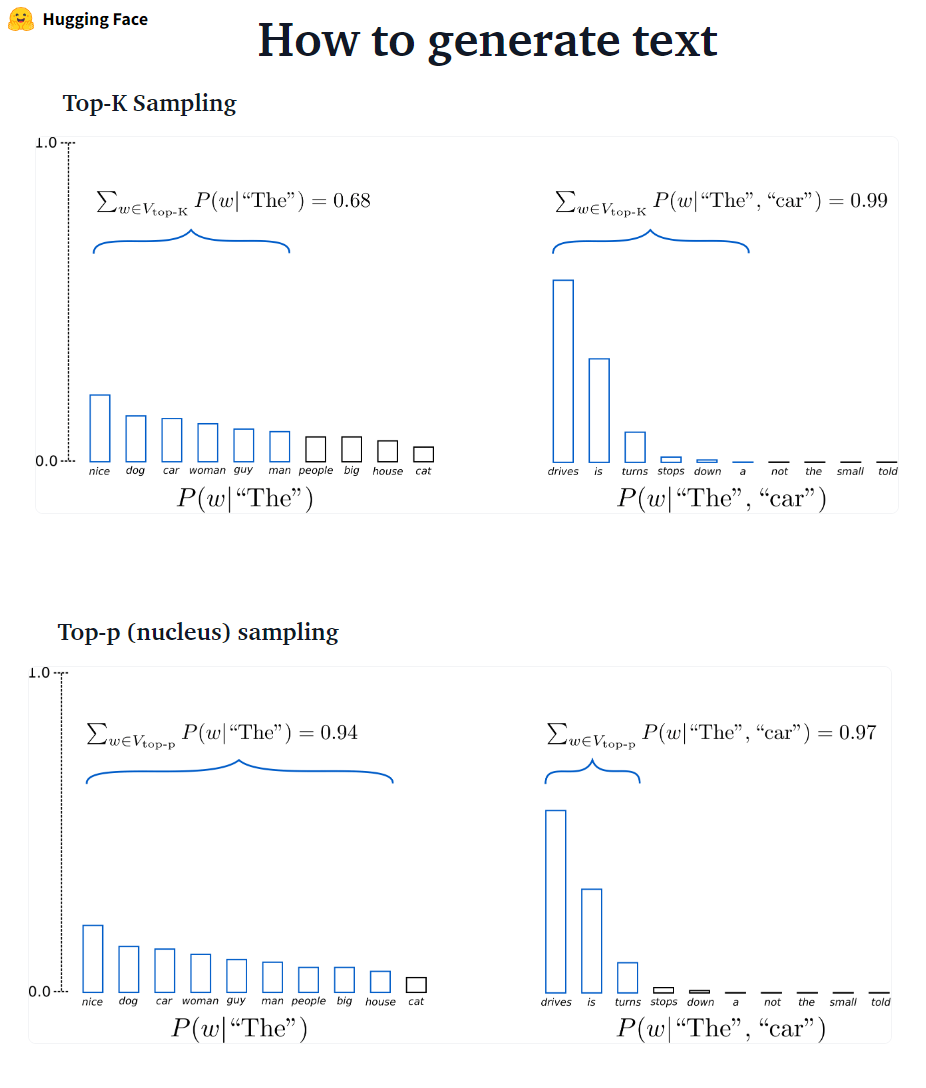
✅เป็นวิธีการถอดรหัสแบบ Ad-Hoc การสุ่มตัวอย่าง Top-P และ Top-K ดูเหมือนจะสร้างข้อความที่คล่องแคล่วมากกว่าโลภแบบดั้งเดิม-และการค้นหาลำแสงในการสร้างภาษาปลายเปิด
วิศวกรรมพรอมต์ เป็นกระบวนการออกแบบพรอมต์ (อินพุตข้อความ) สำหรับแบบจำลองภาษาเพื่อสร้างผลลัพธ์ที่จำเป็น วิศวกรรมที่รวดเร็วเกี่ยวข้องกับการเลือกคำหลักที่เหมาะสมการให้บริบทมีความชัดเจนและเฉพาะเจาะจงในวิธีที่นำพฤติกรรมของโมเดลภาษาที่บรรลุการตอบสนองที่ต้องการ ผ่านวิศวกรรมที่รวดเร็วเราสามารถควบคุมน้ำเสียงสไตล์ความยาว ฯลฯ ได้โดยไม่ต้องปรับแต่ง
การเรียนรู้แบบไม่มี-ช็อต เกี่ยวข้องกับการขอให้แบบจำลองการคาดการณ์โดยไม่ต้องให้ตัวอย่างใด ๆ (ศูนย์ช็อต) ตัวอย่างเช่น:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
เมื่อ Zero-shot ไม่ดีพอขอแนะนำให้ช่วยโมเดลโดยให้ตัวอย่างในพรอมต์ซึ่งนำไปสู่การกระตุ้นด้วยการยิงไม่กี่ครั้ง
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
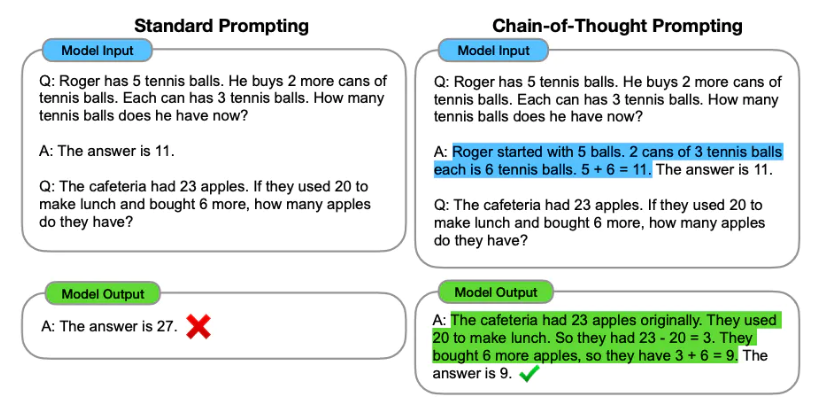
นอกเหนือจาก วิศวกรรมที่รวดเร็ว เราอาจพิจารณาตัวเลือกเพิ่มเติม:
สำหรับข้อมูลทางวิศวกรรมที่รวดเร็วเพิ่มเติมโปรดดูคู่มือวิศวกรรมที่รวดเร็วซึ่งมีเอกสารล่าสุดทั้งหมดคำแนะนำการเรียนรู้การบรรยายการอ้างอิงและเครื่องมือ
การปรับแต่ง LLMS ในชุดข้อมูลดาวน์สตรีมส่งผลให้ประสิทธิภาพเพิ่มขึ้นอย่างมากเมื่อเปรียบเทียบกับการใช้ LLMs ที่ได้รับการฝึกฝนไว้นอกกรอบ (การอนุมานแบบศูนย์ช็อตเป็นต้น) อย่างไรก็ตามเมื่อโมเดลมีขนาดใหญ่ขึ้นเรื่อย ๆ การปรับแต่งอย่างเต็มที่จะไม่สามารถฝึกฮาร์ดแวร์ผู้บริโภคได้ นอกจากนี้การจัดเก็บและปรับใช้โมเดลที่ปรับแต่งอย่างอิสระอย่างอิสระสำหรับงานดาวน์สตรีมแต่ละงานมีราคาแพงมากเนื่องจากรุ่นที่ปรับจูนมีขนาดเท่ากันกับแบบจำลองดั้งเดิม วิธีการปรับแต่งพารามิเตอร์-ประสิทธิภาพ (PEFT) มีไว้เพื่อแก้ไขปัญหาทั้งสอง! แนวทาง PEFT ช่วยให้คุณได้รับประสิทธิภาพเทียบเคียงได้กับการปรับแต่งแบบเต็มในขณะที่มีพารามิเตอร์ฝึกอบรมจำนวนน้อยเท่านั้น ตัวอย่างเช่น:
