llms
1.0.0
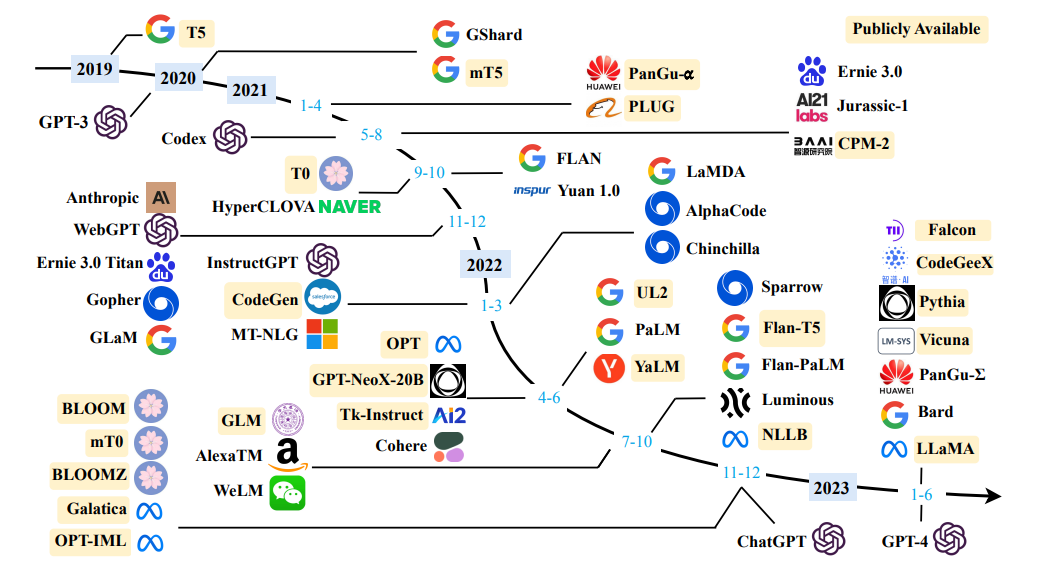 大規模な言語モデルの調査
大規模な言語モデルの調査
単純な定義:言語モデリングは、次に来る単語を予測するタスクです。
「犬はで遊んでいます...」
言語モデルの主な目的は、文に確率を割り当て、より可能性の高い文を区別することです。
音声認識には、音響モデル(音声信号)だけでなく、言語モデルも使用します。同様に、光学文字認識(OCR)には、ビジョンモデルと言語モデルの両方を使用します。言語モデルは、このような認識システムにとって非常に重要です。
時には、明確ではない文を聞いたり読んだりしますが、言語モデルを使用して、騒々しいビジョン/音声入力にもかかわらず、それを高い精度で認識することができます。
言語モデルは次のいずれかを計算します。
言語モデリングは、多くのNLPタスクのサブコンポーネントであり、特にテキストの生成やテキストの確率の推定を含むタスクのサブコンポーネントです。
チェーンルール:
$ p(水、水、そう、透明)= p(the)×p(水| the)×p(is | the、water)×p(so | the、water、is)×p(clear | the、water、so、so)$
何が起こったのですか?チェーンルールは、文で単語の共同確率を計算するために適用されます。
大量のテキスト(ウィキペディアなどのコーパス)を使用して、単語の頻度について統計を収集し、これらを使用して次の単語を予測します。たとえば、これらの3つの単語の生徒が開いた後にワードwが来る確率は、次のように推定できます。
上記の例は4グラムモデルです。そして、私たちは得るかもしれません:
「本」という言葉は、この文脈では「車」よりも可能性が高いと結論付けることができます。
「学生がオープンした」前に、以前のコンテキストを無視しました
したがって、任意のテキストは、次の単語の出力確率分布からサンプリングすることにより、開始ワード(s)を与えられた言語モデルから生成できます。
あらゆる種類のテキストでLMをトレーニングしてから、そのスタイル(ハリーポッターなど)でテキストを生成できます。
トリグラム、4グラム、5グラム、およびnグラムに拡張できます。
一般に、これは言語には長距離依存関係があるため、言語の不十分なモデルです。ただし、実際には、これらの3,4グラムはほとんどのアプリケーションでうまく機能します。
GoogleのN-GRAMモデルはあなたに属します:Google Researchは、さまざまなR&DプロジェクトにWord N-Gramモデルを使用しています。 Google N-Gramは、1,024,908,267,229ワードの実行中のテキストを処理し、少なくとも40回表示する1,176,470,663の5ワードシーケンスすべてにカウントを公開しました。
言語学データコンソーシアムLDCからのテキストの数は次のとおりです。
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
以下は、このコーパスの4グラムデータの例です。
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
たとえば、「表示として機能する」という4つの単語のシーケンスは、コーパスで72回見られています。
時には、推定するのに十分なデータがない場合があります。 nを増やすと、スパースの問題が悪化します。通常、私たちは5より大きいnを持つことはできません。
NLMは通常(常にではありませんが)RNNを使用して単語のシーケンス(文、段落など)を学習するため、次の単語を予測できます。
利点:
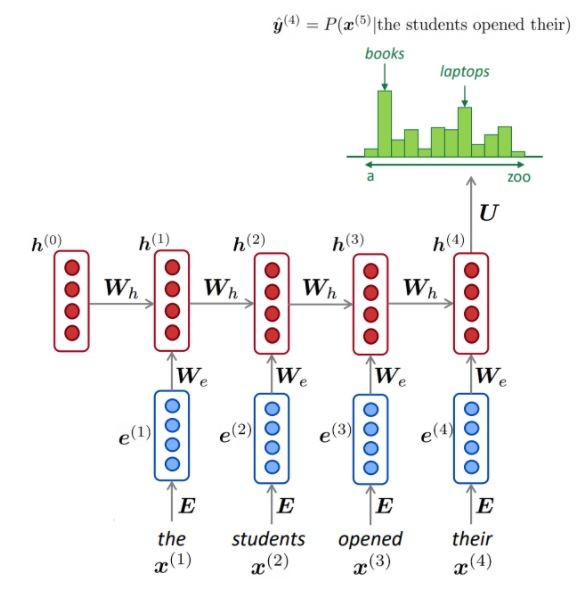
描かれているように、各ステップで、語彙に対する次の単語の確率分布があります。
NLMのトレーニング:
長いシーケンス学習の例:
短所:
LMは、スピーチ認識、機械翻訳、要約など、さまざまなアプリケーションで入力(音声、画像(OCR)、テキストなど)のテキスト条件を生成するために使用できます。
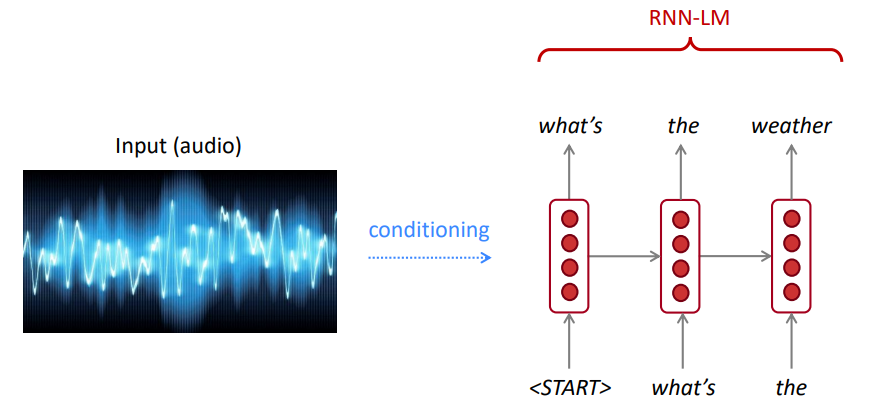
私たちの言語モデルは、悪い文よりも良い(おそらく)文を好むのですか?
