model2vec
v0.3.3

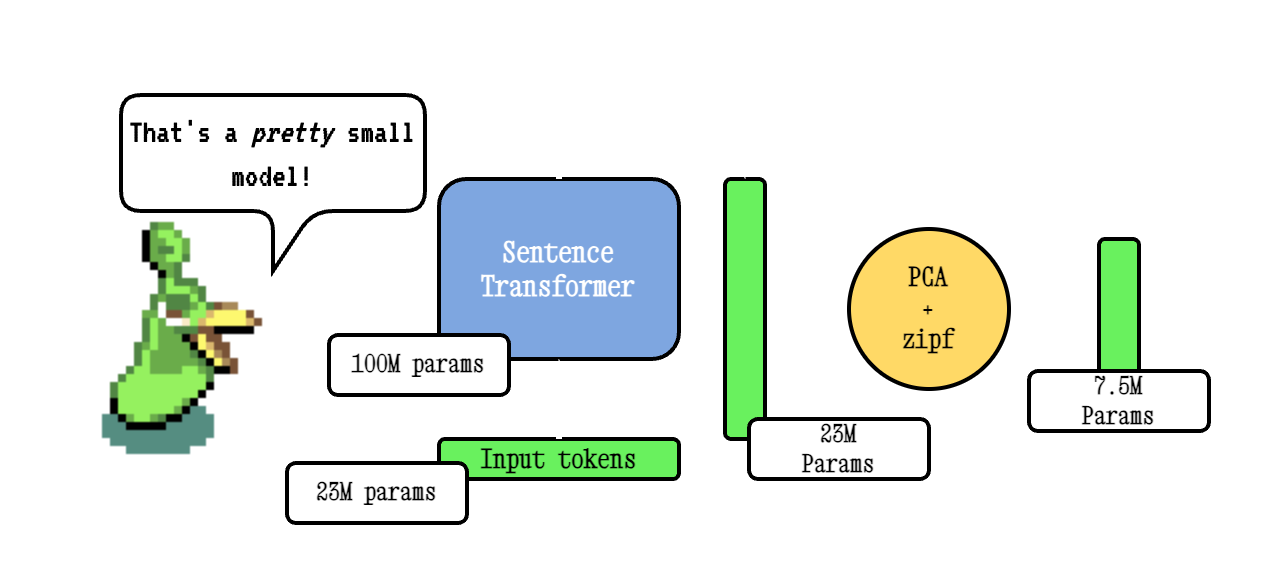
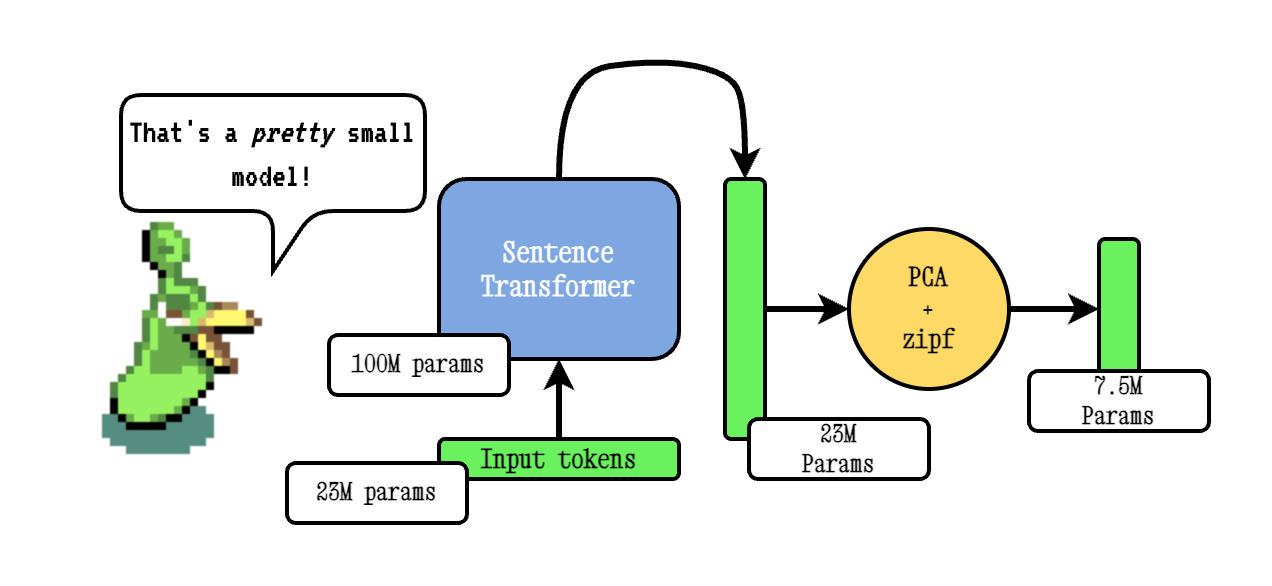
O Model2Vec é uma técnica para transformar qualquer transformador de frase em um modelo estático muito pequeno, reduzindo o tamanho do modelo em 15x e tornando os modelos até 500x mais rapidamente, com uma pequena queda no desempenho. Nosso melhor modelo é o modelo de incorporação estática mais com desempenho do mundo. Veja nossos resultados aqui, ou mergulhe para ver como funciona.
