model2vec
v0.3.3

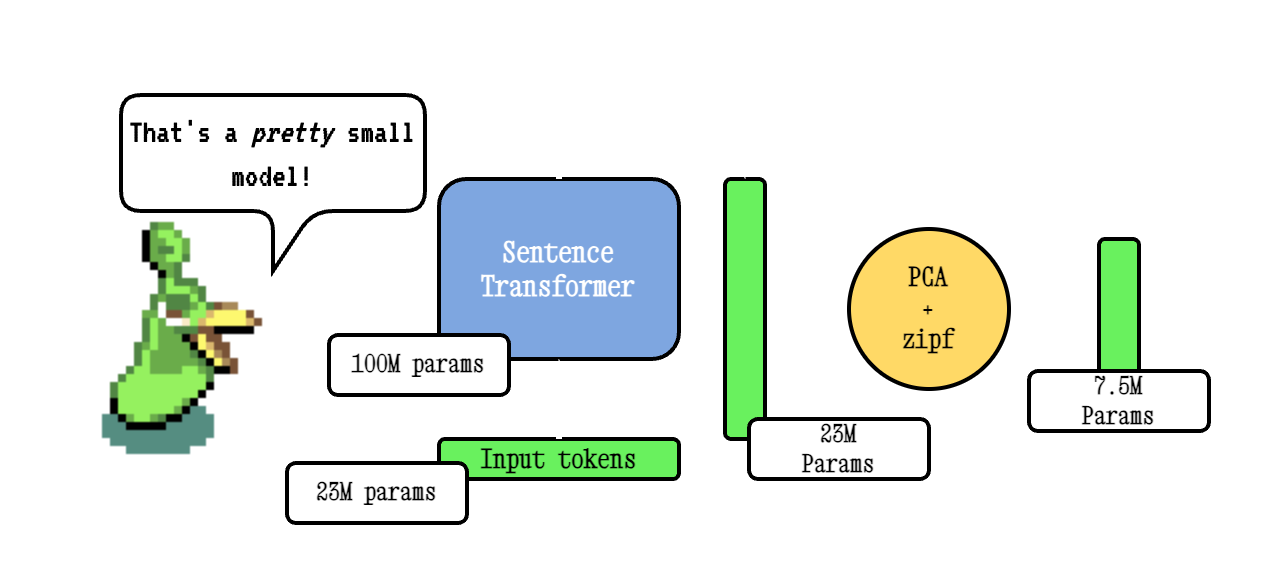
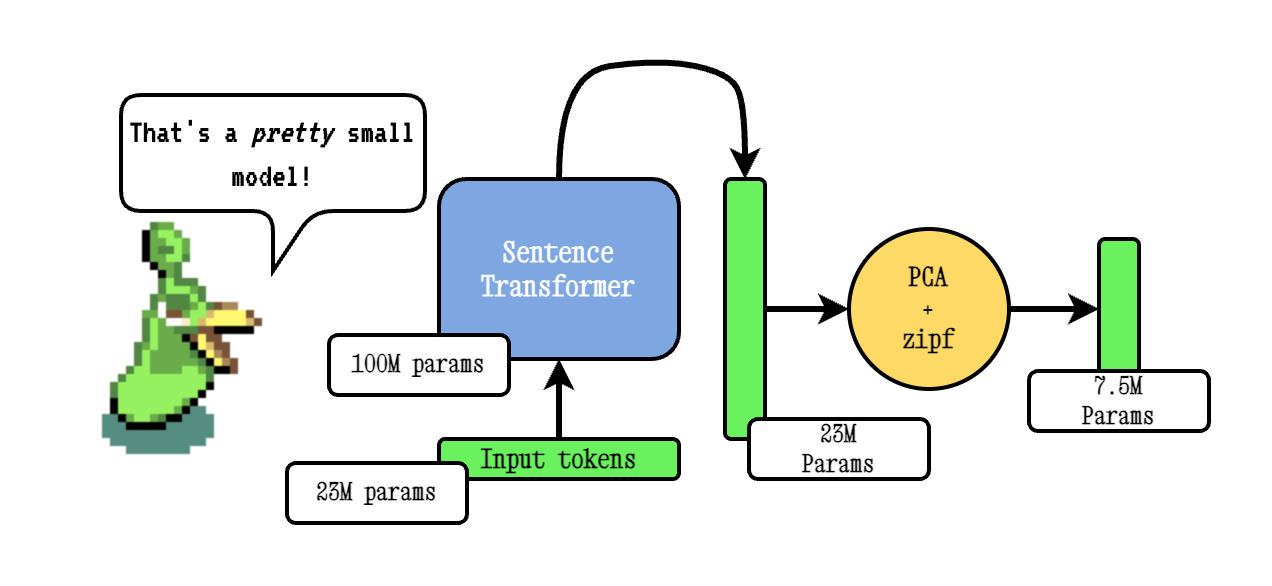
Model2Vec هي تقنية لتحويل أي محول جملة إلى نموذج ثابت صغير حقًا ، مما يقلل من حجم الطراز بمقدار 15x وجعل النماذج تصل إلى 500x أسرع ، مع انخفاض صغير في الأداء. أفضل نموذج لدينا هو نموذج التضمين الثابت الأكثر أداء في العالم. انظر نتائجنا هنا ، أو الغوص لترى كيف يعمل.
