model2vec
v0.3.3

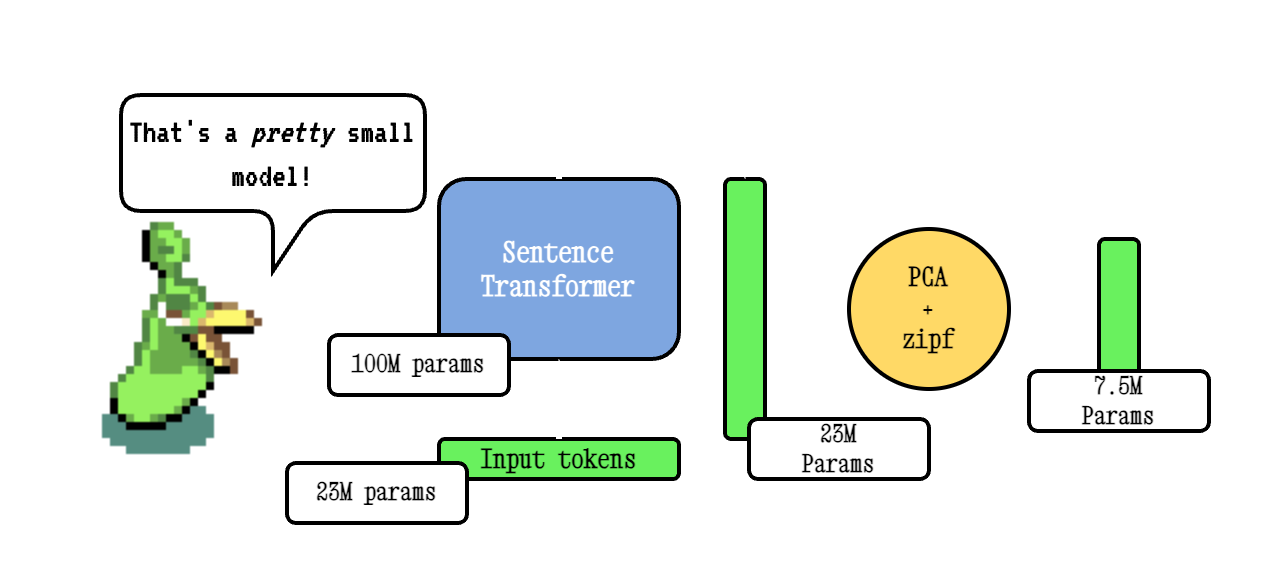
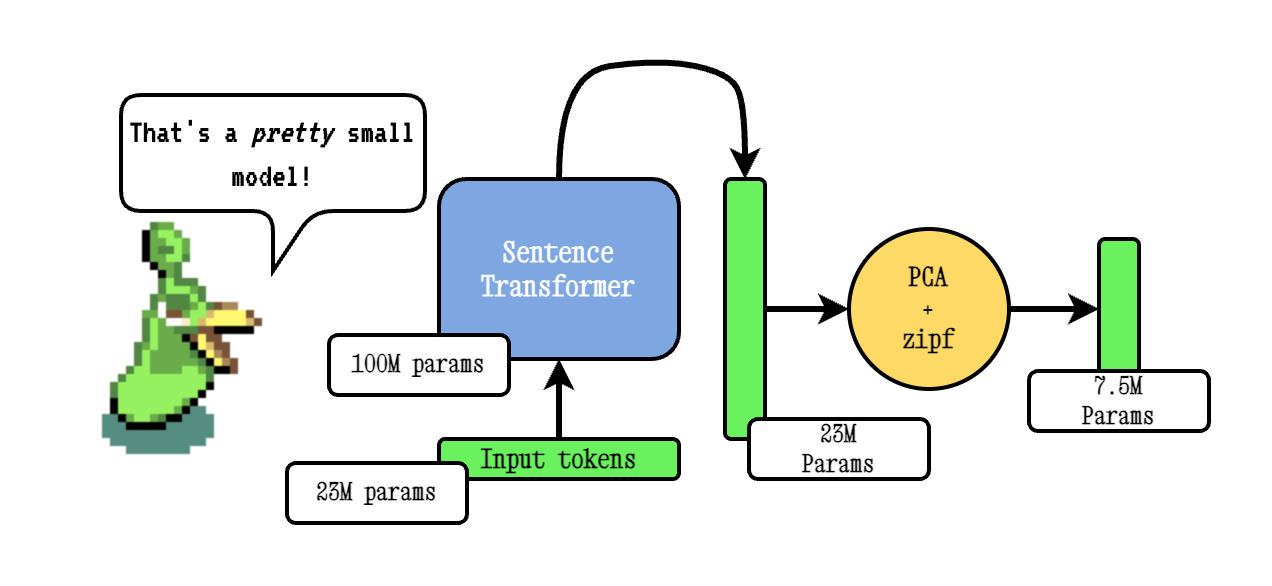
Model2VEC ist eine Technik, um jeden Satztransformator in ein wirklich kleines statisches Modell zu verwandeln, wodurch die Modellgröße um 15x reduziert und die Modelle mit einem kleinen Leistungsrückgang um bis zu 500x schneller gestaltet werden. Unser bestes Modell ist das leistungsstärkste statische Einbettungsmodell der Welt. Sehen Sie unsere Ergebnisse hier oder tauchen Sie ein, um zu sehen, wie es funktioniert.
