llms
1.0.0
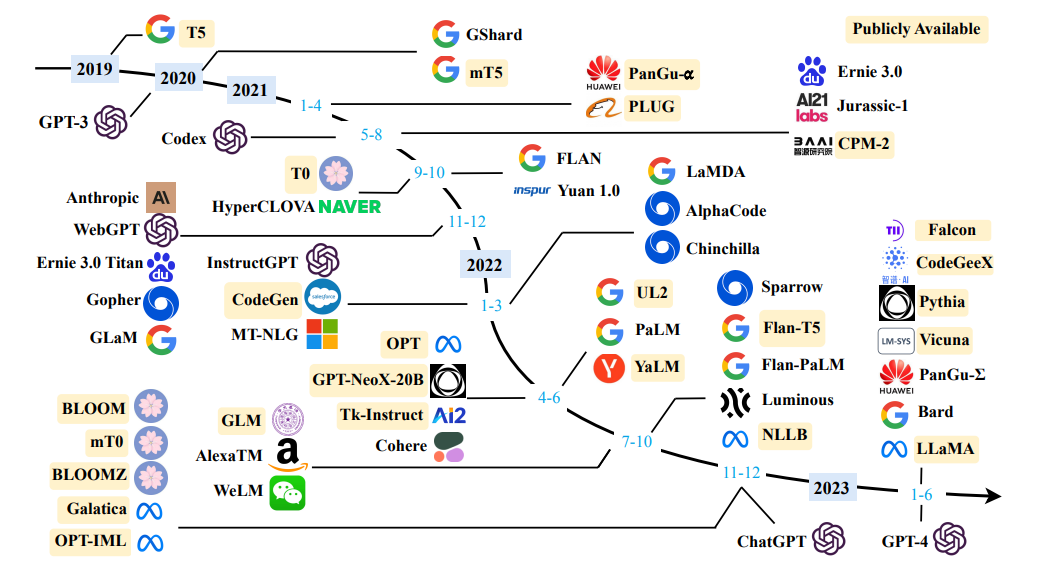 Quellen Sie eine Übersicht über große Sprachmodelle
Quellen Sie eine Übersicht über große Sprachmodelle
Einfache Definition: Sprachmodellierung ist die Aufgabe, vorherzusagen, was Wort als nächstes kommt.
"Der Hund spielt im ..."
Der Hauptzweck von Sprachmodellen besteht darin, einem Satz eine Wahrscheinlichkeit zuzuweisen, zwischen den wahrscheinlicheren und den weniger wahrscheinlichen Sätzen zu unterscheiden.
Für die Spracherkennung verwenden wir nicht nur das Akustikmodell (das Sprachsignal), sondern auch ein Sprachmodell. In ähnlicher Weise verwenden wir für die optische Charaktererkennung (OCR) sowohl ein Visionsmodell als auch ein Sprachmodell. Sprachmodelle sind für solche Erkennungssysteme sehr wichtig.
Manchmal hören oder lesen Sie einen Satz, der nicht klar ist, aber wenn Sie Ihr Sprachmodell verwenden, können Sie ihn trotz der lauten Seh-/Spracheingabe immer noch mit hoher Genauigkeit erkennen.
Das Sprachmodell berechnet eines von:
Die Sprachmodellierung ist eine Unterkomponente vieler NLP -Aufgaben, insbesondere für solche, die Text generieren oder die Wahrscheinlichkeit von Text schätzen.
Die Kettenregel:
$ P (das Wasser, ist, so, klar) = p (das) × p (Wasser | das) × p (ist | das, Wasser) × p (so | das, Wasser, ist) × p (klar | Das Wasser, ist, so) $
Was ist gerade passiert? Die Kettenregel wird angewendet, um die gemeinsame Wahrscheinlichkeit von Wörtern in einem Satz zu berechnen.
Mit einer großen Menge Text (Korpus wie Wikipedia) sammeln wir Statistiken darüber, wie häufig verschiedene Wörter sind, und verwenden diese, um das nächste Wort vorherzusagen. Zum Beispiel kann die Wahrscheinlichkeit, dass ein Wort W nach diesen drei Wörtern kommt, die die Schüler ihr geöffnet haben, wie folgt geschätzt werden:
Das obige Beispiel ist ein 4-Gramm-Modell. Und wir können:
Wir können daraus schließen, dass das Wort „Bücher“ in diesem Zusammenhang wahrscheinlicher ist als „Autos“.
Wir haben den vorherigen Kontext ignoriert, bevor "Schüler ihre öffneten" "
Dementsprechend kann ein willkürlicher Text aus einem Sprachmodell generiert werden, das startete Wort (n) bezeichnet wird, indem aus der Ausgabegteilwahrscheinlichkeitsverteilung des nächsten Wortes usw. Stichproben probiert.
Wir können einen LM auf jeder Art von Text trainieren und dann Text in diesem Stil erstellen (Harry Potter usw.).
Wir können uns auf Trigramme, 4-Gramm, 5-Gramm und N-Gramm erstrecken.
Im Allgemeinen ist dies ein nicht genügend Sprachmodell, da die Sprache Fernabhängigkeiten aufweist. In der Praxis funktionieren diese 3,4 Gramm jedoch für die meisten Anwendungen gut.
Die N-Gram-Modelle von Google gehören Ihnen: Google Research verwendet Word N-Gram-Modelle für eine Vielzahl von F & E-Projekten. Google N-Gram verarbeitete 1.024.908.267.229 Wörter ausführlicher Text und veröffentlichte die Zählungen für alle 1.176.470.663 Fünf-Wörter-Sequenzen, die mindestens 40 Mal erscheinen.
Die Zählungen von Text aus dem Linguistik -Datenkonsortium LDC sind wie folgt:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
Das Folgende ist ein Beispiel für die 4-Gramm -Daten in diesem Korpus:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
Zum Beispiel wurde die Abfolge der vier Wörter "als Indikation" 72 Mal im Korpus gesehen.
Manchmal haben wir nicht genügend Daten, um abzuschätzen. Das Erhöhen von N verschlechtert die Probleme mit Sparsamkeit. Normalerweise können wir nicht größer als 5 haben.
NLM verwendet normalerweise (aber nicht immer) ein RNN, um Sequenzen von Wörtern (Sätze, Absätzen,… usw.) zu lernen und kann daher das nächste Wort vorhersagen.
Vorteile:
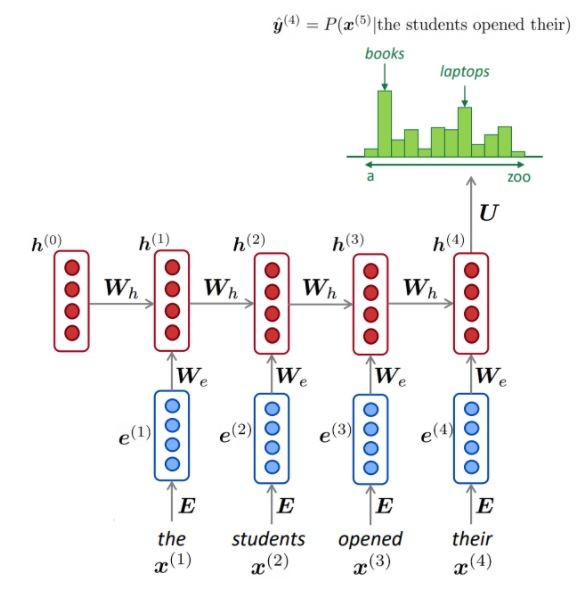
Wie dargestellt, haben wir bei jedem Schritt eine Wahrscheinlichkeitsverteilung des nächsten Wortes über dem Wortschatz.
Training eines NLM:
Beispiel für lange Sequenzlernen:
Nachteile:
LM kann verwendet werden, um Textbedingungen für Eingabe (Sprache, Bild (OCR), Text usw.) über verschiedene Anwendungen hinweg zu generieren, wie z. B. Spracherkennung, maschinelle Übersetzung, Zusammenfassung usw.
