model2vec
v0.3.3

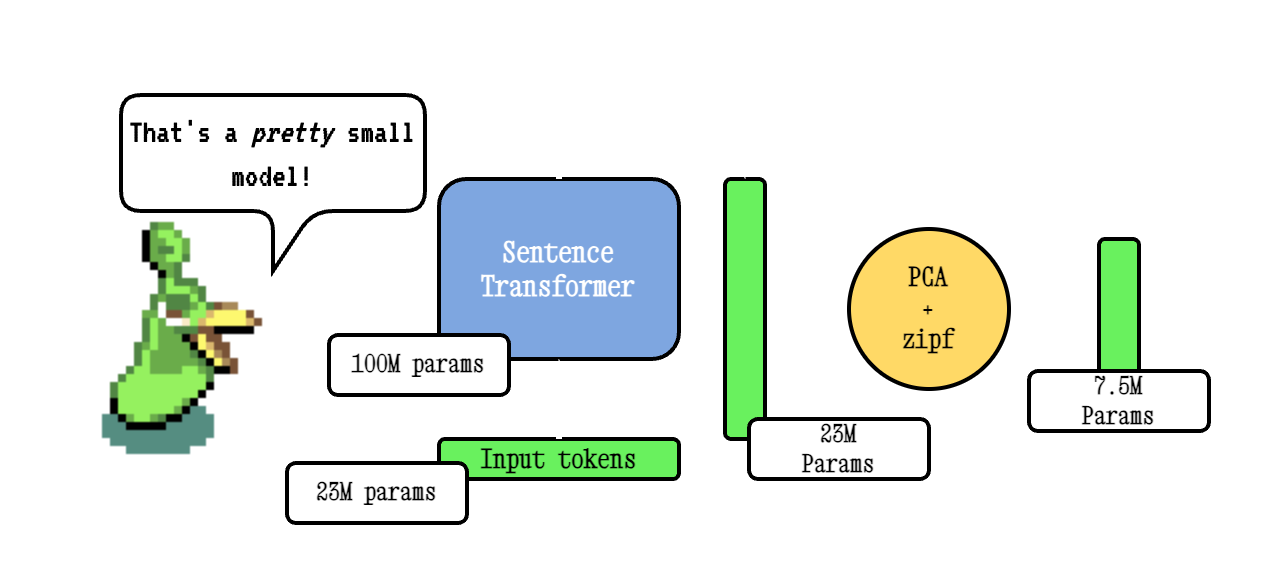
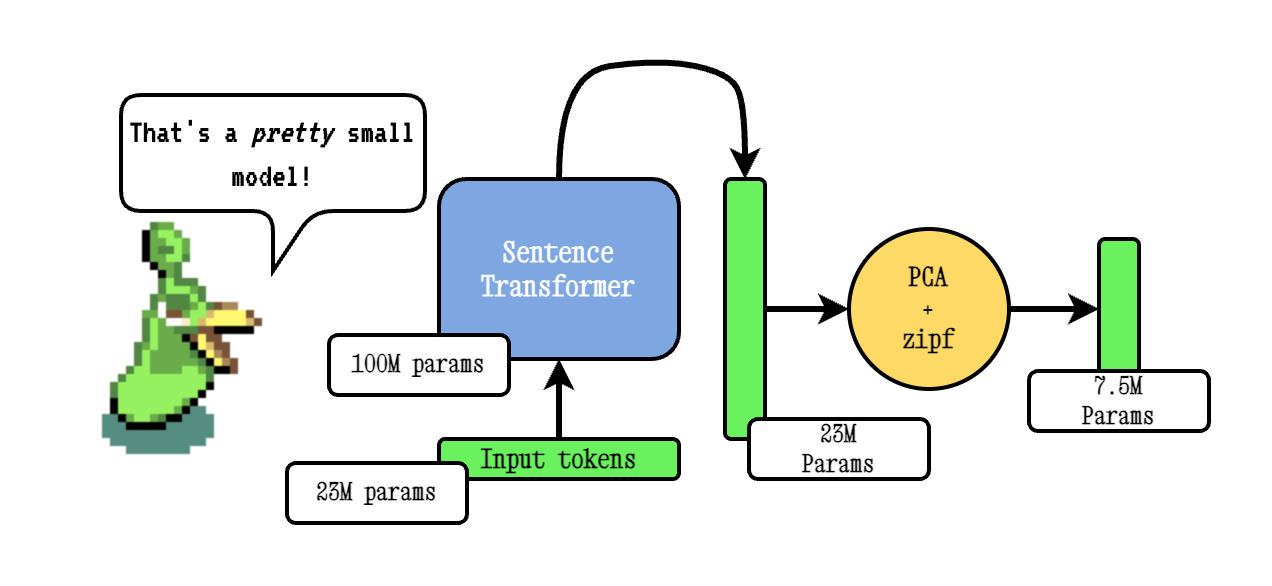
Model2Vec adalah teknik untuk mengubah transformator kalimat menjadi model statis yang sangat kecil, mengurangi ukuran model sebesar 15x dan membuat model hingga 500x lebih cepat, dengan penurunan kecil dalam kinerja. Model terbaik kami adalah model embedding statis paling berkinerja di dunia. Lihat hasil kami di sini, atau menyelam untuk melihat cara kerjanya.
