model2vec
v0.3.3

Model2vec เป็นเทคนิคในการเปลี่ยนหม้อแปลงประโยคใด ๆ ให้กลายเป็นโมเดลคงที่ขนาดเล็กจริงๆลดขนาดรุ่นลง 15x และทำให้โมเดลเร็วขึ้นถึง 500 เท่าโดยมีประสิทธิภาพลดลงเล็กน้อย โมเดลที่ดีที่สุดของเราคือรูปแบบการฝังแบบคงที่มากที่สุดในโลก ดูผลลัพธ์ของเราที่นี่หรือดำน้ำเพื่อดูว่ามันทำงานอย่างไร
ติดตั้งแพ็คเกจด้วย:
pip install model2vec สิ่งนี้จะติดตั้งแพ็คเกจการอนุมานฐานซึ่งขึ้นอยู่กับ numpy และการพึ่งพาเล็กน้อยอื่น ๆ หากคุณต้องการกลั่นโมเดลของคุณเองคุณสามารถติดตั้งอุปกรณ์เสริมการกลั่นด้วย:
pip install model2vec[distill]วิธีที่ง่ายที่สุดในการเริ่มต้นด้วย Model2vec คือการโหลดหนึ่งในรุ่นเรือธงของเราจาก HuggingFace Hub โมเดลเหล่านี้ได้รับการฝึกอบรมล่วงหน้าและพร้อมใช้งาน ตัวอย่างโค้ดต่อไปนี้แสดงวิธีโหลดโมเดลและสร้าง Embeddings:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])และนั่นคือ คุณสามารถใช้โมเดลเพื่อจำแนกข้อความเป็นคลัสเตอร์หรือสร้างระบบ RAG
แทนที่จะใช้หนึ่งในโมเดลของเราคุณสามารถกลั่นโมเดล Model2Vec ของคุณเองจากโมเดลหม้อแปลงประโยค ตัวอย่างโค้ดต่อไปนี้แสดงวิธีการกลั่นโมเดล:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )การกลั่นเร็วมากและใช้เวลาเพียง 30 วินาทีใน CPU ที่ดีที่สุดคือการกลั่นไม่จำเป็นต้องมีข้อมูลการฝึกอบรม
สำหรับการใช้งานขั้นสูงเช่นการใช้ Model2VEC ในไลบรารี SENTENCE Transformers โปรดดูส่วนการใช้งาน
numpyfrom_pretrained และ push_to_hub ที่คุ้นเคย แบบจำลองของเราเองสามารถพบได้ที่นี่ อย่าลังเลที่จะแบ่งปันของคุณเอง Model2vec สร้างโมเดลขนาดเล็กเร็วและทรงพลังซึ่งมีประสิทธิภาพสูงกว่าโมเดลการฝังแบบคงที่อื่น ๆ โดยอัตรากำไรขั้นต้นขนาดใหญ่ในทุกงานที่เราสามารถหาได้ เช่นเดียวกับ BPEMB มันสามารถสร้างการฝังคำย่อยได้ แต่มีประสิทธิภาพที่ดีกว่ามาก การกลั่นไม่ต้องการข้อมูล ใด ๆ เพียงแค่คำศัพท์และแบบจำลอง