การปรับจูนการปรับแต่ง: กลไกที่เรียบง่าย แต่มีประสิทธิภาพสำหรับการเรียนรู้ เช่นเดียวกับข้อความที่ได้รับการออกแบบทางวิศวกรรมการแจ้งเตือนแบบนุ่มนวลจะถูกเชื่อมต่อกับข้อความอินพุต แต่แทนที่จะเลือกจากรายการคำศัพท์ที่มีอยู่“ โทเค็น” ของพรอมต์ซอฟต์เป็นเวกเตอร์ที่เรียนรู้ได้ ซึ่งหมายความว่าพรอมต์ซอฟท์สามารถปรับให้เหมาะสมกับ end-to-end ผ่านชุดข้อมูลการฝึกอบรมดังที่แสดงด้านล่าง: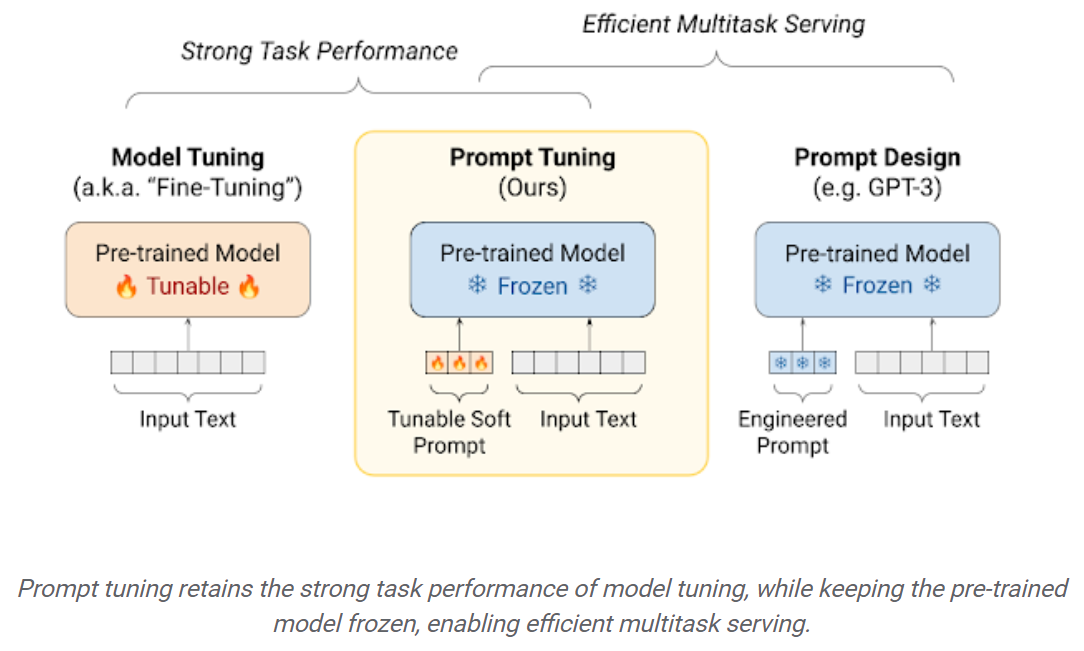
LORA การปรับระดับต่ำของ LLMS เป็นวิธีที่ค้างน้ำหนักแบบจำลองที่ผ่านการฝึกอบรมและฉีดเมทริกซ์การสลายตัวของอันดับฝึกอบรมได้ในแต่ละชั้นของสถาปัตยกรรมหม้อแปลง ลดจำนวนพารามิเตอร์ที่สามารถฝึกอบรมได้อย่างมากสำหรับงานดาวน์สตรีม รูปด้านล่างจากวิดีโอนี้อธิบายแนวคิดหลัก: 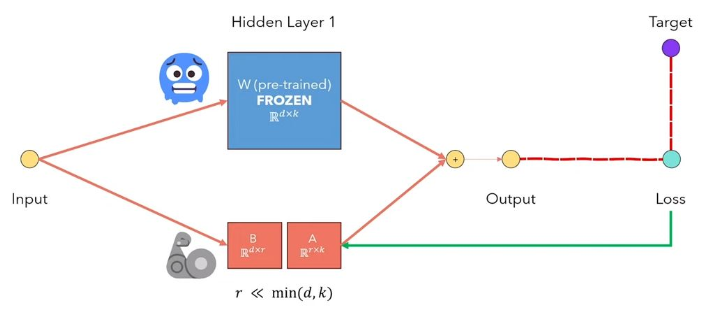
แบบจำลองภาษาขนาดใหญ่มักจะมีวัตถุประสงค์ทั่วไปมีประสิทธิภาพน้อยกว่าสำหรับงานเฉพาะโดเมน อย่างไรก็ตามพวกเขาสามารถปรับแต่งได้อย่างละเอียดในงานบางอย่างเช่นการวิเคราะห์ความเชื่อมั่น สำหรับ TAK ที่ซับซ้อนมากขึ้นที่ต้องการความรู้ภายนอกเป็นไปได้ที่จะสร้างระบบแบบจำลองภาษาที่เข้าถึงแหล่งความรู้ภายนอกเพื่อให้งานที่จำเป็นเสร็จสมบูรณ์ สิ่งนี้ช่วยให้เกิดความแม่นยำมากขึ้นและช่วยลดปัญหาของ "ภาพหลอน" ดังที่แสดงใน figuer ด้านล่าง:
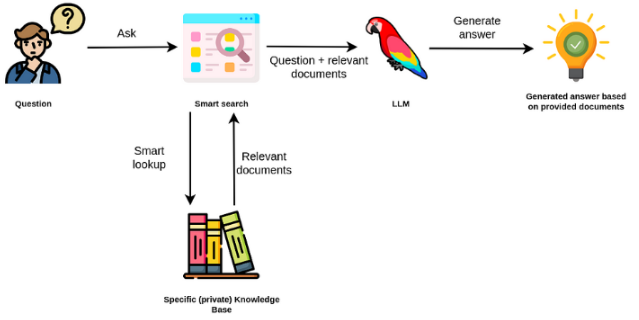
ในกรณีนี้แทนที่จะใช้ LLM เพื่อเข้าถึงความรู้ภายในเราใช้ LLM เป็นอินเทอร์เฟซภาษาธรรมชาติกับความรู้ภายนอกของเรา ขั้นตอนแรกคือการแปลงเอกสารและการสืบค้นผู้ใช้ใด ๆ เป็นรูปแบบที่เข้ากันได้เพื่อทำการค้นหาที่เกี่ยวข้อง (แปลงข้อความเป็นเวกเตอร์หรือฝังตัว) จากนั้นพรอมต์ผู้ใช้ดั้งเดิมจะถูกผนวกเข้ากับเอกสารที่เกี่ยวข้อง / คล้ายกันภายในแหล่งความรู้ภายนอก (เป็นบริบท) จากนั้นโมเดลจะตอบคำถามตามบริบทภายนอกที่ให้ไว้
