llms
1.0.0
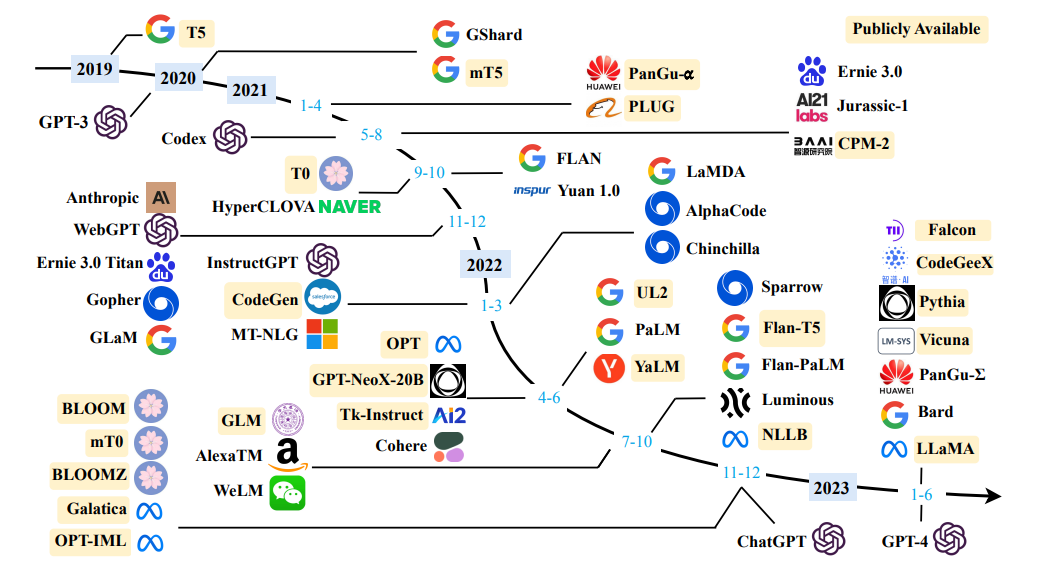 Sumber survei model bahasa besar
Sumber survei model bahasa besar
Definisi Sederhana: Pemodelan Bahasa adalah tugas memprediksi kata apa yang terjadi selanjutnya.
"Anjing itu bermain di ..."
Tujuan utama dari model bahasa adalah untuk menetapkan probabilitas untuk kalimat, untuk membedakan antara kalimat yang lebih mungkin dan yang lebih kecil kemungkinannya.
Untuk pengenalan suara, kami tidak hanya menggunakan model akustik (sinyal bicara), tetapi juga model bahasa. Demikian pula, untuk pengenalan karakter optik (OCR), kami menggunakan model visi dan model bahasa. Model bahasa sangat penting untuk sistem pengakuan seperti itu.
Terkadang, Anda mendengar atau membaca kalimat yang tidak jelas, tetapi menggunakan model bahasa Anda, Anda masih dapat mengenalinya dengan akurasi tinggi meskipun input visi/ucapan yang bising.
Model bahasa menghitung salah satu dari:
Pemodelan bahasa adalah subkomponen dari banyak tugas NLP, terutama yang melibatkan pembuatan teks atau memperkirakan probabilitas teks.
Aturan rantai:
$ P (air, adalah, jadi, jernih) = p (the) × p (air | the) × p (is | the, air) × p (jadi | the, air, is) × p (jernih | air, air, jadi) $ $
Apa yang baru saja terjadi? Aturan rantai diterapkan untuk menghitung probabilitas kata bersama dalam kalimat.
Menggunakan sejumlah besar teks (corpus seperti Wikipedia), kami mengumpulkan statistik tentang seberapa sering kata yang berbeda, dan menggunakannya untuk memprediksi kata berikutnya. Misalnya, probabilitas bahwa kata W datang setelah tiga kata ini siswa dibuka dapat diperkirakan sebagai berikut:
Contoh di atas adalah model 4-gram. Dan kita mungkin mendapatkan:
Kita dapat menyimpulkan bahwa kata "buku" lebih mungkin daripada "mobil" dalam konteks ini.
Kami mengabaikan konteks sebelumnya sebelum "siswa membuka mereka"
Dengan demikian, teks sewenang -wenang dapat dihasilkan dari model bahasa yang diberikan kata awal, dengan mengambil sampel dari distribusi probabilitas output dari kata berikutnya, dan sebagainya.
Kita dapat melatih LM pada segala jenis teks, lalu menghasilkan teks dengan gaya itu (Harry Potter, dll.).
Kita dapat memperpanjang ke trigram, 4-gram, 5 gram, dan n-gram.
Secara umum, ini adalah model bahasa yang tidak mencukupi karena bahasa tersebut memiliki ketergantungan jarak jauh. Namun, dalam praktiknya, 3,4 gram ini bekerja dengan baik untuk sebagian besar aplikasi.
Model N-Gram Google milik Anda: Google Research telah menggunakan model N-Gram Word untuk berbagai proyek R&D. Google N-Gram memproses 1.024.908.267.229 kata-kata menjalankan teks dan menerbitkan jumlah untuk semua 1.176.470.663 urutan lima kata yang muncul setidaknya 40 kali.
Jumlah teks dari Konsorsium Data Linguistik LDC adalah sebagai berikut:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
Berikut ini adalah contoh data 4-gram dalam korpus ini:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
Sebagai contoh, urutan empat kata "berfungsi sebagai indikasi" telah terlihat di corpus 72 kali.
Terkadang kita tidak memiliki cukup data untuk diperkirakan. Meningkatkan N memperburuk masalah sparsity. Biasanya kita tidak dapat memiliki N yang lebih besar dari 5.
NLM biasanya (tetapi tidak selalu) menggunakan RNN untuk mempelajari urutan kata (kalimat, paragraf, ... dll) dan karenanya dapat memprediksi kata berikutnya.
Keuntungan:
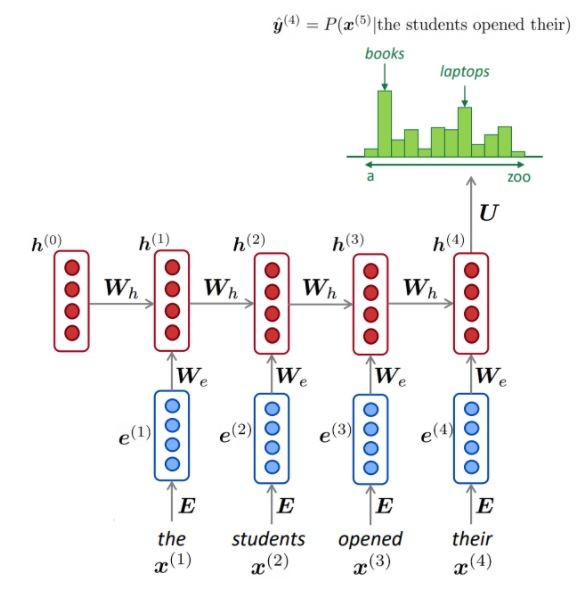
Seperti yang digambarkan, pada setiap langkah, kami memiliki distribusi probabilitas kata berikutnya melalui kosakata.
Melatih NLM:
Contoh pembelajaran urutan panjang:
Kerugian:
LM dapat digunakan untuk menghasilkan kondisi teks pada input (pidato, gambar (OCR), teks, dll.) Di berbagai aplikasi seperti: pengenalan suara, terjemahan mesin, ringkasan, dll.
