model2vec
v0.3.3

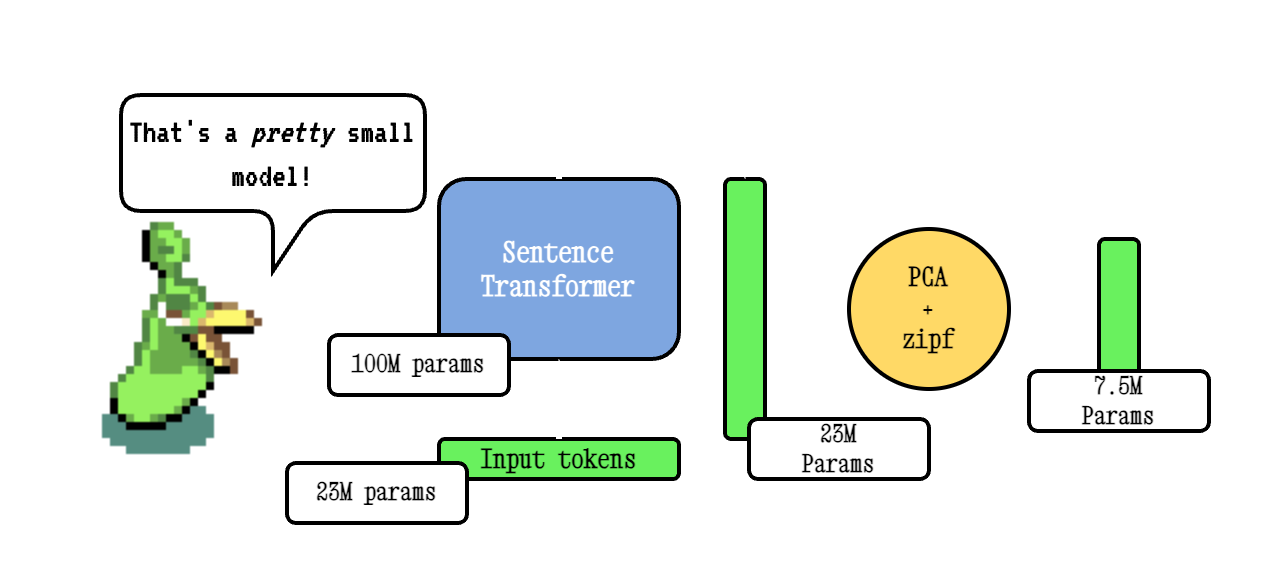
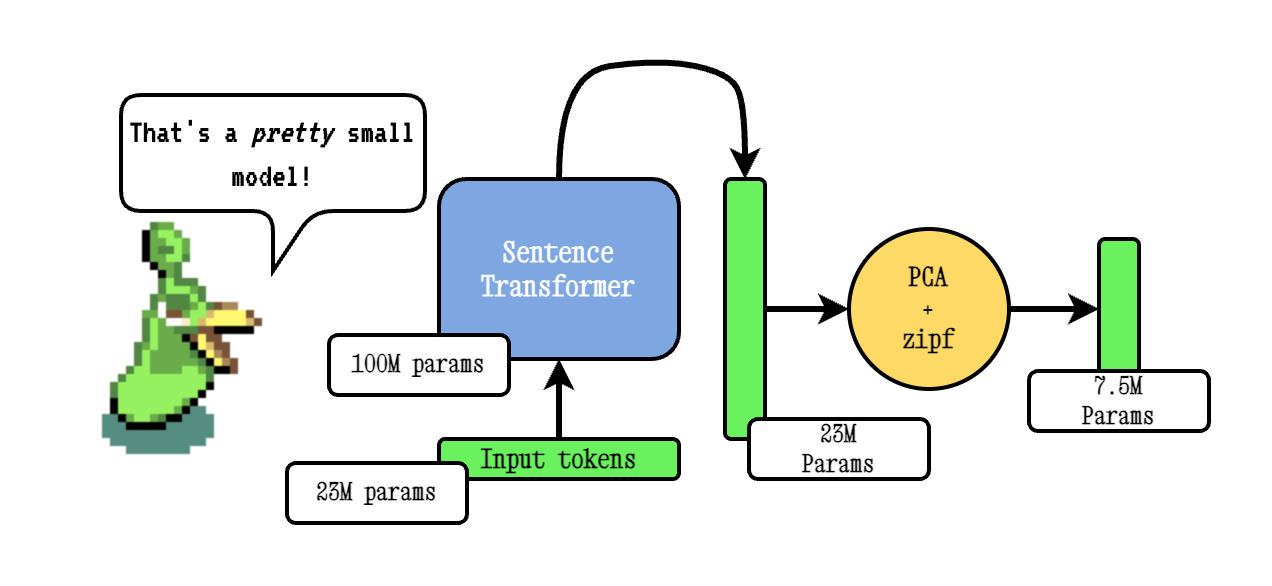
Model2VEC - это метод превращения любого трансформатора предложений в действительно небольшую статическую модель, уменьшая размер модели в 15 раз и сделает модели в 500X быстрее, с небольшим падением производительности. Наша лучшая модель - самая эффективная модель статического встраивания в мире. Посмотрите наши результаты здесь или погрузитесь, чтобы увидеть, как это работает.
Установите пакет с:
pip install model2vec Это установит базовый пакет вывода, который зависит только от numpy и нескольких других незначительных зависимостей. Если вы хотите переоборудовать свои собственные модели, вы можете установить дополнения дистилляции с:
pip install model2vec[distill]Самый простой способ начать работу с Model2VEC - это загрузить одну из наших флагманских моделей из центра Huggingface. Эти модели предварительно обучены и готовы к использованию. Следующий фрагмент кода показывает, как загрузить модель и встроить встраивание:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])И это все. Вы можете использовать модель для классификации текстов, для кластера или для создания тряпичной системы.
Вместо того, чтобы использовать одну из наших моделей, вы также можете изготовить свою собственную модель модели2VEC из модели трансформатора предложений. Следующий фрагмент кода показывает, как переоборудовать модель:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Дистилляция действительно быстрая и занимает всего 30 секунд на процессоре. Лучше всего, дистилляция не требует учебных данных.
Для расширенного использования, такого как использование Model2VEC в библиотеке Transformers, пожалуйста, обратитесь к разделам использования.