โมเดลภาษาขนาดใหญ่ (LLMS) กำลังเกิดขึ้นเป็นเทคโนโลยีการเปลี่ยนแปลง อย่างไรก็ตามการใช้ LLMs เหล่านี้ในการแยกมักจะไม่เพียงพอสำหรับการสร้างแอพพลิเคชั่นที่ทรงพลังอย่างแท้จริง Langchain มีเป้าหมายที่จะช่วยในการพัฒนาแอปพลิเคชันดังกล่าว
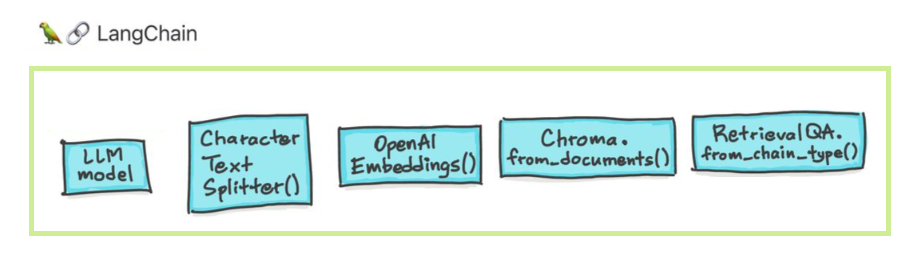
มีหกพื้นที่หลักที่ Langchain ออกแบบมาเพื่อช่วยเหลือ เหล่านี้คือการเพิ่มลำดับความซับซ้อน:
ซึ่งรวมถึงการจัดการที่รวดเร็วการเพิ่มประสิทธิภาพที่รวดเร็ว, อินเทอร์เฟซทั่วไปสำหรับ LLM ทั้งหมดและยูทิลิตี้ทั่วไปสำหรับการทำงานกับ LLMS LLMS และโมเดลแชท มีความละเอียด แต่แตกต่างกันอย่างมาก LLMs ใน Langchain อ้างถึงโมเดลการเติมข้อความบริสุทธิ์ APIs ที่พวกเขาห่อใช้พรอมต์สตริงเป็นอินพุตและเอาต์พุตการเสร็จสิ้นสตริง GPT-3 ของ Openai ถูกนำมาใช้เป็น LLM โมเดลแชทมักได้รับการสนับสนุนจาก LLM แต่ปรับโดยเฉพาะสำหรับการสนทนา
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
คุณยังสามารถเข้าถึงข้อมูลเฉพาะของผู้ให้บริการที่ส่งคืน ข้อมูลนี้ไม่ได้มาตรฐานในผู้ให้บริการ
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
พรอมต์สำหรับโมเดลแชทคือรายการข้อความแชท ข้อความแชทแต่ละรายการเกี่ยวข้องกับเนื้อหาและพารามิเตอร์เพิ่มเติมที่เรียกว่าบทบาท ตัวอย่างเช่นใน API OpenAI CHAT API ข้อความแชทสามารถเชื่อมโยงกับผู้ช่วย AI, มนุษย์หรือบทบาทของระบบ
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
โซ่เกินกว่าการเรียก LLM เดียวและเกี่ยวข้องกับลำดับของการโทร (ไม่ว่าจะเป็น LLM หรือยูทิลิตี้อื่น) Langchain จัดเตรียมอินเทอร์เฟซมาตรฐานสำหรับโซ่การรวมเข้ากับเครื่องมืออื่น ๆ และโซ่แบบครบวงจรสำหรับแอปพลิเคชันทั่วไป ห่วงโซ่โดยทั่วไปสามารถกำหนดเป็นลำดับของการโทรไปยังส่วนประกอบซึ่งอาจรวมถึงโซ่อื่น ๆ
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