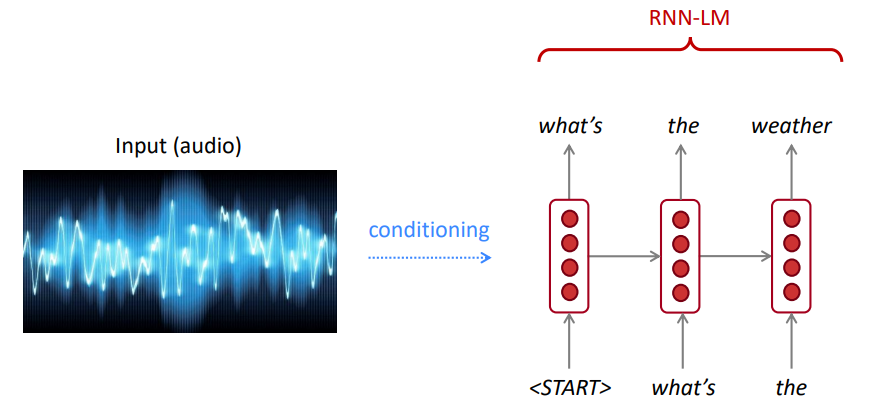
Apakah model bahasa kita lebih suka kalimat yang baik (kemungkinan) daripada yang buruk?
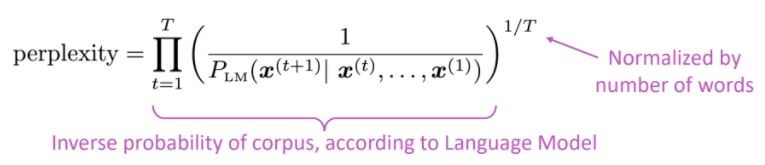
Metrik evaluasi standar untuk model bahasa adalah kebingungan kebingungan adalah probabilitas terbalik dari set tes, dinormalisasi dengan jumlah kata
BESAR BESAR = model yang lebih baik
Kebingungan terkait dengan faktor cabang: rata -rata, berapa banyak hal yang bisa terjadi selanjutnya.
Bukannya RNN, mari kita gunakan perhatian mari kita gunakan model pra-terlatih besar
Apa masalahnya? Salah satu tantangan terbesar dalam pemrosesan bahasa alami (NLP) adalah kekurangan data pelatihan untuk banyak tugas yang berbeda. Namun, model NLP berbasis pembelajaran modern meningkat ketika dilatih pada jutaan, atau miliaran, dari contoh pelatihan beranotasi.
Pra-pelatihan adalah solusinya: untuk membantu menutup celah ini, berbagai teknik telah dikembangkan untuk melatih model representasi bahasa tujuan umum menggunakan jumlah besar teks yang tidak diretrot. Model pra-terlatih kemudian dapat disesuaikan dengan data kecil untuk tugas yang berbeda seperti menjawab pertanyaan dan analisis sentimen, menghasilkan peningkatan akurasi yang substansial dibandingkan dengan pelatihan pada kumpulan data ini dari awal.
Arsitektur Transformer diusulkan dalam kertas perhatian adalah semua yang Anda butuhkan, digunakan untuk Tugas Penerjemahan Mesin Saraf (NMT), yang terdiri dari:
Seperti yang disebutkan di koran:
" Kami mengusulkan arsitektur jaringan sederhana yang baru, transformator, semata -mata didasarkan pada mekanisme perhatian, mengeluarkan kekambuhan dan konvolusi sepenuhnya "
Gagasan utama perhatian dapat diringkas seperti yang disebutkan dalam artikel Openai:
" ... Setiap elemen output terhubung ke setiap elemen input, dan bobot di antara mereka dihitung secara dinamis berdasarkan keadaan , suatu proses yang disebut perhatian. "
Berdasarkan arsitektur ini (vanilla transformers!), Komponen encoder atau dekoder dapat digunakan sendiri untuk memungkinkan model generik pra-terlatih yang sangat besar yang dapat disesuaikan untuk tugas hilir seperti klasifikasi teks, terjemahan, ringkasan, penjawab pertanyaan, dll. Misalnya:
Model -model ini, Bert dan GPT misalnya, dapat dianggap sebagai Imagenet NLP.
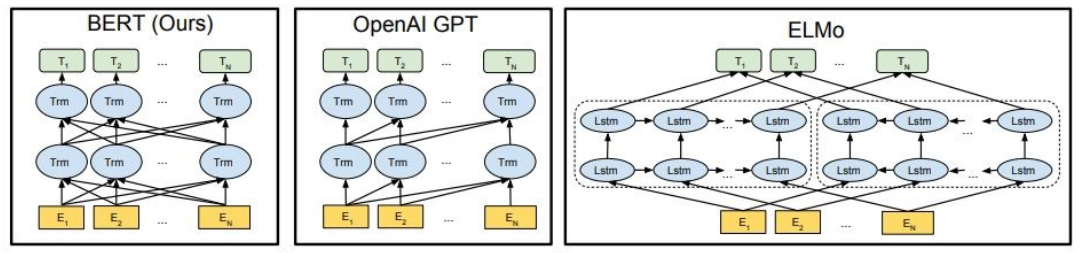
Seperti yang ditunjukkan, Bert sangat dua arah, Openai GPT tidak dirugikan, dan Elmo adalah dua arah yang dangkal.
Representasi pra-terlatih bisa:
Model bahasa kontekstual dapat berupa:
Di bagian ini, kita akan menggunakan model bahasa besar yang berbeda
GPT2 (penerus GPT) adalah model pra-terlatih pada bahasa Inggris menggunakan tujuan pemodelan bahasa kausal ( CLM ), dilatih hanya untuk memprediksi kata berikutnya dalam 40GB teks internet. Ini pertama kali dirilis di halaman ini. GPT2 menampilkan serangkaian kemampuan yang luas, termasuk kemampuan untuk menghasilkan sampel teks sintetis bersyarat. Pada tugas-tugas bahasa seperti menjawab pertanyaan, pemahaman membaca, ringkasan, dan terjemahan, GPT2 mulai mempelajari tugas-tugas ini dari teks mentah, tidak menggunakan data pelatihan khusus tugas. DistilGPT2 adalah versi suling GPT2, ini dimaksudkan untuk digunakan untuk kasus penggunaan yang sama dengan peningkatan fungsionalitas menjadi lebih kecil dan lebih mudah dijalankan daripada model dasar.
Di sini kami memuat model GPT2 yang sudah terlatih, minta model GPT2 untuk melanjutkan teks input kami (prompt), dan akhirnya, ekstrak fitur tertanam dari model DistilGPT2.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Bert adalah model Transformers yang dilatih sebelumnya pada kumpulan besar data bahasa Inggris dengan cara yang di-swadaya. Ini berarti hanya terlatih pada teks mentah saja, tanpa ada manusia yang memberi label dengan cara apa pun dengan proses otomatis untuk menghasilkan input dan label dari teks-teks tersebut. Lebih tepatnya, itu sudah diprioritaskan dengan dua tujuan:
Dalam contoh ini, kami akan menggunakan model BERT pra-terlatih untuk tugas analisis sentimen.
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4ALL adalah ekosistem untuk melatih dan menggunakan model bahasa besar yang kuat dan disesuaikan yang berjalan secara lokal di CPU kelas konsumen.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
Coba model berikut:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM adalah serangkaian model utama model bahasa besar, dibangun dari awal menggunakan pipa data khusus dan pelatihan terdistribusi. Model Falcon-7b/40b adalah canggih untuk ukurannya, mengungguli sebagian besar model lain pada tolok ukur NLP. Sumber Open-Sourced Sejumlah Artefak:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
LLAMA2 adalah keluarga model bahasa besar yang terkemuka yang dirilis oleh Meta Today, dan kami senang untuk sepenuhnya mendukung peluncuran dengan integrasi komprehensif dalam memeluk Wajah. Llama 2 sedang dirilis dengan lisensi komunitas yang sangat permisif dan tersedia untuk penggunaan komersial. Kode, model pretrained, dan model yang disesuaikan semuanya dirilis hari ini
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
CODET5+ adalah keluarga baru model bahasa terbuka yang besar dengan arsitektur encoder-decoder yang dapat beroperasi secara fleksibel dalam mode yang berbeda (yaitu Encoder-only, Decoder-Only, dan Encoder-Decoder) untuk mendukung berbagai tugas pemahaman kode dan pembuatan.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
Untuk lebih banyak model, periksa CODETF dari Salesforce, perpustakaan berbasis transformator Python untuk kode model bahasa besar (kode LLMS) dan intelijen kode, memberikan antarmuka yang mulus untuk pelatihan dan menyimpulkan tugas intelijen kode seperti ringkasan kode, terjemahan, pembuatan kode, dan sebagainya.
