model2vec
v0.3.3

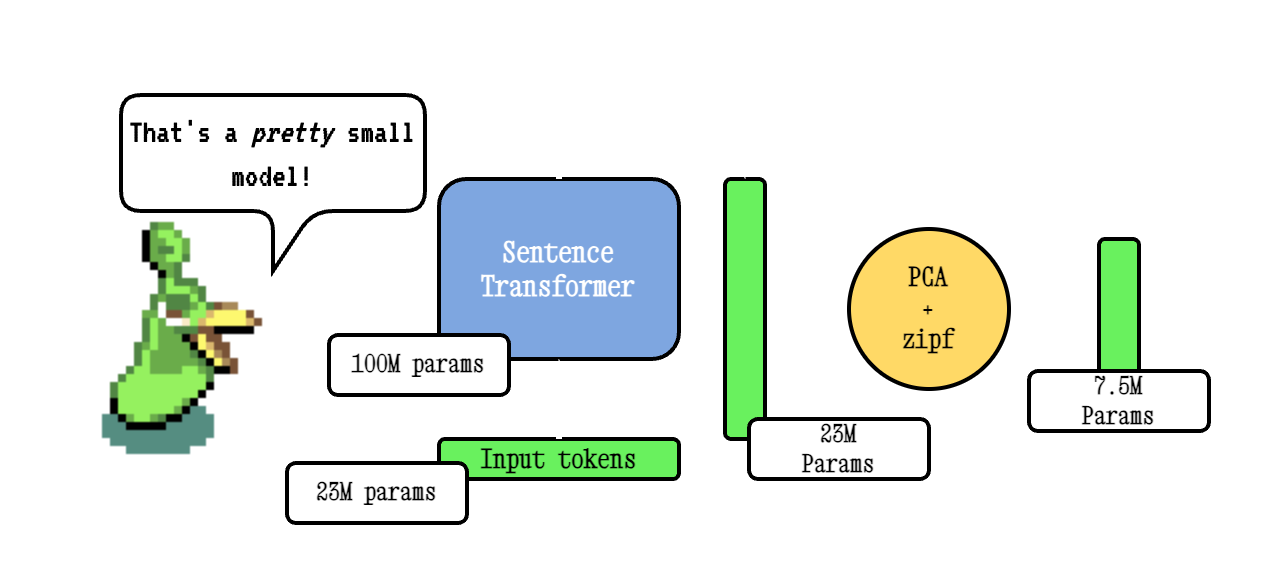
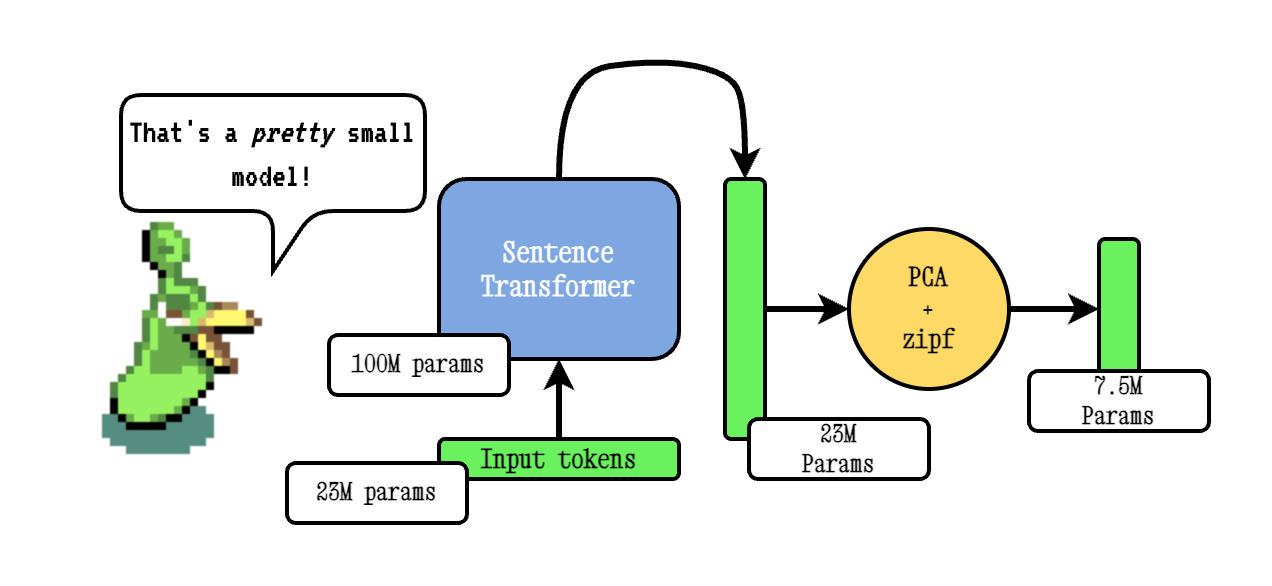
Model2Vec es una técnica para convertir cualquier transformador de oración en un modelo estático realmente pequeño, reduciendo el tamaño del modelo en 15X y haciendo que los modelos sean hasta 500x más rápido, con una pequeña caída en el rendimiento. Nuestro mejor modelo es el modelo de incrustación estática más desempeñada del mundo. Vea nuestros resultados aquí, o bucee para ver cómo funciona.
