model2vec
v0.3.3

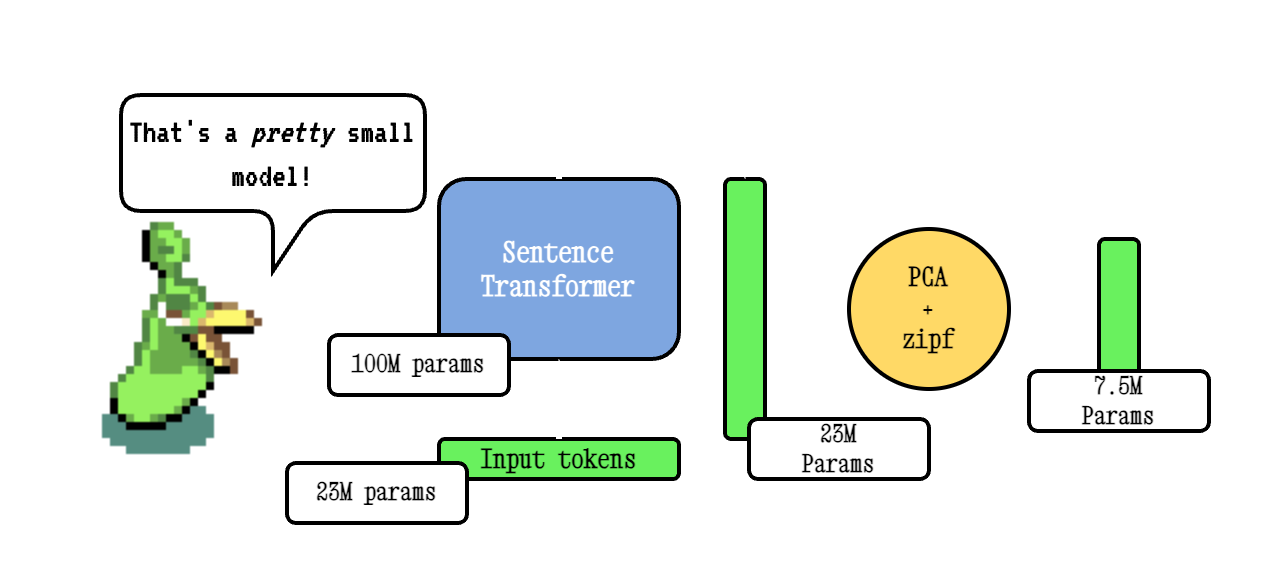
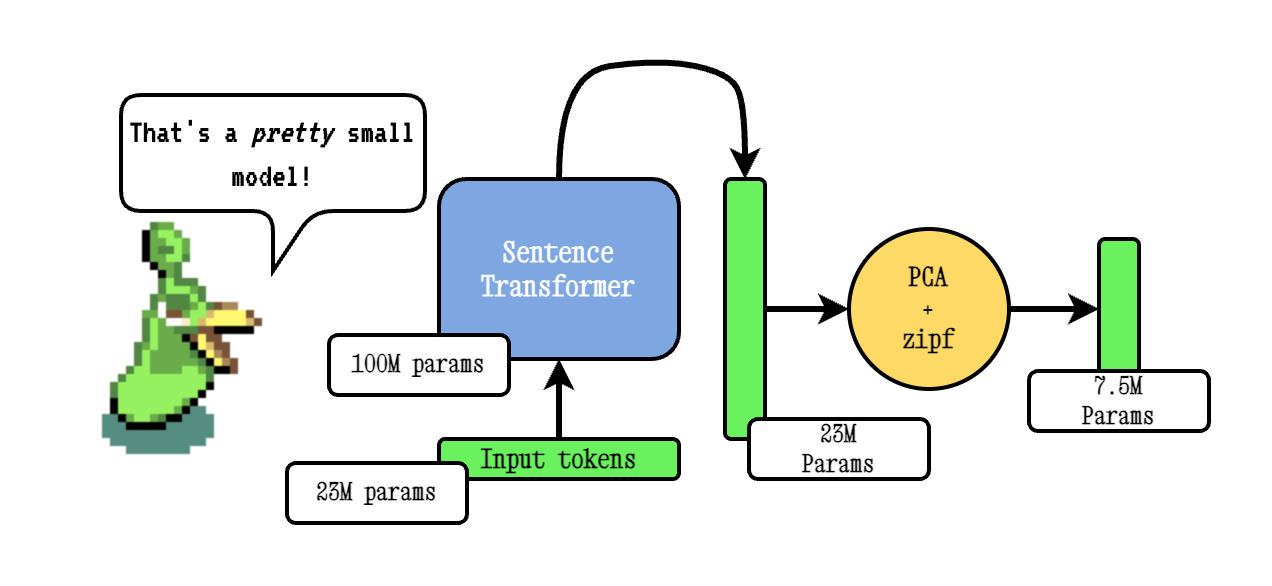
Model2Vec是一种将任何句子变压器变成非常小的静态模型的技术,可将模型大小降低15倍,并使模型更快地提高到500倍,并且性能下降较小。我们的最佳模型是世界上最出色的静态嵌入模型。在此处查看我们的结果,或潜入您的工作原理。
安装包裹:
pip install model2vec这将安装基本推理软件包,该软件包仅取决于numpy和其他一些次要依赖性。如果要蒸馏自己的型号,则可以安装蒸馏量表以下方式:
pip install model2vec[distill]开始使用Model2VEC的最简单方法是从HuggingFace Hub加载我们的旗舰模型之一。这些模型已进行了预训练,可以使用。以下代码片段显示了如何加载模型并制作嵌入:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])就是这样。您可以使用该模型对文本进行分类,群集或构建抹布系统。
您还可以从句子变压器模型中提取自己的Model2VEC模型,而不是使用我们的模型之一。以下代码段显示了如何提炼模型:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )蒸馏真的很快,在CPU上只需要30秒。最重要的是,蒸馏不需要培训数据。
有关高级用法,例如在“句子变形金刚库中使用Model2Vec”,请参阅使用段。
numpy 。from_pretrained和push_to_hub ,可以轻松地共享和加载模型。我们自己的型号可以在这里找到。随时分享自己的。 Model2Vec创建了一个小型,快速且功能强大的模型,该模型在我们可以找到的所有任务上的大幅度优于其他静态嵌入模型,同时比传统的静态嵌入模型(如手套)更快地创建。像BPEMB一样,它可以创建子字嵌入,但性能更好。蒸馏不需要任何数据,只是词汇和模型。
基本模型2VEC技术通过通过句子变压器模型传递词汇,然后使用PCA降低所得嵌入的维度,最后使用ZIPF权重加权嵌入。在推论期间,我们只采用句子中发生的所有令牌嵌入的均值。
我们的药水模型是使用Tokenlearn进行预训练的,Tokenlearn是一种预先培训模型2VEC蒸馏模型的技术。这些模型是通过以下步骤创建的:
smooth inverse frequency (SIF)加权嵌入嵌入: w = 1e-3 / (1e-3 + proba) 。在这里, proba是我们用于培训的语料库中令牌的概率。有关更广泛的深色,请参阅我们的Model2Vec博客文章和我们的Tokenlearn博客文章。
推理的作用如下。该示例显示了我们自己的一个模型,但是您也可以加载一个本地的模型,或者从集线器上加载另一个模型。
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])以下代码段显示了如何在句子变形金刚库中使用Model2VEC模型。如果要在句子变形金刚管道中使用模型,这将很有用。
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])以下代码可用于从句子变压器中提炼模型。如上所述,这会导致非常小的模型,这种模型的性能可能较低。
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )如果您已经加载了模型,或者需要以某种特殊的方式加载模型,我们还提供了一个接口来提炼内存中的模型。
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )以下代码段显示了如何使用句子变形金刚库提炼模型。如果要在句子变形金刚管道中使用模型,这将很有用。
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])如果您通过词汇量,您将获得一组静态单词嵌入,以及一个定制的令牌仪以符合该词汇。这与您如何使用手套或传统Word2Vec相媲美,但实际上并不需要语料库或数据。