言語モデルの標準的な評価メトリックは困惑です困惑はテストセットの逆確率であり、単語の数によって正規化されています
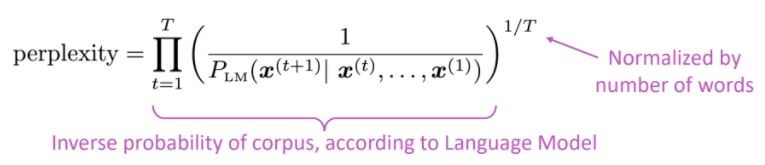
低い困惑=より良いモデル
困惑はブランチファクターに関連しています。平均して、次に発生する可能性のあるものの数。
RNNの代わりに、注意を使って大規模な事前訓練を受けたモデルを使用しましょう
何が問題ですか?自然言語処理(NLP)の最大の課題の1つは、多くの異なるタスクのトレーニングデータの不足です。ただし、最新のディープラーニングベースのNLPモデルは、数百万、または数十億の注釈付きトレーニングの例で訓練されると改善します。
トレーニング前は解決策です。このギャップを埋めるために、膨大な量の発表されていないテキストを使用して、汎用言語表現モデルをトレーニングするためのさまざまな手法が開発されました。事前に訓練されたモデルは、質問の回答やセンチメント分析などのさまざまなタスクの小さなデータで微調整でき、これらのデータセットのトレーニングとゼロからのトレーニングと比較して、実質的な精度の改善をもたらすことができます。
トランスアーキテクチャは、次のような神経機械翻訳タスク(NMT)に使用される必要なすべての注意を紙で提案しました。
論文で述べたように:
「私たちは、注意メカニズムのみに基づいて、再発と畳み込みを完全に分配する新しいシンプルなネットワークアーキテクチャである変圧器を提案します」
注意の主なアイデアは、Openaiの記事に記載されているように要約することができます。
「 ...すべての出力要素はすべての入力要素に接続されており、それらの間の重みは状況、注意と呼ばれるプロセスに基づいて動的に計算されます。 」
このアーキテクチャ(バニラトランス!)に基づいて、エンコーダーまたはデコーダーコンポーネントは、テキスト分類、翻訳、要約、質問への回答などのダウンストリームタスクに微調整できる大規模な事前に訓練されたジェネリックモデルを可能にするために単独で使用できます。
たとえば、これらのモデルは、BERTとGPTをNLPのイメージネットと見なすことができます。
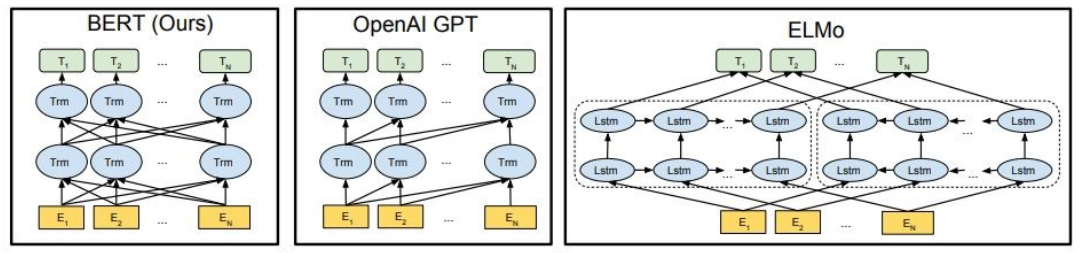
示されているように、Bertは深く双方向であり、Openai GPTは単方向であり、Elmoは浅く双方向です。
事前に訓練された表現は次のとおりです。
コンテキスト言語モデルは次のようになります。
この部分では、さまざまな大きな言語モデルを使用します
GPT2(GPTの後継者)は、因果言語モデリング( CLM )目的を使用して英語の事前に訓練されたモデルであり、40GBのインターネットテキストの次の単語を予測するように訓練されています。このページで最初にリリースされました。 GPT2は、条件付き合成テキストサンプルを生成する機能など、幅広い機能セットを表示します。質問への回答、読解、要約、翻訳などの言語タスクでは、GPT2は、タスク固有のトレーニングデータを使用して、生のテキストからこれらのタスクを学び始めます。 Distilgpt2はGPT2の蒸留バージョンであり、ベースモデルよりも小さく実行が容易であるという機能が向上し、同様のユースケースに使用することを目的としています。
ここでは、事前に訓練されたGPT2モデルをロードし、GPT2モデルに入力テキスト(プロンプト)を継続するように依頼し、最後にdistilgpt2モデルから埋め込み機能を抽出します。
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Bertは、英語データの大規模なコーパスで自己監視された方法で事前に訓練されたトランスモデルです。これは、生のテキストのみで事前に訓練されており、それらのテキストから入力とラベルを生成するための自動プロセスで人間がラベル付けされていないことを意味します。より正確には、それは2つの目的で前提とされていました。
この例では、センチメント分析タスクに事前に訓練されたBERTモデルを使用します。
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4allは、消費者グレードのCPUでローカルに実行される強力でカスタマイズされた大規模な言語モデルをトレーニングおよび展開するエコシステムです。
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
次のモデルを試してください。
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLMは、カスタムデータパイプラインと分散トレーニングを使用して、ゼロから構築されたTIIの大規模な言語モデルのフラッグシップシリーズです。 Falcon-7B/40Bモデルは、サイズの最先端であり、NLPベンチマーク上の他のほとんどのモデルを上回っています。オープンソースの多くのアーティファクト:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
Llama2は、Metaが今日リリースした最先端のオープンアクセス大規模な言語モデルのファミリーであり、Faceの包括的な統合で発売を完全にサポートできることを嬉しく思います。 Llama 2は、非常に寛容なコミュニティライセンスでリリースされており、商業用に利用できます。コード、前提型モデル、および微調整されたモデルはすべて今日リリースされています
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
Codet5+は、異なるモード(つまりエンコーダーのみ、デコーダーのみ、エンコーダデコーダー)で柔軟に動作できるエンコーダーデコーダーアーキテクチャを備えたオープンコードの大規模言語モデルの新しいファミリです。
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
その他のモデルについては、SalesforceのCodetF、コード大規模な言語モデル(コードLLM)およびコードインテリジェンス用のPython TransformerベースのライブラリであるCodetFをチェックして、コード要約、翻訳、コード生成などのコードインテリジェンスタスクのトレーニングと推論のためのシームレスなインターフェイスを提供します。
?§オープンな大型言語モデルとチャットします
beam検索では、貪欲な検索よりも高い確率のある出力シーケンスが常にありますが、最も可能性の高い出力を見つけることは保証されていません。
トランスでは、パラメーターnum_return_sequencesを返す必要がある最高のスコアリングビームの数に設定するだけです。そのnum_return_sequences <= num_beams!