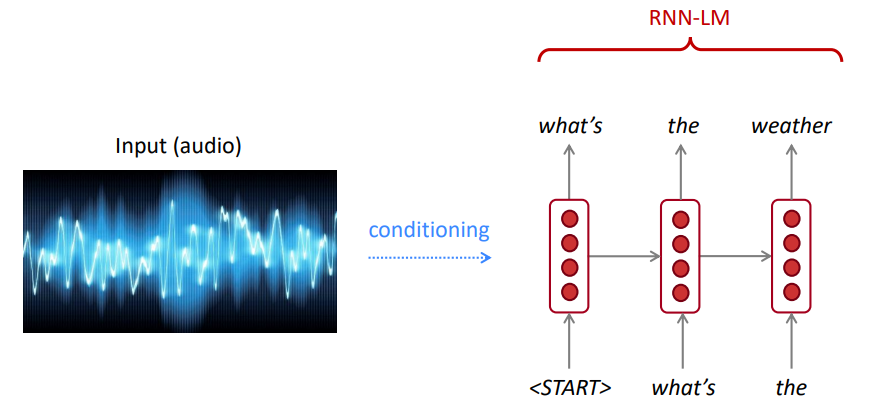
Bevorzugt unser Sprachmodell gute (wahrscheinlich) Sätze für schlechte Sätze?
Die Standardbewertungsmetrik für Sprachmodelle ist verwirrend verblüfft
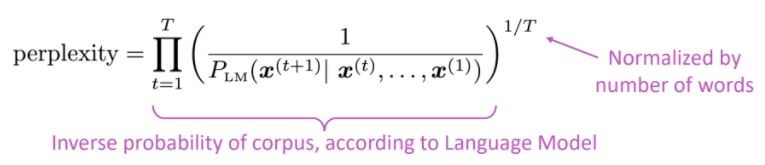
Niedrigere Verwirrung = besseres Modell
Verwirrung hängt mit dem Zweigfaktor zusammen: Wie viele Dinge können im Durchschnitt als nächstes auftreten.
Lassen Sie uns anstelle von RNN Aufmerksamkeit verwenden, um große vorgebrachte Modelle zu verwenden
Was ist das Problem? Eine der größten Herausforderungen bei der Verarbeitung natürlicher Sprache (NLP) ist der Mangel an Trainingsdaten für viele unterschiedliche Aufgaben. Moderne NLP-Modelle mit Deep-Lernbasierten verbessern sich jedoch, wenn sie auf Millionen oder Milliarden an kommentierten Schulungsbeispielen geschult sind.
Vorausbildung ist die Lösung: Um diese Lücke zu schließen, wurden eine Vielzahl von Techniken für das Training für die Repräsentationsmodelle für allgemeine Sprachdarstellungen entwickelt, wobei die enorme Menge an nicht annotierter Text. Das vorgebreitete Modell kann dann mit kleinen Daten für verschiedene Aufgaben wie Fragenbeantwortung und Stimmungsanalyse fein abgestimmt werden, was zu erheblichen Genauigkeitsverbesserungen im Vergleich zum Training dieser Datensätze von Grund auf führt.
Die Transformatorarchitektur wurde in der Aufmerksamkeit der Arbeit vorgeschlagen, was Sie brauchen, was Sie für die neuronale maschinelle Übersetzungsaufgabe (NMT) verwendet haben, die aus:
Wie in der Zeitung erwähnt:
" Wir schlagen eine neue einfache Netzwerkarchitektur vor, den Transformator, der ausschließlich auf Aufmerksamkeitsmechanismen basiert und auf Rezidiven und Wäldungen vollständig verzichtet ."
Die Hauptidee der Aufmerksamkeit kann wie im Artikel des OpenAI erwähnt werden:
" ... jedes Ausgangselement ist mit jedem Eingangselement verbunden, und die Gewichtungen zwischen ihnen werden dynamisch auf der Grundlage der Umstände berechnet , ein Prozess, der Aufmerksamkeit bezeichnet. "
Basierend auf dieser Architektur (den Vanilletransformatoren!) Können Encoder- oder Decoderkomponenten allein verwendet werden, um massive vorgebrachte generische Modelle zu ermöglichen, die für nachgeschaltete Aufgaben wie Textklassifizierung, Übersetzung, Zusammenfassung, Beantwortung von Fragen usw. fein abgestimmt werden können. Beispielsweise:
Diese Modelle, Bert und GPT, können beispielsweise als Imagnet des NLP angesehen werden.
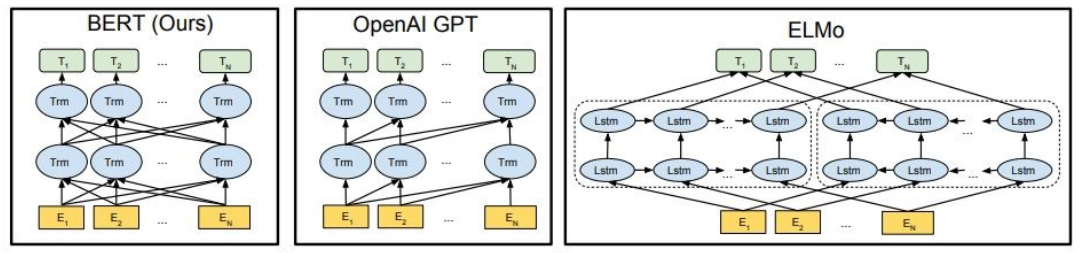
Wie gezeigt ist Bert zutiefst bidirektional, Openai GPT ist unidirektional und Elmo ist flach bidirektional.
Vorausgebildete Darstellungen können sein:
Kontextsprachmodelle können sein:
In diesem Teil werden wir verschiedene Großsprachmodelle verwenden
GPT2 (ein Nachfolger von GPT) ist ein vorgebildetes Modell in englischer Sprache mit einem CLM- Ziel (Causal Language Modeling), das einfach geschult ist, um das nächste Wort in 40 GB Internet-Text vorherzusagen. Es wurde zum ersten Mal auf dieser Seite veröffentlicht. GPT2 zeigt einen breiten Satz von Funktionen an, einschließlich der Möglichkeit, bedingte synthetische Textproben zu erzeugen. Bei Sprachaufgaben wie Beantwortung von Fragen, Leseverständnis, Zusammenfassung und Übersetzung beginnt GPT2, diese Aufgaben aus dem Rohtext zu lernen, wobei keine aufgabenspezifischen Trainingsdaten verwendet werden. DistilGPT2 ist eine destillierte Version von GPT2, die für ähnliche Anwendungsfälle verwendet werden soll, wobei die erhöhte Funktionalität von kleinerem und leichter zu betrieben ist als das Basismodell.
Hier laden wir ein vorgebildetes GPT2- Modell, bitten Sie das GPT2-Modell, unseren Eingabetxt (Eingabeaufforderung) fortzusetzen, und extrahieren schließlich eingebettete Merkmale aus dem Modell DistilGPT2.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
Bert ist ein Transformatorenmodell, das auf einen großen Korpus englischer Daten in selbstsaugter Weise ausgebildet ist. Dies bedeutet, dass es nur in den Rohtexten vorgebracht wurde, ohne dass Menschen sie in irgendeiner Weise mit einem automatischen Prozess kennzeichneten, um Eingänge und Beschriftungen aus diesen Texten zu generieren. Genauer gesagt wurde es mit zwei Zielen vorgebracht:
In diesem Beispiel werden wir ein vorgebildetes Bert- Modell für die Stimmungsanalyseaufgabe verwenden.