การสร้างข้อมูลเพิ่มเติมเกี่ยวข้องกับโซ่เฉพาะประเภทที่โต้ตอบกับแหล่งข้อมูลภายนอกเป็นครั้งแรกเพื่อดึงข้อมูลเพื่อใช้ในขั้นตอนการสร้าง ตัวอย่างรวมถึงคำถาม/การตอบคำถามที่เฉพาะเจาะจง
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
การค้นหาความคล้ายคลึงกัน
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
ตัวแทนเกี่ยวข้องกับการตัดสินใจ LLM เกี่ยวกับการกระทำใดที่จะดำเนินการนั้นเห็นการสังเกตและการทำซ้ำจนกว่าจะเสร็จสิ้น Langchain จัดเตรียมอินเทอร์เฟซมาตรฐานสำหรับตัวแทนการเลือกตัวแทนให้เลือกและตัวอย่างของตัวแทน end-to-end แนวคิดหลักของตัวแทนคือการใช้ LLM เพื่อเลือกลำดับของการกระทำที่จะดำเนินการ ในโซ่ลำดับของการกระทำจะถูกบันทึกไว้ (ในรหัส) ในตัวแทนรูปแบบภาษาถูกใช้เป็นเอ็นจิ้นให้เหตุผลเพื่อพิจารณาว่าการกระทำใดที่จะดำเนินการและลำดับใด
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
หน่วยความจำหมายถึงสถานะการคงอยู่ระหว่างการเรียกโซ่/เอเจนต์ Langchain จัดเตรียมอินเทอร์เฟซมาตรฐานสำหรับหน่วยความจำการรวบรวมการใช้งานหน่วยความจำและตัวอย่างของโซ่/ตัวแทนที่ใช้หน่วยความจำ
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
เราสามารถใช้วิธีการต่าง ๆ เพื่อแชทกับเอกสารของเรา ไม่จำเป็นต้องปรับแต่ง LLM ทั้งหมด แต่เราสามารถให้บริบทที่ถูกต้องพร้อมกับคำถามของเรากับโมเดลที่ผ่านการฝึกอบรมมาก่อนและได้รับคำตอบตามเอกสารที่เราให้ไว้
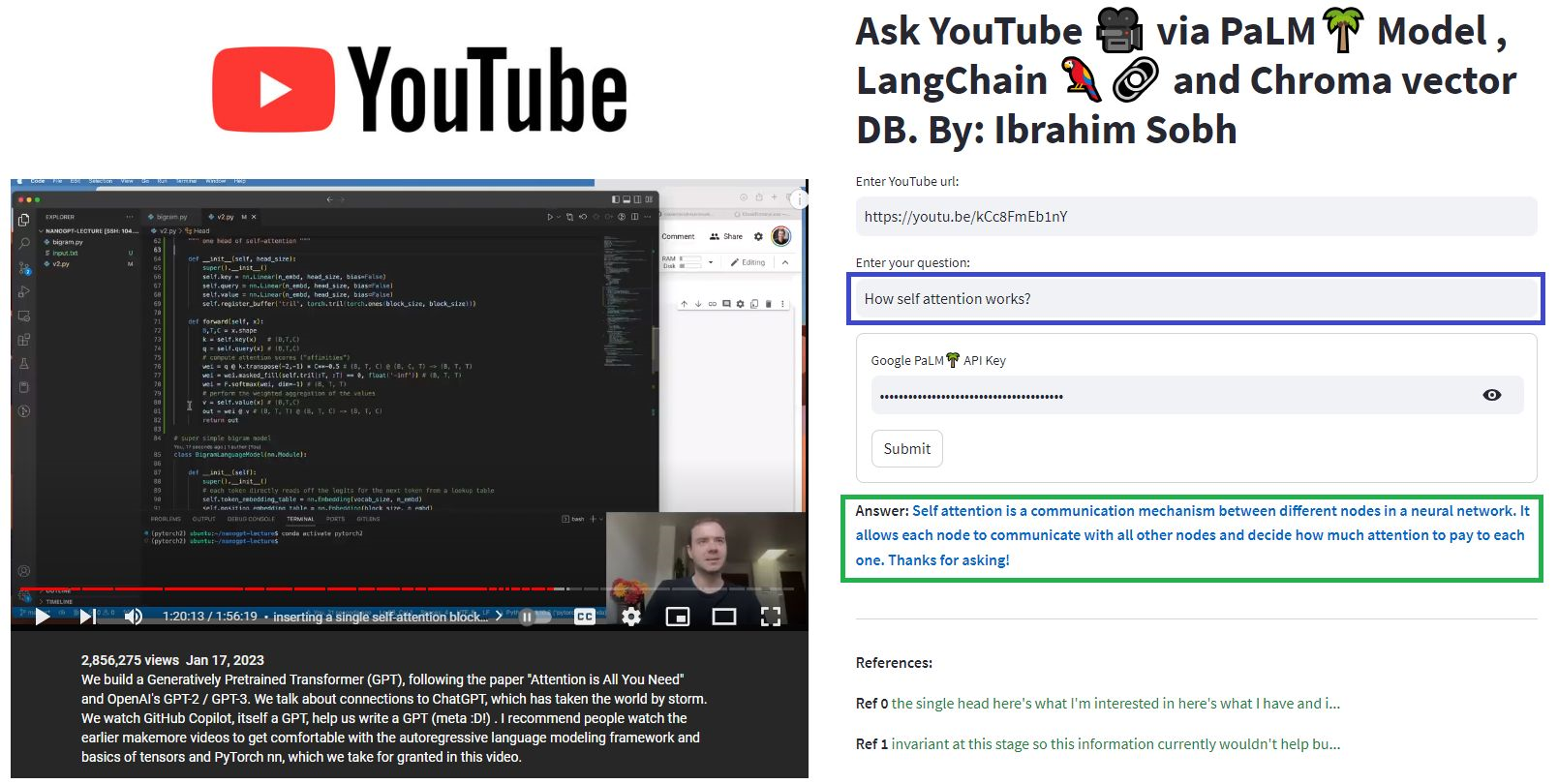
ที่นี่เราแชทกับบทความดีๆนี้ชื่อว่า Transformers โดยไม่มีความเจ็บปวด? การถามคำถามที่เกี่ยวข้องกับหม้อแปลงความสนใจตัวเข้ารหัส ฯลฯ ในขณะที่ใช้โมเดลปาล์มที่ทรงพลังโดย Google และกรอบ Langchain สำหรับการพัฒนาแอพพลิเคชั่นที่ขับเคลื่อนด้วยโมเดลภาษา
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
คำถาม : ? 'เอกสารเหล่านี้เกี่ยวกับอะไร?'