Installieren Sie das Paket mit:
pip install model2vec Dadurch wird das Basisinferenzpaket installiert, das nur von numpy und einigen anderen kleinen Abhängigkeiten abhängt. Wenn Sie Ihre eigenen Modelle destillieren möchten, können Sie die Destillation -Extras mit:
pip install model2vec[distill]Der einfachste Weg, um mit Model2VEC zu beginnen, besteht darin, eines unserer Flaggschiff -Modelle aus dem Huggingface -Hub zu laden. Diese Modelle sind vorgeschrieben und verwendet. Das folgende Code -Snippet zeigt, wie ein Modell geladen und Einbettung erstellt wird:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Und das war's. Sie können das Modell verwenden, um Texte zu klassifizieren, sich zu gruppieren oder ein Lappensystem zu erstellen.
Anstatt eines unserer Modelle zu verwenden, können Sie auch Ihr eigenes Modell2VEC -Modell von einem Satztransformatormodell destillieren. Das folgende Code -Snippet zeigt, wie ein Modell destilliert werden soll:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Die Destillation ist sehr schnell und dauert nur 30 Sekunden bei der CPU. Das Beste ist, dass die Destillation keine Trainingsdaten erfordert.
Für die fortgeschrittene Verwendung, z. B. die Verwendung von Modell2VEC in der Satztransformatoren -Bibliothek, finden Sie in den Verwendungsabschnitten.
numpy .from_pretrained und push_to_hub in den Huggingface -Hub integriert und laden Modelle aus dem Huggingface -Hub. Unsere eigenen Modelle finden Sie hier. Fühlen Sie sich frei, Ihre eigenen zu teilen. Model2VEC erstellt ein kleines, schnelles und leistungsstarkes Modell, das andere statische Einbettungsmodelle mit einem großen Rand für alle Aufgaben übertrifft, die wir finden konnten, und zwar viel schneller zu erstellen als herkömmliche statische Einbettungsmodelle wie Handschuh. Wie BPEMB kann es Subword -Einbettungen erstellen, jedoch mit viel besserer Leistung. Die Destillation benötigt keine Daten, nur ein Wortschatz und ein Modell.
Die Basismodell2VEC -Technik erfolgt, indem sie ein Vokabular durch ein Satztransformatormodell übergeben, dann die Dimensionalität der resultierenden Einbettungen mithilfe von PCA reduziert und schließlich die Einbettungsdings mithilfe der ZiPF -Gewichtung abschließt. Während der Inferenz nehmen wir einfach den Mittelwert aller Token -Einbettungen, die in einem Satz auftreten.
Unsere Trankmodelle werden unter Verwendung von Tokenlearn, einer Technik für Modell2VEC-Destillationsmodelle vor dem Training, ausgebildet. Diese Modelle werden mit den folgenden Schritten erstellt:
smooth inverse frequency (SIF) unter Verwendung der folgenden Formel gewichtet: w = 1e-3 / (1e-3 + proba) . Hier ist proba die Wahrscheinlichkeit des Tokens im Korpus, den wir zum Training verwendet haben.Für einen viel umfangreicheren Tiefe finden Sie in unserem Model2VEC -Blogbeitrag und in unserem Blog -Beitrag zum Tokenlearn.
Inferenz funktioniert wie folgt. Das Beispiel zeigt eines unserer eigenen Modelle, aber Sie können auch nur einen lokalen oder anderen aus dem Hub laden.
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Das folgende Code -Snippet zeigt, wie ein Modell2VEC -Modell in der Satztransformatorenbibliothek verwendet wird. Dies ist nützlich, wenn Sie das Modell in einer Satztransformatoren -Pipeline verwenden möchten.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Der folgende Code kann verwendet werden, um ein Modell aus einem Satztransformator zu destillieren. Wie oben erwähnt, führt dies zu wirklich kleinem Modell, das weniger leistungsfähig sein könnte.
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Wenn Sie bereits über ein Modell geladen sind oder ein Modell auf besondere Weise laden müssen, bieten wir auch eine Schnittstelle zur Destillation von Modellen im Speicher an.