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4ALL ist ein Ökosystem, um leistungsstarke und maßgeschneiderte Großsprachenmodelle zu trainieren und einzusetzen, die lokal auf CPUs der Verbrauchergrade laufen.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
Probieren Sie die folgenden Modelle aus:
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM ist die Flaggschiff -Serie von TII von großer Sprachmodellen, die mit einer benutzerdefinierten Datenpipeline und einem verteilten Training von Grund auf neu erstellt wurden. Falcon-7b/40b-Modelle sind für ihre Größe auf dem neuesten Stand der Technik und übertreffen die meisten anderen Modelle auf NLP-Benchmarks. Open-Sourced eine Reihe von Artefakten:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
LLAMA2 ist eine Familie hochmoderner Open-Access-großer Sprachmodelle, die heute von Meta veröffentlicht wurden, und wir freuen uns, den Start mit umfassender Integration in das umarmende Gesicht voll und ganz zu unterstützen. LLAMA 2 wird mit einer sehr zulässigen Community -Lizenz veröffentlicht und steht für die kommerzielle Nutzung zur Verfügung. Der Code, die vorbereiteten Modelle und die fein abgestimmten Modelle werden heute alle veröffentlicht
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
Codet5+ ist eine neue Familie offener Code-großsprachigen Modelle mit einer Encoder-Decoder-Architektur, die in verschiedenen Modi flexibel arbeiten kann (dh Nur Encoder, nur Decoder und Encoder-Decoder), um eine breite Palette von Codeverständnis und Erzeugungsaufgaben zu unterstützen.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
Weitere Modelle finden Sie Codetf von Salesforce, einer Python-basierten Bibliothek für Code-Großsprachenmodelle (Code LLMs) und Code-Intelligenz, die eine nahtlose Schnittstelle für Schulungen und Ausleger in Code-Intelligenz-Aufgaben wie Code-Zusammenfassung, Übersetzung, Codegenerierung usw. bietet.
? ️ chatten Sie mit offenen großen Sprachmodellen
✅ Strahlsuche findet immer eine Ausgangssequenz mit höherer Wahrscheinlichkeit als gierige Suche, findet jedoch nicht garantiert die wahrscheinlichste Ausgabe.
In Transformatoren setzen wir einfach die Parameter num_return_sequences auf die Anzahl der höchsten Bewertungsstrahlen, die zurückgegeben werden sollten. Stellen Sie jedoch sicher, dass num_return_sequences <= num_beams!
✅ Die Strahlsuche kann bei Aufgaben sehr gut funktionieren, bei denen die Länge der gewünschten Generation mehr oder weniger vorhersehbar ist wie bei der maschinellen Übersetzung oder Zusammenfassung. Aber dies ist nicht der Fall für die offene Generation, bei der die gewünschte Ausgangslänge stark variieren kann, z. B. Dialog und Geschichtenerzeugung. Strahlsuche leidet stark unter wiederholte Erzeugung. Als Menschen möchten wir, dass er einen Text erzeugt, um uns zu überraschen und nicht langweilig/vorhersehbar zu sein ("Strahlsuche ist weniger überraschend)
In Transformatoren setzen wir do_sample = true und deaktivieren die Top-K-Abtastung (mehr dazu später) über top_k = 0.
???-? ???????? GPT2 übernahm dieses Stichprobenschema.
???-? ???????? Die Wahrscheinlichkeitsmasse wird dann in diese Wörtermenge umverteilt. Nachdem P = 0,92 eingestellt ist, wählt Top-P-Stichproben die minimale Anzahl von Wörtern, die 92% der Wahrscheinlichkeitsmasse überschreiten.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ Während Top-P eleganter zu sein scheint als Top-K, funktionieren beide Methoden in der Praxis gut. TOP-P kann auch in Kombination mit Top-K verwendet werden, was sehr niedrig rangierte Wörter vermeiden kann und gleichzeitig eine dynamische Auswahl ermöglicht.
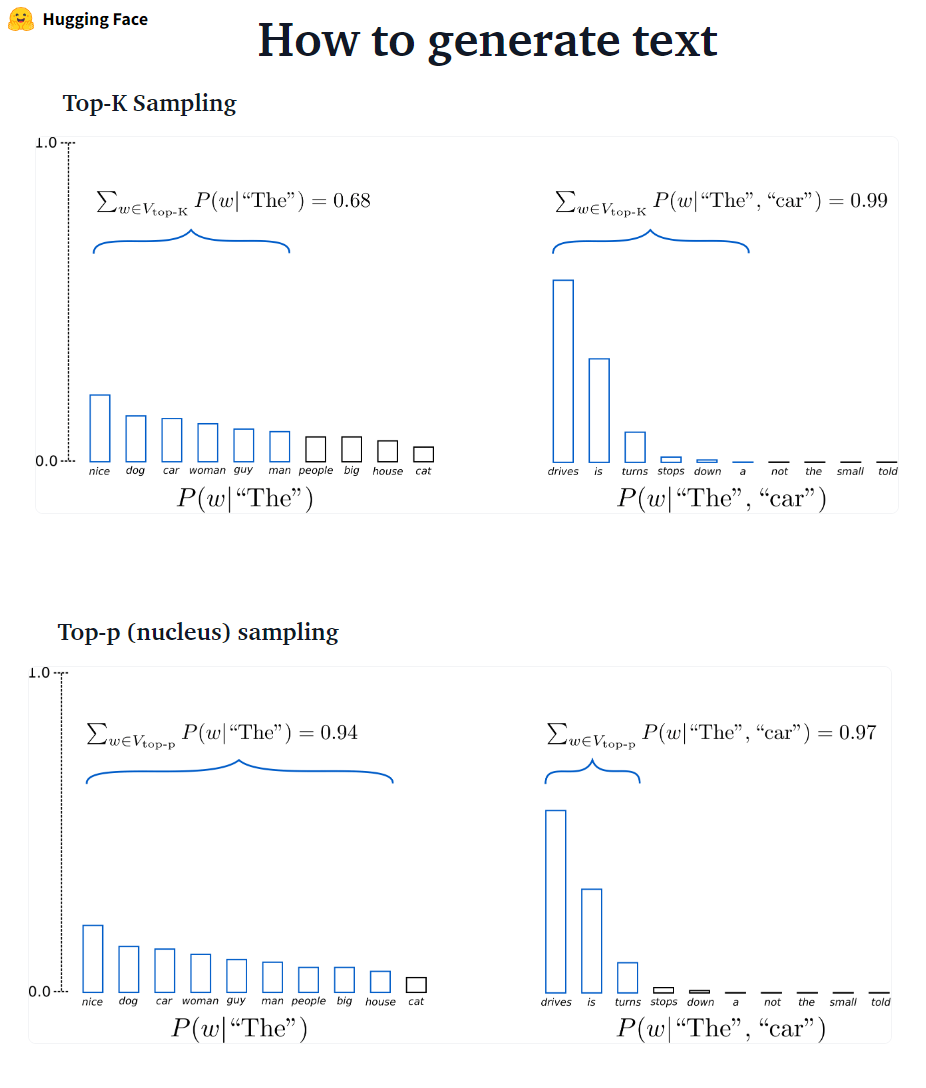
✅ Als Ad-hoc-Dekodierungsmethoden scheinen die Top-P- und Top-K-Stichproben einen fließenden Text zu erzeugen als herkömmliche gierige-Strahlsuche zur Erzeugung offener Sprache.
Ein Umformungstechnik ist das Entwerfen der Eingabeaufforderungen (Texteingabe) für ein Sprachmodell, um die erforderliche Ausgabe zu generieren. Ein Umlauf -Engineering beinhaltet die Auswahl geeigneter Schlüsselwörter, bietet einen Kontext, das klar und spezifisch ist, dass das Sprachmodellverhalten die gewünschten Antworten erreicht. Durch Proportion Engineering können wir den Ton, Stil, Länge usw. des Modells ohne Feinabstimmung steuern.
Das Lernen von Zero-Shot bittet das Modell, beispielsweise Vorhersagen zu treffen, ohne Beispiele (Zero Shot) zu liefern:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
Wenn Null-Shot nicht gut genug ist, wird empfohlen, das Modell zu helfen, indem Beispiele in der Eingabeaufforderung angelegt werden, die zu wenigen Schussanforderungen führen.
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
Zusätzlich zum schnellen Engineering können wir weitere Optionen in Betracht ziehen:
Weitere Informationen zur Ingenieurwesen finden Sie im fordernen Ingenieurhandbuch, der alle neuesten Artikel, Lernleitfäden, Vorträge, Referenzen und Tools enthält.