? ️ mengobrol dengan model bahasa besar terbuka
✅ Pencarian balok akan selalu menemukan urutan output dengan probabilitas yang lebih tinggi daripada pencarian serakah, tetapi tidak dijamin menemukan output yang paling mungkin.
Dalam Transformers, kami cukup mengatur parameter num_return_secreences ke jumlah balok skor tertinggi yang harus dikembalikan. Pastikan meskipun num_return_sequences <= num_beams!
✅ Pencarian balok dapat bekerja dengan sangat baik dalam tugas -tugas di mana panjang generasi yang diinginkan lebih atau kurang dapat diprediksi seperti dalam terjemahan atau ringkasan mesin. ? Tapi ini bukan kasus untuk generasi terbuka di mana panjang output yang diinginkan dapat sangat bervariasi, misalnya dialog dan pembuatan cerita. Pencarian balok sangat menderita dari generasi yang berulang. Sebagai manusia, kami ingin teks yang dihasilkan untuk mengejutkan kami dan tidak membosankan/dapat diprediksi (? Pencarian balok kurang mengejutkan)
Di Transformers, kami mengatur do_sample = true dan menonaktifkan pengambilan sampel top-k (lebih lanjut tentang ini nanti) melalui top_k = 0.
???-? ????????: K kata -kata berikutnya yang paling mungkin disaring dan massa probabilitas didistribusikan kembali di antara hanya kata -kata berikutnya. GPT2 mengadopsi skema pengambilan sampel ini.
???-? ????????: Alih-alih pengambilan sampel hanya dari kata-kata K yang paling mungkin, dalam pengambilan sampel Top-P terpilih dari set kata-kata sekecil mungkin yang probabilitas kumulatifnya melebihi probabilitas p. Massa probabilitas kemudian didistribusikan kembali di antara set kata -kata ini. Setelah menetapkan P = 0,92, pengambilan sampel Top-P memilih jumlah kata minimum untuk melampaui 92% dari massa probabilitas.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ Sementara Top-P tampaknya lebih elegan daripada Top-K, kedua metode bekerja dengan baik dalam praktiknya. Top-P juga dapat digunakan dalam kombinasi dengan top-K, yang dapat menghindari kata-kata peringkat yang sangat rendah sambil memungkinkan untuk beberapa seleksi dinamis.
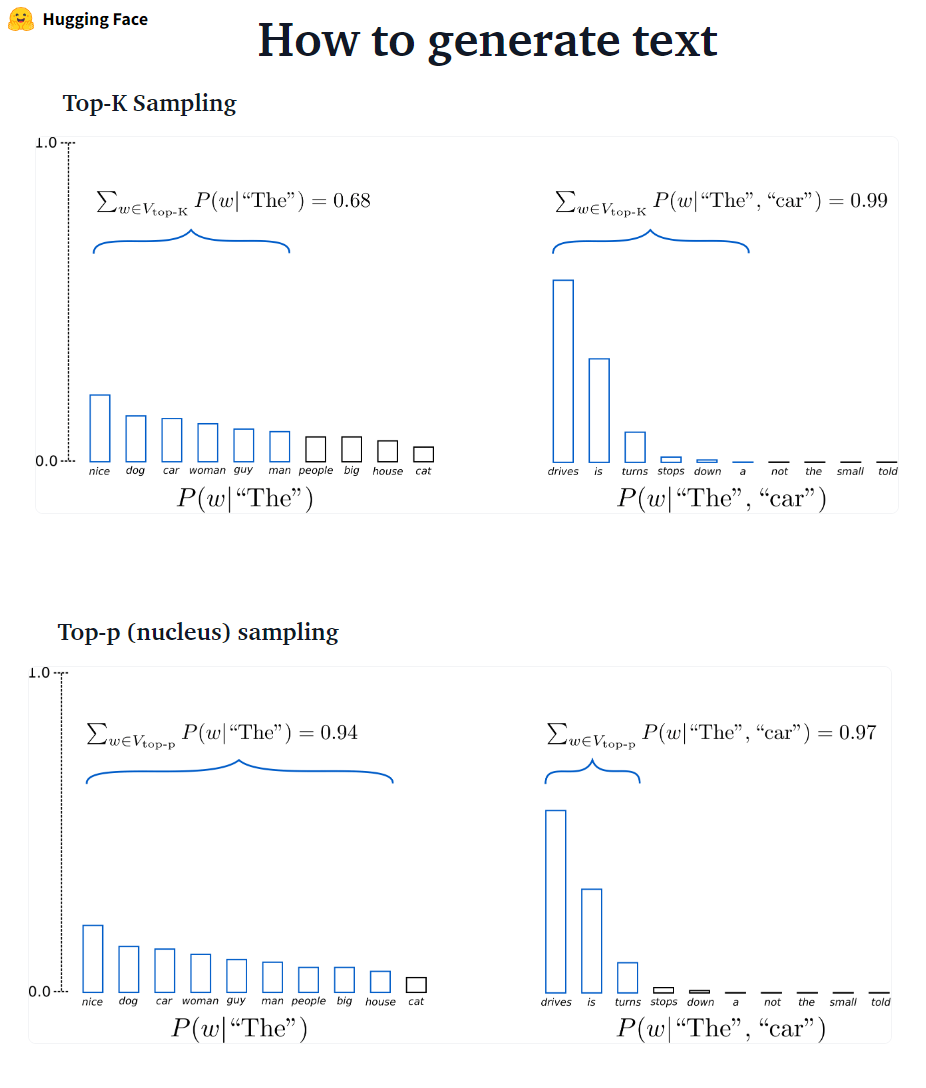
✅ Sebagai metode decoding ad-hoc, pengambilan sampel top-P dan atas-k tampaknya menghasilkan teks yang lebih fasih daripada pencarian serakah-dan balok tradisional pada generasi bahasa terbuka.
Prompt Engineering adalah proses merancang prompt (input teks) untuk model bahasa untuk menghasilkan output yang diperlukan. Teknik yang cepat melibatkan pemilihan kata kunci yang sesuai, memberikan konteks, menjadi jelas dan spesifik dengan cara yang mengarahkan perilaku model bahasa yang mencapai respons yang diinginkan. Melalui rekayasa cepat, kita dapat mengontrol nada, gaya, panjang, dll. Tanpa penyesuaian.
Pembelajaran zero-shot melibatkan meminta model untuk membuat prediksi tanpa memberikan contoh (nol bidikan), misalnya:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
Ketika zero-shot tidak cukup baik, disarankan untuk membantu model dengan memberikan contoh dalam prompt yang mengarah pada beberapa dorongan tembakan.
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
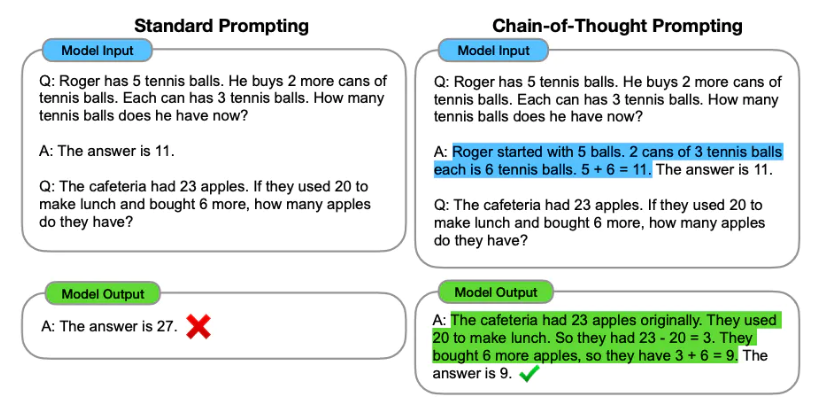
Selain rekayasa cepat , kami dapat mempertimbangkan lebih banyak opsi:
Untuk informasi rekayasa yang lebih cepat, lihat panduan rekayasa cepat yang berisi semua makalah terbaru, panduan belajar, kuliah, referensi, dan alat.
