llms
1.0.0
 Obter uma pesquisa de grandes modelos de linguagem
Obter uma pesquisa de grandes modelos de linguagem
Definição simples: a modelagem de idiomas é a tarefa de prever qual palavra vem a seguir.
"O cachorro está brincando no ..."
O principal objetivo dos modelos de linguagem é atribuir uma probabilidade a uma frase, distinguir entre as frases mais provável e menos provável.
Para reconhecimento de fala, usamos não apenas o modelo acústica (o sinal de fala), mas também um modelo de idioma. Da mesma forma, para o reconhecimento óptico de caracteres (OCR), usamos um modelo de visão e um modelo de idioma. Os modelos de idiomas são muito importantes para esses sistemas de reconhecimento.
Às vezes, você ouve ou lê uma frase que não é clara, mas, usando seu modelo de idioma, ainda pode reconhecê -la com alta precisão, apesar da visão barulhenta da visão/fala.
O modelo de idioma calcula um dos:
A modelagem de idiomas é um subcomponente de muitas tarefas de PNL, especialmente aquelas que envolvem gerar texto ou estimar a probabilidade de texto.
A regra da cadeia:
$ P (a água, é, portanto, claro) = p (o) × p (água | o) × p (é | o, água) × p (então | a água, é) × p (limpo | a água, é, assim) $
O que acabou de acontecer? A regra da cadeia é aplicada para calcular a probabilidade articular das palavras em uma frase.
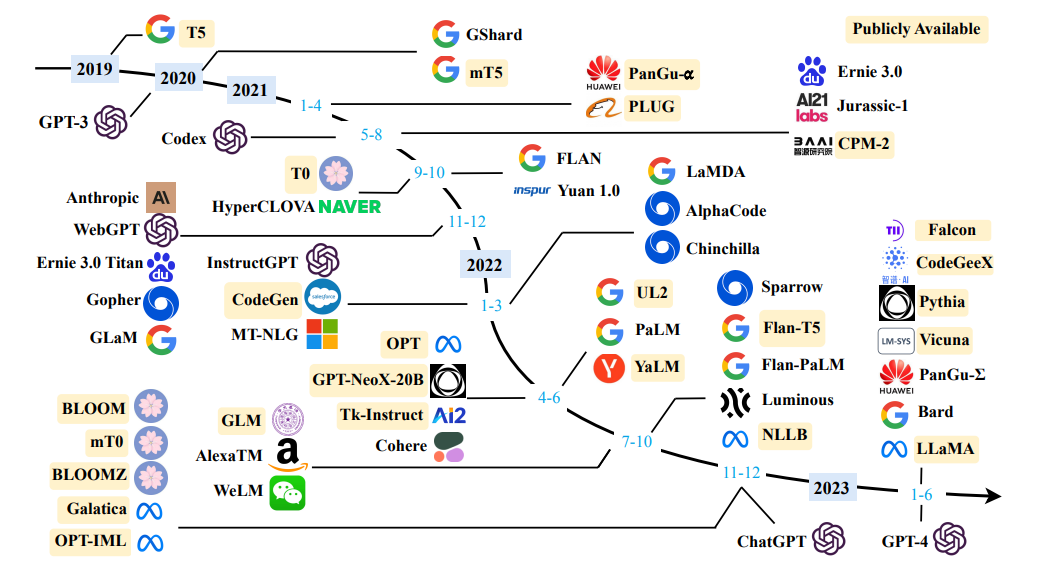
Usando uma grande quantidade de texto (corpus como a Wikipedia), coletamos estatísticas sobre com que frequência as palavras diferentes são e as usamos para prever a próxima palavra. Por exemplo, a probabilidade de que uma palavra tenha chega depois dessas três palavras que os alunos abriram podem ser estimados da seguinte forma:
O exemplo acima é um modelo de 4 gramas. E podemos obter:
Podemos concluir que a palavra "livros" é mais provável do que "carros" nesse contexto.
Ignoramos o contexto anterior antes de "os alunos abrirem seus"
Consequentemente, o texto arbitrário pode ser gerado a partir de um modelo de idioma com as palavras iniciais, amostragem da distribuição de probabilidade de saída da próxima palavra e assim por diante.
Podemos treinar um LM em qualquer tipo de texto e gerar texto nesse estilo (Harry Potter, etc.).
Podemos se estender a trigrams, 4 gramas, 5 gramas e gramas.
Em geral, este é um modelo insuficiente de linguagem, porque o idioma tem dependências de longa distância. No entanto, na prática, esses 3,4 gramas funcionam bem para a maioria das aplicações.
Os modelos N-Gram do Google pertencem a você: o Google Research tem usado modelos de Word n-Gram para uma variedade de projetos de P&D. O Google N-Gram processou 1.024.908.267.229 palavras de texto em execução e publicou as contagens para todas as 1.176.470.663 sequências de cinco palavras que aparecem pelo menos 40 vezes.
As contagens de texto do Linguistics Data Consortium LDC são as seguintes:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
A seguir, é apresentado um exemplo dos dados de 4 gramas neste corpus:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
Por exemplo, a sequência das quatro palavras "serve como indicação" foi vista no corpus 72 vezes.
Às vezes, não temos dados suficientes para estimar. O aumento de N piora os problemas de escassez. Normalmente, não podemos ter n maior que 5.
O NLM geralmente (mas nem sempre) usa um RNN para aprender sequências de palavras (frases, parágrafos,… etc.) e, portanto, podem prever a próxima palavra.
Vantagens:
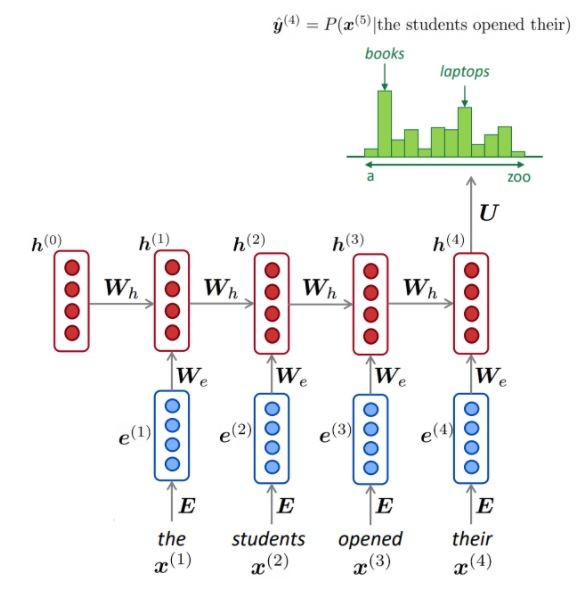
Como descrito, a cada etapa, temos uma distribuição de probabilidade da próxima palavra sobre o vocabulário.
Treinando um NLM:
Exemplo de aprendizado de sequência longa:
Desvantagens:
O LM pode ser usado para gerar condições de texto na entrada (fala, imagem (OCR), texto etc.) em diferentes aplicações, como: reconhecimento de fala, tradução de máquinas, resumo, etc.