Feinabstimmende LLMs auf nachgeschalteten Datensätzen führen zu enormen Leistungssteigerungen im Vergleich zur Verwendung der vorbereiteten LLMs außerhalb des Boxs (z. B. Null-Shot-Inferenz). Wenn jedoch die Modelle immer größer werden, wird die volle Feinabstimmung für Verbraucherhardware nicht zu trainieren. Darüber hinaus wird das Speichern und Bereitstellen von fein abgestimmten Modellen für jede nachgeschaltete Aufgabe sehr teuer, da fein abgestimmte Modelle die gleiche Größe haben wie das ursprüngliche vorbereitete Modell. PEFT-Ansätze (parametereffiziente Feinabstimmungen) sollen beide Probleme angehen! Mit PEFT-Ansätzen können Sie die Leistung vergleichbar mit vollständiger Feinabstimmung erhalten und nur eine kleine Anzahl trainierbarer Parameter haben. Zum Beispiel:
Einfaches Tuning: Ein einfacher und dennoch effektiver Mechanismus zum Lernen von „weichen Eingabeaufforderungen“ für gefrorene Sprachmodelle, um bestimmte nachgeschaltete Aufgaben auszuführen. Genau wie in technische Textaufforderungen werden weiche Eingabeaufforderungen zum Eingabtext verkettet. Anstatt aus vorhandenen Vokabeln auszuwählen, sind die „Token“ der Soft -Eingabeaufforderung lernbare Vektoren. Dies bedeutet, dass eine Soft-Eingabeaufforderung End-to-End über einen Trainingsdatensatz optimiert werden kann, wie unten gezeigt: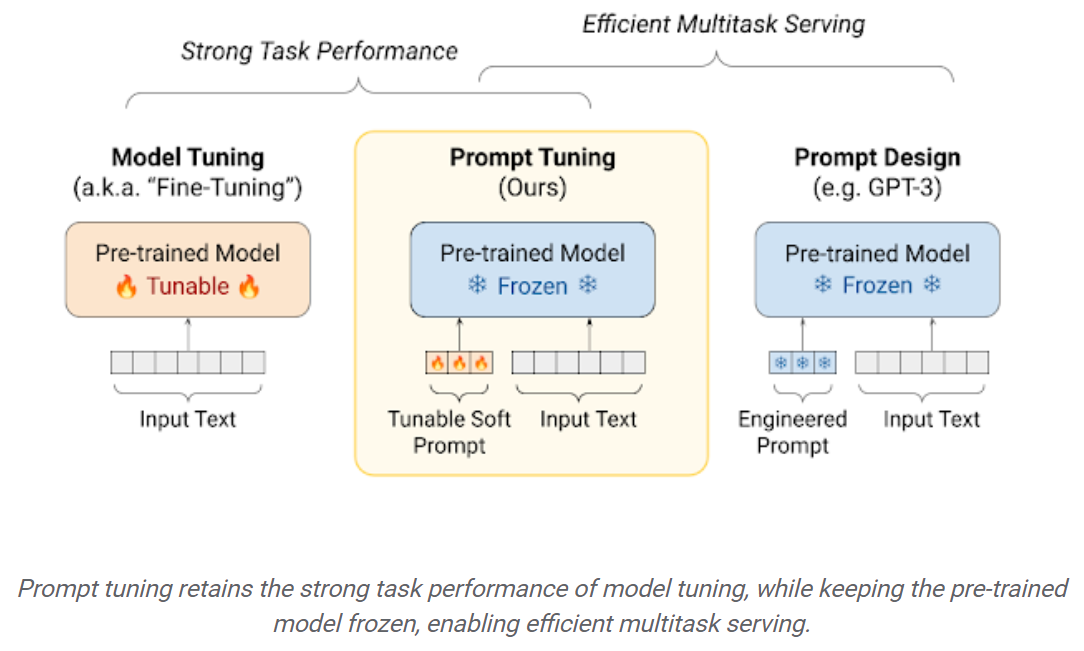
Lora Low-Rank-Anpassung von LLMs ist eine Methode, die die vorbereiteten Modellgewichte einfriert und trainierbare Rang-Zersetzungsmatrizen in jede Schicht der Transformatorarchitektur injiziert. Verringerung der Anzahl der trainierbaren Parameter für nachgeschaltete Aufgaben erheblich. Die folgende Abbildung aus diesem Video erklärt die Hauptidee: 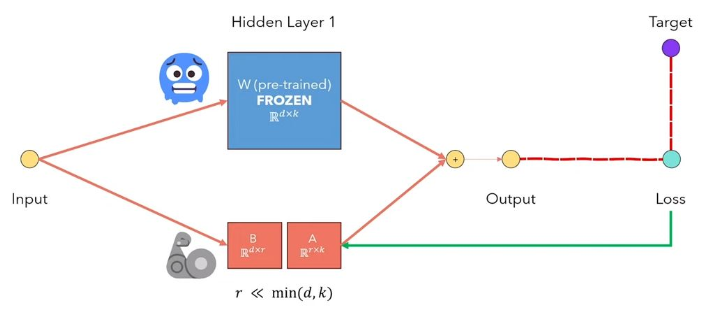
Großsprachmodelle sind in der Regel allgemeiner Zweck und für domänenspezifische Aufgaben weniger effektiv. Sie können jedoch bei einigen Aufgaben wie Stimmungsanalyse fein abgestimmt werden. Für komplexere TAKs, die externes Wissen erfordern, ist es möglich, ein auf Sprachmodell basierendes System zu erstellen, das auf externe Wissensquellen zugreift, um die erforderlichen Aufgaben zu erledigen. Dies ermöglicht mehr sachliche Genauigkeit und hilft, das Problem der "Halluzination" zu mildern. Wie im folgenden Figuer gezeigt:
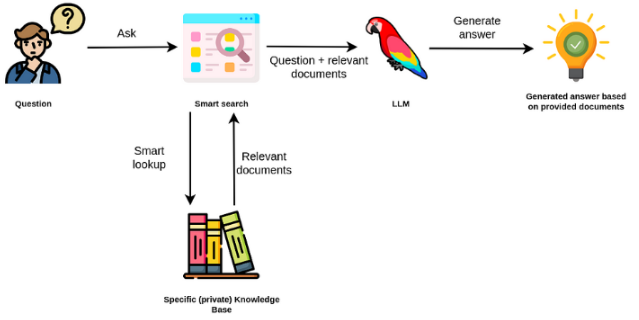
In diesem Fall verwenden wir anstatt LLMs, um auf sein internes Wissen zuzugreifen, das LLM als natürliche Sprachschnittstelle zu unserem externen Wissen zu verwenden. Der erste Schritt besteht darin, die Dokumente und alle Benutzerabfragen in ein kompatibles Format umzuwandeln, um die Relevanzsuche durchzuführen (Text in Vektoren oder Einbettungen umwandeln). Die ursprüngliche Benutzeraufforderung wird dann mit relevanten / ähnlichen Dokumenten innerhalb der externen Wissensquelle (als Kontext) angehängt. Das Modell beantwortet dann die Fragen basierend auf dem bereitgestellten externen Kontext.
Große Sprachmodelle (LLMs) entwickeln sich als transformative Technologie. Die Verwendung dieser LLMs isoliert reicht jedoch häufig nicht aus, um wirklich leistungsstarke Anwendungen zu erstellen. Langchain zielt darauf ab, die Entwicklung solcher Anwendungen zu unterstützen.