Fine-tuning LLMS pada dataset hilir menghasilkan keuntungan kinerja yang sangat besar jika dibandingkan dengan menggunakan LLM pretrained out-of-the-box (inferensi nol-shot, misalnya). Namun, ketika model menjadi lebih besar dan lebih besar, fine-tuning penuh menjadi tidak layak untuk berlatih pada perangkat keras konsumen. Selain itu, menyimpan dan menggunakan model yang disesuaikan secara independen untuk setiap tugas hilir menjadi sangat mahal, karena model yang disesuaikan memiliki ukuran yang sama dengan model pretrain yang asli. Pendekatan fine-tuning (PEFT) parameter-efisien dimaksudkan untuk mengatasi kedua masalah! Pendekatan PEFT memungkinkan Anda untuk mendapatkan kinerja yang sebanding dengan fine-tuning penuh sementara hanya memiliki sejumlah kecil parameter yang dapat dilatih. Misalnya:
Tuning Prompt: Mekanisme sederhana namun efektif untuk belajar "permintaan lunak" untuk mengkondisikan model bahasa beku untuk melakukan tugas hilir tertentu. Sama seperti petunjuk teks yang direkayasa, prompt lunak digabungkan dengan teks input. Tetapi alih -alih memilih dari item kosa kata yang ada, "token" dari soft prompt adalah vektor yang dapat dipelajari. Ini berarti soft prompt dapat dioptimalkan ujung ke ujung atas dataset pelatihan, seperti yang ditunjukkan di bawah ini: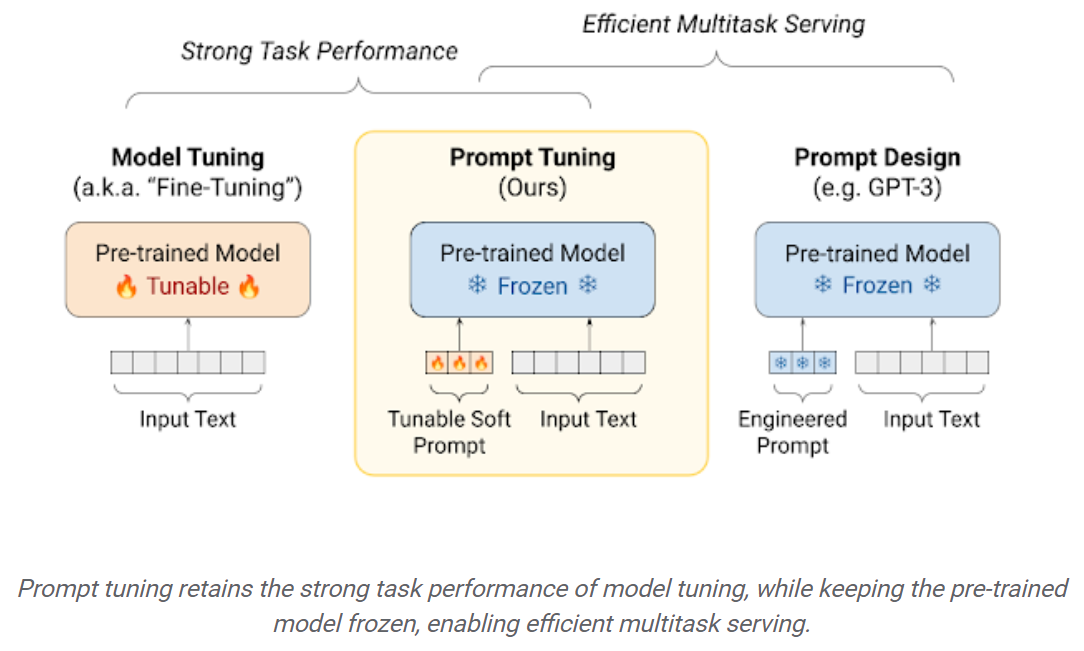
Adaptasi LLMS LORA LORA adalah metode yang membekukan bobot model pretrained dan menyuntikkan matriks dekomposisi peringkat yang dapat dilatih ke dalam setiap lapisan arsitektur transformator. Sangat mengurangi jumlah parameter yang dapat dilatih untuk tugas hilir. Angka di bawah ini, dari video ini, mengeksplian ide utama: 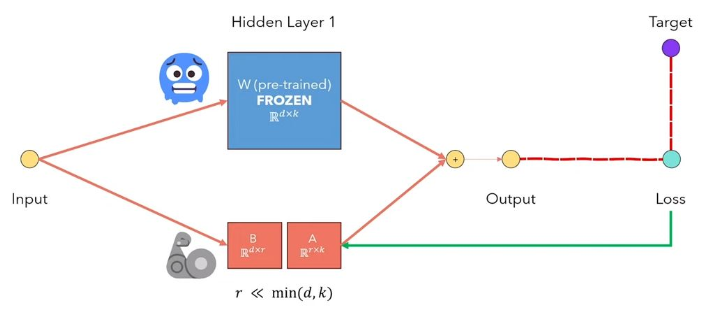
Model bahasa besar biasanya tujuan umum, kurang efektif untuk tugas khusus domain. Namun, mereka dapat disesuaikan dengan beberapa tugas seperti analisis sentimen. Untuk TAKS yang lebih kompleks yang membutuhkan pengetahuan eksternal, dimungkinkan untuk membangun sistem berbasis model bahasa yang mengakses sumber pengetahuan eksternal untuk menyelesaikan tugas yang diperlukan. Ini memungkinkan keakuratan yang lebih faktual, dan membantu mengurangi masalah "halusinasi". Seperti yang ditunjukkan pada figuer di bawah ini:
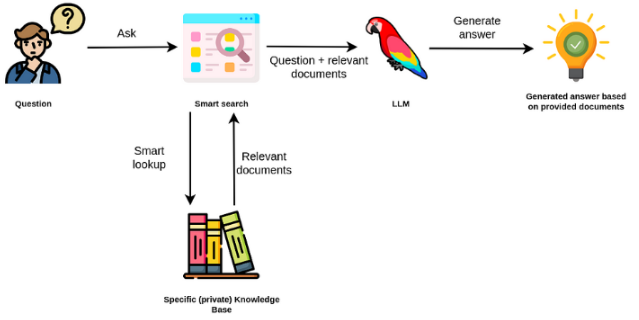
Dalam hal ini, alih -alih menggunakan LLM untuk mengakses pengetahuan internalnya, kami menggunakan LLM sebagai antarmuka bahasa alami untuk pengetahuan eksternal kami. Langkah pertama adalah mengonversi dokumen dan permintaan pengguna apa pun menjadi format yang kompatibel untuk melakukan pencarian relevansi (mengubah teks menjadi vektor, atau embeddings). Prompt pengguna asli kemudian ditambahkan dengan dokumen yang relevan / serupa dalam sumber pengetahuan eksternal (sebagai konteks). Model kemudian menjawab pertanyaan berdasarkan konteks eksternal yang disediakan.
Model bahasa besar (LLM) muncul sebagai teknologi transformatif. Namun, menggunakan LLM ini secara terpisah sering tidak cukup untuk membuat aplikasi yang benar -benar kuat. Langchain bertujuan untuk membantu dalam pengembangan aplikasi tersebut.