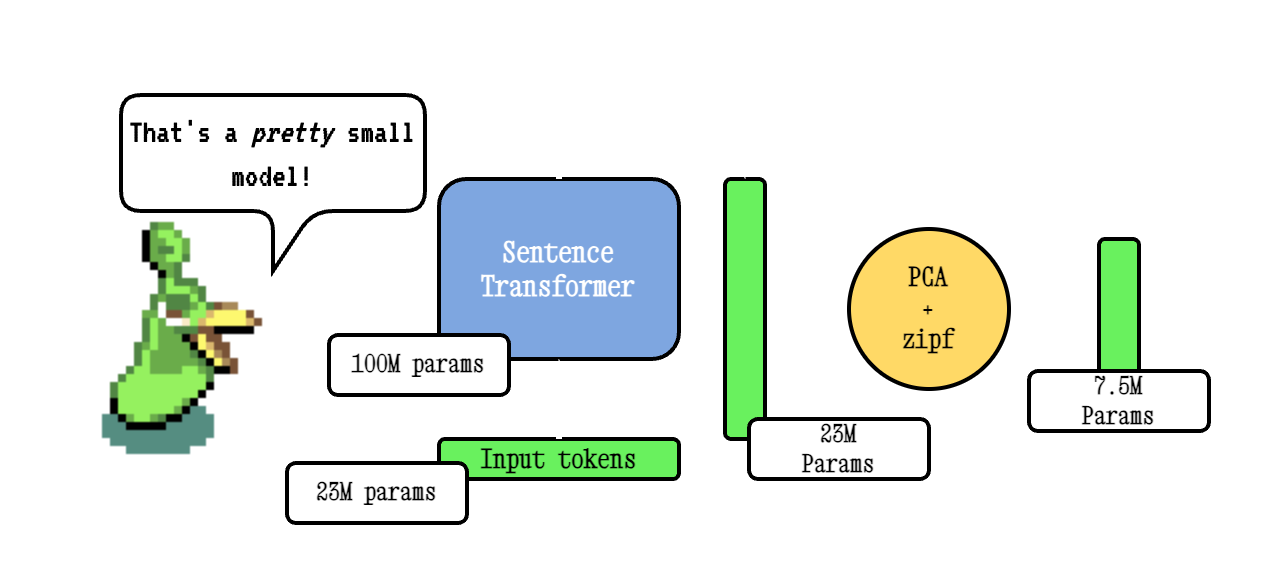
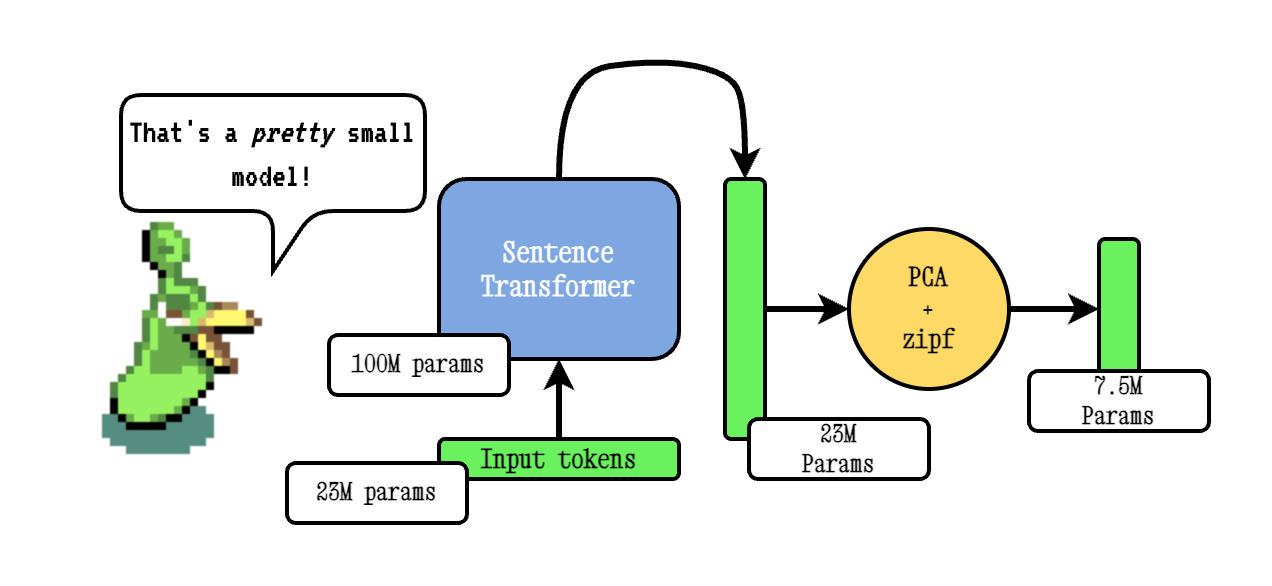
เทคนิคพื้นฐานของ Model2vec ทำงานโดยผ่านคำศัพท์ผ่านโมเดลหม้อแปลงประโยคจากนั้นลดขนาดของการฝังที่เกิดขึ้นโดยใช้ PCA และในที่สุดก็ถ่วงน้ำหนักการฝังโดยใช้การถ่วงน้ำหนัก ZIPF ในระหว่างการอนุมานเราเพียงแค่ใช้ค่าเฉลี่ยของการฝังโทเค็นทั้งหมดที่เกิดขึ้นในประโยค
โมเดลยาของเราได้รับการฝึกอบรมล่วงหน้าโดยใช้ Tokenlearn ซึ่งเป็นเทคนิคในการฝึกอบรมแบบจำลองการกลั่นแบบจำลอง Pre-Train2vec โมเดลเหล่านี้ถูกสร้างขึ้นด้วยขั้นตอนต่อไปนี้:
smooth inverse frequency (SIF) โดยใช้สูตรต่อไปนี้: w = 1e-3 / (1e-3 + proba) . ที่นี่ proba เป็นความน่าจะเป็นของโทเค็นในคลังข้อมูลที่เราใช้สำหรับการฝึกอบรมสำหรับ DeepDive ที่กว้างขวางยิ่งขึ้นโปรดดูโพสต์บล็อก Model2vec ของเราและโพสต์บล็อก Tokenlearn ของเรา
การอนุมานทำงานดังนี้ ตัวอย่างแสดงหนึ่งในโมเดลของเราเอง แต่คุณสามารถโหลดเครื่องใหม่หรืออีกรุ่นหนึ่งจากฮับได้
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])ตัวอย่างโค้ดต่อไปนี้แสดงวิธีใช้โมเดล Model2vec ในไลบรารี Transformers ประโยค สิ่งนี้มีประโยชน์หากคุณต้องการใช้โมเดลในไปป์ไลน์ของประโยค Transformers
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])รหัสต่อไปนี้สามารถใช้เพื่อกลั่นโมเดลจากหม้อแปลงประโยค ดังที่ได้กล่าวไว้ข้างต้นสิ่งนี้นำไปสู่รูปแบบเล็ก ๆ ที่อาจมีประสิทธิภาพน้อยกว่า
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )หากคุณมีรุ่นที่โหลดอยู่แล้วหรือจำเป็นต้องโหลดโมเดลด้วยวิธีพิเศษบางอย่างเรายังเสนออินเทอร์เฟซเพื่อกลั่นโมเดลในหน่วยความจำ
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )ตัวอย่างโค้ดต่อไปนี้แสดงวิธีการกลั่นโมเดลโดยใช้ไลบรารี Sentence Transformers สิ่งนี้มีประโยชน์หากคุณต้องการใช้โมเดลในไปป์ไลน์ของประโยค Transformers