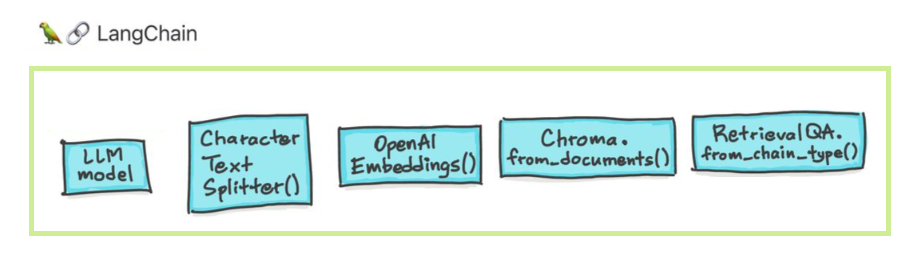
Es gibt sechs Hauptbereiche, mit denen Langchain helfen soll. Diese sind in zunehmender Reihenfolge der Komplexität:
Dies beinhaltet das schnelle Management, eine schnelle Optimierung, eine generische Schnittstelle für alle LLMs und gemeinsame Dienstprogramme für die Arbeit mit LLMs. LLMs und Chat -Modelle sind subtil, aber wichtiger. LLMs in Langchain beziehen sich auf reine Textabschlussmodelle. Die APIs, die sie einwickeln, nehmen eine String -Eingabeaufforderung als Eingabe und geben eine Zeichenfolge aus. OpenAIs GPT-3 wird als LLM implementiert. Chat -Modelle werden oft von LLMs gesichert, aber speziell auf Gespräche eingestellt.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?nnTo get to the other side.'
Sie können auch auf Anbieter auf spezifische Informationen zugreifen, die zurückgegeben werden. Diese Informationen sind nicht über Anbieter hinweg standardisiert.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
Die Eingabeaufforderung für Chat -Modelle ist eine Liste von Chat -Nachrichten. Jede Chat -Nachricht ist mit dem Inhalt und einem zusätzlichen Parameter bezeichnet, der als Rolle bezeichnet wird. In der OpenAI -Chat -API -API kann beispielsweise eine Chat -Nachricht mit einem AI -Assistenten, einem Menschen oder einer Systemrolle zugeordnet werden.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
Ketten gehen über einen einzelnen LLM -Aufruf hinaus und beinhalten Sequenzen von Aufrufen (ob an einem LLM oder einem anderen Dienstprogramm). Langchain bietet eine Standardschnittstelle für Ketten, viele Integrationen mit anderen Tools und End-to-End-Ketten für gemeinsame Anwendungen. Kette kann sehr generell als eine Abfolge von Aufrufen von Komponenten definiert werden, die andere Ketten enthalten können.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
Die Datenvergrößerungsgenerierung umfasst bestimmte Arten von Ketten, die zunächst mit einer externen Datenquelle interagieren, um Daten für die Verwendung im Erzeugungsschritt abzurufen. Beispiele sind Fragen/Beantwortung bestimmter Datenquellen.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
Ähnlichkeitssuche
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
Agenten betreffen ein LLM, das Entscheidungen darüber trifft, welche Maßnahmen ergriffen werden müssen, diese Maßnahmen ergreifen, eine Beobachtung sehen und diese wiederholen, bis sie durchgeführt werden. Langchain bietet eine Standardschnittstelle für Agenten, eine Auswahl von Agenten zur Auswahl und Beispiele von End-to-End-Agenten. Die Kernidee der Agenten besteht darin, eine LLM zu verwenden, um eine Folge von Aktionen zu wählen, die er ergreifen sollten. In Ketten ist eine Folge von Aktionen festcodiert (im Code). In Agenten wird ein Sprachmodell als Argumentationsmotor verwendet, um zu bestimmen, welche Aktionen und in welcher Reihenfolge ergriffen werden sollen.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Das Gedächtnis bezieht sich auf den anhaltenden Zustand zwischen den Anrufen einer Kette/eines Agenten. Langchain bietet eine Standardschnittstelle für Speicher, eine Sammlung von Speicherimplementierungen und Beispiele für Ketten/Agenten, die Speicher verwenden.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
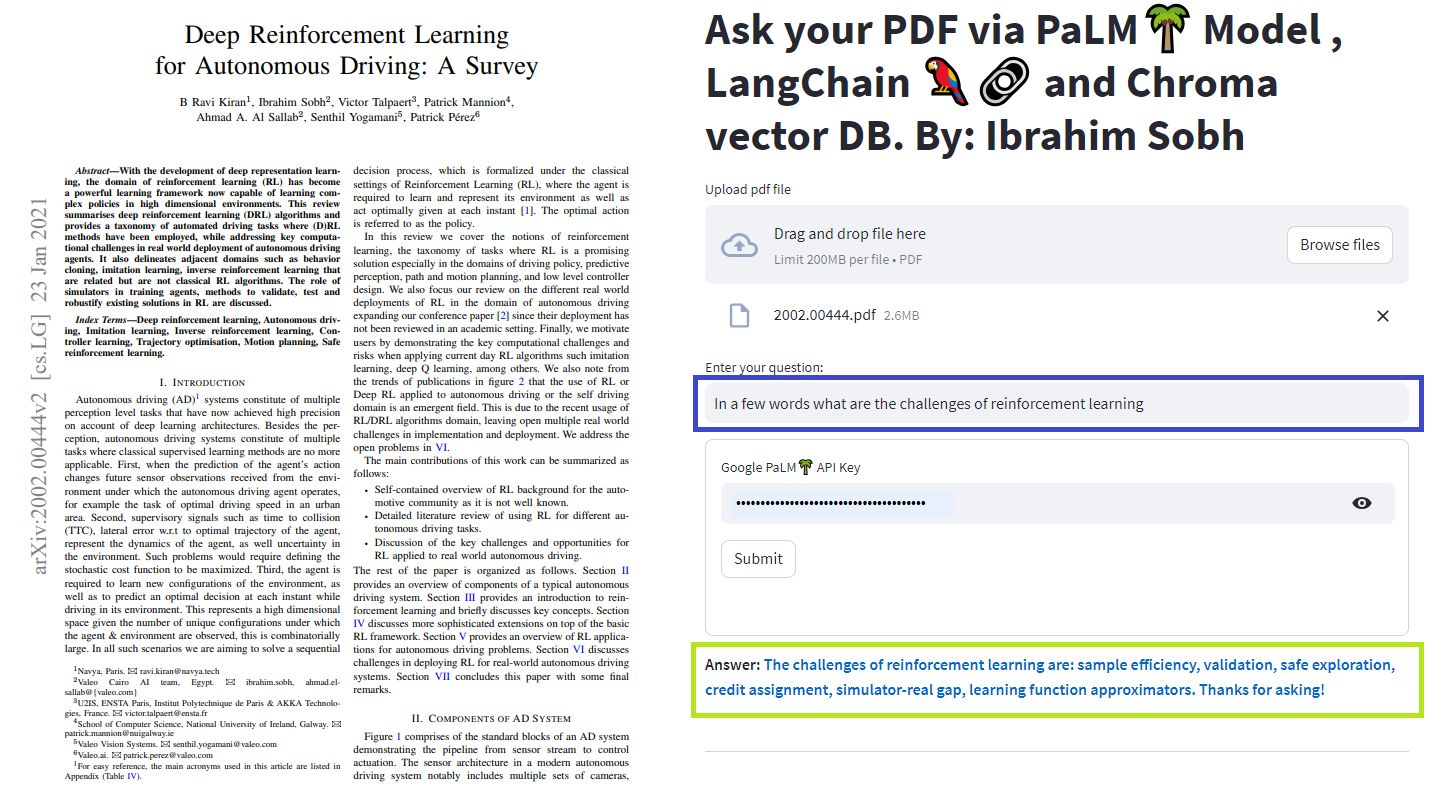
Wir können verschiedene Methoden verwenden, um mit unseren Dokumenten zu chatten. Sie müssen nicht die gesamte LLM fein abschneiden, sondern können den richtigen Kontext zusammen mit unserer Frage an das vorgebrachte Modell bereitstellen und einfach die Antworten auf basierend auf unseren bereitgestellten Dokumenten erhalten.