Instal paket dengan:
pip install model2vec Ini akan menginstal paket inferensi dasar, yang hanya tergantung pada numpy dan beberapa dependensi minor lainnya. Jika Anda ingin menyaring model Anda sendiri, Anda dapat menginstal ekstra distilasi dengan:
pip install model2vec[distill]Cara termudah untuk memulai dengan Model2VEC adalah dengan memuat salah satu model andalan kami dari hub Huggingface. Model-model ini sudah terlatih dan siap digunakan. Cuplikan kode berikut menunjukkan cara memuat model dan membuat embeddings:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Dan itu saja. Anda dapat menggunakan model untuk mengklasifikasikan teks, untuk mengelompok, atau membangun sistem RAG.
Alih -alih menggunakan salah satu model kami, Anda juga dapat menyaring model Model2VEC Anda sendiri dari model transformator kalimat. Cuplikan kode berikut menunjukkan cara menyaring model:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Distilasi sangat cepat dan hanya membutuhkan waktu 30 detik pada CPU. Yang terbaik dari semuanya, distilasi tidak memerlukan data pelatihan.
Untuk penggunaan lanjutan, seperti menggunakan Model2VEC di perpustakaan Transformers Kalimat, silakan merujuk ke bagian penggunaan.
numpy .from_pretrained dan push_to_hub . Model kami sendiri dapat ditemukan di sini. Jangan ragu untuk berbagi sendiri. Model2Vec menciptakan model kecil, cepat, dan kuat yang mengungguli model embedding statis lainnya dengan margin besar pada semua tugas yang bisa kita temukan, sementara jauh lebih cepat untuk dibuat daripada model embedding statis tradisional seperti sarung tangan. Seperti Bpemb, dapat membuat embeddings subword, tetapi dengan kinerja yang jauh lebih baik. Distilasi tidak memerlukan data apa pun , hanya kosakata dan model.
Teknik Model2VEC BASE bekerja dengan melewati kosakata melalui model transformator kalimat, kemudian mengurangi dimensionalitas embeddings yang dihasilkan menggunakan PCA, dan akhirnya menimbang embeddings menggunakan bobot ZIPF. Selama kesimpulan, kami hanya mengambil rata -rata dari semua token embedding yang terjadi dalam sebuah kalimat.
Model ramuan kami dilatih sebelumnya menggunakan TokenLearn, teknik untuk model distilasi model pra-kereta2VEC. Model -model ini dibuat dengan langkah -langkah berikut:
smooth inverse frequency (SIF) menggunakan rumus berikut: w = 1e-3 / (1e-3 + proba) . Di sini, proba adalah probabilitas token dalam korpus yang kami gunakan untuk pelatihan.Untuk DeepDive yang jauh lebih luas, silakan merujuk ke posting blog Model2Vec kami dan posting blog TokenLearn kami.
Inferensi berfungsi sebagai berikut. Contoh ini menunjukkan salah satu model kami sendiri, tetapi Anda juga bisa memuat yang lokal, atau yang lain dari hub.
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Cuplikan kode berikut menunjukkan cara menggunakan model Model2VEC di pustaka Transformers Kalimat. Ini berguna jika Anda ingin menggunakan model dalam pipa Transformers Kalimat.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Kode berikut dapat digunakan untuk menyaring model dari transformator kalimat. Seperti disebutkan di atas, ini mengarah pada model yang sangat kecil yang mungkin kurang berkinerja.