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])หากคุณผ่านคำศัพท์คุณจะได้รับชุดคำศัพท์แบบคงที่พร้อมกับโทเค็นที่กำหนดเองสำหรับคำศัพท์นั้น สิ่งนี้เปรียบได้กับวิธีที่คุณจะใช้ถุงมือหรือ Word2vec แบบดั้งเดิม แต่ไม่จำเป็นต้องใช้คลังข้อมูลหรือข้อมูล
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) โดยค่าเริ่มต้นสิ่งนี้จะกลั่นโมเดลด้วย tokenizer subword โดยรวมคำศัพท์ (คำย่อย) กับคำศัพท์ใหม่ หากคุณต้องการรับ tokenizer ระดับคำแทน (ด้วยคำศัพท์ที่ผ่าน) พารามิเตอร์ use_subword สามารถตั้งค่าเป็น False ได้เช่น:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) หมายเหตุสำคัญ: เราถือว่าคำศัพท์ที่ผ่านถูกจัดเรียงในความถี่อันดับ เช่นเราไม่สนใจเกี่ยวกับความถี่คำที่แท้จริง แต่สมมติว่าคำที่พบบ่อยที่สุดคือคำแรกและคำที่พบบ่อยที่สุดคือคำที่น้อยที่สุด หากคุณไม่แน่ใจว่าเป็นกรณีนี้ให้ตั้งค่า apply_zipf เป็น False สิ่งนี้จะปิดการใช้งานการถ่วงน้ำหนัก แต่จะทำให้ประสิทธิภาพแย่ลงเล็กน้อย
แบบจำลองของเราสามารถประเมินได้โดยใช้แพ็คเกจการประเมินผลของเรา ติดตั้งแพ็คเกจประเมินผลด้วย:
pip install git+https://github.com/MinishLab/evaluation.git@mainตัวอย่างโค้ดต่อไปนี้แสดงวิธีประเมินโมเดล Model2VEC:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) Model2VEC สามารถใช้โดยตรงในหม้อแปลงประโยคโดยใช้โมดูล StaticEmbedding
ตัวอย่างโค้ดต่อไปนี้แสดงวิธีโหลดโมเดล Model2vec ลงในโมเดลหม้อแปลงประโยคประโยค:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])ตัวอย่างโค้ดต่อไปนี้แสดงวิธีการกลั่นโมเดลโดยตรงในโมเดลหม้อแปลงประโยคประโยค:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])สำหรับเอกสารเพิ่มเติมโปรดดูเอกสารประกอบประโยค Transformers