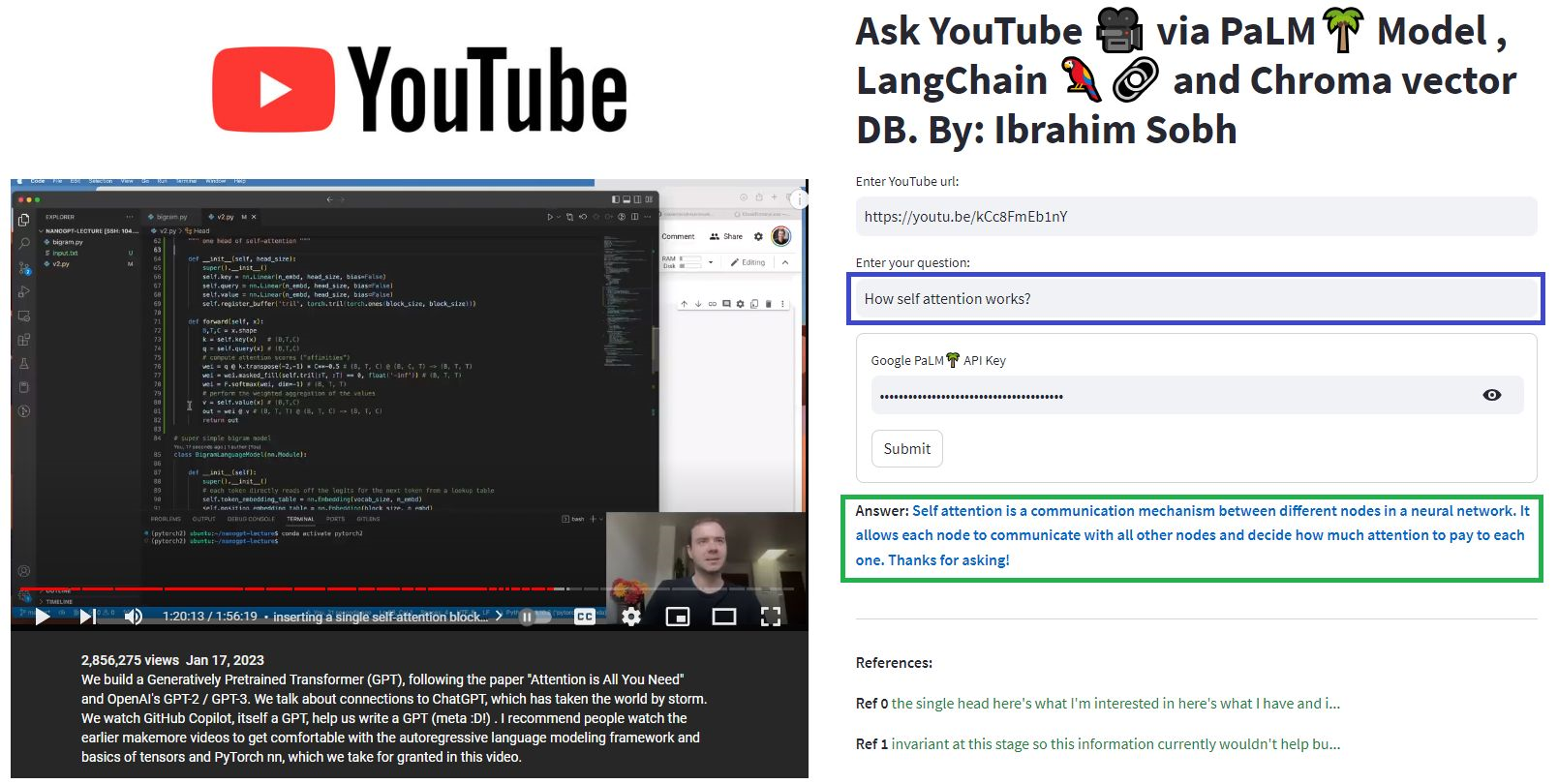
Hier unterhalten wir uns mit diesem schönen Artikel mit dem Titel Transformers ohne Schmerzen? Stellen Sie Fragen zu Transformatoren, Aufmerksamkeit, Encoder-Decoder usw. und verwenden Sie das leistungsstarke Palmmodell durch Google und das Langchain-Framework für die Entwicklung von Anwendungen, die von Sprachmodellen betrieben werden.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
Frage : ? "Worum geht es in diesen Dokumenten?"
Antwort : ? "In den Dokumenten handelt es sich um Transformatoren, die eine Art neuronaler Netzwerk sind, das erfolgreich in der Verarbeitung natürlicher Sprache und der Computer -Vision -Aufgaben verwendet wurde."
Frage : ? "Was ist die Hauptidee von Transformatoren?"
Antwort : ? "Die Hauptidee von Transformatoren ist es, Aufmerksamkeitsmechanismen zu verwenden, um Abhängigkeiten von Langstrecken in Sequenzen zu modellieren."
Frage : ? "Was ist Positionscodierung?"
Antwort : ? "Positionscodierung ist eine Technik, mit der die Reihenfolge der Wörter in einer Sequenz dargestellt wird."
Frage : ? "Wie werden Abfrage-, Schlüssel- und Wertvektoren verwendet?"
Antwort : ? 'Der Abfragevektor wird verwendet, um eine gewichtete Summe der Werte durch die Schlüssel zu berechnen. Insbesondere: Q Punktprodukt alle Schlüssel, dann Softmax, um Gewichte zu erhalten und schließlich diese Gewichte zu verwenden, um eine gewichtete Summe der Werte zu berechnen. '
Frage : ? "Wie fange ich an, Transformatoren zu verwenden? '
Antwort : ? „Um Transformers zu verwenden, können Sie die Suggingface -Transformers -Bibliothek verwenden. Diese Bibliothek bietet Tausenden von vorbereiteten Modellen, um Aufgaben zu Texten wie Klassifizierung, Informationsextraktion, Fragenbeantwortung, Zusammenfassung, Übersetzung, Textgenerierung usw. in mehr als 100 Sprachen auszuführen. '
Sie können Ihre eigenen Dokumente und Fragen ausprobieren!