beamビーム検索は、機械の翻訳や要約のように、目的の生成の長さが多かれ少なかれ予測可能なタスクで非常にうまく機能します。しかし、これは、対話やストーリー生成など、目的の出力長が大きく異なる可能性があるオープンエンドの世代の場合ではありません。ビーム検索は、繰り返しの生成に大きく苦しんでいます。人間として、私たちは生成されたテキストが私たちを驚かせ、退屈/予測可能ではないことを望んでいます(?ビーム検索は驚くことではありません)
トランスでは、do_sample = trueを設定し、top-k = 0を介してtop-kサンプリングを非アクティブ化します(これについては後で詳しく説明します)。
??? - ? ?????????:最も可能性の高い次の単語がフィルタリングされ、確率質量はこれらのk次の単語のみで再分配されます。 GPT2はこのサンプリングスキームを採用しました。
??? - ? ?????????:最も可能性の高いk単語からのみサンプリングする代わりに、累積確率が確率pを超える可能性のある単語の最小セットから選択します。その後、確率質量は、この一連の単語の中に再配布されます。 P = 0.92を設定すると、TOP-Pサンプリングは、確率質量の92%を超える最小単語数を選択します。
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
top-pはトップKよりもエレガントに見えますが、両方の方法は実際にはうまく機能します。 TOP-Pは、TOP-Kと組み合わせて使用することもできます。これにより、ランク付けされた単語が非常に低くなり、動的な選択が可能になります。
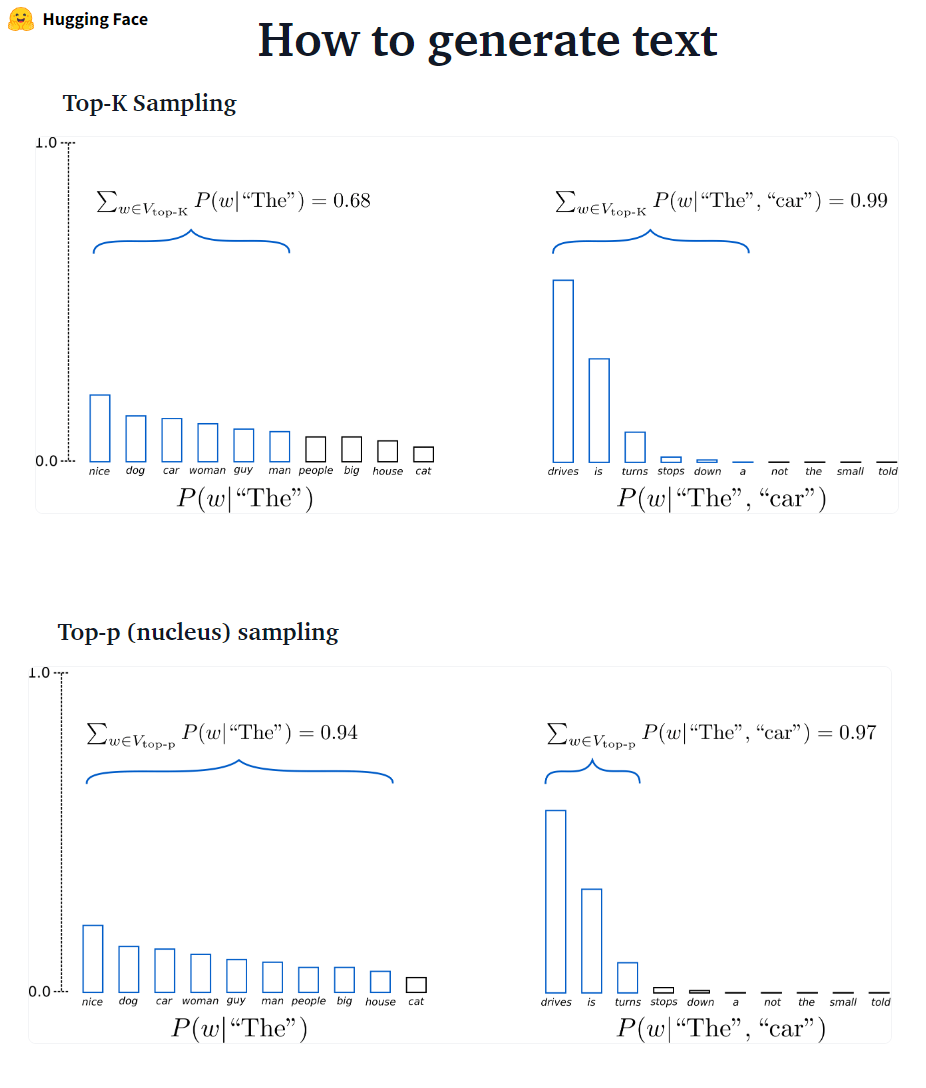
Ad-Hoc Decodingメソッドとして、TOP-PおよびTOP-Kサンプリングは、従来の貪欲よりも流fluentなテキストを生成し、オープンエンド言語生成のビーム検索を作成するようです。
プロンプトエンジニアリングは、必要な出力を生成するための言語モデルのプロンプト(テキスト入力)を設計するプロセスです。プロンプトエンジニアリングには、適切なキーワードを選択し、コンテキストを提供し、望ましい応答を達成する言語モデルの動作を指示する方法で明確かつ具体的であることが含まれます。迅速なエンジニアリングを通じて、モデルのトーン、スタイル、長さなどを微調整せずに制御できます。
ゼロショット学習には、例を提供せずにモデルに予測を行うように求めることが含まれます(ゼロショット)。
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
ゼロショットが十分ではない場合は、少数のショットプロンプトにつながるプロンプトに例を提供することでモデルを支援することをお勧めします。
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
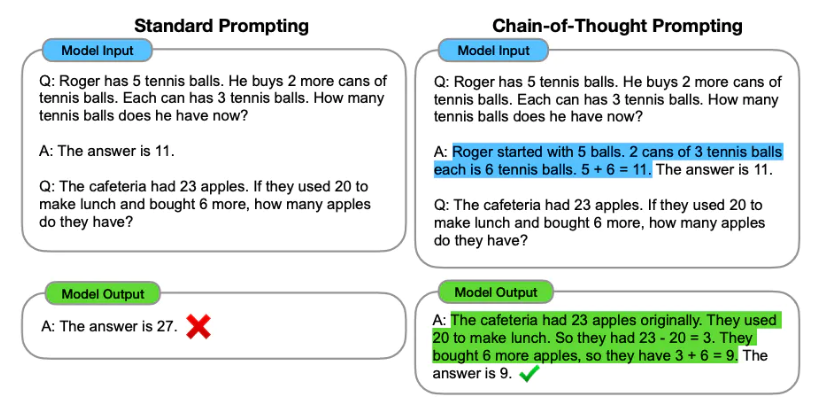
迅速なエンジニアリングに加えて、より多くのオプションを検討する場合があります。
より迅速なエンジニアリング情報については、すべての最新の論文、学習ガイド、講義、参照、ツールを含むプロンプトエンジニアリングガイドを参照してください。
下流のデータセットでLLMを微調整すると、前処理されたLLMSをすぐに使用する場合と比較すると、パフォーマンスが大きくなります(たとえば、ゼロショット推論など)。ただし、モデルが大きくなり、大きくなるにつれて、完全な微調整は消費者ハードウェアでトレーニングすることができません。さらに、微調整されたモデルは元の前提条件モデルと同じサイズであるため、下流タスクごとに微調整されたモデルを個別に保存および展開することは非常に高価になります。パラメーター効率の高い微調整(PEFT)アプローチは、両方の問題に対処することを目的としています! PEFTアプローチを使用すると、少数のトレーニング可能なパラメーターのみを持っている間、完全な微調整に匹敵するパフォーマンスを取得できます。例えば:
プロンプトチューニング:「ソフトプロンプト」を学習するためのシンプルで効果的なメカニズムは、特定のダウンストリームタスクを実行するための凍結言語モデルを条件付けます。エンジニアリングされたテキストプロンプトと同様に、ソフトプロンプトは入力テキストに連結されます。しかし、既存の語彙アイテムから選択するのではなく、ソフトプロンプトの「トークン」は学習可能なベクトルです。これは、以下に示すように、トレーニングデータセットでソフトプロンプトをエンドツーエンドで最適化できることを意味します。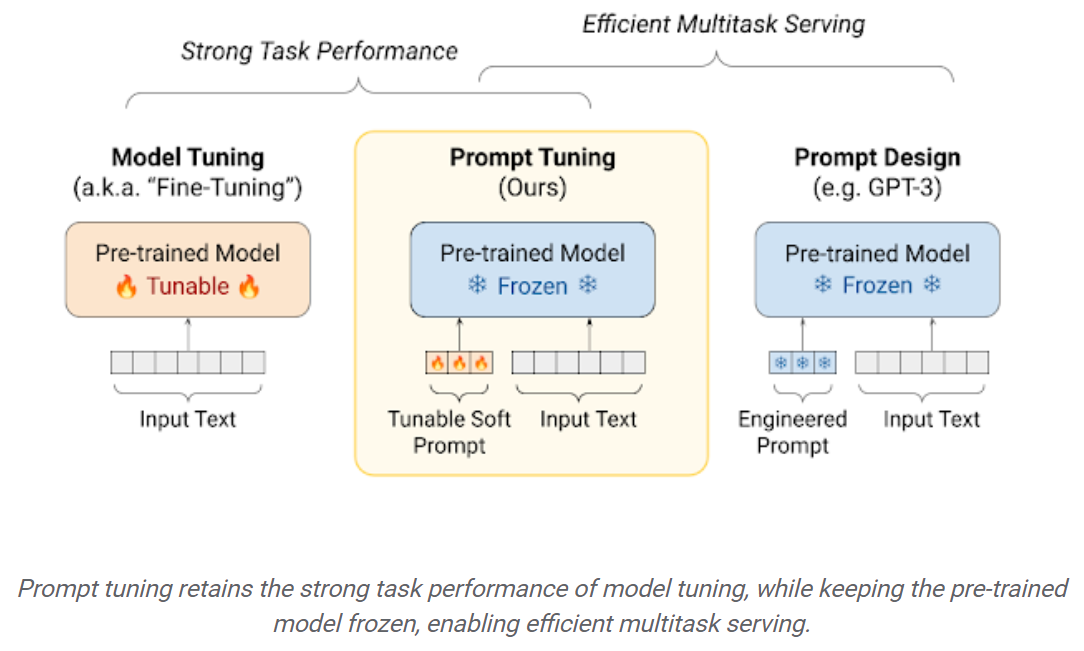
LORA Low-rank適応LLMSは、事前に処理されたモデルの重みをフリーズし、トレーニング可能なランク分解マトリックスをトランスアーキテクチャの各層に注入する方法です。ダウンストリームタスクのトレーニング可能なパラメーターの数を大幅に削減します。このビデオから、以下の図は、主なアイデア: 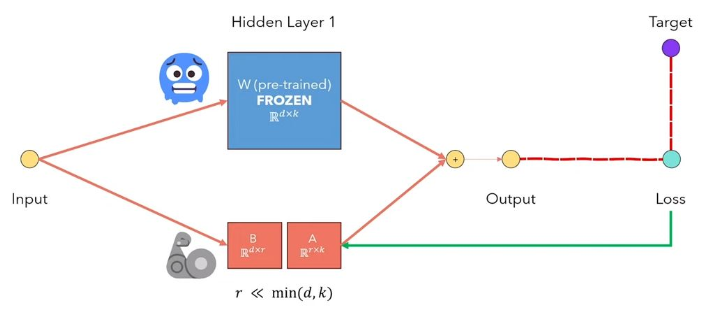
大規模な言語モデルは通常、一般的な目的であり、ドメイン固有のタスクではあまり効果的ではありません。ただし、感情分析などのいくつかのタスクでは、微調整できます。外部の知識を必要とするより複雑なTAKSの場合、外部の知識ソースにアクセスして必要なタスクを完了する言語モデルベースのシステムを構築することが可能です。これにより、より事実上の正確さが可能になり、「幻覚」の問題を軽減するのに役立ちます。以下の図に示すように:
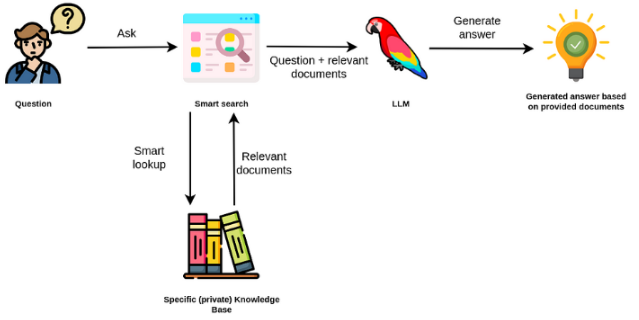
この場合、LLMを使用して内部知識にアクセスする代わりに、LLMを外部知識への自然言語インターフェイスとして使用します。最初のステップは、ドキュメントと任意のユーザーが互換性のある形式に変換して、関連性検索を実行することです(テキストをベクトル、または埋め込みに変換)。元のユーザープロンプトは、外部知識ソース内の関連 /類似のドキュメント(コンテキストとして)で追加されます。次に、モデルは、提供された外部コンテキストに基づいて質問に答えます。
大規模な言語モデル(LLM)は、変革的技術として浮上しています。ただし、これらのLLMを単独で使用することは、本当に強力なアプリケーションを作成するには不十分な場合があります。 Langchainは、このようなアプリケーションの開発を支援することを目指しています。
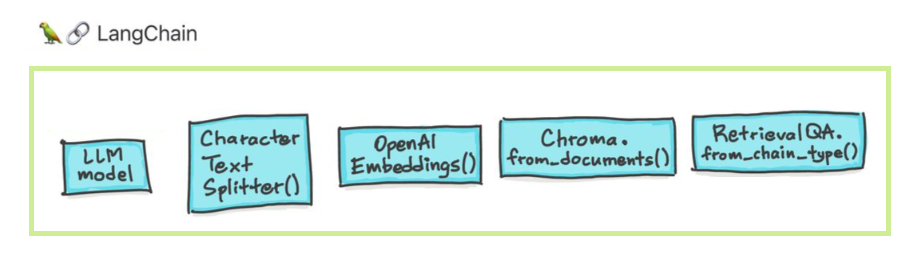
Langchainが支援するように設計された6つの主要な領域があります。これらは、複雑さの順序を増やしています。
これには、迅速な管理、迅速な最適化、すべてのLLMの汎用インターフェイス、およびLLMSを操作するための一般的なユーティリティが含まれます。 LLMSとチャットモデルは微妙ですが、重要なことに異なります。 LANGCHAINのLLMSは、純粋なテキスト完了モデルを参照しています。彼らがラップするAPIは、入力として文字列プロンプトを取得し、文字列の完了を出力します。 OpenaiのGPT-3はLLMとして実装されています。チャットモデルは多くの場合LLMSによって支えられていますが、会話をするために特別に調整されています。
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
また、返されるプロバイダー特定の情報にアクセスすることもできます。この情報は、プロバイダー間で標準化されていません。
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
チャットモデルへのプロンプトは、チャットメッセージのリストです。各チャットメッセージはコンテンツに関連付けられており、ロールと呼ばれる追加のパラメーターが関連付けられています。たとえば、Openai Chat Completions APIでは、チャットメッセージをAIアシスタント、人間、またはシステムの役割に関連付けることができます。
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