คำตอบ : ? 'เอกสารเป็นเรื่องเกี่ยวกับหม้อแปลงซึ่งเป็นเครือข่ายประสาทชนิดหนึ่งที่ใช้งานได้สำเร็จในการประมวลผลภาษาธรรมชาติและงานวิสัยทัศน์คอมพิวเตอร์'
คำถาม : ? 'แนวคิดหลักของ Transformers คืออะไร'
คำตอบ : ? 'แนวคิดหลักของหม้อแปลงคือการใช้กลไกความสนใจในการจำลองการพึ่งพาระยะยาวในลำดับ'
คำถาม : ? 'การเข้ารหัสตำแหน่งคืออะไร?'
คำตอบ : ? 'การเข้ารหัสตำแหน่งเป็นเทคนิคที่ใช้ในการแสดงลำดับของคำในลำดับ'
คำถาม : ? 'ใช้เวกเตอร์แบบสอบถามคีย์และค่าอย่างไร?'
คำตอบ : ? 'เวกเตอร์แบบสอบถามใช้เพื่อคำนวณผลรวมถ่วงน้ำหนักของค่าผ่านปุ่ม โดยเฉพาะ: Q DOT ผลิตภัณฑ์คีย์ทั้งหมดจากนั้น softmax เพื่อรับน้ำหนักและใช้น้ำหนักเหล่านี้ในที่สุดเพื่อคำนวณผลรวมถ่วงน้ำหนักของค่า '