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Jika Anda sudah memiliki model yang dimuat, atau perlu memuat model dengan cara khusus, kami juga menawarkan antarmuka untuk menyaring model dalam memori.
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )Cuplikan kode berikut menunjukkan cara menyaring model menggunakan perpustakaan Transformers Kalimat. Ini berguna jika Anda ingin menggunakan model dalam pipa Transformers Kalimat.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Jika Anda melewati kosakata, Anda mendapatkan satu set embeddings kata statis, bersama dengan tokenizer khusus untuk kosakata itu. Ini sebanding dengan cara Anda menggunakan sarung tangan atau word2vec tradisional, tetapi sebenarnya tidak memerlukan corpus atau data.
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) Secara default, ini akan menyaring model dengan tokenizer subword, menggabungkan vocab model (subword) dengan kosakata baru. Jika Anda ingin mendapatkan tokenizer tingkat kata sebagai gantinya (dengan hanya kosa kata yang dilewatkan), parameter use_subword dapat diatur ke False , misalnya:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) Catatan Penting: Kami menganggap kosakata yang diteruskan diurutkan dalam frekuensi peringkat. yaitu, kami tidak peduli dengan frekuensi kata yang sebenarnya, tetapi asumsikan bahwa kata yang paling sering adalah yang pertama, dan kata yang paling tidak sering adalah yang terakhir. Jika Anda tidak yakin apakah ini kasusnya, atur apply_zipf ke False . Ini menonaktifkan bobot, tetapi juga akan membuat kinerja sedikit lebih buruk.
Model kami dapat dievaluasi menggunakan paket evaluasi kami. Instal Paket Evaluasi dengan:
pip install git+https://github.com/MinishLab/evaluation.git@mainCuplikan kode berikut menunjukkan cara mengevaluasi model Model2Vec:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) Model2VEC dapat digunakan secara langsung dalam transformator kalimat menggunakan modul StaticEmbedding .
Cuplikan kode berikut menunjukkan cara memuat model Model2VEC ke dalam model transformator kalimat:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Cuplikan kode berikut menunjukkan cara menyaring model langsung ke model transformator kalimat:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Untuk dokumentasi lebih lanjut, silakan merujuk ke dokumentasi Transformers Kalimat.
Model2Vec dapat digunakan di txtai untuk embeddings teks, pencarian tetangga terdekat, dan salah satu fungsi lain yang ditawarkan TXTAI. Cuplikan kode berikut menunjukkan cara menggunakan model2vec di txtai:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2Vec adalah model default untuk semantik chunking di Chonkie. Untuk menggunakan Model2Vec untuk chunking semantik di Chonkie, cukup instal chonkie dengan pip install chonkie[semantic] dan gunakan salah satu model potion di kelas SemanticChunker . Cuplikan kode berikut menunjukkan cara menggunakan model2vec di Chonkie:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )Untuk menggunakan model Model2VEC di Transformers.js, cuplikan kode berikut dapat digunakan sebagai titik awal:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version Perhatikan bahwa ini mensyaratkan bahwa Model2Vec memiliki file model.onnx dan beberapa tokenizer yang diperlukan. Untuk menghasilkan ini untuk model yang belum memilikinya, cuplikan kode berikut dapat digunakan:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " Kami menyediakan sejumlah model yang dapat digunakan di luar kotak. Model -model ini tersedia di hub Huggingface dan dapat dimuat menggunakan metode from_pretrained . Model tercantum di bawah ini.
| Model | Bahasa | Vocab | Transformator kalimat | Jenis tokenizer | Params | Tokenlearn |
|---|---|---|---|---|---|---|
| Ramuan-basis-8m | Bahasa inggris | Keluaran | BGE-BASE-EN-V1.5 | Subword | 7.5m | ✅ |
| Ramuan-basis-4m | Bahasa inggris | Keluaran | BGE-BASE-EN-V1.5 | Subword | 3.7m | ✅ |
| Ramuan-Base-2m | Bahasa inggris | Keluaran | BGE-BASE-EN-V1.5 | Subword | 1.8m | ✅ |
| M2v_multilingual_output | Multibahasa | Keluaran | Labse | Subword | 471m |
Kami telah melakukan eksperimen ekstensif untuk mengevaluasi kinerja model Model2VEC. Hasilnya didokumentasikan dalam folder hasil. Hasilnya disajikan pada bagian berikut:
Mit
Jika Anda menggunakan Model2Vec dalam penelitian Anda, silakan kutip yang berikut:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