Instale el paquete con:
pip install model2vec Esto instalará el paquete de inferencia base, que solo depende de numpy y algunas otras dependencias menores. Si desea destilar sus propios modelos, puede instalar los extras de destilación con:
pip install model2vec[distill]La forma más fácil de comenzar con Model2Vec es cargar uno de nuestros modelos insignia del Hub Huggingface. Estos modelos son pretrados y están listos para usar. El siguiente fragmento de código muestra cómo cargar un modelo y hacer incrustaciones:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Y eso es todo. Puede usar el modelo para clasificar textos, agruparse o construir un sistema RAG.
En lugar de usar uno de nuestros modelos, también puede destilar su propio modelo Model2Vec de un modelo de transformador de oraciones. El siguiente fragmento de código muestra cómo destilar un modelo:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )La destilación es realmente rápida y solo toma 30 segundos en la CPU. Lo mejor de todo es que la destilación no requiere datos de entrenamiento.
Para el uso avanzado, como el uso de Model2Vec en la biblioteca de transformadores de oraciones, consulte las secciones de uso.
numpy .from_pretrained y push_to_hub . Nuestros propios modelos se pueden encontrar aquí. Siéntase libre de compartir el tuyo. Model2Vec crea un modelo pequeño, rápido y potente que supera a otros modelos de incrustación estática por un gran margen en todas las tareas que podríamos encontrar, mientras que es mucho más rápido crear que los modelos de incrustación estática tradicionales como el guante. Al igual que BPIMB, puede crear incrustaciones de subvenciones, pero con un rendimiento mucho mejor. La destilación no necesita ningún dato, solo un vocabulario y un modelo.
La técnica Base Model2VEC funciona pasando un vocabulario a través de un modelo de transformador de oraciones, luego reduciendo la dimensionalidad de los incrustaciones resultantes usando PCA, y finalmente ponderando los incrustaciones utilizando la ponderación ZIPF. Durante la inferencia, simplemente tomamos la media de todas las embedidas de token que ocurren en una oración.
Nuestros modelos de poción se entrenan previamente utilizando TokenLearn, una técnica para pre-entrenamiento de modelos de destilación modelo2VEC. Estos modelos se crean con los siguientes pasos:
smooth inverse frequency (SIF) utilizando la siguiente fórmula: w = 1e-3 / (1e-3 + proba) . Aquí, proba es la probabilidad del token en el corpus que utilizamos para el entrenamiento.Para un profundo mucho más extenso, consulte nuestra publicación de blog Model2Vec y nuestra publicación de blog TokenLearn.
La inferencia funciona de la siguiente manera. El ejemplo muestra uno de nuestros propios modelos, pero también puede cargar uno local u otro desde el centro.
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])El siguiente fragmento de código muestra cómo usar un modelo Model2Vec en la biblioteca de transformadores de oraciones. Esto es útil si desea usar el modelo en una tubería de transformadores de oración.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])El siguiente código se puede usar para destilar un modelo de un transformador de oración. Como se mencionó anteriormente, esto conduce a un modelo realmente pequeño que podría ser menos desempeñado.