คำถาม : ? 'จะเริ่มใช้ Transformers ได้อย่างไร'
คำตอบ : ? 'ในการเริ่มใช้หม้อแปลงคุณสามารถใช้ไลบรารี HuggingFace Transformers ไลบรารีนี้มีแบบจำลองที่ผ่านการฝึกฝนหลายพันแบบเพื่อดำเนินงานเกี่ยวกับข้อความต่าง ๆ เช่นการจำแนกประเภทการสกัดข้อมูลการตอบคำถามการสรุปการแปลการสร้างข้อความ ฯลฯ ใน 100+ ภาษา '
คุณสามารถลองใช้เอกสารและคำถามของคุณเอง!
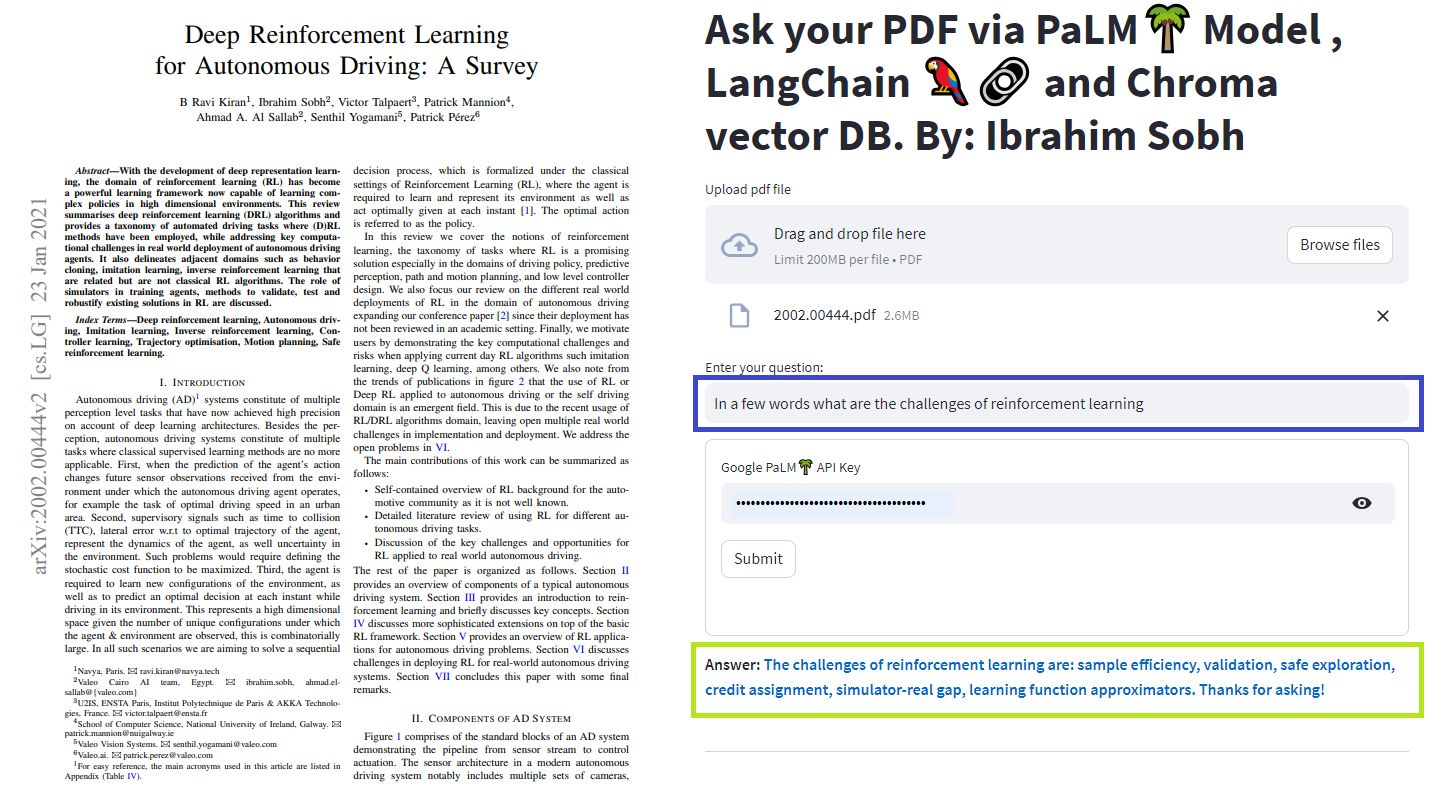
ในบทเรียนง่ายๆเหล่านี้: วิธีรับคำตอบจากเอกสาร ข้อความ ไฟล์ PDF และแม้แต่วิดีโอ YouTube โดยใช้ฐานข้อมูล Chroma Vector, Palm LLM โดย Google และห่วงโซ่ตอบคำถามจาก Langchain สุดท้ายใช้ Streamlit เพื่อพัฒนาและโฮสต์เว็บแอปพลิเคชัน