تثبيت الحزمة مع:
pip install model2vec سيؤدي ذلك إلى تثبيت حزمة الاستدلال الأساسية ، والتي تعتمد فقط على numpy وبعض التبعيات البسيطة الأخرى. إذا كنت ترغب في تقطير النماذج الخاصة بك ، يمكنك تثبيت إضافات التقطير مع:
pip install model2vec[distill]أسهل طريقة للبدء مع Model2Vec هي تحميل أحد الطرز الرئيسية لدينا من Huggingface Hub. هذه النماذج مدربة مسبقًا وجاهزة للاستخدام. يوضح مقتطف الكود التالي كيفية تحميل نموذج وجعل التضمينات:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])وهذا كل شيء. يمكنك استخدام النموذج لتصنيف النصوص ، أو التجميع ، أو لبناء نظام خرقة.
بدلاً من استخدام أحد طرزنا ، يمكنك أيضًا تقطير نموذج Model2Vec الخاص بك من نموذج محول الجملة. يوضح مقتطف الكود التالي كيفية تقطير النموذج:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )التقطير سريع حقًا ولا يستغرق سوى 30 ثانية على وحدة المعالجة المركزية. أفضل للجميع ، التقطير لا يتطلب أي بيانات تدريب.
للاستخدام المتقدم ، مثل استخدام Model2Vec في مكتبة Transformers الجملة ، يرجى الرجوع إلى أقسام الاستخدام.
numpy .from_pretrained و push_to_hub . يمكن العثور على نماذجنا الخاصة هنا. لا تتردد في مشاركة بنفسك. ينشئ Model2Vec نموذجًا صغيرًا وسريعًا وقويًا يتفوق على نماذج التضمين الثابتة الأخرى بهامش كبير في جميع المهام التي يمكن أن نجدها ، مع كونها أسرع بكثير لإنشاء نماذج التضمين الثابتة التقليدية مثل القفاز. مثل BPEMB ، يمكن أن يخلق تضمينات من الكلمات الفرعية ، ولكن مع أداء أفضل بكثير. التقطير لا يحتاج إلى أي بيانات ، مجرد مفردات ونموذج.
تعمل تقنية Base Model2Vec عن طريق تمرير المفردات من خلال نموذج محول الجملة ، ثم تقليل أبعاد التضمين الناتجة باستخدام PCA ، وأخيراً ترجيح التضمينات باستخدام ترجيح ZIPF. أثناء الاستدلال ، نأخذ ببساطة متوسط كل التضمينات الرمزية التي تحدث في جملة.
يتم تدريب نماذج الجرعة الخاصة بنا مسبقًا باستخدام Tokenlearn ، وهي تقنية لنماذج تقطير Model2VEC قبل المدربين. يتم إنشاء هذه النماذج مع الخطوات التالية:
smooth inverse frequency (SIF) باستخدام الصيغة التالية: w = 1e-3 / (1e-3 + proba) . هنا ، proba هو احتمال الرمز المميز في المجموعة التي استخدمناها للتدريب.للحصول على أعماق أكثر شمولاً ، يرجى الرجوع إلى منشور مدونة Model2Vec ونشر مدونة Tokenlearn.
الاستدلال يعمل على النحو التالي. يوضح المثال أحد طرزنا الخاصة ، ولكن يمكنك أيضًا تحميل واحد محلي أو آخر من المحور.
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])يوضح مقتطف الكود التالي كيفية استخدام نموذج Model2Vec في مكتبة Transformers الجملة. هذا مفيد إذا كنت ترغب في استخدام النموذج في خط أنابيب محولات الجملة.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])يمكن استخدام الكود التالي لتقطير نموذج من محول الجملة. كما ذكر أعلاه ، هذا يؤدي إلى نموذج صغير حقًا قد يكون أقل أداء.
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )إذا كان لديك بالفعل نموذج تم تحميله ، أو بحاجة إلى تحميل نموذج بطريقة خاصة ، فنحن نقدم أيضًا واجهة لتقطير النماذج في الذاكرة.