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" )默认情况下,这将用子词令牌将模型提炼,将模型(子字)词汇与新词汇结合在一起。如果您想获得一个单词级令牌(仅使用传递的词汇),则可以将use_subword参数设置为False ,例如:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False )重要说明:我们假设传递的词汇以等级频率排序。即,我们不在乎实际的单词频率,但确实假设最常见的单词是第一个,而最少的单词是最后的。如果您不确定是否是情况,请将apply_zipf设置为False 。这可以禁用加权,但也会使性能变得更糟。
可以使用我们的评估软件包评估我们的模型。安装评估包:
pip install git+https://github.com/MinishLab/evaluation.git@main以下代码片段显示了如何评估模型2VEC模型:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores ))Model2Vec可以使用StaticEmbedding模块直接在句子变压器中使用。
以下代码段显示了如何将Model2VEC模型加载到句子变压器模型中:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])以下代码片段显示了如何将模型直接提炼成句子变压器模型:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])有关更多文档,请参阅“句子变形金刚”文档。
Model2Vec可以在TXTAI中用于文本嵌入,最近的邻居搜索以及TXTAI提供的任何其他功能。以下代码片段显示了如何在TXTAI中使用Model2Vec:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2Vec是Chonkie语义块的默认模型。要在Chonkie中使用Model2Vec进行语义块,只需使用pip install chonkie[semantic] ,然后使用SemanticChunker类中的一种potion模型。以下代码片段显示了如何在Chonkie中使用Model2Vec:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )要在变形金刚中使用Model2VEC模型,以下代码片段可以用作起点:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version请注意,这要求Model2Vec具有model.onnx文件和几个必需的Tokenizers文件。为了生成这些模型,可以使用以下代码片段:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " 我们提供了可以开箱即用的许多型号。这些模型可在HuggingFace Hub上使用,可以使用from_pretrained方法加载。这些模型在下面列出。
| 模型 | 语言 | 词汇 | 句子变压器 | 令牌类型 | 参数 | tokenlearn |
|---|---|---|---|---|---|---|
| 电池基8m | 英语 | 输出 | BGE-BASE-EN-V1.5 | 子字 | 7.5m | ✅ |
| 电池基4m | 英语 | 输出 | BGE-BASE-EN-V1.5 | 子字 | 3.7m | ✅ |
| 电碱-2M | 英语 | 输出 | BGE-BASE-EN-V1.5 | 子字 | 18m | ✅ |
| m2v_multlingual_output | 多种语言 | 输出 | Labse | 子字 | 471m |
我们已经进行了广泛的实验,以评估Model2VEC模型的性能。结果记录在结果文件夹中。结果在以下各节中介绍:
麻省理工学院
如果您在研究中使用Model2Vec,请引用以下内容:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