คุณจะต้องใช้ google_api_key ของคุณ (คุณสามารถรับได้จาก Google) สถาปัตยกรรมระบบ THS มีดังนี้:
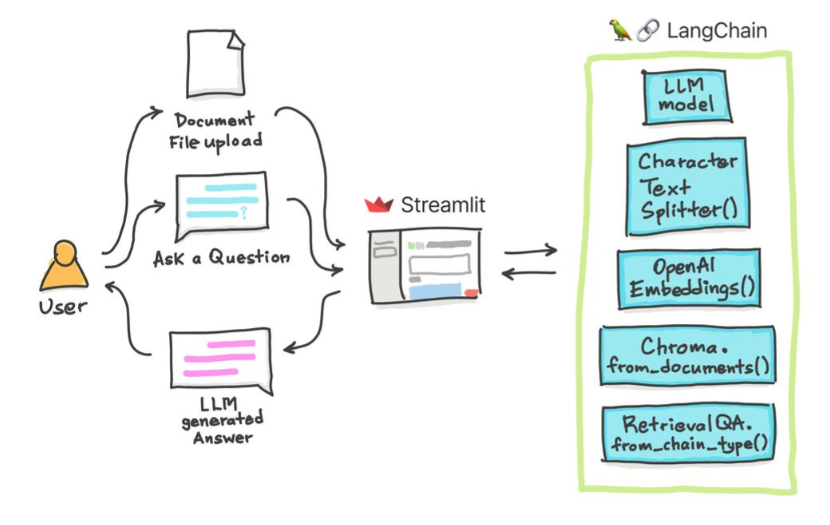
มีความแตกต่างระหว่างการประเมิน LLM กับการประเมินระบบที่ใช้ LLM โดยทั่วไปหลังจากการฝึกอบรมก่อน ทั่วไป LLM จะได้รับการประเมินบนมาตรฐานมาตรฐาน:
ระบบ LLMS สามารถสรุปข้อความทำการตอบคำถามค้นหาความเชื่อมั่นของข้อความสามารถทำการแปลและอื่น ๆ ขึ้นอยู่กับระบบการประเมินผลอาจมีดังนี้:
ตัวอย่างเช่นในกรณีของ ระบบตอบคำถาม เราต้องการคู่ของคำถามและคำตอบในชุดการประเมินผลของเรา เราสามารถใช้คำอธิบายประกอบของมนุษย์เพื่อสร้างคู่คำถามและคำตอบที่เป็นมาตรฐานทองคำด้วยตนเอง However, it is costly and time-consuming. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