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )يوضح مقتطف الكود التالي كيفية تقطير نموذج باستخدام مكتبة Transformers الجملة. هذا مفيد إذا كنت ترغب في استخدام النموذج في خط أنابيب محولات الجملة.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])إذا قمت بتمرير مفردات ، فستحصل على مجموعة من تضمينات الكلمات الثابتة ، مع رمز مخصص لهذا المفردات بالضبط. هذا مشابه لكيفية استخدام القفاز أو Word2Vec التقليدي ، ولكنه لا يتطلب بالفعل مجموعة أو بيانات.
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) بشكل افتراضي ، سيؤدي ذلك إلى تقطير نموذج مع رمز رمزي فرعي ، يجمع بين المفردات النماذج (الكلمة الفرعية) مع المفردات الجديدة. إذا كنت ترغب في الحصول على رمز على مستوى الكلمات بدلاً من ذلك (مع المفردات التي تم تمريرها فقط) ، يمكن تعيين معلمة use_subword على False ، على سبيل المثال:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) ملاحظة مهمة: نفترض أن المفردات التي تم تمريرها يتم فرزها في تردد الرتبة. أي ، نحن لا نهتم بترددات الكلمات الفعلية ، لكن نفترض أن الكلمة الأكثر شيوعًا هي الأولى ، وأن الكلمة الأقل تكرارًا هي الأخيرة. إذا لم تكن متأكدًا مما إذا كانت هذه هي الحالة ، فقم بتعيين apply_zipf إلى False . هذا يعطل الترجيح ، ولكنه سيجعل الأداء أسوأ قليلاً.
يمكن تقييم نماذجنا باستخدام حزمة التقييم الخاصة بنا. تثبيت حزمة التقييم مع:
pip install git+https://github.com/MinishLab/evaluation.git@mainيوضح مقتطف الكود التالي كيفية تقييم نموذج Model2Vec:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) يمكن استخدام Model2Vec مباشرة في محولات الجملة باستخدام وحدة StaticEmbedding .
يوضح مقتطف الكود التالي كيفية تحميل نموذج Model2Vec في نموذج محول الجملة:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])يوضح مقتطف الكود التالي كيفية تقطير نموذج مباشرة في نموذج محول الجملة:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])لمزيد من الوثائق ، يرجى الرجوع إلى وثائق Transformers الجملة.
يمكن استخدام Model2VEC في Txtai للتضمينات النصية ، والبحث عن الأقرباء ، وأي من الوظائف الأخرى التي يوفرها Txtai. يوضح مقتطف الكود التالي كيفية استخدام Model2Vec في Txtai:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2VEC هو النموذج الافتراضي للتشكيل الدلالي في Chonkie. لاستخدام Model2VEC للقطع الدلالي في Chonkie ، ما عليك سوى تثبيت Chonkie مع pip install chonkie[semantic] واستخدام أحد طرز potion في فئة SemanticChunker . يوضح مقتطف الكود التالي كيفية استخدام Model2Vec في Chonkie:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )لاستخدام نموذج Model2VEC في Transformers.js ، يمكن استخدام مقتطف الكود التالي كنقطة انطلاق:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version لاحظ أن هذا يتطلب أن يكون لدى Model2Vec ملف model.onnx . لإنشاءها لنموذج لا يحتوي عليها بعد ، يمكن استخدام مقتطف الكود التالي:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " نحن نقدم عددًا من النماذج التي يمكن استخدامها خارج الصندوق. تتوفر هذه النماذج على مركز Huggingface ويمكن تحميلها باستخدام طريقة from_pretrained . النماذج مدرجة أدناه.
| نموذج | لغة | المفردات | محول الجملة | نوع الرمز المميز | params | Tokenlearn |
|---|---|---|---|---|---|---|
| PORTION-BASE-8M | إنجليزي | الإخراج | bge-base-en-v1.5 | الكلمة الفرعية | 7.5m | ✅ |
| PORTION-BASE-4M | إنجليزي | الإخراج | bge-base-en-v1.5 | الكلمة الفرعية | 3.7m | ✅ |
| PORTION-BASE-2M | إنجليزي | الإخراج | bge-base-en-v1.5 | الكلمة الفرعية | 1.8 م | ✅ |
| m2v_multilingual_output | متعدد اللغات | الإخراج | لاب | الكلمة الفرعية | 471 م |
لقد أجرينا تجارب واسعة لتقييم أداء نماذج Model2VEC. تم توثيق النتائج في مجلد النتائج. يتم عرض النتائج في الأقسام التالية:
معهد ماساتشوستس للتكنولوجيا
إذا كنت تستخدم Model2Vec في بحثك ، فيرجى الاستشهاد بما يلي:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