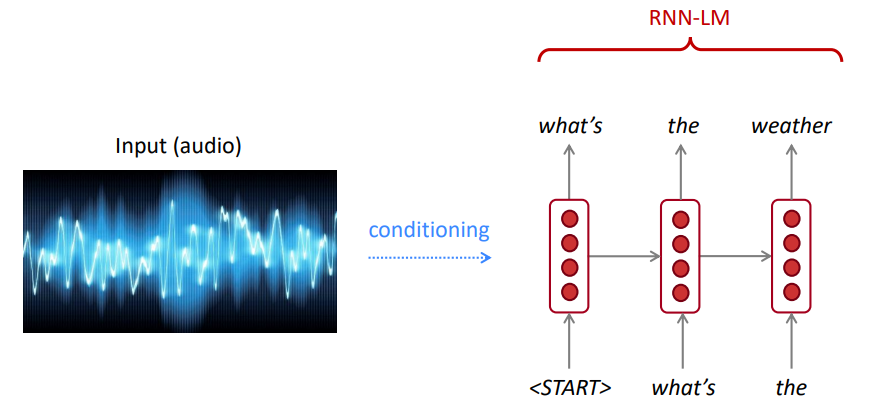
Nosso modelo de idioma prefere frases boas (prováveis) aos ruins?
A métrica de avaliação padrão para modelos de linguagem é a perplexidade perplexidade é a probabilidade inversa do conjunto de testes, normalizada pelo número de palavras
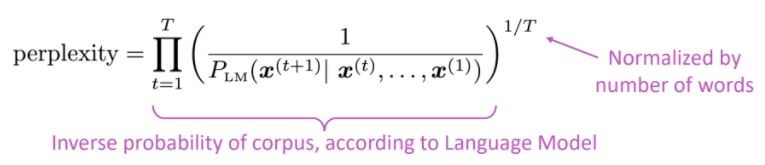
Menor perplexidade = modelo melhor
A perplexidade está relacionada ao fator de filial: em média, quantas coisas podem ocorrer a seguir.
Em vez de RNN, vamos usar a atenção, vamos usar grandes modelos pré-treinados
Qual é o problema? Um dos maiores desafios no processamento de linguagem natural (PNL) é a escassez de dados de treinamento para muitas tarefas distintas. No entanto, os modelos modernos de PNL baseados em aprendizado profundo melhoram quando treinados em milhões, ou bilhões, de exemplos de treinamento anotados.
O pré-treinamento é a solução: para ajudar a fechar essa lacuna, uma variedade de técnicas foi desenvolvida para o treinamento de modelos de representação de idiomas de uso geral, usando a enorme quantidade de texto não anotado. O modelo pré-treinado pode ser ajustado em pequenos dados para tarefas diferentes, como resposta a perguntas e análise de sentimentos, resultando em melhorias substanciais de precisão em comparação com o treinamento nesses conjuntos de dados do zero.
A arquitetura do transformador foi proposta na atenção do papel é tudo o que você precisa, usado para a tarefa de tradução da máquina neural (NMT), consistindo em:
Como mencionado no artigo:
" Propomos uma nova arquitetura de rede simples, o transformador, baseado apenas em mecanismos de atenção, dispensando completamente a recorrência e convoluções "
A principal idéia de atenção pode ser resumida conforme mencionado no artigo do Openai:
" ... todo elemento de saída é conectado a todos os elementos de entrada, e as ponderações entre eles são calculadas dinamicamente com base nas circunstâncias , um processo chamado atenção".
Com base nessa arquitetura (os transformadores de baunilha!), Os componentes do codificador ou decodificador podem ser usados sozinhos para permitir modelos genéricos pré-treinados pré-treinados que podem ser ajustados para tarefas a jusante, como classificação de texto, tradução, resumo, resposta a perguntas etc. por exemplo:
Esses modelos, Bert e GPT, por exemplo, podem ser considerados como o imagenet da PNL.
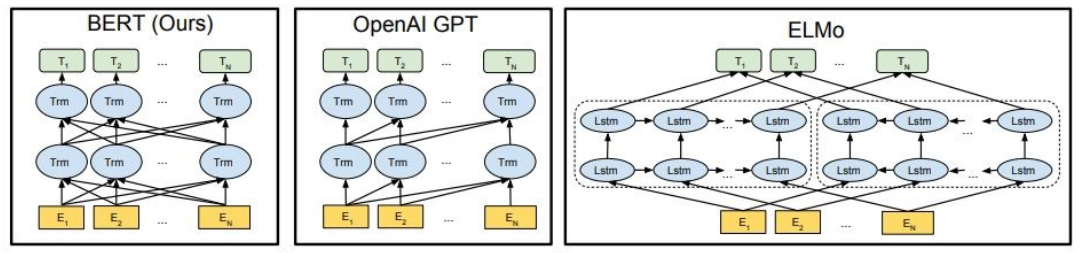
Como mostrado, Bert é profundamente bidirecional, o OpenAI GPT é unidirecional e Elmo é superficialmente bidirecional.
Representações pré-treinadas podem ser:
Modelos de linguagem contextual podem ser:
Nesta parte, vamos usar diferentes modelos de idiomas grandes
O GPT2 (um sucessor do GPT) é um modelo pré-treinado no idioma inglês usando um objetivo de modelagem de idiomas causal ( CLM ), treinado simplesmente para prever a próxima palavra em 40 GB de texto da Internet. Foi lançado pela primeira vez nesta página. O GPT2 exibe um amplo conjunto de recursos, incluindo a capacidade de gerar amostras de texto sintético condicional. Em tarefas de idioma, como resposta a perguntas, compreensão de leitura, resumo e tradução, o GPT2 começa a aprender essas tarefas com o texto bruto, usando dados de treinamento específicos da tarefa. O DISTILGPT2 é uma versão destilada do GPT2, pretende ser usada para casos de uso semelhantes, com o aumento da funcionalidade de ser menor e mais fácil de executar do que o modelo básico.
Aqui, carregamos um modelo GPT2 pré-treinado, pedimos ao modelo GPT2 para continuar nosso texto de entrada (prompt) e, finalmente, extrair recursos incorporados do modelo destilgpt2.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Bert é um modelo Transformers pré-treinado em um grande corpus de dados em inglês de maneira auto-supervisionada. Isso significa que foi pré-treinado apenas nos textos brutos, sem humanos que os rotulam de alguma forma com um processo automático para gerar entradas e etiquetas a partir desses textos. Mais precisamente, foi pré -levado com dois objetivos:
Neste exemplo, usaremos um modelo BERT pré-treinado para a tarefa de análise de sentimentos.
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
O GPT4all é um ecossistema para treinar e implantar modelos de grandes idiomas poderosos e personalizados que são executados localmente nas CPUs de grau de consumo.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
Experimente os seguintes modelos:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
A Falcon LLM é a série de modelos de idiomas grandes da TII, construída a partir do zero usando um pipeline de dados personalizado e treinamento distribuído. Os modelos Falcon-7B/40B são de última geração pelo seu tamanho, superando a maioria dos outros modelos nos benchmarks de PNL. De origem aberta vários artefatos:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
O LLAMA2 é uma família de grandes modelos de idiomas de acesso aberto de última geração lançados pela Meta Today, e estamos entusiasmados em apoiar totalmente o lançamento com uma integração abrangente em abraçar o rosto. O LLAMA 2 está sendo lançado com uma licença comunitária muito permissiva e está disponível para uso comercial. O código, os modelos pré-terenciados e os modelos de ajuste fino estão sendo lançados hoje
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
O CODET5+ é uma nova família de modelos de idiomas grandes de código aberto com uma arquitetura de codificador-decodificador que pode operar de maneira flexível em diferentes modos (ou seja, somente codificador, apenas decodificador e codificador-decodificador) para suportar uma ampla gama de tarefas de compreensão e geração de código.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
Para mais modelos, verifique o CodeTF do Salesforce, uma biblioteca baseada em transformadores do Python para modelos de idiomas de código (Code LLMS) e inteligência de código, fornecendo uma interface perfeita para treinamento e inferir em tarefas de inteligência de código, como resumo do código, tradução, geração de código e assim por diante.