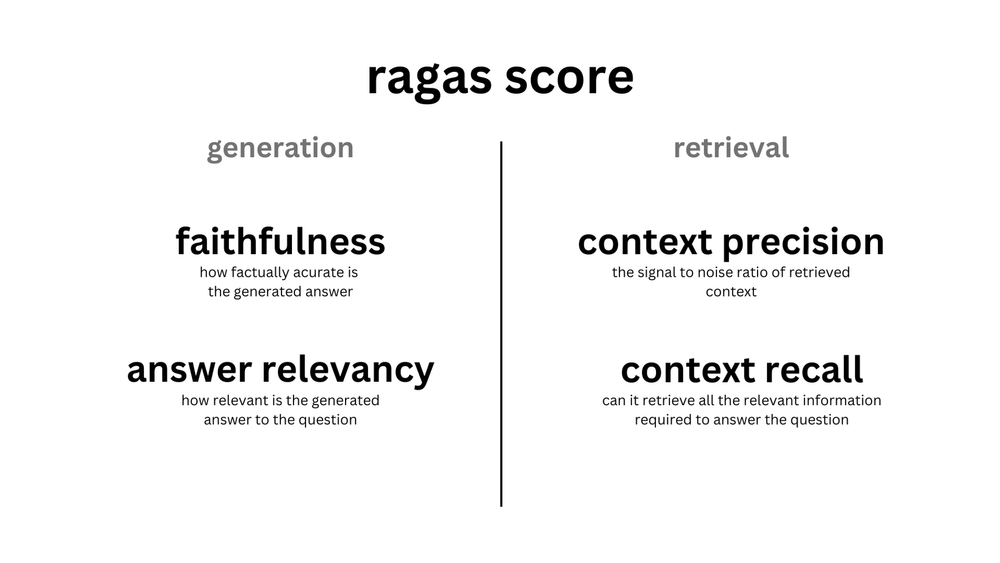
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
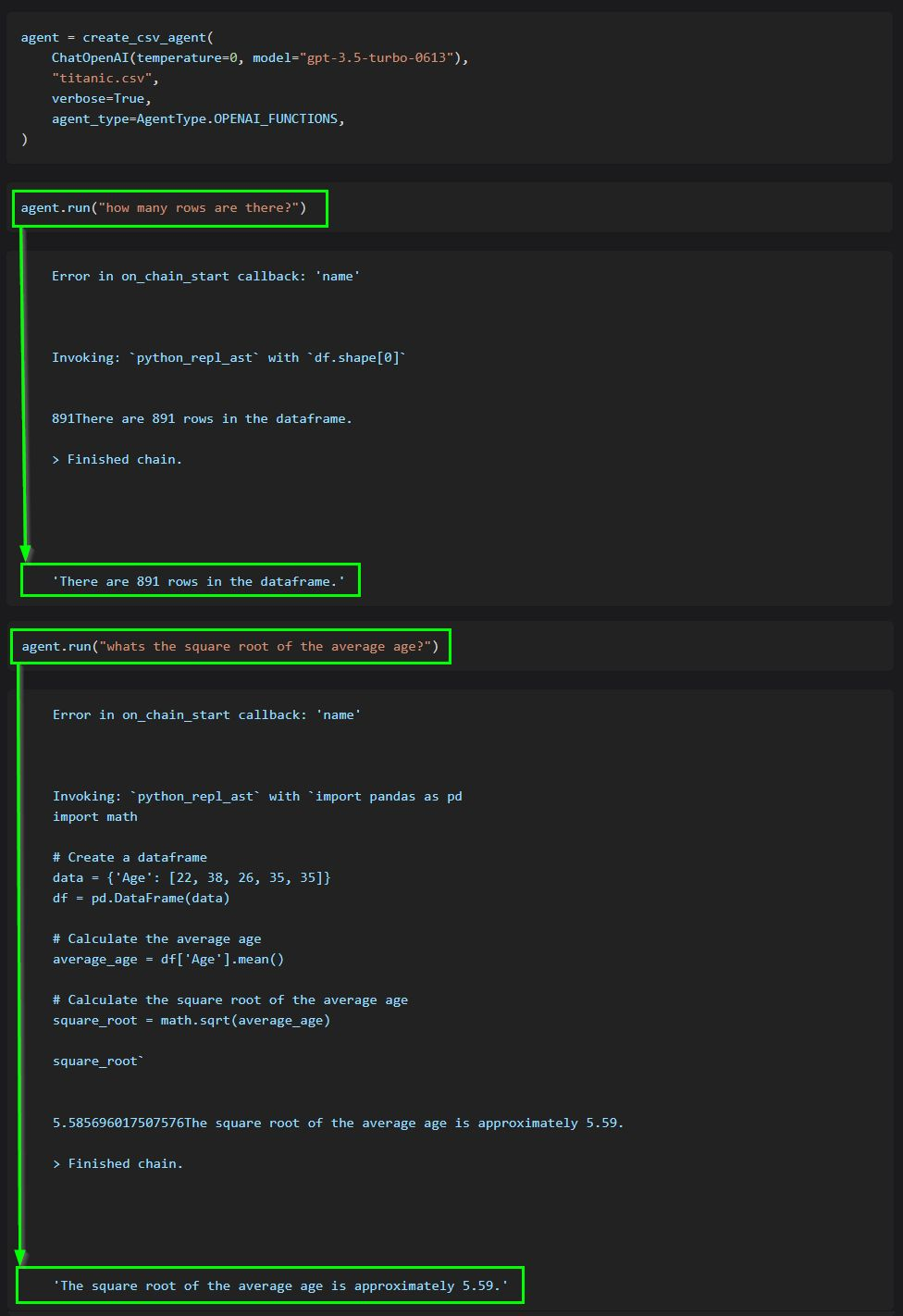
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
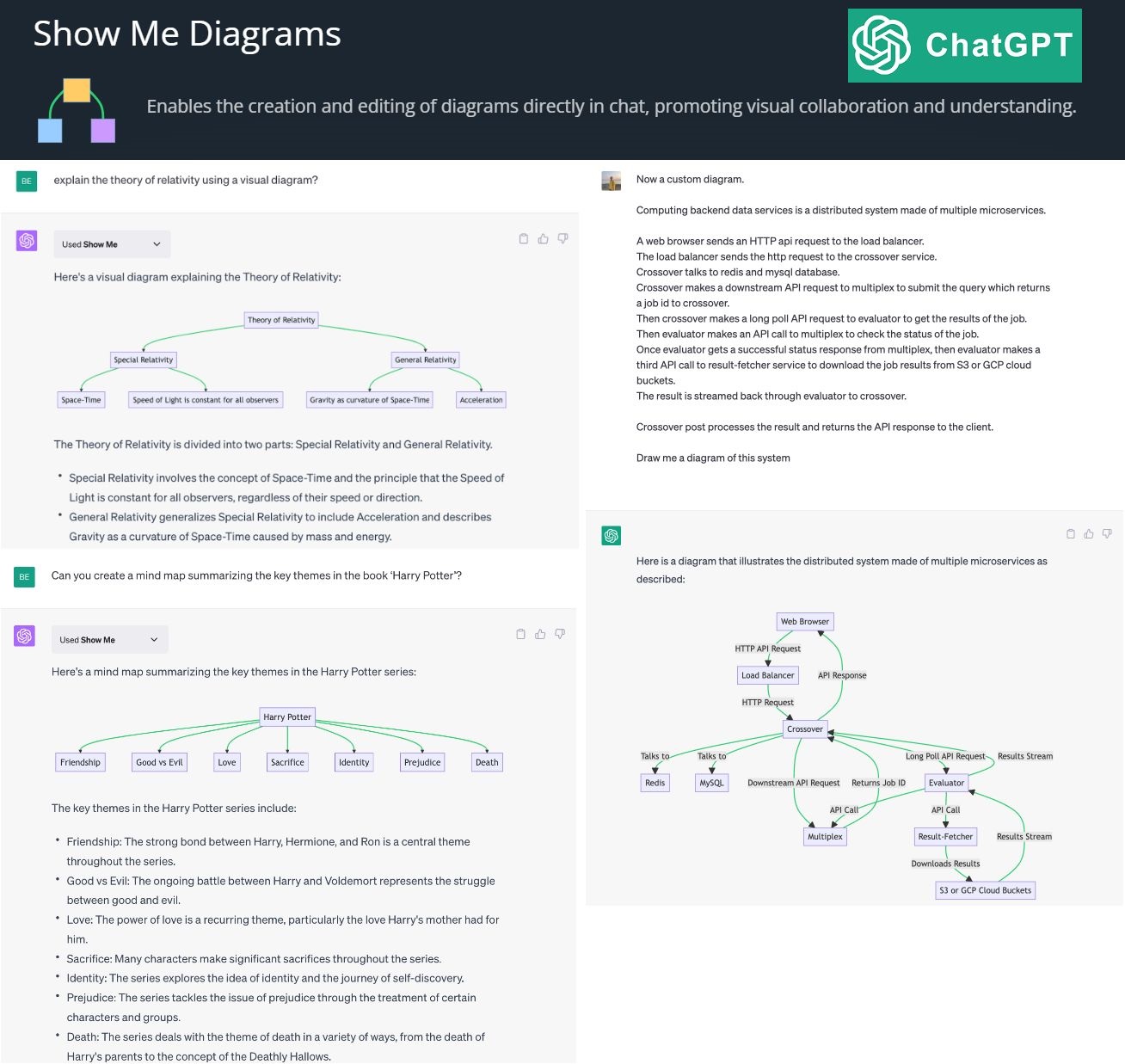
By creating and editing diagrams via Show Me Diagrams
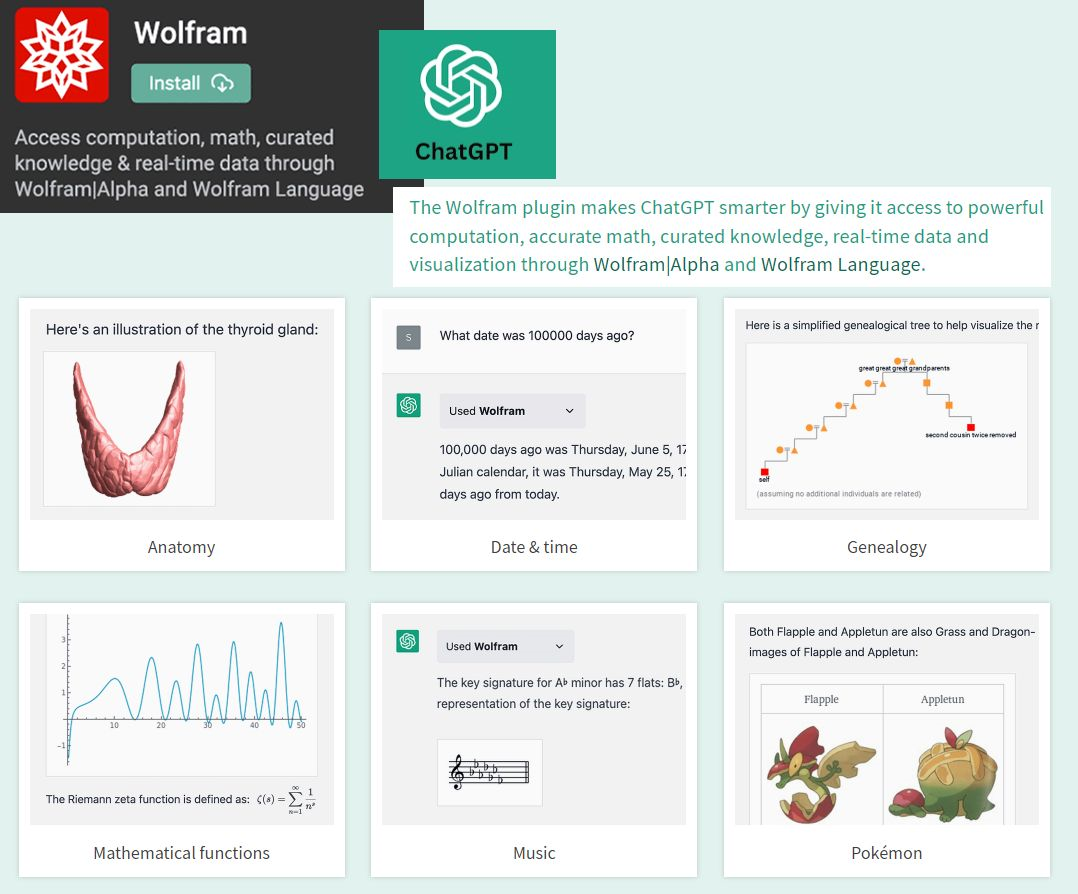
By accessing the power of mathematics provided by Wolfram
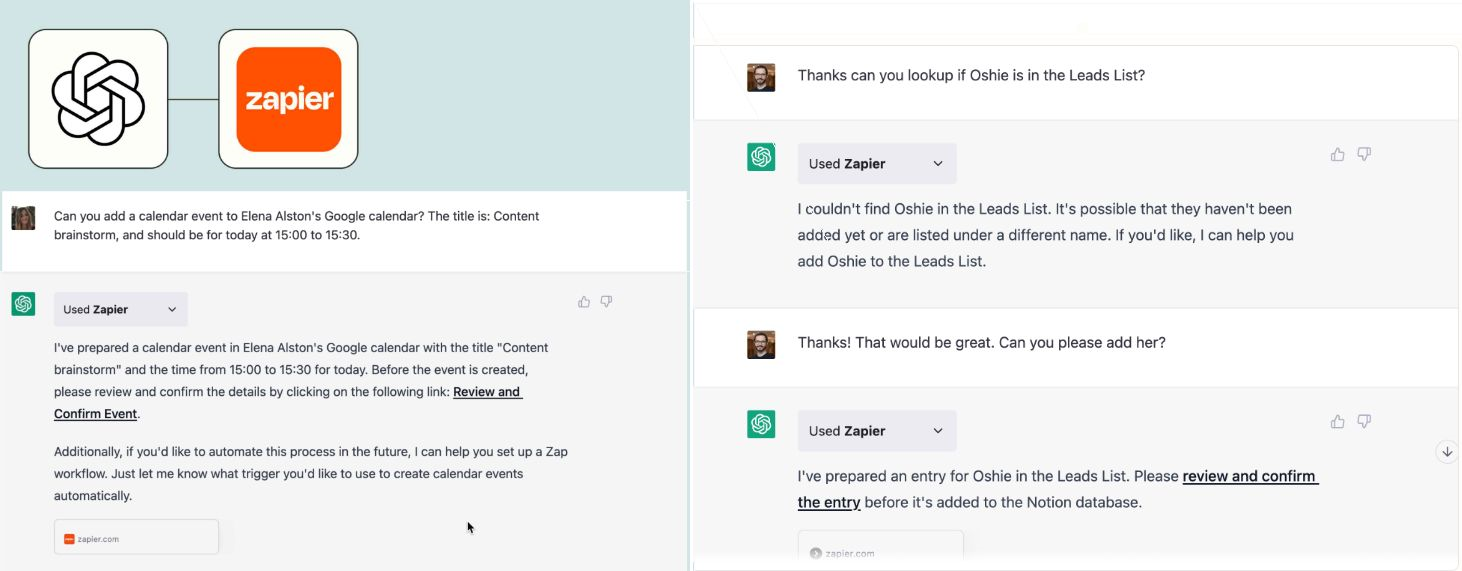
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
- AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