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Si ya tiene un modelo cargado o necesita cargar un modelo de alguna manera especial, también ofrecemos una interfaz para destilar modelos en la memoria.
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )El siguiente fragmento de código muestra cómo destilar un modelo utilizando la biblioteca de transformadores de oraciones. Esto es útil si desea usar el modelo en una tubería de transformadores de oración.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Si pasa un vocabulario, obtienes un conjunto de incrustaciones de palabras estáticas, junto con un tokenizador personalizado para exactamente ese vocabulario. Esto es comparable a cómo usaría Glove o Word2Vec tradicional, pero en realidad no requiere un corpus o datos.
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) De manera predeterminada, esto destilará un modelo con un tokenizador de subvención, combinando el vocabulario de modelos (subfrencional) con el nuevo vocabulario. Si desea obtener un tokenizador de nivel de palabra (solo con el vocabulario aprobado), el parámetro use_subword se puede establecer en False , por ejemplo:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) Nota importante: Suponemos que el vocabulario aprobado se clasifica en frecuencia de rango. es decir, no nos importan las frecuencias de palabras reales, pero suponemos que la palabra más frecuente es la primera, y la última palabra frecuente es la última. Si no está seguro de si este es el caso, establezca apply_zipf en False . Esto desactiva la ponderación, pero también empeorará un poco el rendimiento.
Nuestros modelos se pueden evaluar utilizando nuestro paquete de evaluación. Instale el paquete de evaluación con:
pip install git+https://github.com/MinishLab/evaluation.git@mainEl siguiente fragmento de código muestra cómo evaluar un modelo Model2Vec:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) Model2Vec se puede usar directamente en transformadores de oraciones utilizando el módulo StaticEmbedding .
El siguiente fragmento de código muestra cómo cargar un modelo Model2Vec en un modelo de transformador de oración:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])El siguiente fragmento de código muestra cómo destilar un modelo directamente en un modelo de transformador de oración:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Para obtener más documentación, consulte la documentación de transformadores de oraciones.
Model2VEC se puede usar en TXTAI para incrustaciones de texto, búsqueda de vecinos más cercanos y cualquiera de las otras funcionalidades que ofrece Txtai. El siguiente fragmento de código muestra cómo usar Model2Vec en TXTAI:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2Vec es el modelo predeterminado para fragmentos semánticos en Chonkie. Para usar Model2VEC para fragmentos semánticos en Chonkie, simplemente instale Chonkie con pip install chonkie[semantic] y use uno de los modelos potion en la clase SemanticChunker . El siguiente fragmento de código muestra cómo usar Model2Vec en Chonkie:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )Para usar un modelo Model2Vec en Transformers.js, el siguiente fragmento de código se puede usar como punto de partida:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version Tenga en cuenta que esto requiere que el Model2Vec tenga un archivo model.onnx y varios archivos de tokenizers requeridos. Para generarlos para un modelo que aún no los tiene, se puede usar el siguiente fragmento de código:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " Proporcionamos una serie de modelos que se pueden usar fuera de la caja. Estos modelos están disponibles en el Hub de Huggingface y se pueden cargar utilizando el método from_pretrained . Los modelos se enumeran a continuación.
| Modelo | Idioma | Vocabulario | Transformador de oraciones | Tipo de tokenizador | Parámetros | Tokenlearn |
|---|---|---|---|---|---|---|
| Base de poción-8m | Inglés | Producción | BGE-BASE-EN-V1.5 | Subvención | 7.5m | ✅ |
| poción-base-4m | Inglés | Producción | BGE-BASE-EN-V1.5 | Subvención | 3.7m | ✅ |
| poción-base-2m | Inglés | Producción | BGE-BASE-EN-V1.5 | Subvención | 1.8m | ✅ |
| M2v_multilingual_output | Plurilingüe | Producción | Labero | Subvención | 471m |
Hemos realizado experimentos extensos para evaluar el rendimiento de los modelos Model2VEC. Los resultados se documentan en la carpeta de resultados. Los resultados se presentan en las siguientes secciones:
MIT
Si usa Model2Vec en su investigación, cite lo siguiente:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