? ️ conversar com modelos abertos de idiomas abertos
✅ A pesquisa de feixe sempre encontrará uma sequência de saída com maior probabilidade do que a pesquisa gananciosa, mas não é garantido para encontrar a saída mais provável.
Nos Transformers, simplesmente definimos o parâmetro num_return_sequências para o número de vigas de pontuação mais altas que devem ser retornadas. Certifique -se de que NUM_RETURN_SEMENCIES <= NUM_BEAMS!
✅ A pesquisa de feixe pode funcionar muito bem em tarefas em que a duração da geração desejada é mais ou menos previsível, como na tradução ou resumo da máquina. ? Mas esse não é o caso da geração aberta, onde o comprimento da saída desejado pode variar bastante, por exemplo, diálogo e geração de histórias. A pesquisa de feixe sofre fortemente de geração repetitiva. Como seres humanos, queremos que o texto gerado nos surpreenda e não seja chato/previsível (a pesquisa de feixe é menos surpreendente)
Nos transformadores, definimos do_Sample = true e desativamos a amostragem Top-K (mais sobre isso mais tarde) via top_k = 0.
???-? ?????????: K mais provável As próximas palavras são filtradas e a massa de probabilidade é redistribuída entre apenas as que as próximas palavras. O GPT2 adotou esse esquema de amostragem.
???-? ?????????: Em vez de amostrar apenas a partir das palavras K mais prováveis, na amostragem de Top-P escolhe do menor conjunto possível de palavras cuja probabilidade cumulativa excede a probabilidade p. A massa de probabilidade é então redistribuída nesse conjunto de palavras. Tendo definido P = 0,92, a amostragem Top-P escolhe o número mínimo de palavras para exceder 92% da massa de probabilidade.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ Embora o Top-P pareça mais elegante que o Top-K, ambos os métodos funcionam bem na prática. O TOP-P também pode ser usado em combinação com o Top-K, que pode evitar palavras com classificação muito baixa, permitindo alguma seleção dinâmica.
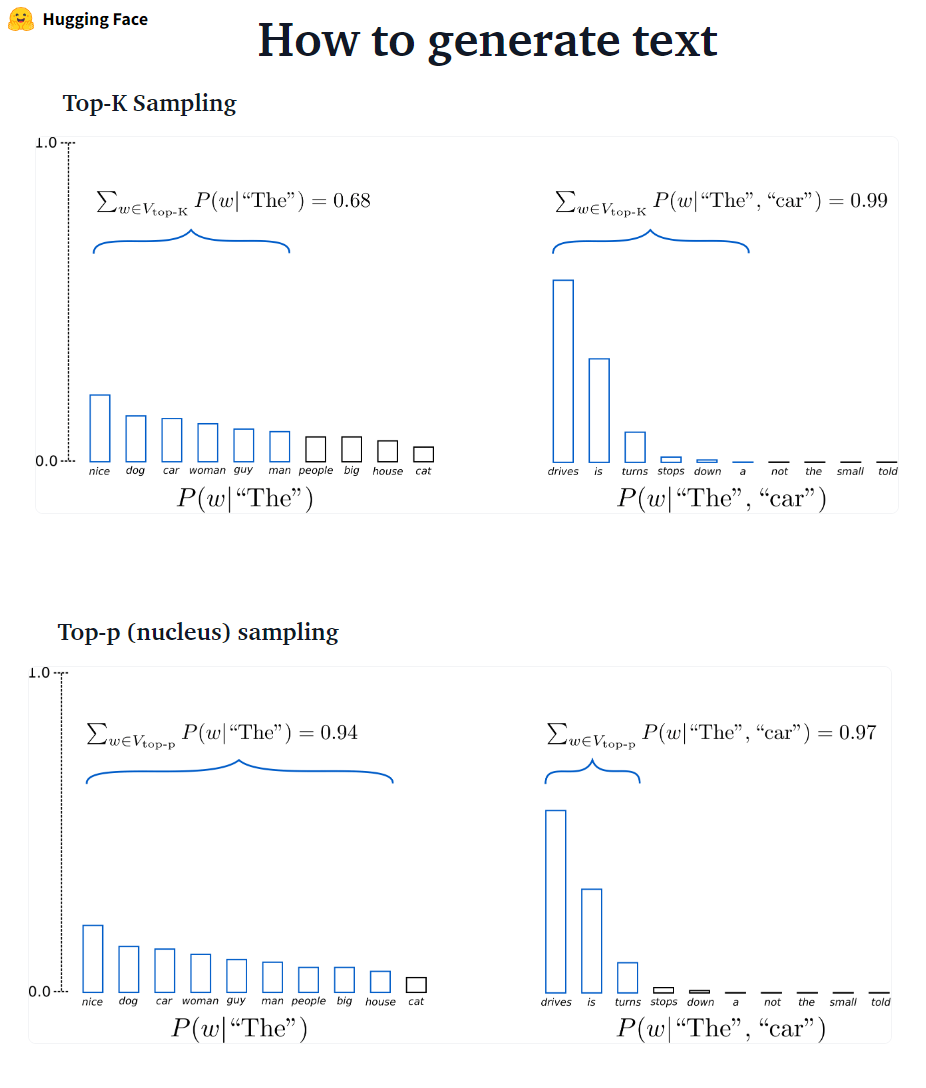
✅ Como métodos de decodificação ad-hoc, a amostragem Top-P e Top-K parece produzir texto mais fluente do que a pesquisa tradicional gananciosa-e a pesquisa de feixe na geração de linguagem aberta.
A engenharia rápida é o processo de projetar os prompts (entrada de texto) para um modelo de idioma para gerar a saída necessária. A engenharia imediata envolve a seleção de palavras -chave apropriadas, o fornecimento de contexto, sendo claro e específico de uma maneira que direciona o comportamento do modelo de idioma que atinge respostas desejadas. Através da engenharia rápida, podemos controlar o tom, o estilo, o comprimento, etc. de um modelo, sem ajuste fino.
A aprendizagem de tiro zero envolve pedir ao modelo para fazer previsões sem fornecer exemplos (zero tiro), por exemplo:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
Quando o Zero-Shot não é bom o suficiente, é recomendável ajudar o modelo, fornecendo exemplos no prompt que leva a poucos pedidos.