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )Das folgende Code -Snippet zeigt, wie ein Modell mithilfe der Satztransformatorenbibliothek destilliert werden kann. Dies ist nützlich, wenn Sie das Modell in einer Satztransformatoren -Pipeline verwenden möchten.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Wenn Sie ein Wortschatz bestehen, erhalten Sie eine Reihe statischer Worteinbettungen zusammen mit einem benutzerdefinierten Tokenizer für genau dieses Wortschatz. Dies ist vergleichbar mit der Verwendung von Handschuh oder herkömmlichem Word2VEC, benötigt jedoch keinen Korpus oder Daten.
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) Standardmäßig destilliert dies ein Modell mit einem Subword -Tokenizer und kombiniert das Modelle (Subword) -Vokabale mit dem neuen Wortschatz. Wenn Sie stattdessen einen Tokenizer auf Wortebene erhalten möchten (mit nur dem übergebenen Wortschatz), kann der Parameter use_subword auf False festgelegt werden, z. B.:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) Wichtiger Hinweis: Wir gehen davon aus, dass das bestandene Vokabular in Rangfrequenz sortiert ist. dh die tatsächlichen Wortfrequenzen interessieren uns nicht, aber gehen Sie davon aus, dass das häufigste Wort zuerst ist und das am wenigsten häufige Wort zuletzt ist. Wenn Sie sich nicht sicher sind, ob dies der Fall ist, setzen Sie apply_zipf auf False . Dies deaktiviert die Gewichtung, wird aber auch die Leistung etwas verschlimmern.
Unsere Modelle können mit unserem Bewertungspaket bewertet werden. Installieren Sie das Bewertungspaket mit:
pip install git+https://github.com/MinishLab/evaluation.git@mainThe following code snippet shows how to evaluate a Model2Vec model:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) Model2Vec can be used directly in Sentence Transformers using the StaticEmbedding module.
Das folgende Code -Snippet zeigt, wie ein Modell2VEC -Modell in ein Satztransformatormodell geladen wird:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Das folgende Code -Snippet zeigt, wie ein Modell direkt in ein Satztransformatormodell destilliert werden kann:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Weitere Unterlagen finden Sie in der Dokumentation der Satztransformatoren.
Model2VEC kann in TXTAI für Texteinbettungen, die Suche nach nächster Nachbarn und die anderen Funktionen, die TXTAI anbietet, verwendet werden. Das folgende Code -Snippet zeigt, wie Sie Model2VEC in TXTAI verwenden:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2VEC ist das Standardmodell für das semantische Chunking in Chonkie. Um Model2VEC für das semantische Chunking in Chonkie zu verwenden, installieren Sie einfach Chonkie mit pip install chonkie[semantic] und verwenden Sie eines der potion in der SemanticChunker -Klasse. Das folgende Code -Snippet zeigt, wie Sie Model2VEC in Chonkie verwenden:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )Um ein Modell2VEC -Modell in Transformers.js zu verwenden, kann der folgende Code -Snippet als Ausgangspunkt verwendet werden:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version Beachten Sie, dass dies erfordert, dass das Model2VEC über eine model.onnx -Datei und mehrere erforderliche Tokenizer -Datei verfügt. Um diese für ein Modell zu generieren, das sie noch nicht hat, kann das folgende Code -Snippet verwendet werden:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " Wir stellen eine Reihe von Modellen bereit, die aus dem Box verwendet werden können. Diese Modelle sind auf dem Huggingface -Hub verfügbar und können mit der von der from_pretrained Methode geladen werden. Die Modelle sind unten aufgeführt.
| Modell | Sprache | Wortschatz | Satztransformator | Tokenizer -Typ | Parameter | Tokenlearn |
|---|---|---|---|---|---|---|
| Trankbasis-8m | Englisch | Ausgabe | bge-base-en-v1.5 | Subword | 7,5 m | ✅ |
| Trankbasis-4m | Englisch | Ausgabe | bge-base-en-v1.5 | Subword | 3,7 m | ✅ |
| Trankbasis-2m | Englisch | Ausgabe | bge-base-en-v1.5 | Subword | 1,8 m | ✅ |
| M2v_multilingual_output | Mehrsprachig | Ausgabe | Labor | Subword | 471m |
Wir haben umfangreiche Experimente durchgeführt, um die Leistung von Modell2VEC -Modellen zu bewerten. Die Ergebnisse sind im Ergebnisordner der Ergebnisse dokumentiert. Die Ergebnisse werden in den folgenden Abschnitten dargestellt:
MIT
Wenn Sie Modell2VEC in Ihrer Forschung verwenden, geben Sie Folgendes an:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