numpy .from_pretrained и push_to_hub . Наши собственные модели можно найти здесь. Не стесняйтесь делиться своим собственным. Model2VEC создает небольшую, быструю и мощную модель, которая превосходит другие статические модели встраивания с большим отрывом на всех задачах, которые мы могли бы найти, в то же время будучи гораздо быстрее создавать, чем традиционные статические модели встраивания, такие как перчатка. Как и BPEMB, он может создавать встроенные подножки, но с гораздо лучшей производительностью. Дистилляция не нуждается в никаких данных, просто словаре и модели.
Базовая техника Model2VEC работает, передавая словарный запас через модель трансформатора предложений, затем снижая размерность полученных встроенных встроений с использованием PCA, и, наконец, взвешивая встраивания с использованием взвешивания ZIPF. Во время вывода мы просто принимаем среднее значение всех встроенных токенов, встречающихся в предложении.
Наши модели зелья предварительно обучены с использованием Tokenlearn, методики для моделей дистилляции Model2VEC Model2VEC. Эти модели создаются со следующими шагами:
smooth inverse frequency (SIF) используя следующую формулу: w = 1e-3 / (1e-3 + proba) Полем Здесь, proba , вероятность токена в корпусе, которое мы использовали для обучения.Для гораздо более обширного глубокого, пожалуйста, обратитесь к нашим сообщению в блоге Model2VEC и на нашем блоге Tokenlearn.
Вывод работает следующим образом. В примере показан одна из наших собственных моделей, но вы также можете просто загрузить локальную или другую из концентратора.
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Следующий фрагмент кода показывает, как использовать модель модели2VEC в библиотеке трансформаторов предложений. Это полезно, если вы хотите использовать модель в трубопроводе Transformers.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Следующий код может быть использован для изготовления модели из трансформатора предложения. Как упоминалось выше, это приводит к действительно маленькой модели, которая может быть менее эффективной.