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
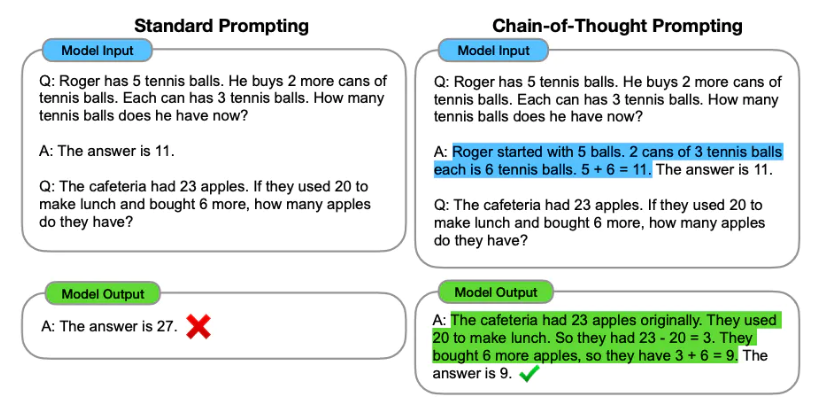
Além de prontamente engenharia , podemos considerar mais opções:
Para obter mais informações rápidas sobre engenharia, consulte o guia de engenharia rápido que contém todos os artigos mais recentes, guias de aprendizado, palestras, referências e ferramentas.
Os LLMs de ajuste fino nos conjuntos de dados a jusante resultam em enormes ganhos de desempenho quando comparados ao uso do LLMS pré-treinado pronta para uso (inferência de tiro zero, por exemplo). No entanto, à medida que os modelos ficam cada vez maiores, o ajuste fino total se torna inviável para treinar no hardware do consumidor. Além disso, armazenar e implantar modelos de ajuste fino independentemente para cada tarefa a jusante se torna muito caro, porque os modelos ajustados são do mesmo tamanho que o modelo pré-treinamento original. As abordagens de ajuste fino (PEFT) com eficiência de parâmetro devem resolver os dois problemas! As abordagens de PEFT permitem que você obtenha desempenho comparável ao ajuste fino completo, e possui apenas um pequeno número de parâmetros treináveis. Por exemplo:
Ajuste rápido: um mecanismo simples, porém eficaz, para aprender “instruções suaves” a condicionar modelos de linguagem congelada a executar tarefas específicas a jusante. Assim como os avisos de texto de engenharia, os avisos suaves são concatenados para o texto de entrada. Mas, em vez de selecionar a partir dos itens de vocabulário existentes, os "tokens" do prompt Soft são vetores aprendidos. Isso significa que um prompt suave pode ser otimizado de ponta a ponta em um conjunto de dados de treinamento, como mostrado abaixo: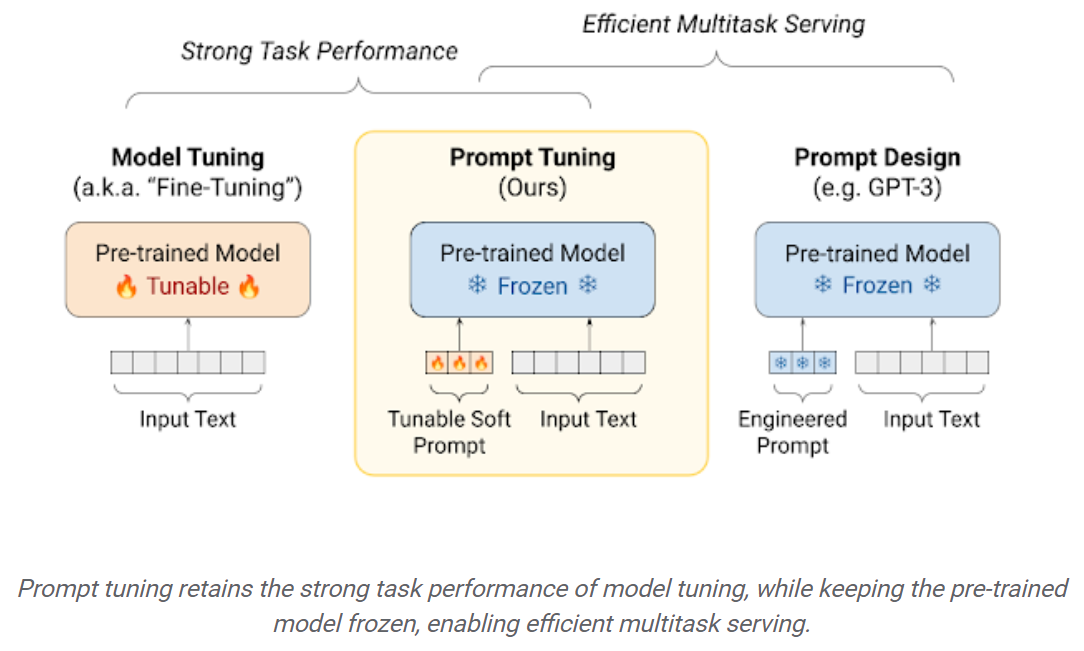
A adaptação de LORA de baixo rank do LLMS é um método que congela os pesos do modelo pré-treinado e injeta matrizes de decomposição de classificação treináveis em cada camada da arquitetura do transformador. Reduzindo bastante o número de parâmetros treináveis para tarefas a jusante. A figura abaixo, a partir deste vídeo, explica a idéia principal: 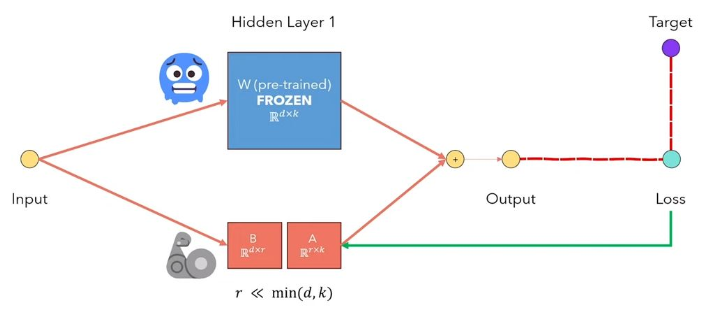
Os grandes modelos de linguagem são geralmente de uso geral, menos eficazes para tarefas específicas de domínio. No entanto, eles podem ser ajustados em algumas tarefas, como análise de sentimentos. Para taks mais complexos que exigem conhecimento externo, é possível criar um sistema baseado em modelos de idiomas que acessa fontes de conhecimento externas para concluir as tarefas necessárias. Isso permite uma precisão mais factual e ajuda a mitigar o problema da "alucinação". Conforme mostrado no Farder abaixo:
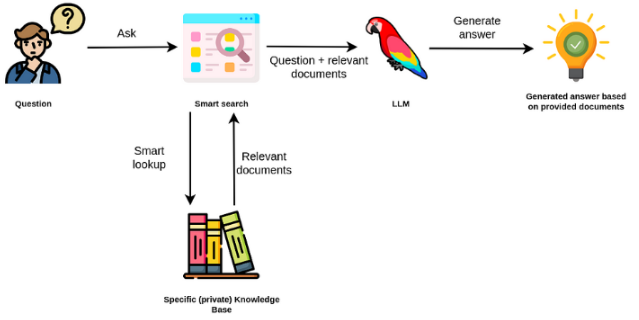
Nesse caso, em vez de usar o LLMS para acessar seu conhecimento interno, usamos o LLM como uma interface de linguagem natural ao nosso conhecimento externo. A primeira etapa é converter os documentos e qualquer consulta do usuário em um formato compatível para executar a pesquisa de relevância (converta texto em vetores ou incorporação). O prompt original do usuário é então anexado a documentos relevantes / semelhantes na fonte de conhecimento externa (como contexto). O modelo responde às perguntas com base no contexto externo fornecido.
Os grandes modelos de linguagem (LLMs) estão emergindo como uma tecnologia transformadora. No entanto, o uso desses LLMs isoladamente geralmente é insuficiente para criar aplicativos verdadeiramente poderosos. Langchain pretende ajudar no desenvolvimento de tais aplicações.