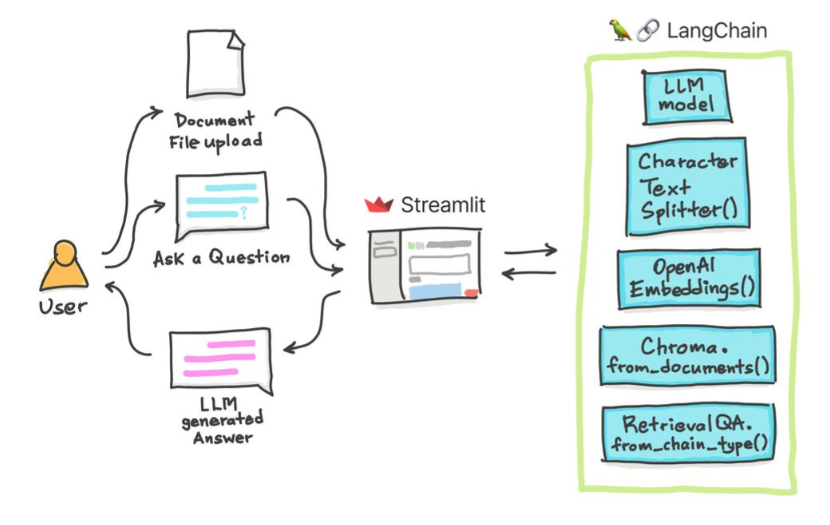
In diesen einfachen Tutorials: So erhalten Sie Antworten aus Textdokumenten , PDF -Dateien und sogar YouTube -Videos mithilfe der Chroma Vector -Datenbank, Palm LLM von Google und einer Frage, die Kette von Langchain aus Langchain beantwortet. Verwenden Sie schließlich Streamlit, um die Webanwendung zu entwickeln und zu hosten. Sie müssen Ihren Google_API_Key verwenden (Sie können einen von Google erhalten). Diese Systemarchitektur ist wie folgt:
Es gibt einen Unterschied zwischen der Bewertung eines LLM und der Bewertung eines LLM-basierten Systems. Normalerweise werden LLMs nach generischer Vorabbildung an Standard-Benchmarks bewertet:
LLMS-Systeme können Text zusammenfassen, Fragen beantworten, das Gefühl eines Textes finden, Übersetzung durchführen und vieles mehr. Basierend auf dem System kann die Bewertung wie folgt sein:
Beispielsweise benötigen wir bei Fragen des Fragenbeantwortungssystems Fragen und Antworten in unserem Bewertungssatz. We can use human annotators to create gold-standard pairs of questions and answers manually. However, it is costly and time-consuming. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called
Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
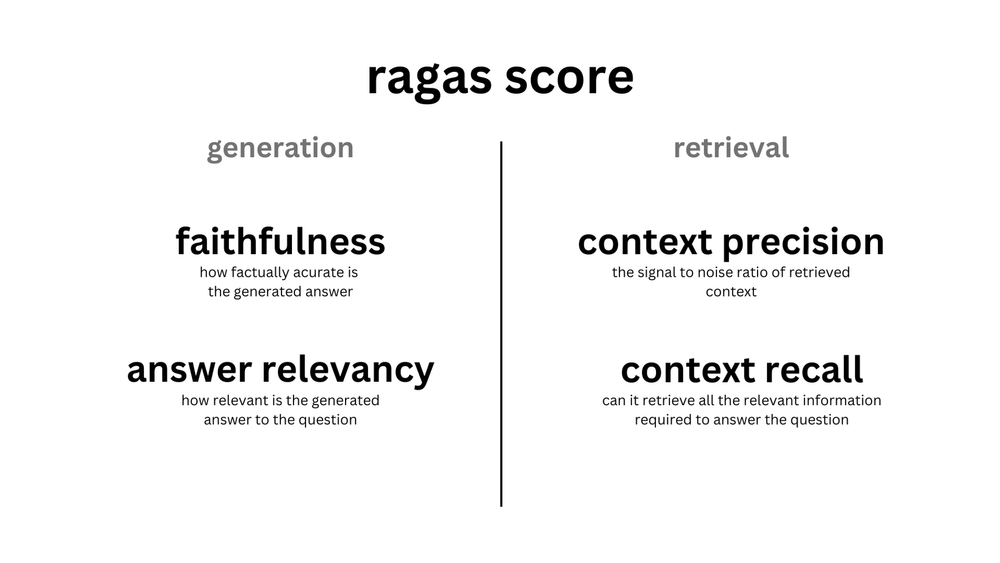
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM's context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
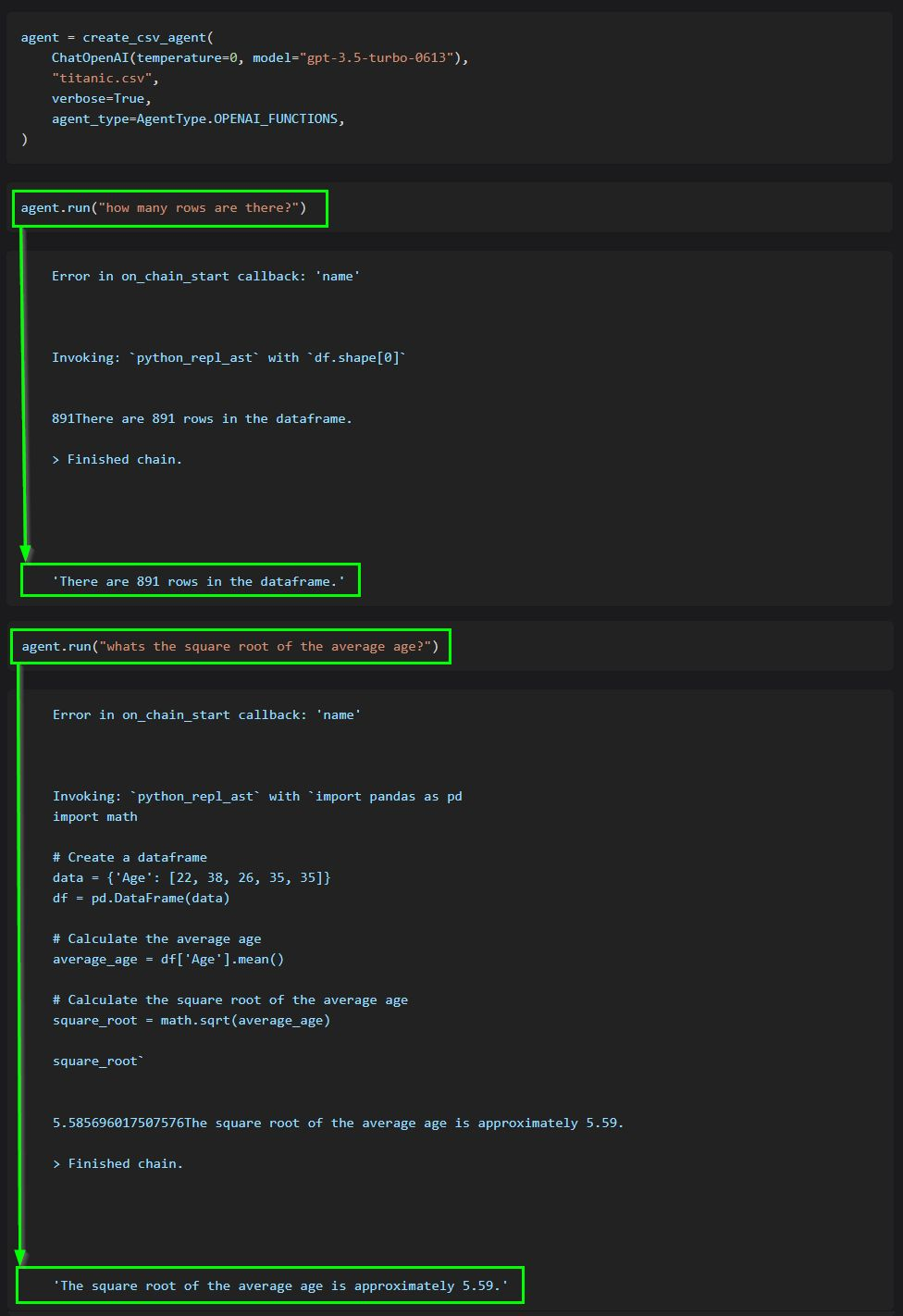
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.
ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.