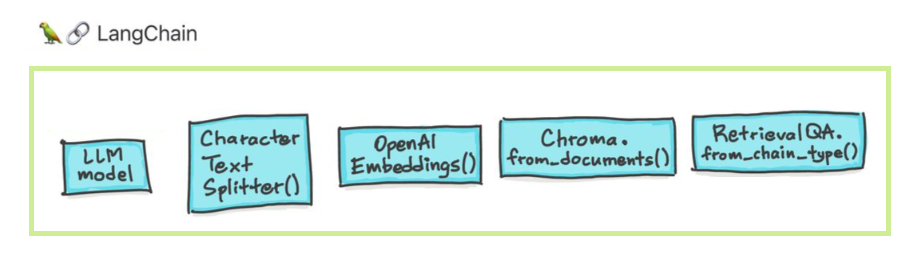
Ada enam area utama yang dirancang Langchain untuk membantu. Ini, dalam meningkatkan urutan kompleksitas:
Ini termasuk manajemen yang cepat, optimasi cepat, antarmuka generik untuk semua LLM, dan utilitas umum untuk bekerja dengan LLM. LLM dan model obrolan secara halus tetapi penting berbeda. Llms di langchain merujuk ke model penyelesaian teks murni. API yang mereka bungkus mengambil prompt string sebagai input dan output penyelesaian string. GPT-3 Openai diimplementasikan sebagai LLM. Model obrolan sering didukung oleh LLMS tetapi disetel khusus untuk melakukan percakapan.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
Anda juga dapat mengakses informasi spesifik penyedia yang dikembalikan. Informasi ini tidak distandarisasi lintas penyedia.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
Model chat prompt adalah daftar pesan obrolan. Setiap pesan obrolan dikaitkan dengan konten, dan parameter tambahan yang disebut peran. Misalnya, di OpenAI CHAT COMPLETIONS API, pesan obrolan dapat dikaitkan dengan asisten AI, peran manusia atau sistem.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
Rantai melampaui satu panggilan LLM dan melibatkan urutan panggilan (apakah ke LLM atau utilitas yang berbeda). Langchain menyediakan antarmuka standar untuk rantai, banyak integrasi dengan alat lain, dan rantai ujung ke ujung untuk aplikasi umum. Rantai secara umum dapat didefinisikan sebagai urutan panggilan ke komponen, yang dapat mencakup rantai lain.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
Data Augmented Generation melibatkan jenis rantai tertentu yang pertama -tama berinteraksi dengan sumber data eksternal untuk mengambil data untuk digunakan dalam langkah pembuatan. Contohnya termasuk pertanyaan/menjawab atas sumber data tertentu.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
Pencarian kesamaan
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
Agen melibatkan LLM yang membuat keputusan tentang tindakan mana yang harus diambil, mengambil tindakan itu, melihat pengamatan, dan mengulanginya sampai dilakukan. Langchain menyediakan antarmuka standar untuk agen, pilihan agen untuk dipilih, dan contoh agen ujung ke ujung. Gagasan inti dari agen adalah menggunakan LLM untuk memilih urutan tindakan yang harus diambil. Dalam rantai, urutan tindakan hardcoded (dalam kode). Dalam agen, model bahasa digunakan sebagai mesin penalaran untuk menentukan tindakan mana yang harus diambil dan dalam urutan mana.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Memori mengacu pada keadaan yang bertahan antara panggilan rantai/agen. Langchain menyediakan antarmuka standar untuk memori, kumpulan implementasi memori, dan contoh rantai/agen yang menggunakan memori.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
Kami dapat menggunakan berbagai metode untuk mengobrol dengan dokumen kami. Tidak perlu menyempurnakan seluruh LLM, sebaliknya kami dapat memberikan konteks yang tepat bersama dengan pertanyaan kami kepada model pra-terlatih dan hanya mendapatkan jawaban berdasarkan dokumen yang disediakan.
Di sini, kami mengobrol dengan artikel bagus ini berjudul Transformers Without Pain? Mengajukan pertanyaan yang berkaitan dengan transformator, perhatian, encoder-decoder, dll. Sambil memanfaatkan model Palm yang kuat oleh Google dan kerangka kerja Langchain untuk mengembangkan aplikasi yang ditenagai oleh model bahasa.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
Pertanyaan : ? 'Tentang apa dokumen -dokumen ini?'
Menjawab : ? 'Dokumen -dokumennya adalah tentang transformator, yang merupakan jenis jaringan saraf yang telah digunakan dengan sukses dalam pemrosesan bahasa alami dan tugas -tugas visi komputer.'
Pertanyaan : ? 'Apa ide utama Transformers?'
Menjawab : ? 'Gagasan utama Transformers adalah menggunakan mekanisme perhatian untuk memodelkan ketergantungan jangka panjang secara berurutan.'
Pertanyaan : ? 'Apa itu penyandian posisi?'
Menjawab : ? 'Pengkodean posisi adalah teknik yang digunakan untuk mewakili urutan kata dalam urutan.'
Pertanyaan : ? 'Bagaimana permintaan, kunci, dan vektor nilai digunakan?'
Menjawab : ? 'Vektor kueri digunakan untuk menghitung jumlah nilai tertimbang melalui tombol. Khususnya: Q DOT Produk Semua tombol, lalu softmax untuk mendapatkan bobot dan akhirnya menggunakan bobot ini untuk menghitung jumlah tertimbang dari nilai -nilai. '
Pertanyaan : ? 'Bagaimana cara mulai menggunakan Transformers?'
Menjawab : ? 'Untuk mulai menggunakan Transformers, Anda dapat menggunakan perpustakaan Huggingface Transformers. Perpustakaan ini menyediakan ribuan model pretrained untuk melakukan tugas pada teks seperti klasifikasi, ekstraksi informasi, penjawab pertanyaan, ringkasan, terjemahan, pembuatan teks, dll dalam 100+ bahasa. '
Anda dapat mencoba dokumen dan pertanyaan Anda sendiri!