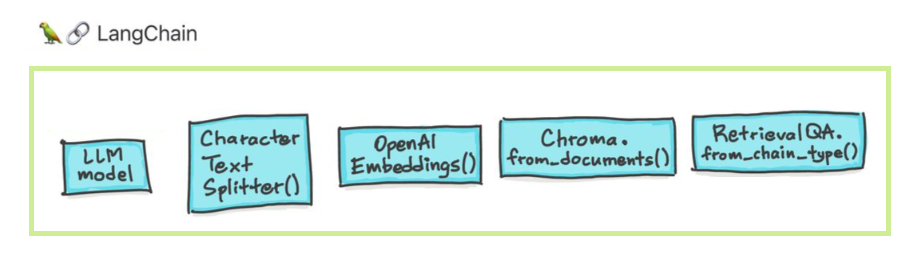
Existem seis áreas principais com as quais Langchain foi projetado para ajudar. Estes são, em uma ordem crescente de complexidade:
Isso inclui gerenciamento imediato, otimização imediata, uma interface genérica para todos os LLMs e utilitários comuns para trabalhar com o LLMS. LLMS e modelos de bate -papo são sutilmente, mas importante, diferentes. LLMS em Langchain consulte os modelos de conclusão de texto puro. As APIs que eles envolvem levam um prompt de string como entrada e saída uma conclusão da string. O GPT-3 do OpenAI é implementado como um LLM. Os modelos de bate -papo geralmente são apoiados pelo LLMS, mas sintonizados especificamente para ter conversas.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
Você também pode acessar informações específicas do provedor que são retornadas. Esta informação não é padronizada entre os provedores.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
O aviso para os modelos de bate -papo é uma lista de mensagens de bate -papo. Cada mensagem de bate -papo está associada ao conteúdo e um parâmetro adicional chamado função. Por exemplo, na API de conclusão de bate -papo do OpenAI, uma mensagem de bate -papo pode ser associada a um assistente de IA, uma função humana ou um sistema.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
As cadeias vão além de uma única chamada LLM e envolvem sequências de chamadas (seja para um LLM ou um utilitário diferente). O Langchain fornece uma interface padrão para cadeias, muitas integrações com outras ferramentas e cadeias de ponta a ponta para aplicações comuns. A cadeia muito genericamente pode ser definida como uma sequência de chamadas para componentes, que podem incluir outras cadeias.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
A geração aumentada de dados envolve tipos específicos de cadeias que primeiro interagem com uma fonte de dados externa para buscar dados para uso na etapa de geração. Os exemplos incluem perguntas/respostas sobre fontes de dados específicas.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
Pesquisa de similaridade
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
Os agentes envolvem um LLM tomar decisões sobre quais ações tomarem, tomar essa ação, ver uma observação e repetir isso até que fosse feito. Langchain fornece uma interface padrão para os agentes, uma seleção de agentes para escolher e exemplos de agentes de ponta a ponta. A idéia principal dos agentes é usar um LLM para escolher uma sequência de ações a serem executadas. Nas cadeias, uma sequência de ações é codificada (no código). Nos agentes, um modelo de idioma é usado como um mecanismo de raciocínio para determinar quais ações tomar e em qual ordem.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
A memória refere -se ao estado persistente entre chamadas de uma cadeia/agente. O Langchain fornece uma interface padrão para a memória, uma coleção de implementações de memória e exemplos de cadeias/agentes que usam memória.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
Podemos usar métodos diferentes para conversar com nossos documentos. Não há necessidade de ajustar todo o LLM, em vez disso, podemos fornecer o contexto certo, juntamente com a nossa pergunta ao modelo pré-treinado e simplesmente obter as respostas com base nos documentos fornecidos.
Aqui, conversamos com este bom artigo intitulado Transformers sem dor? Fazendo perguntas relacionadas a transformadores, atenção, codificador-decidido etc. ao utilizar o poderoso modelo de palmeira pelo Google e a estrutura Langchain para o desenvolvimento de aplicativos alimentados por modelos de idiomas.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
Pergunta : ? 'Do que se trata esses documentos?'
Responder : ? "Os documentos são sobre transformadores, que são um tipo de rede neural que foi usada com sucesso em processamento de linguagem natural e tarefas de visão computacional".
Pergunta : ? 'Qual é a idéia principal dos transformadores?'
Responder : ? "A principal idéia dos transformadores é usar mecanismos de atenção para modelar dependências de longo alcance em sequências".
Pergunta : ? 'O que é a codificação posicional?'
Responder : ? 'A codificação posicional é uma técnica usada para representar a ordem das palavras em uma sequência.'
Pergunta : ? 'Como os vetores de consulta, chave e valor são usados?'
Responder : ? 'O vetor de consulta é usado para calcular uma soma ponderada dos valores através das teclas. Especificamente: Q POT PRODUTO Todas as teclas, depois Softmax para obter pesos e, finalmente, usar esses pesos para calcular uma soma ponderada dos valores. '
Pergunta : ? 'Como começar a usar transformadores?'
Responder : ? 'Para começar a usar Transformers, você pode usar a Biblioteca de Transformers do Huggingface. Esta biblioteca fornece milhares de modelos pré -terem realizado tarefas em textos como classificação, extração de informações, resposta a perguntas, resumo, tradução, geração de texto, etc. em mais de 100 idiomas. '
Você pode experimentar seus próprios documentos e perguntas!