Examples of extending the power of ChatGPT:
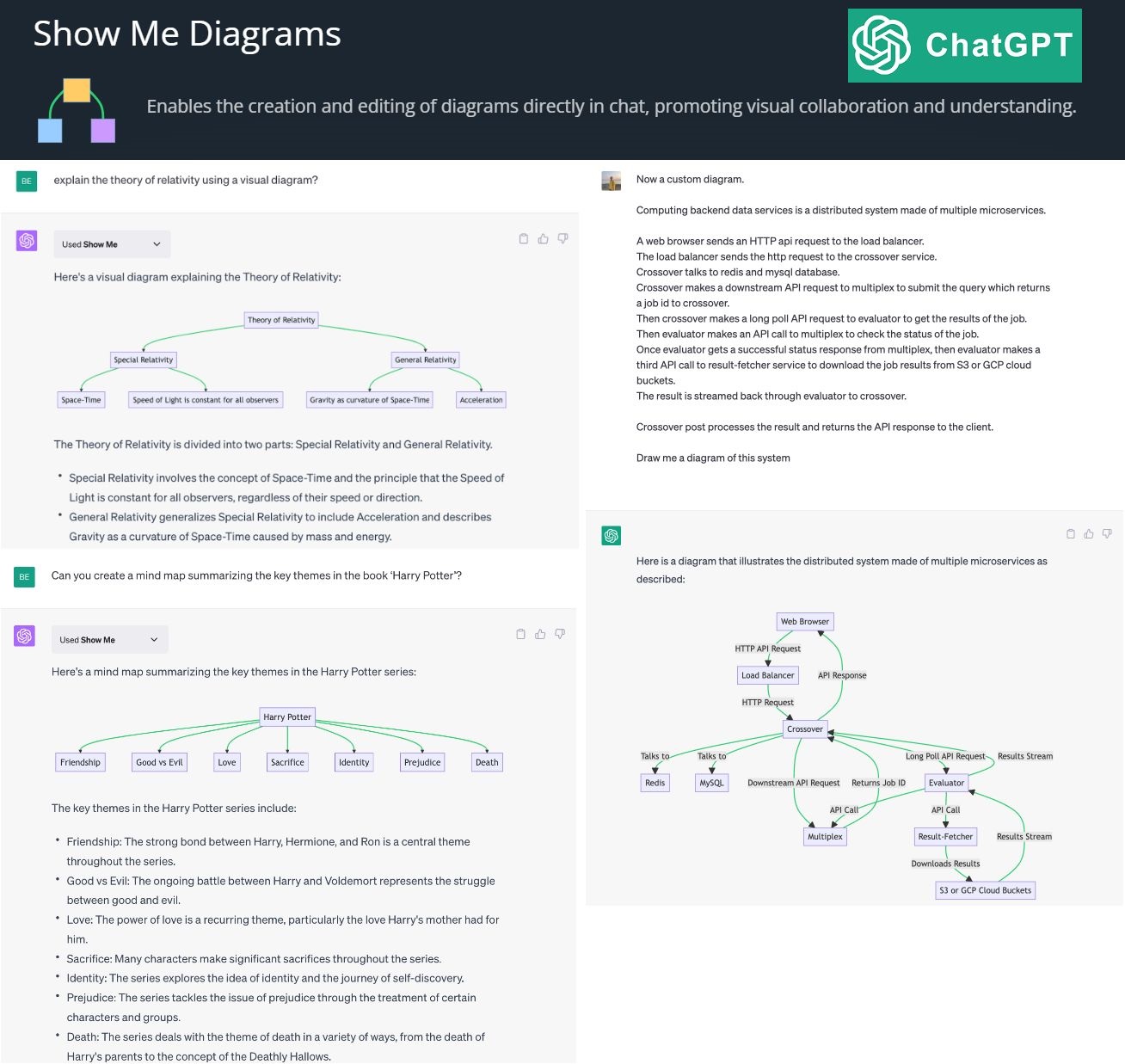
By creating and editing diagrams via Show Me Diagrams
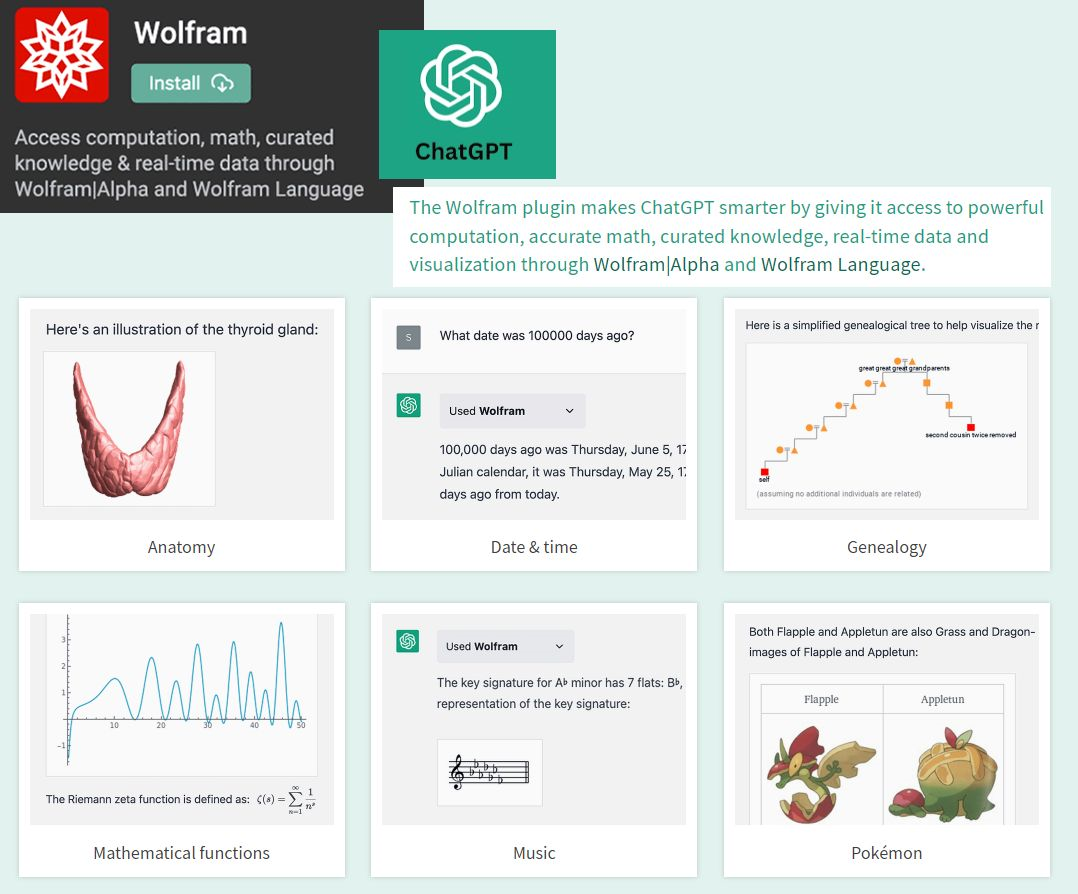
By accessing the power of mathematics provided by Wolfram
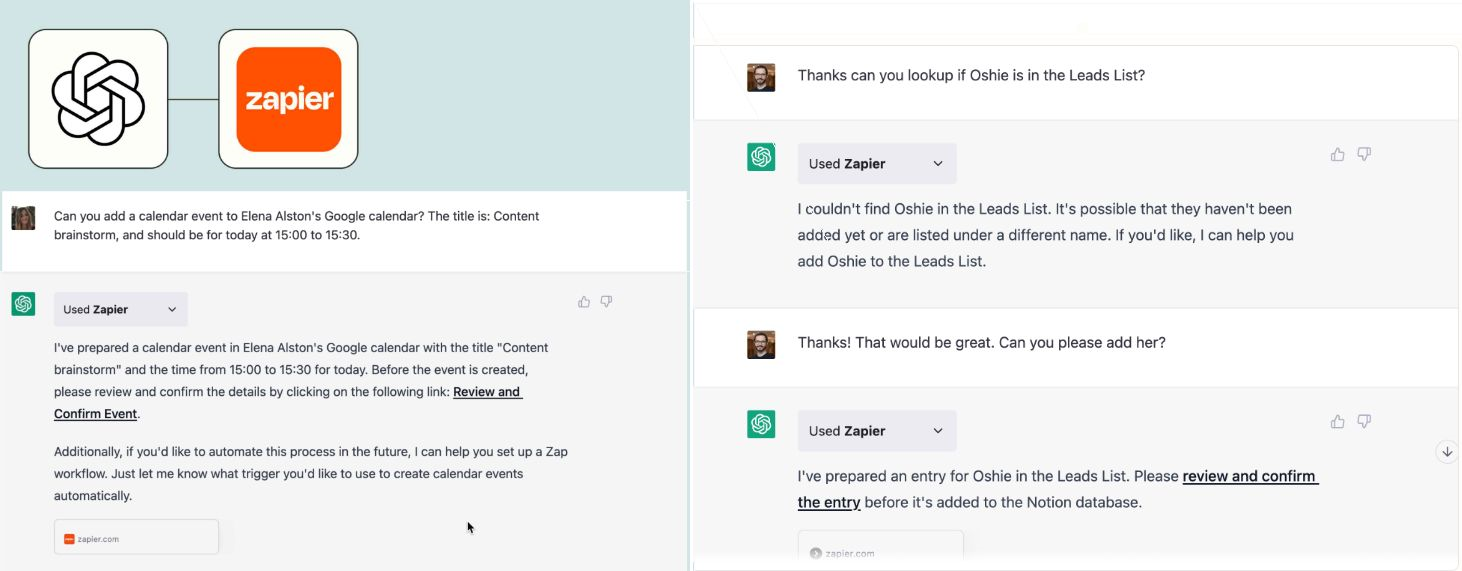
By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.
? AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.