チェーンは単一のLLMコールを超えて、一連の呼び出し(LLMまたは異なるユーティリティにかかわらず)を伴います。 Langchainは、チェーン用の標準インターフェイス、他のツールとの多くの統合、および一般的なアプリケーション用のエンドツーエンドチェーンを提供します。非常に一般的にチェーンは、他のチェーンを含むコンポーネントへの一連のコールとして定義できます。
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
データ増強された生成には、最初に外部データソースと相互作用して、生成ステップで使用するデータを取得する特定のタイプのチェーンが含まれます。例には、特定のデータソースに対する質問/回答が含まれます。
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
類似性検索
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
エージェントは、どのアクションをとるか、そのアクションをとる、観察を見て、それを完了するまで繰り返すLLMを決定することを伴います。 Langchainは、エージェント向けの標準インターフェイス、選択できるエージェントの選択、およびエンドツーエンドのエージェントの例を提供します。エージェントの中心的なアイデアは、LLMを使用して、取る一連のアクションを選択することです。チェーンでは、一連のアクションがハードコードされています(コード)。エージェントでは、言語モデルが推論エンジンとして使用され、どのアクションを実行するか、どの順序でどのようなアクションを決定しますか。
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
メモリとは、チェーン/エージェントの呼び出し間の持続状態を指します。 Langchainは、メモリの標準インターフェイス、メモリ実装のコレクション、およびメモリを使用するチェーン/エージェントの例を提供します。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
さまざまな方法を使用して、ドキュメントとチャットできます。 LLM全体を微調整する必要はありません。代わりに、事前に訓練されたモデルに質問とともに適切なコンテキストを提供し、提供されたドキュメントに基づいて回答を取得できます。
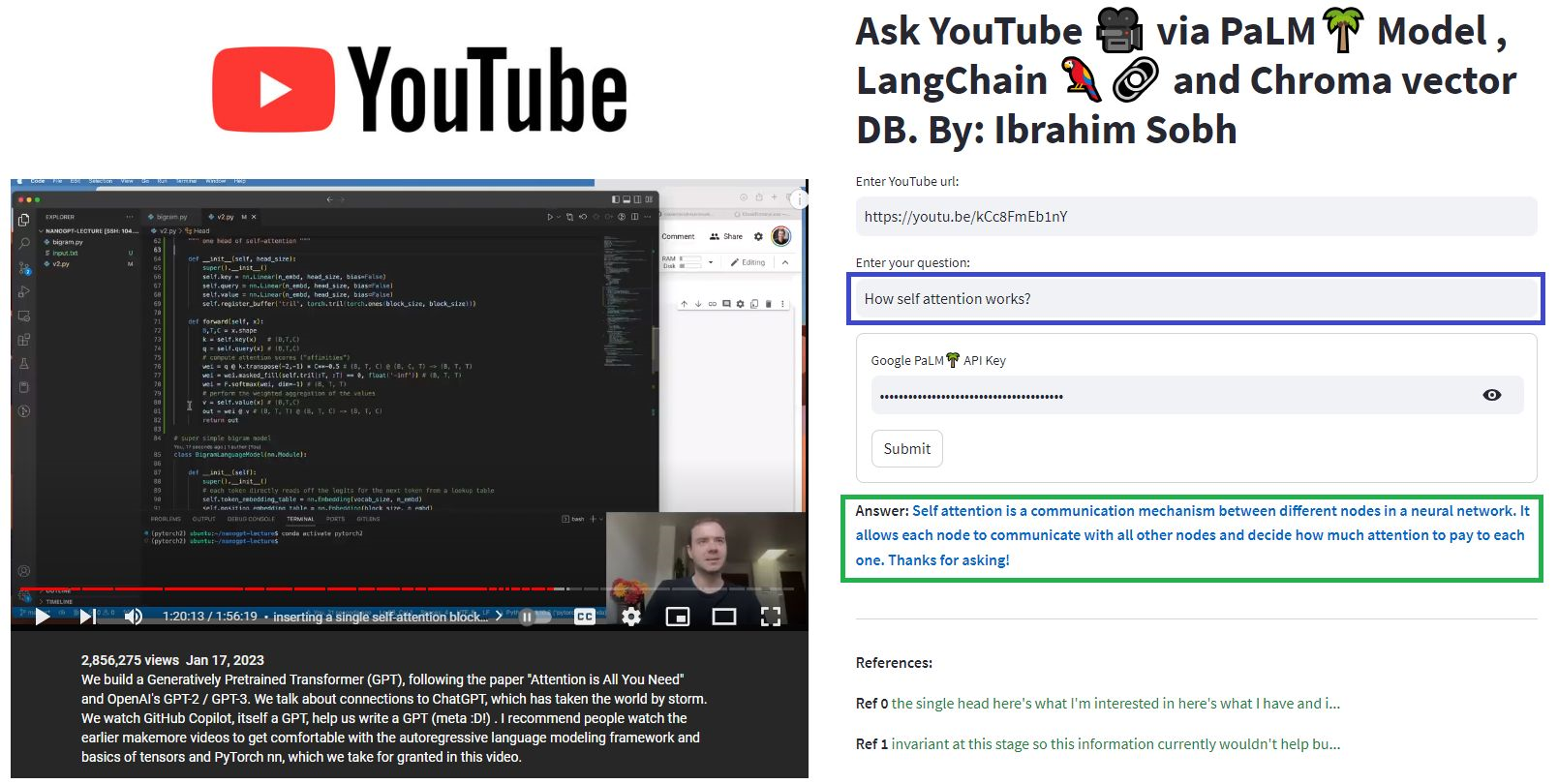
ここで、私たちはこの素敵な記事と「Transformers without Pain?」とチャットしますか?トランス、注意、エンコーダーデコーダーなどに関連する質問をします。Googleによる強力なPalmモデルと、言語モデルを搭載したアプリケーションを開発するためのLangchainフレームワークを利用しています。
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
質問: ? 「これらの文書は何ですか?」
答え: ? 「ドキュメントは変圧器に関するものであり、自然言語処理とコンピュータービジョンタスクで正常に使用されているニューラルネットワークの一種です。」
質問: ? 「トランスフォーマーの主なアイデアは何ですか?」
答え: ? 「変圧器の主な考え方は、注意メカニズムを使用して、シーケンスの長距離依存関係をモデル化することです。」
質問: ? 「位置エンコーディングとは何ですか?」
答え: ? 「位置エンコーディングは、単語の順序を順番に表すために使用される手法です。」
質問: ? 「クエリ、キー、および値ベクトルがどのように使用されますか?」
答え: ? 'クエリベクトルは、キーを介して値の加重合計を計算するために使用されます。具体的には、Q DOT製品すべてのキー、その後ソフトマックスを取得し、最終的にこれらのウェイトを使用して値の加重合計を計算します。
質問: ? 「変圧器の使用方法は?」
答え: ? 「変圧器の使用を開始するには、Huggingface Transformersライブラリを使用できます。このライブラリは、分類、情報抽出、質問回答、要約、翻訳、テキスト生成など、100以上の言語でテキストに関するタスクを実行するための数千の事前に抑制されたモデルを提供します。
独自のドキュメントや質問を試すことができます!