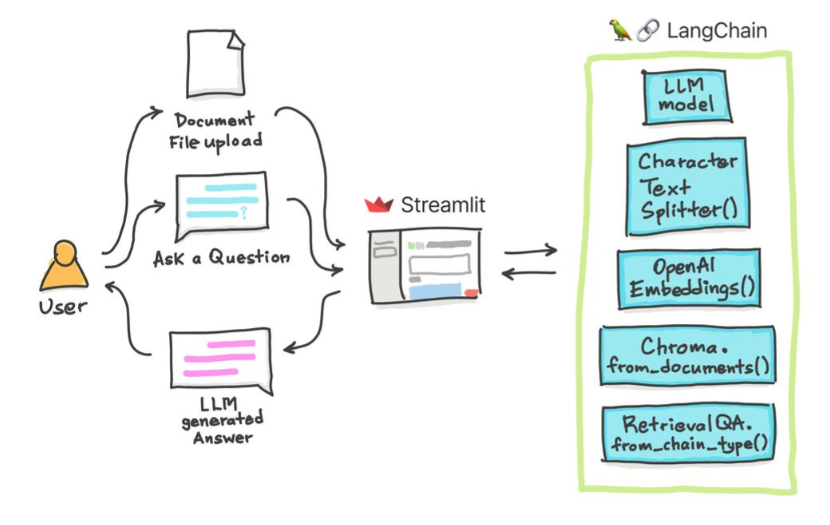
Nestes tutoriais simples: como obter respostas de documentos de texto , arquivos PDF e até vídeos do YouTube usando o banco de dados do Chroma Vector, o Palm LLM pelo Google e uma cadeia de respostas de perguntas da Langchain. Por fim, use o streamlit para desenvolver e hospedar o aplicativo da web. Você precisará usar seu google_api_key (você pode obter um do Google). A arquitetura do sistema é a seguinte:
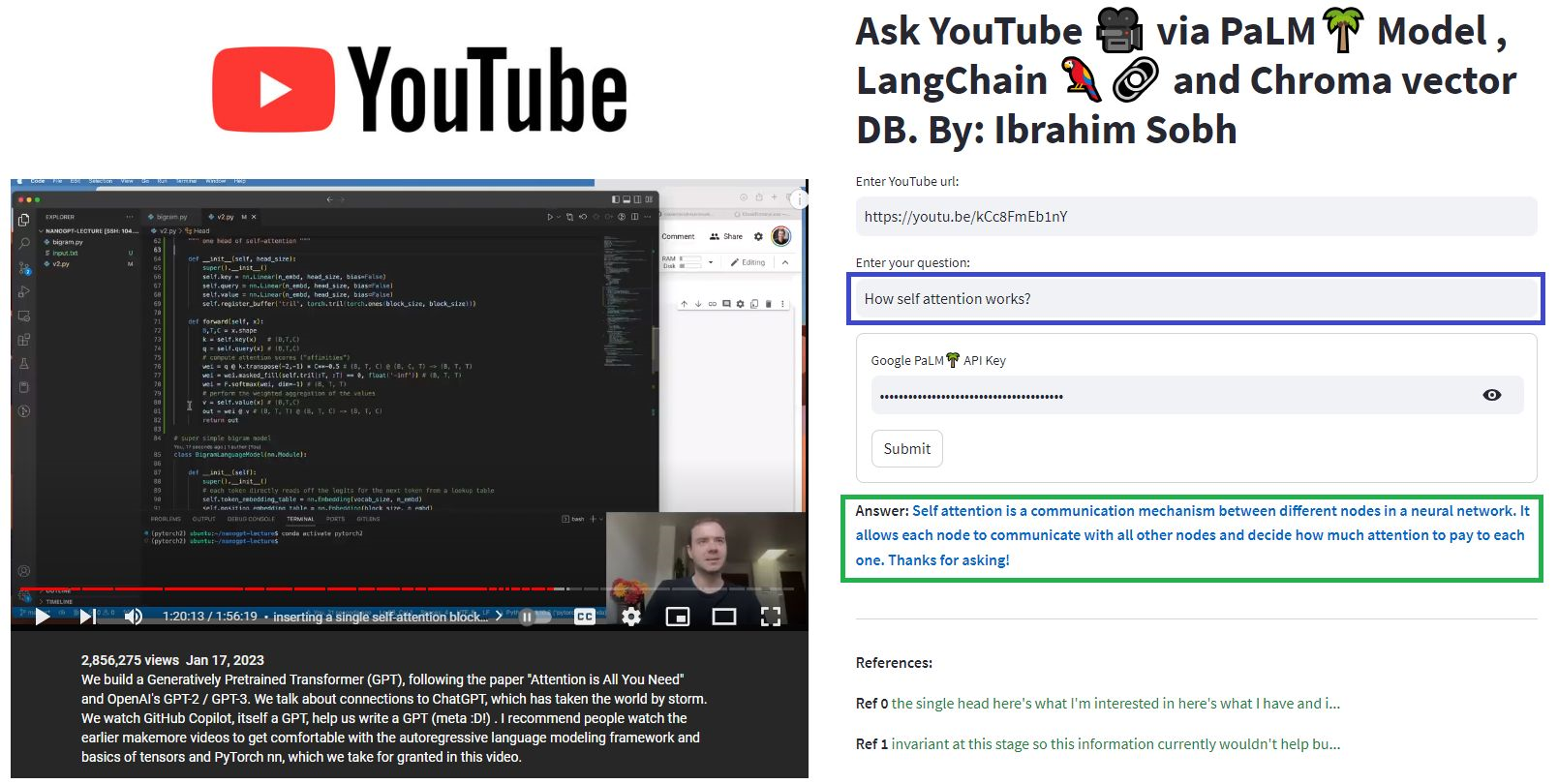
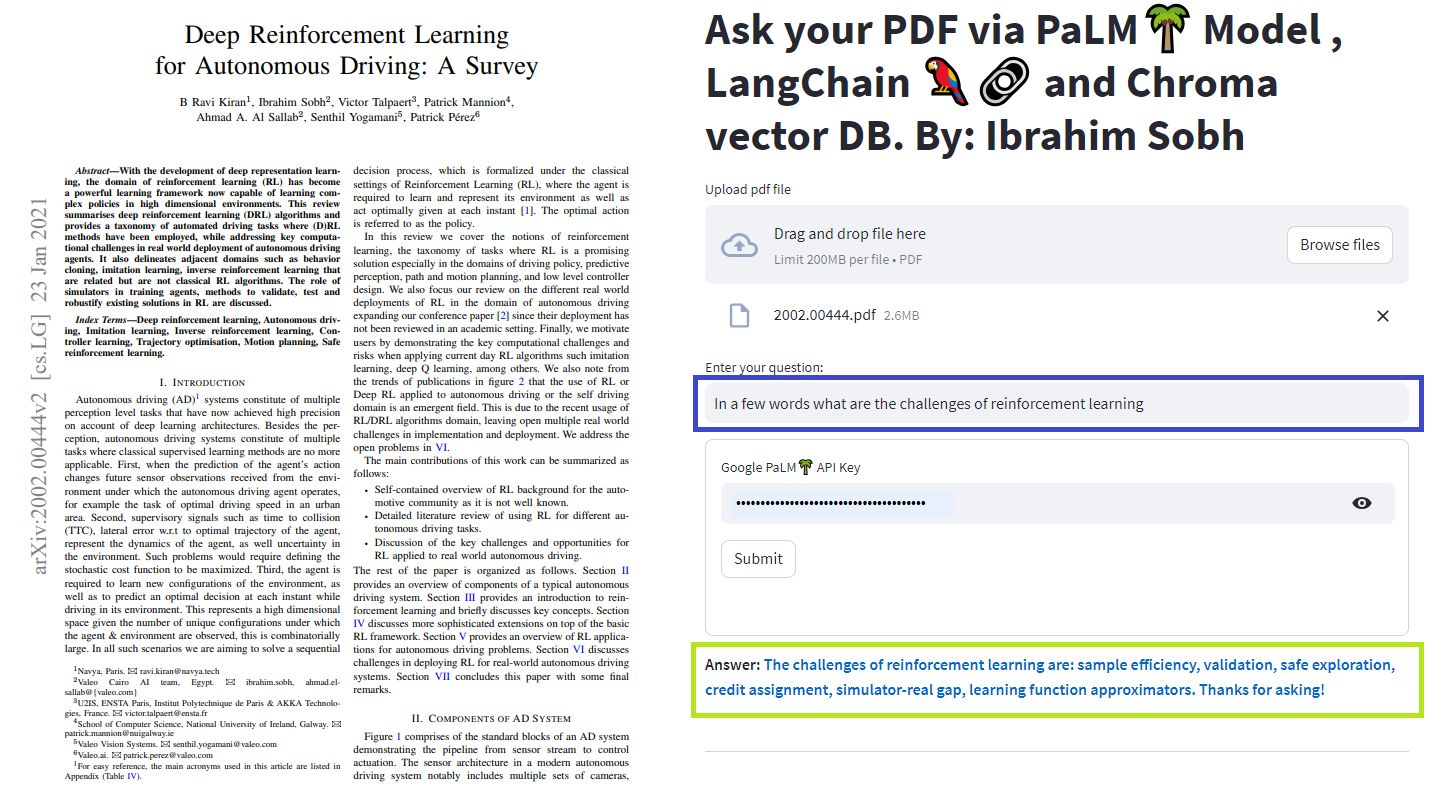