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Если у вас уже есть загруженная модель или вам нужно загрузить модель каким -либо особым образом, мы также предлагаем интерфейс для дистилляции моделей в памяти.
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )Следующий фрагмент кода показывает, как переоборудовать модель, используя библиотеку трансформаторов предложений. Это полезно, если вы хотите использовать модель в трубопроводе Transformers.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Если вы передаете словарный запас, вы получите набор статических встраиваний слов, вместе с пользовательским токенизатором для именно этого словаря. Это сравнимо с тем, как вы бы использовали перчатки или традиционные Word2VEC, но на самом деле не требует корпуса или данных.
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) По умолчанию это будет изготовить модель с токенизатором подвода, объединив слова моделей (подвод) с новым словарным запасом. Если вы хотите вместо этого получить токенизатор на уровне слов (только с пройденным словарем), параметр use_subword может быть установлен на False , например:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) Важное примечание: мы предполагаем, что пройденная словаря отсортирован по частоте ранга. т.е. нам не волнует фактические частоты слов, но предполагаем, что наиболее частым словом является первым, и наименее частым словом является последним. Если вы не уверены, является ли это случаем, установите apply_zipf на False . Это отключает вес, но также будет немного хуже.
Наши модели могут быть оценены с помощью нашего пакета оценки. Установите оценку пакета на:
pip install git+https://github.com/MinishLab/evaluation.git@mainСледующий фрагмент кода показывает, как оценить модель модели2VEC:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) Model2VEC может использоваться непосредственно в трансформаторах предложений с использованием модуля StaticEmbedding .
Следующий фрагмент кода показывает, как загрузить модель модели2VEC в модель трансформатора предложений:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Следующий фрагмент кода показывает, как переоборудовать модель непосредственно в модель трансформатора предложений:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Для получения дополнительной документации, пожалуйста, обратитесь к документации «Трансформеры».
Model2VEC может использоваться в txtai для текстовых внедрений, поиска с ближайшим соседом и любых других функций, которые предлагает Txtai. Следующий фрагмент кода показывает, как использовать Model2VEC в TXTAI:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2VEC - это модель по умолчанию для семантического кункинга в Чонки. Чтобы использовать Model2VEC для семантического кункинга в Чонки, просто установите Chonkie с pip install chonkie[semantic] и использовать одну из моделей potion в классе SemanticChunker . Следующий фрагмент кода показывает, как использовать Model2VEC в Chonkie:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )Чтобы использовать модель модели2VEC в Transformers.js, в качестве отправной точки можно использовать следующий фрагмент кода:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version Обратите внимание, что это требует, чтобы у модели2VEC был файл model.onnx . Чтобы сгенерировать их для модели, у которой их еще нет, можно использовать следующий фрагмент кода:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " Мы предоставляем ряд моделей, которые можно использовать из коробки. Эти модели доступны на концентраторе Huggingface и могут быть загружены с помощью метода from_pretrained . Модели перечислены ниже.
| Модель | Язык | Слока | Предложение трансформатор | Тип токенизатора | Параметры | Tokenlearn |
|---|---|---|---|---|---|---|
| зелье-базой-8м | Английский | Выход | BGE-BASE-EN-V1.5 | Подвеска | 7,5 м | ✅ |
| зелье-базой-4м | Английский | Выход | BGE-BASE-EN-V1.5 | Подвеска | 3,7 м | ✅ |
| зелье-базой-2M | Английский | Выход | BGE-BASE-EN-V1.5 | Подвеска | 1,8 м | ✅ |
| M2v_multilingual_output | Многоязычный | Выход | Лабсе | Подвеска | 471 м |
Мы провели обширные эксперименты для оценки производительности моделей Model2VEC. Результаты задокументированы в папке результатов. Результаты представлены в следующих разделах:
Грань
Если вы используете Model2VEC в своем исследовании, пожалуйста, укажите следующее:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