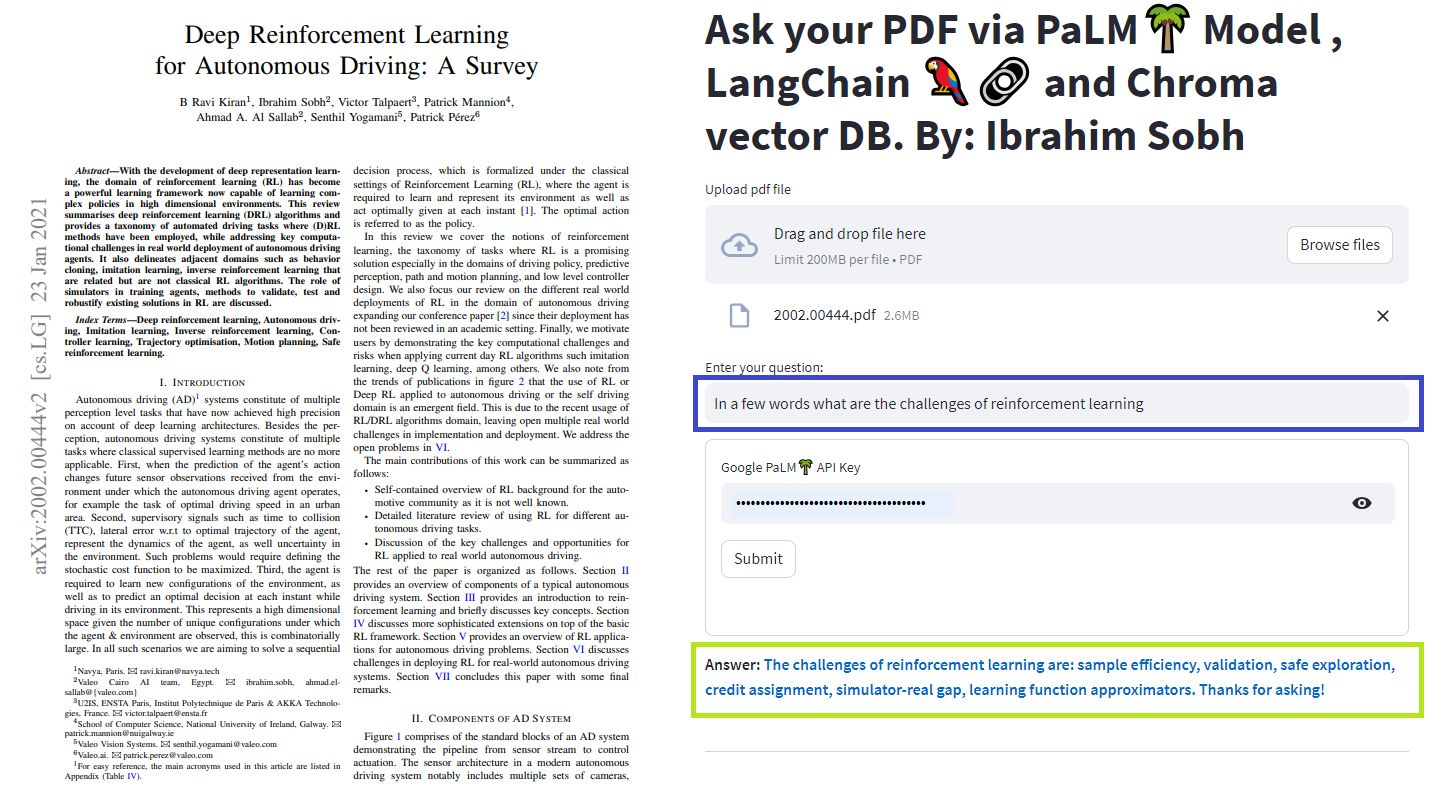
これらの簡単なチュートリアルでは、テキストドキュメント、 PDFファイル、さらにはChroma Vectorデータベースを使用したYouTubeビデオ、Palm LLM by Google、およびLangchainの質問チェーンを使用してYouTubeビデオを取得する方法。最後に、Riremlitを使用して、Webアプリケーションを開発およびホストします。 Google_api_keyを使用する必要があります(Googleから入手できます)。 THSシステムアーキテクチャは次のとおりです。
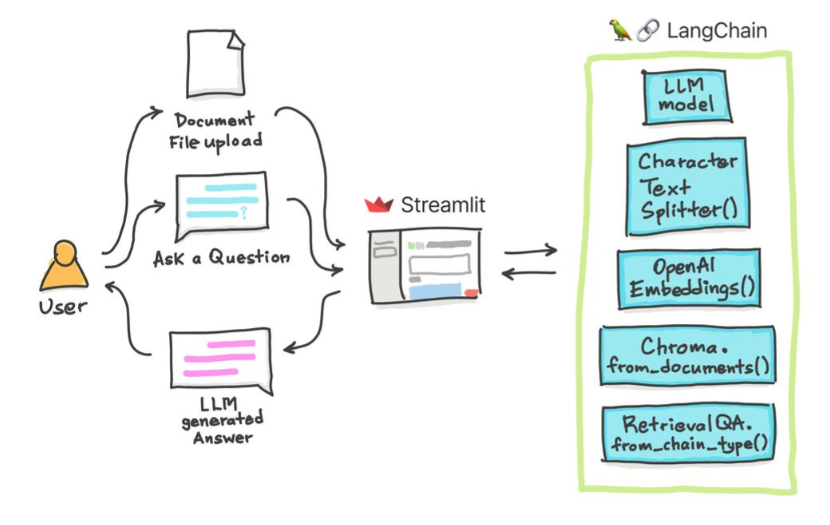
LLMベースのシステムを評価することと、LLMベースのシステムを評価することには違いがあります。通常、一般的な事前トレーニングの後、LLMは標準ベンチマークで評価されます。