Há uma diferença entre avaliar um LLM e avaliar um sistema baseado em LLM. Normalmente, após o pré-treinamento genérico , os LLMs são avaliados em benchmarks padrão:
Os sistemas LLMS podem resumir o texto, fazer a resposta à pergunta, encontrar o sentimento de um texto, fazer tradução e muito mais. Com base no sistema, a avaliação pode ser a seguinte:
Por exemplo, em caso de sistema de resposta a perguntas , precisamos de pares de perguntas e respostas em nosso conjunto de avaliações. Podemos usar anotadores humanos para criar pares de perguntas e respostas padrão-ouro manualmente. However, it is costly and time-consuming. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
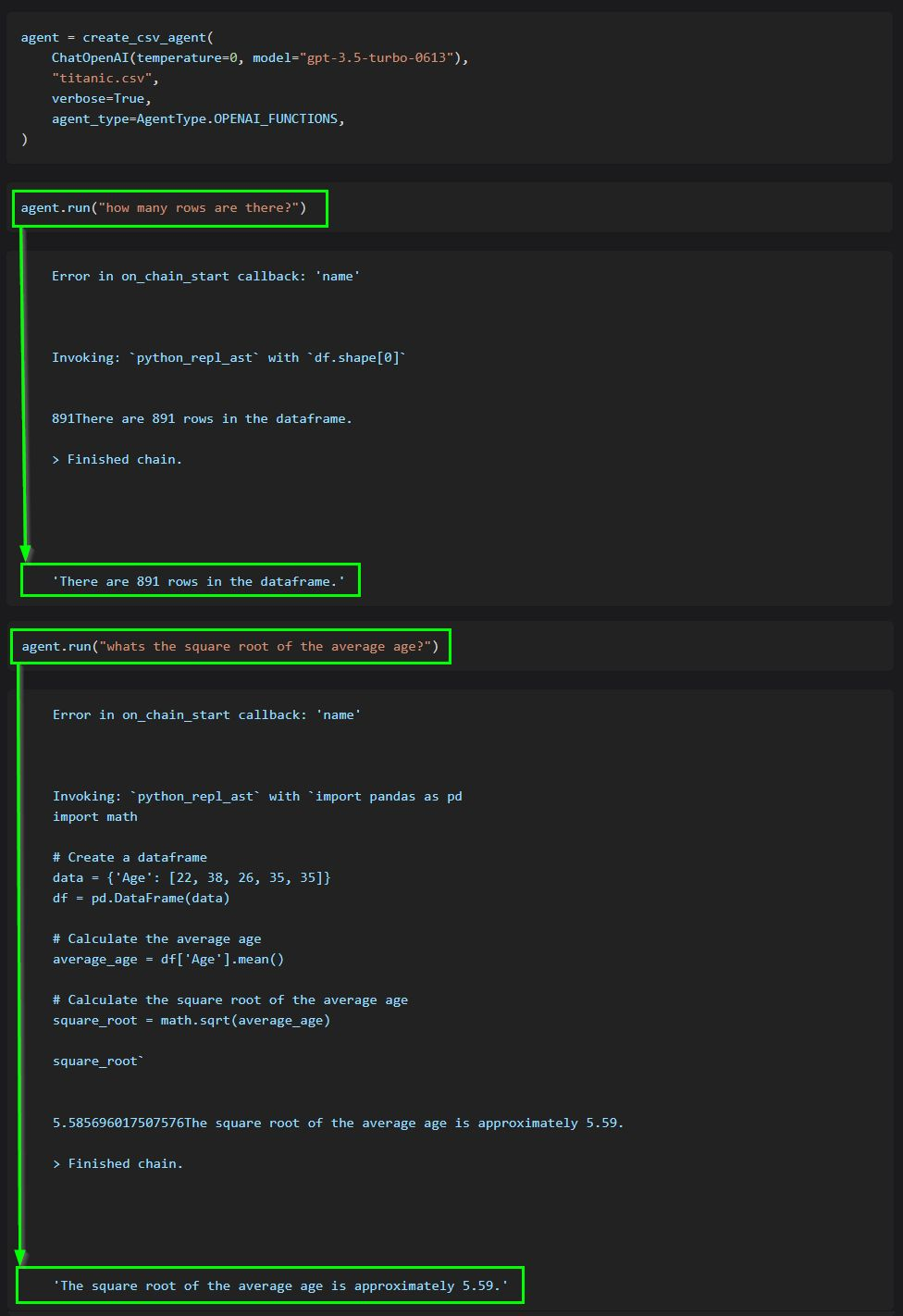
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
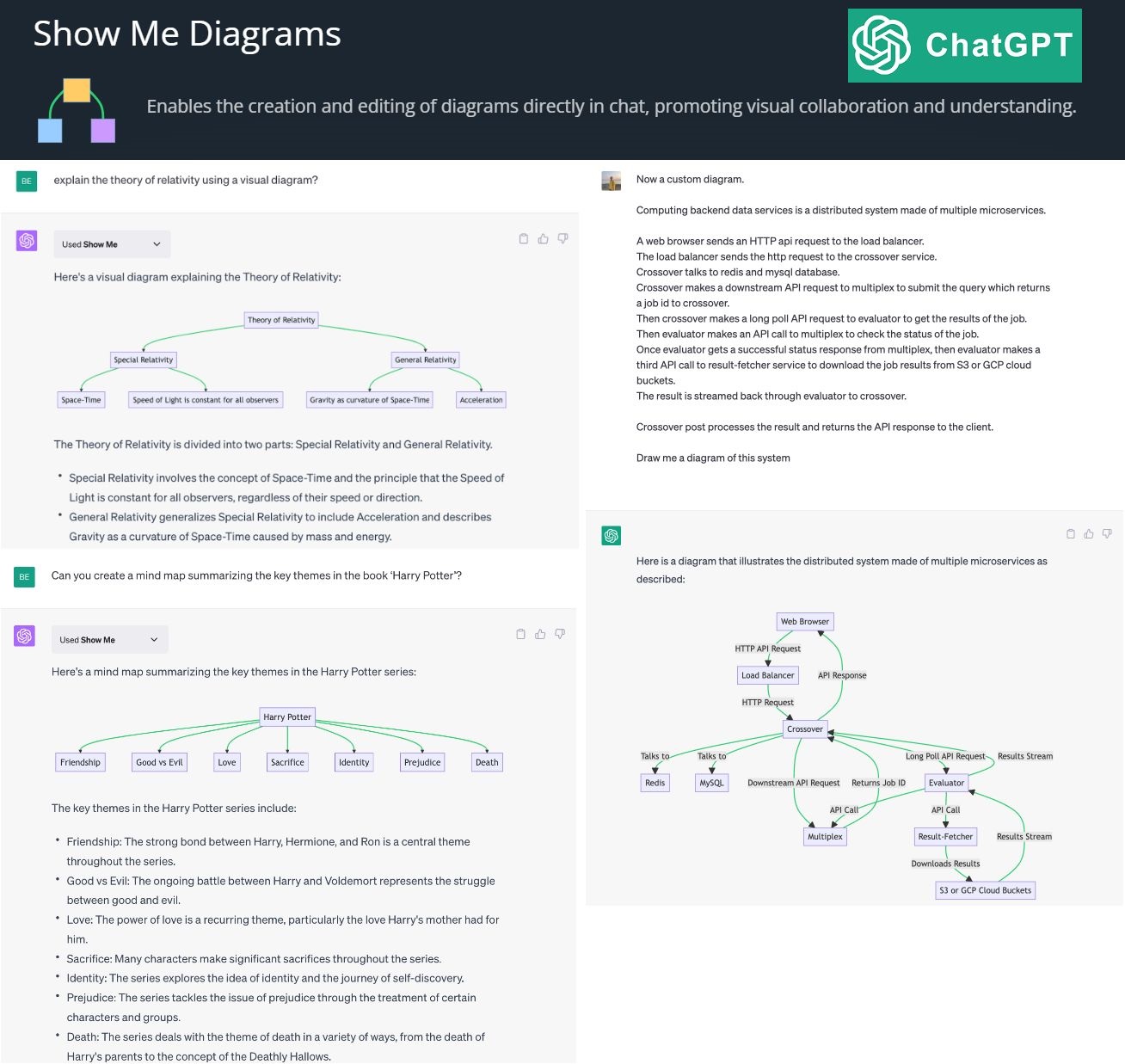
By creating and editing diagrams via Show Me Diagrams
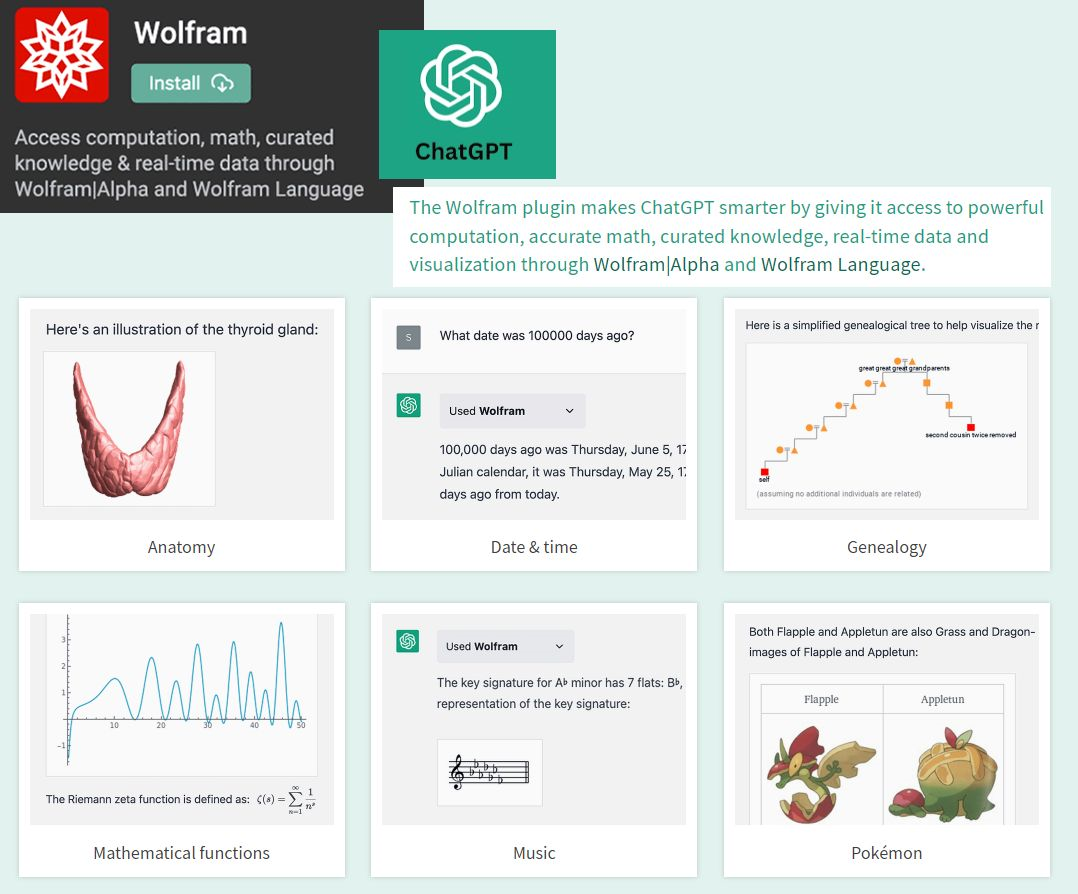
By accessing the power of mathematics provided by Wolfram
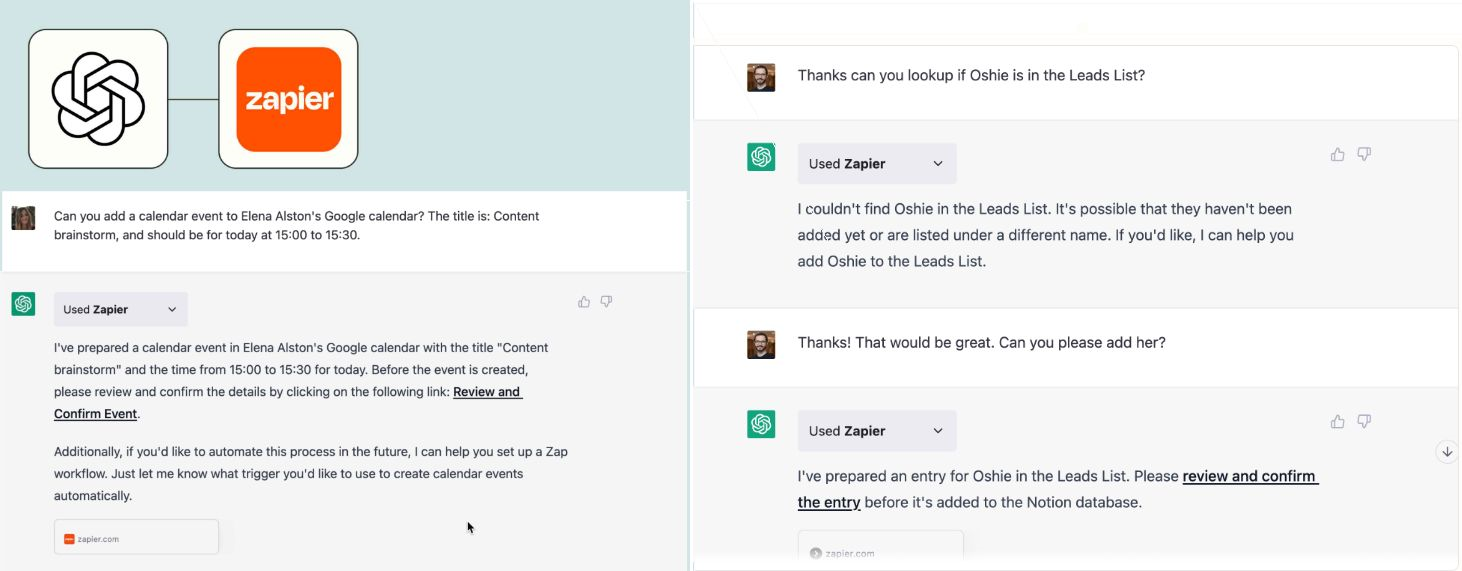
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