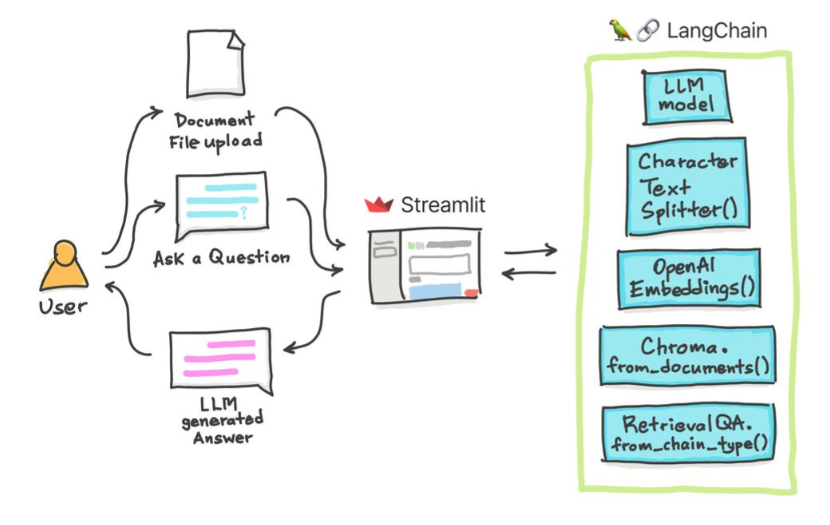
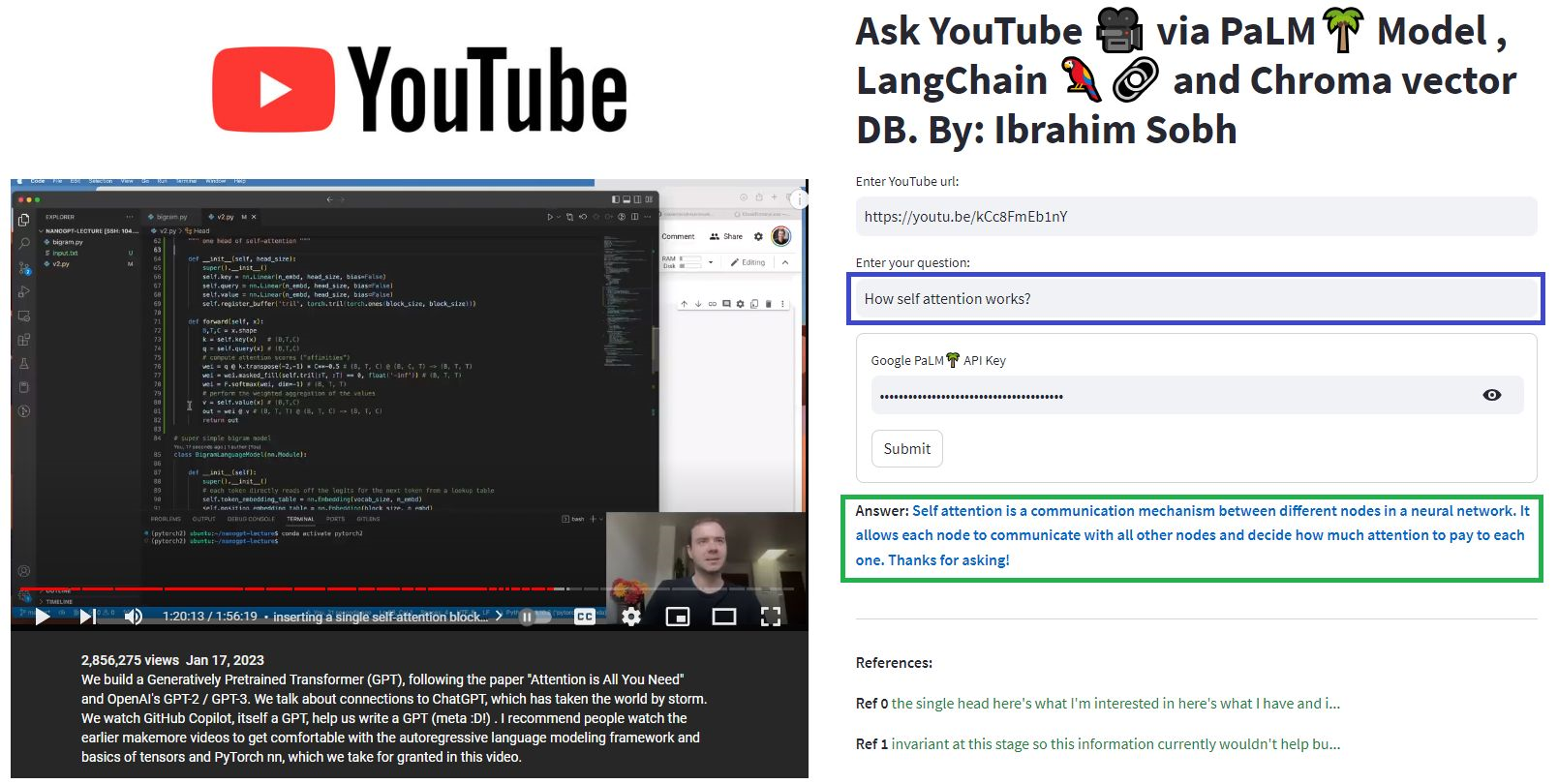
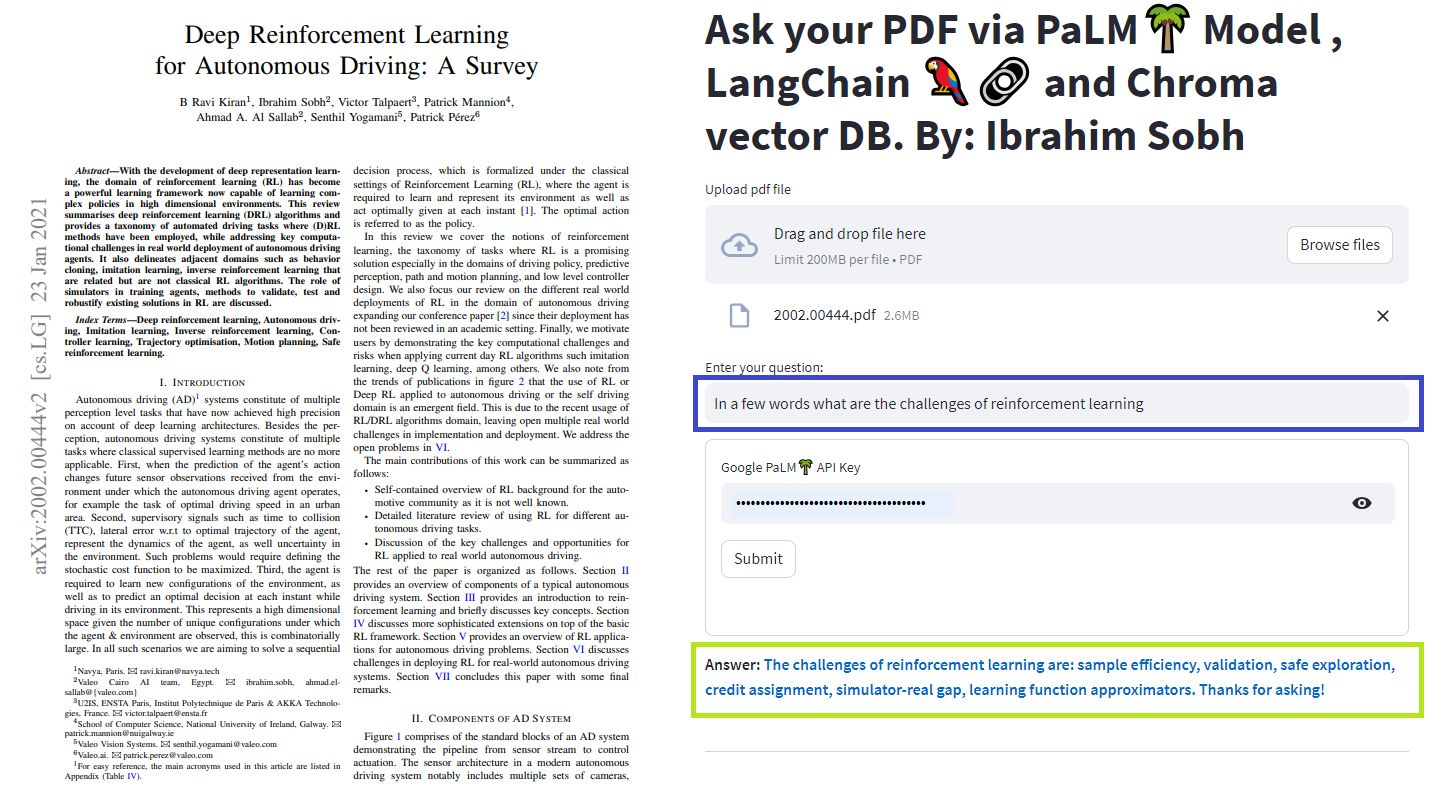
Dalam tutorial sederhana ini: Cara mendapatkan jawaban dari dokumen teks , file PDF , dan bahkan video YouTube menggunakan database Chroma Vector, Palm LLM oleh Google, dan rantai penjawab pertanyaan dari Langchain. Akhirnya, gunakan StreamLit untuk mengembangkan dan meng -host aplikasi web. Anda perlu menggunakan google_api_key Anda (Anda bisa mendapatkannya dari google). Arsitektur sistem THS adalah sebagai berikut:
Ada perbedaan antara mengevaluasi LLM versus mengevaluasi sistem berbasis LLM. Biasanya setelah pra-pelatihan generik , LLM dievaluasi pada tolok ukur standar:
Sistem LLMS dapat meringkas teks, melakukan pertanyaan, menemukan sentimen teks, dapat melakukan terjemahan, dan banyak lagi. Berdasarkan sistem, evaluasi dapat sebagai berikut:
Misalnya dalam hal sistem penjawab pertanyaan , kami membutuhkan sepasang pertanyaan dan jawaban dalam set evaluasi kami. Kita dapat menggunakan annotator manusia untuk membuat pasangan pertanyaan dan jawaban standar emas secara manual. However, it is costly and time-consuming. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
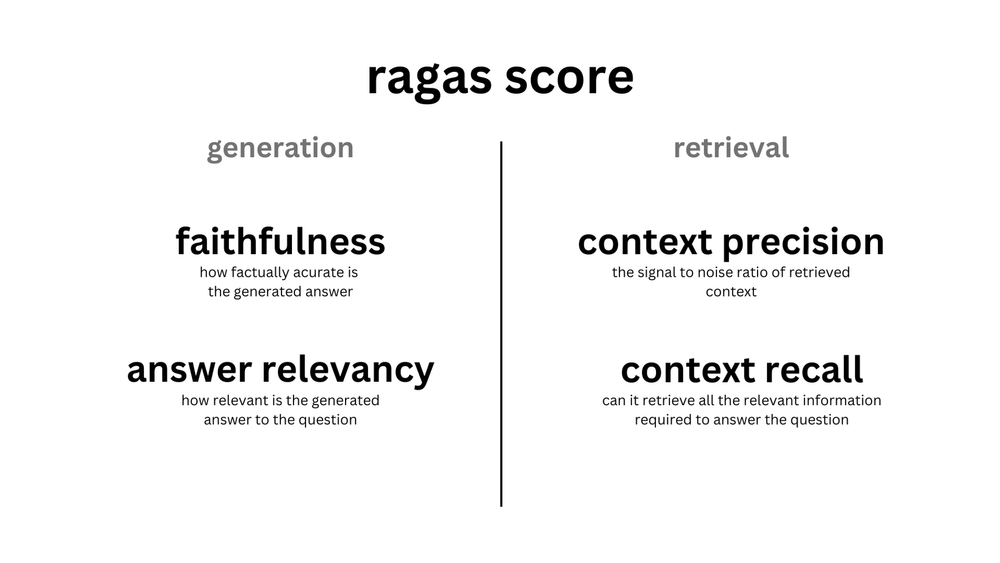
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
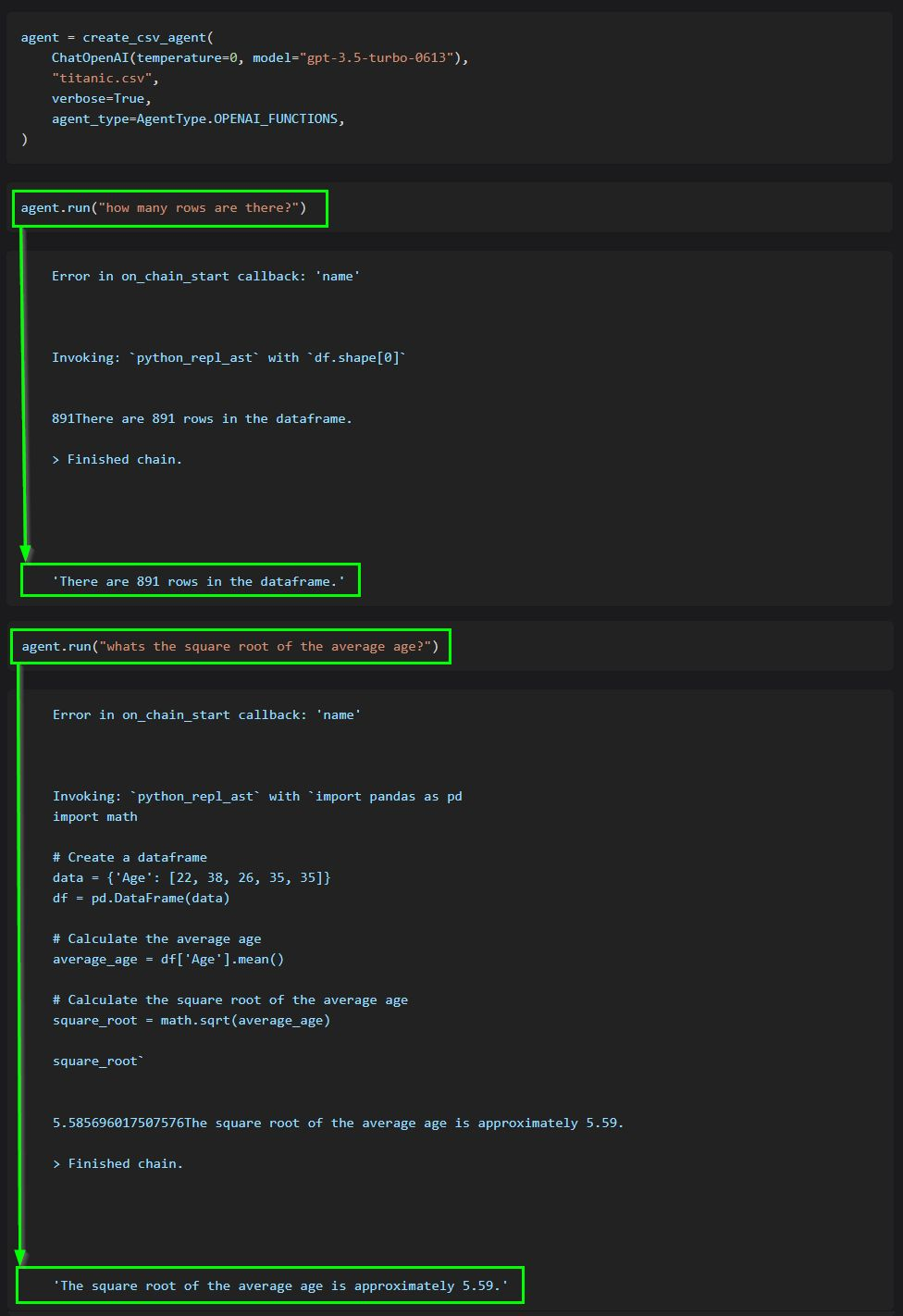
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
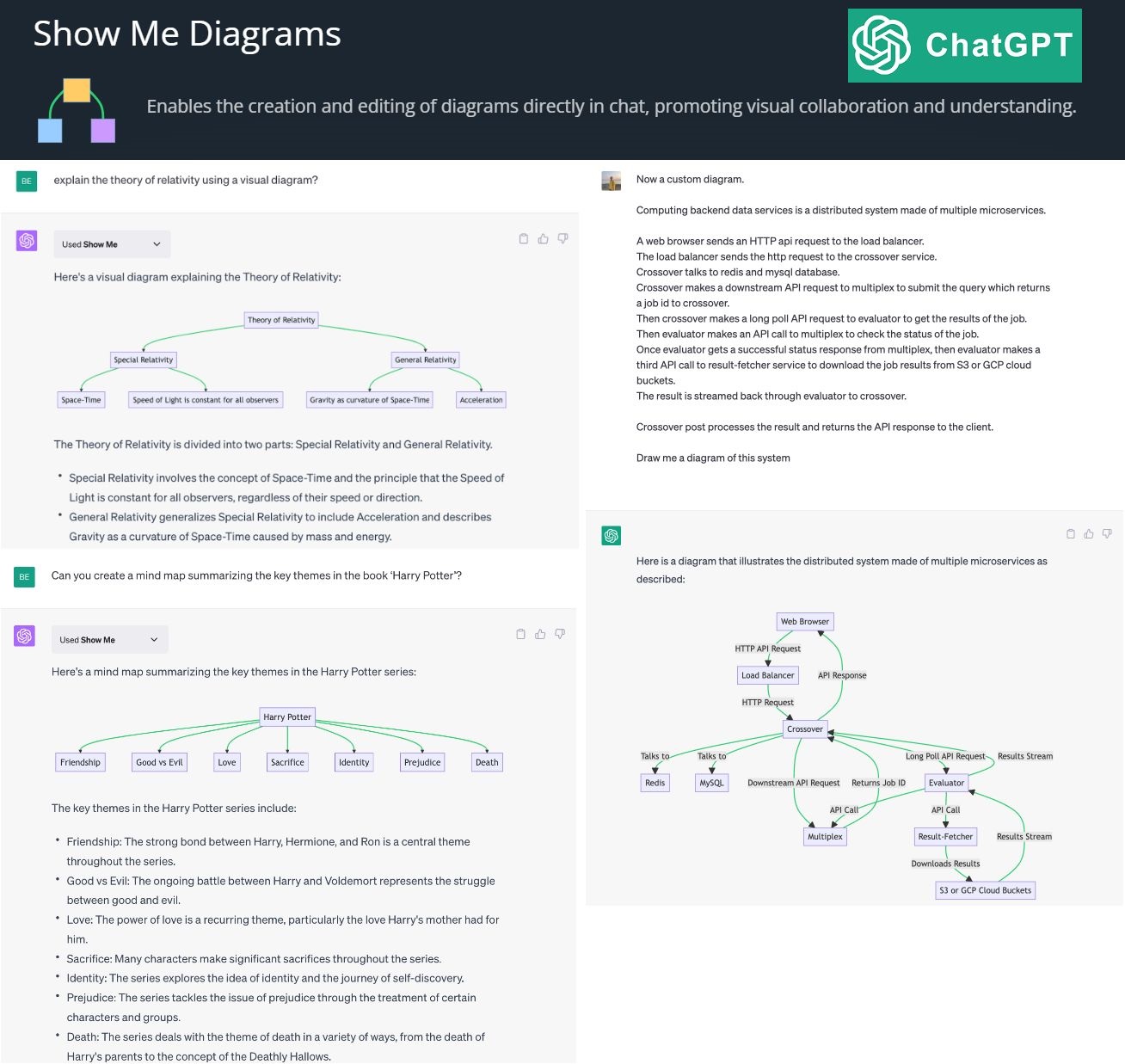
By creating and editing diagrams via Show Me Diagrams
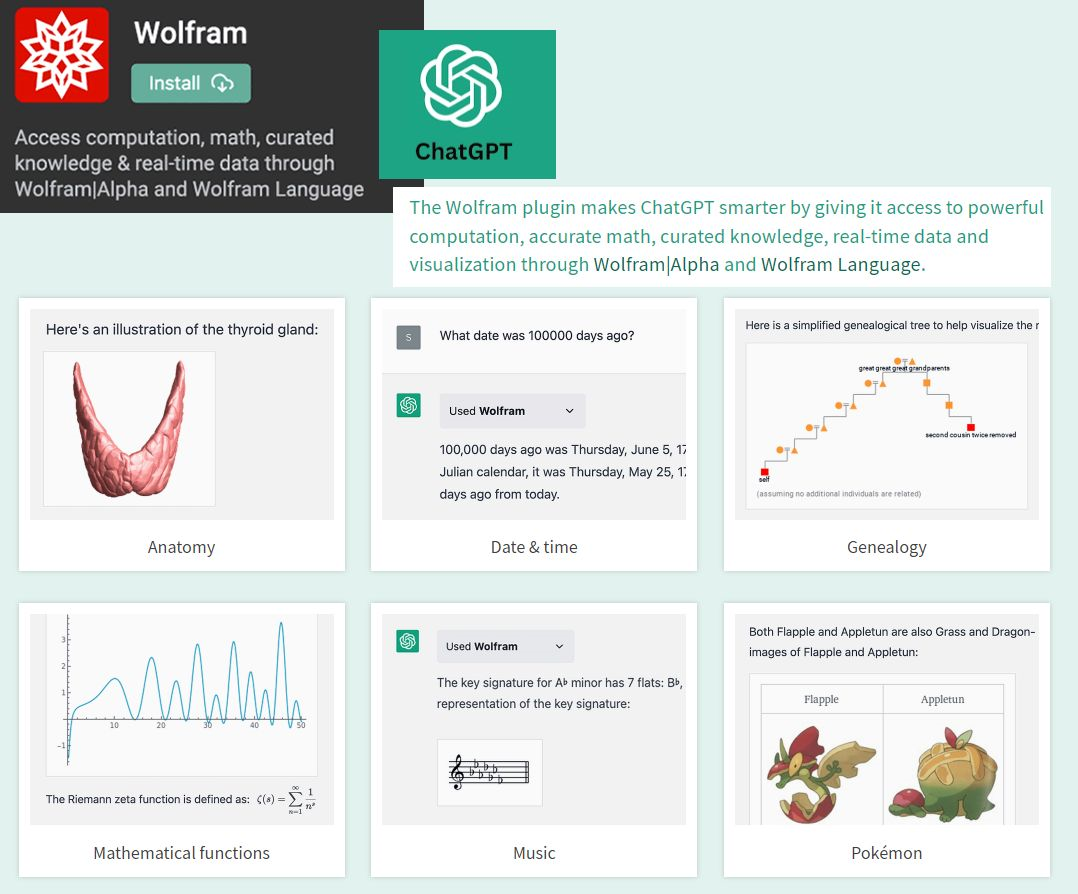
By accessing the power of mathematics provided by Wolfram
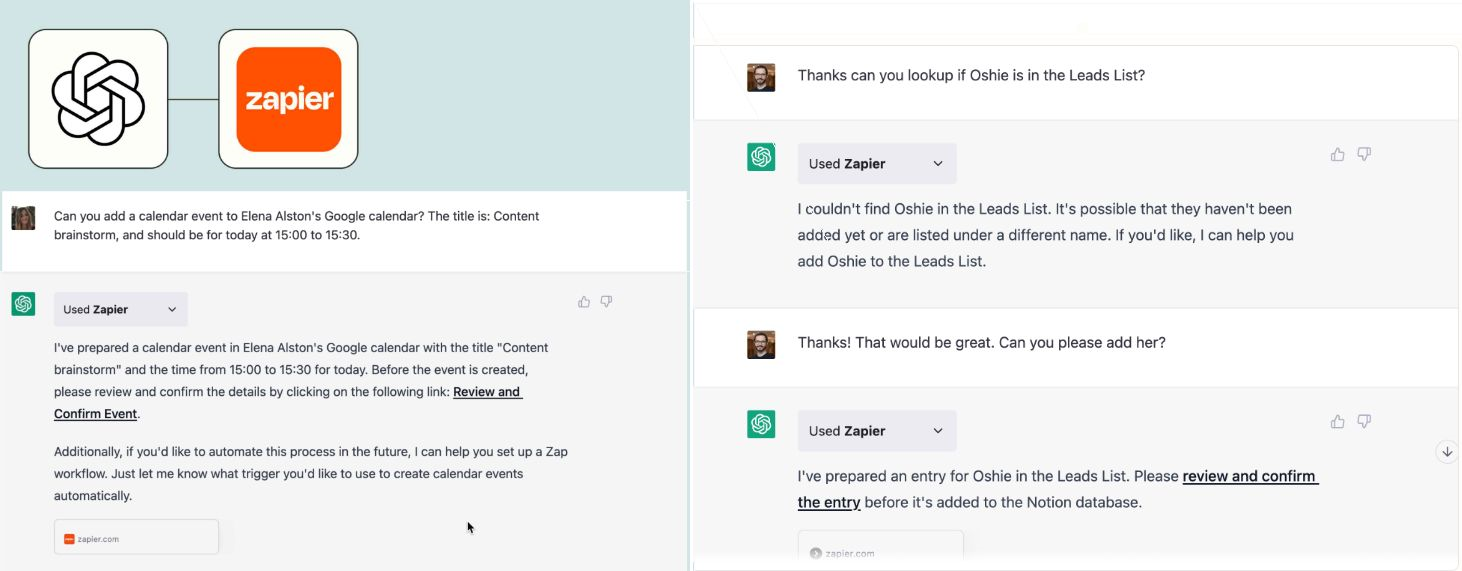
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