LLMSシステムは、テキストを要約したり、質問をしたり、テキストの感情を見つけたり、翻訳を行うことができます。システムに基づいて、評価は次のとおりです。
たとえば、質問に答えるシステムの場合、評価セットには質問と回答のペアが必要です。人間のアノテーターを使用して、手動でゴールドスタンダードの質問と回答を作成できます。 However, it is costly and time-consuming. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
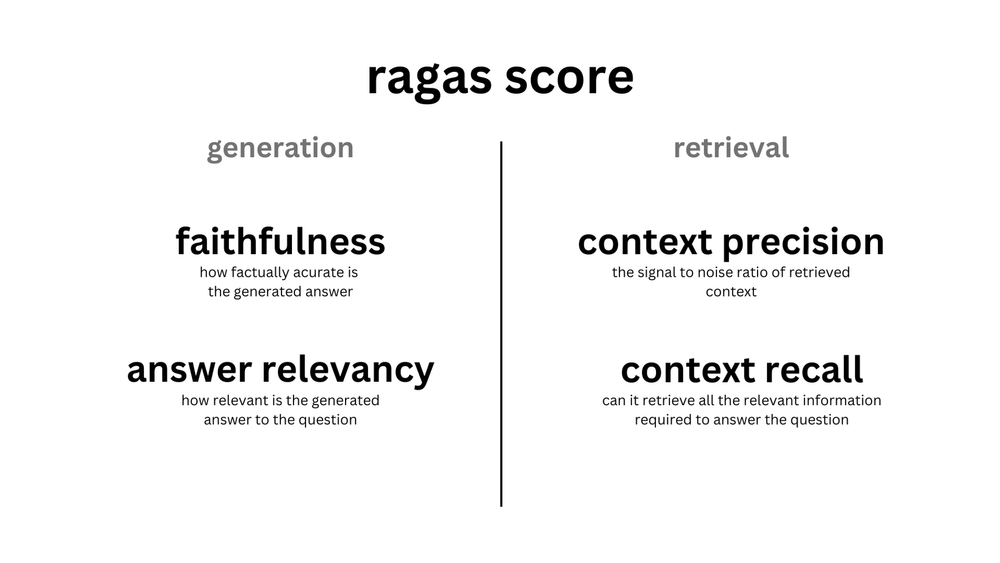
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