Model2VEC สามารถใช้ใน txtai สำหรับการฝังข้อความการค้นหาเพื่อนบ้านที่ใกล้ที่สุดและฟังก์ชันอื่น ๆ ที่ Txtai เสนอ ตัวอย่างโค้ดต่อไปนี้แสดงวิธีใช้ Model2VEC ใน txtai:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2vec เป็นรุ่นเริ่มต้นสำหรับการถ่ายทำแบบ semantic ใน Chonkie หากต้องการใช้ Model2VEC สำหรับความหมายใน Chonkie เพียงติดตั้ง Chonkie ด้วย pip install chonkie[semantic] และใช้หนึ่งใน potion Models ในคลาส SemanticChunker ตัวอย่างโค้ดต่อไปนี้แสดงวิธีใช้ Model2VEC ใน Chonkie:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )ในการใช้โมเดล Model2VEC ใน Transformers.js สามารถใช้ตัวอย่างโค้ดต่อไปนี้เป็นจุดเริ่มต้น:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version โปรดทราบว่าสิ่งนี้ต้องการให้ Model2vec มีไฟล์ model.onnx และไฟล์ tokenizers ที่จำเป็นหลายไฟล์ ในการสร้างสิ่งเหล่านี้สำหรับโมเดลที่ยังไม่มีมันสามารถใช้ตัวอย่างโค้ดต่อไปนี้ได้:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " เรามีหลายรุ่นที่สามารถใช้นอกกรอบได้ รุ่นเหล่านี้มีอยู่บนฮับ HuggingFace และสามารถโหลดได้โดยใช้วิธี from_pretrained โมเดลมีการระบุไว้ด้านล่าง
| แบบอย่าง | ภาษา | คำศัพท์ | หม้อแปลงประโยค | ประเภทโทเคนิเซอร์ | พารามิเตอร์ | Tokenlearn |
|---|---|---|---|---|---|---|
| Potion-base-8m | ภาษาอังกฤษ | เอาท์พุท | BGE-BASE-EN-V1.5 | คำสั่งย่อย | 7.5m | |
| Potion-base-4m | ภาษาอังกฤษ | เอาท์พุท | BGE-BASE-EN-V1.5 | คำสั่งย่อย | 3.7m | |
| ยา | ภาษาอังกฤษ | เอาท์พุท | BGE-BASE-EN-V1.5 | คำสั่งย่อย | 1.8m | |
| m2v_multilingual_output | พูดได้หลายภาษา | เอาท์พุท | ห้องแล็บ | คำสั่งย่อย | 471m |
เราได้ทำการทดลองอย่างกว้างขวางเพื่อประเมินประสิทธิภาพของโมเดล Model2VEC ผลลัพธ์จะถูกบันทึกไว้ในโฟลเดอร์ผลลัพธ์ ผลลัพธ์จะถูกนำเสนอในส่วนต่อไปนี้:
มิกซ์
หากคุณใช้ Model2VEC ในการวิจัยของคุณโปรดอ้างอิงสิ่งต่อไปนี้:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