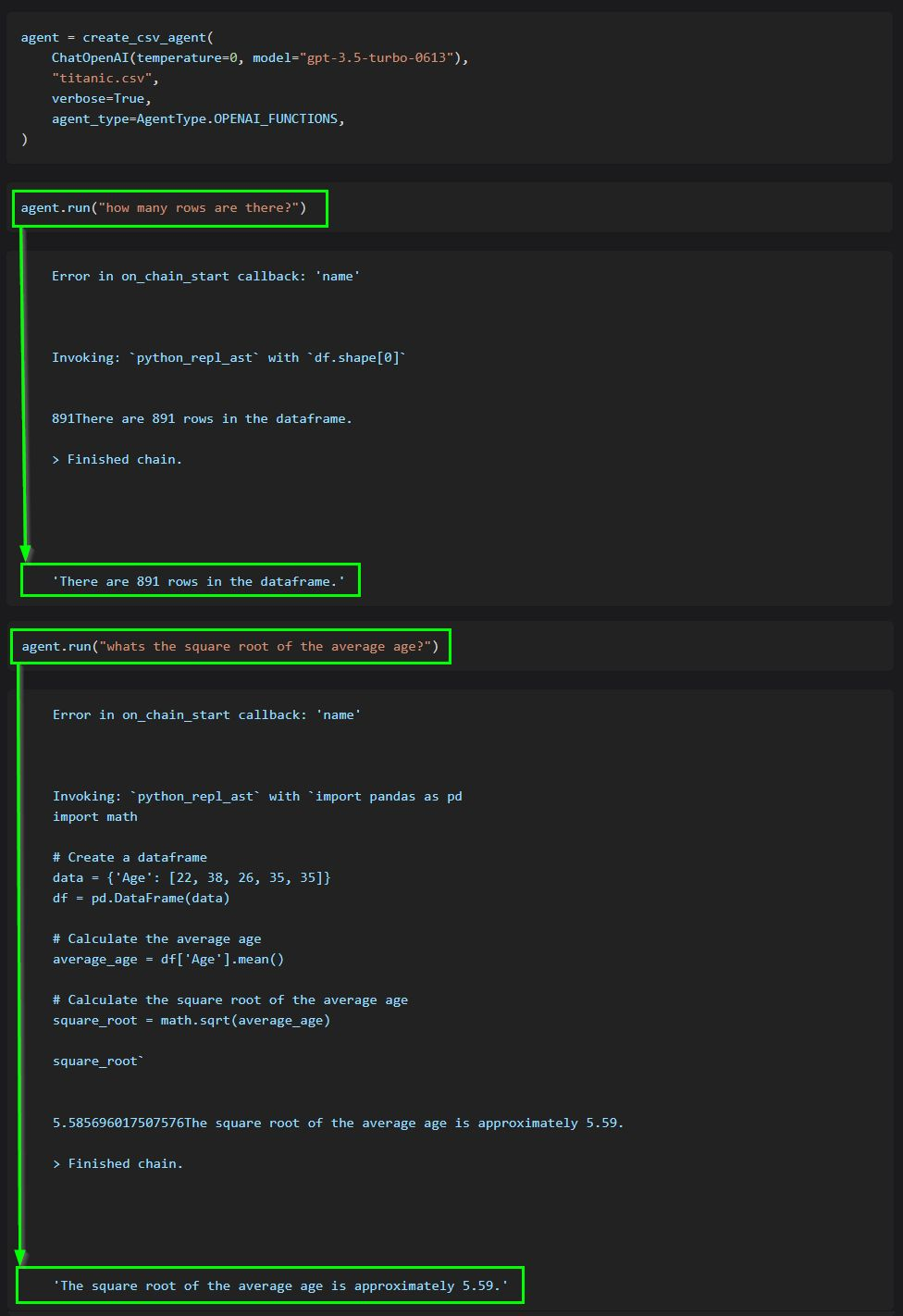
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
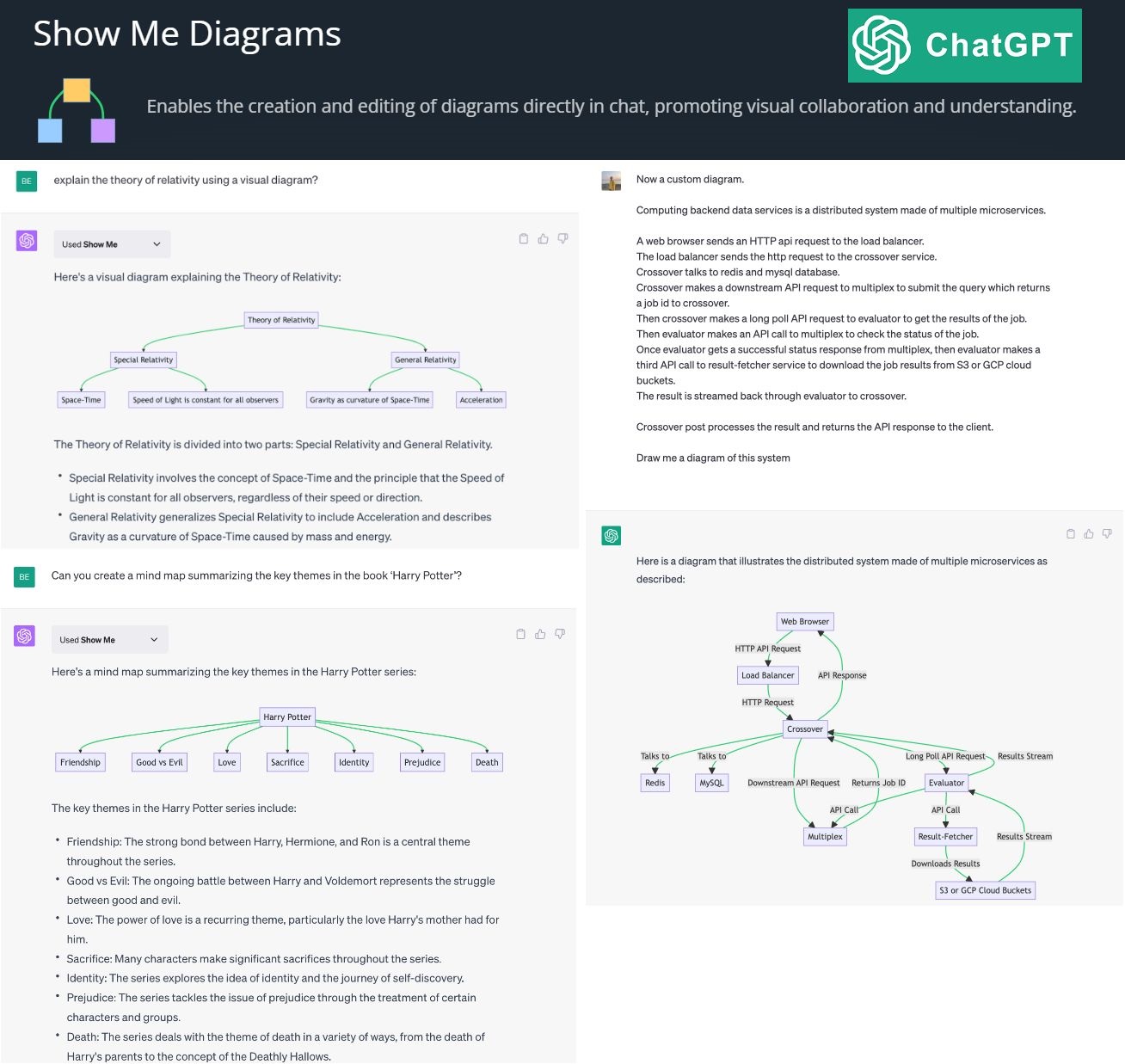
By creating and editing diagrams via Show Me Diagrams
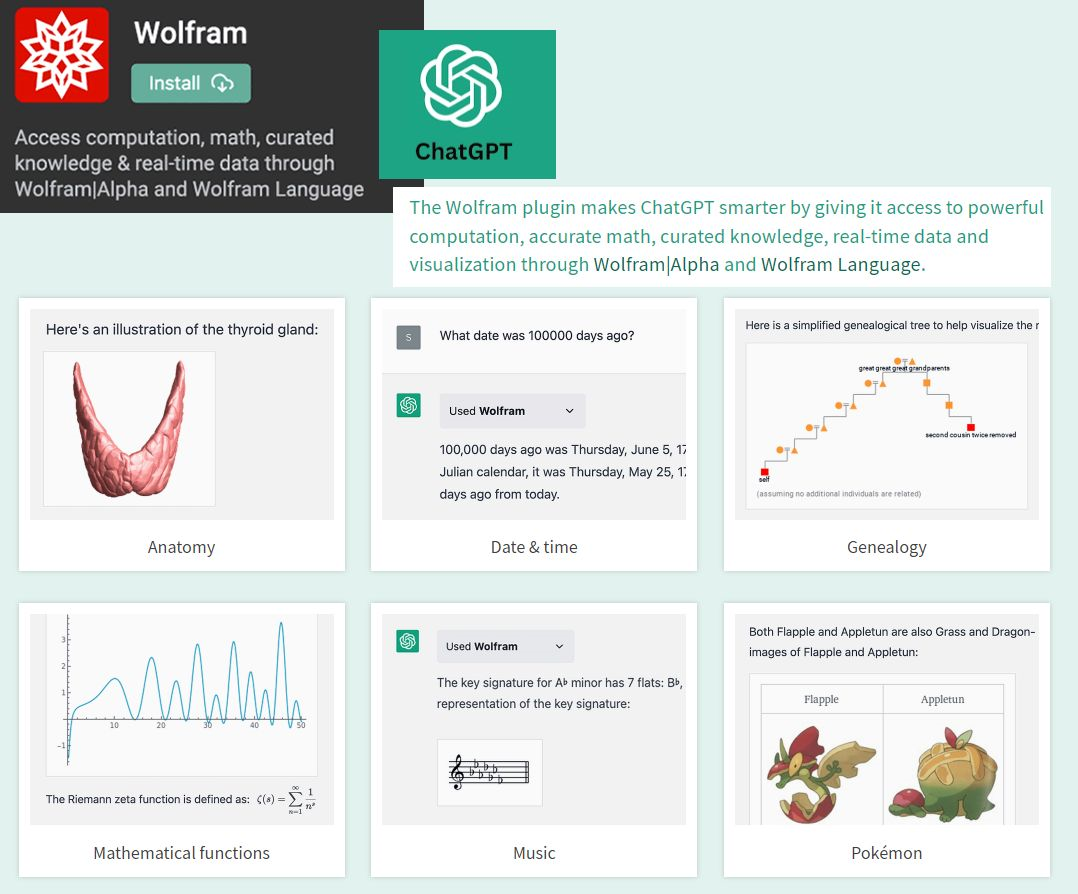
By accessing the power of mathematics provided by Wolfram
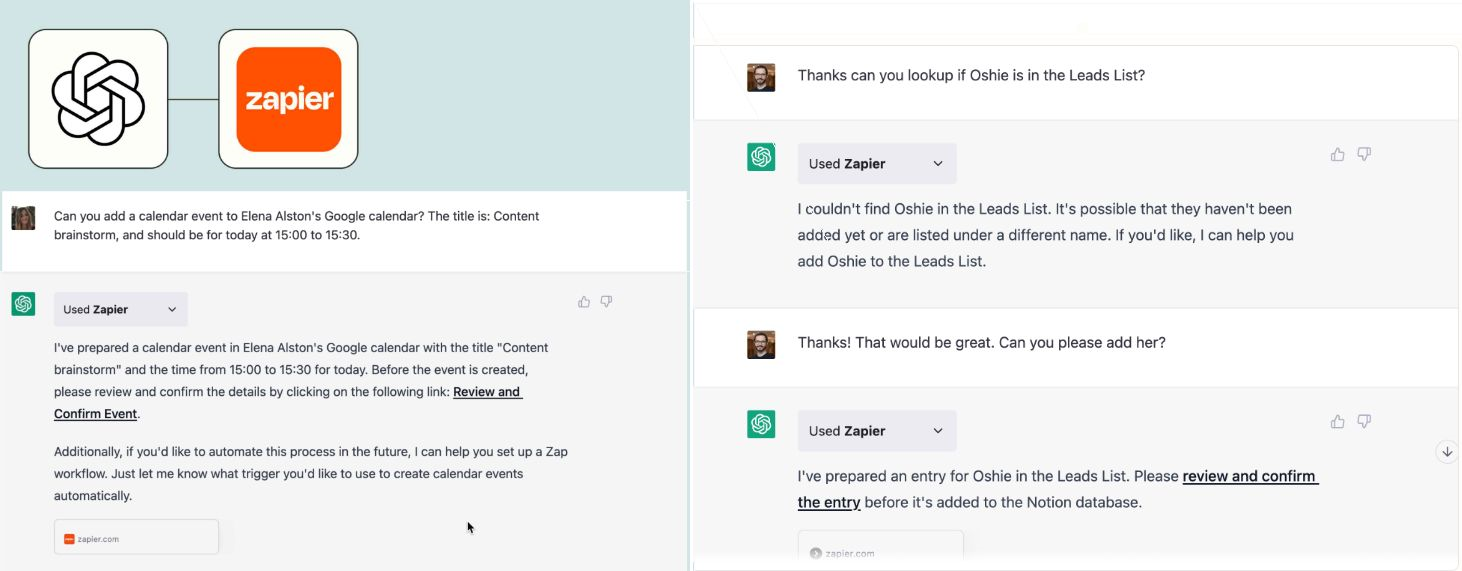
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