Instale o pacote com:
pip install model2vec Isso instalará o pacote de inferência base, que depende apenas do numpy e de algumas outras dependências menores. Se você deseja destilar seus próprios modelos, pode instalar os extras de destilação com:
pip install model2vec[distill]A maneira mais fácil de começar com o Model2vec é carregar um de nossos principais modelos no hub do Huggingface. Esses modelos são pré-treinados e prontos para uso. O snippet de código a seguir mostra como carregar um modelo e fazer incorporação:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])E é isso. Você pode usar o modelo para classificar textos, agrupar ou criar um sistema de pano.
Em vez de usar um de nossos modelos, você também pode destilar seu próprio modelo Model2Vec de um modelo de transformador de sentença. O snippet de código a seguir mostra como destilar um modelo:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )A destilação é muito rápida e leva apenas 30 segundos na CPU. O melhor de tudo é que a destilação não requer dados de treinamento.
Para uso avançado, como o uso do Model2Vec na Biblioteca de Transformers de sentenças, consulte as seções de uso.
numpy .from_pretrained e push_to_hub . Nossos próprios modelos podem ser encontrados aqui. Sinta -se à vontade para compartilhar o seu próprio. O Model2Vec cria um modelo pequeno, rápido e poderoso que supera outros modelos estáticos de incorporação por uma grande margem em todas as tarefas que pudemos encontrar, embora seja muito mais rápido para criar do que os modelos de incorporação estática tradicional, como luva. Como o BPEMB, ele pode criar incorporação de subbordas, mas com desempenho muito melhor. A destilação não precisa de dados, apenas um vocabulário e um modelo.
A técnica básica Model2VEC funciona passando um vocabulário através de um modelo de transformador de frases, reduzindo a dimensionalidade das incorporações resultantes usando o PCA e, finalmente, ponderando as incorporações usando a ponderação do ZIPF. Durante a inferência, simplesmente tomamos a média de todas as incorporações simbólicas que ocorrem em uma frase.
Nossos modelos de poção são pré-treinados usando o TokenLearn, uma técnica para pré-treinar modelos de destilação Model2Vec. Esses modelos são criados com as seguintes etapas:
smooth inverse frequency (SIF) usando a seguinte fórmula: w = 1e-3 / (1e-3 + proba) . Aqui, proba é a probabilidade do token no corpus que usamos para o treinamento.Para um DeepDive muito mais extenso, consulte a nossa postagem no blog Model2vec e nossa postagem no blog Tokenlearn.
A inferência funciona da seguinte maneira. O exemplo mostra um de nossos próprios modelos, mas você também pode carregar um local ou outro do hub.
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])O snippet de código a seguir mostra como usar um modelo Model2vec na biblioteca de Transformers de sentenças. Isso é útil se você deseja usar o modelo em um pipeline de transformadores de frases.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])O código a seguir pode ser usado para destilar um modelo de um transformador de frase. Como mencionado acima, isso leva a um modelo realmente pequeno que pode ser menos executado.
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Se você já possui um modelo carregado ou precisa carregar um modelo de alguma maneira especial, também oferecemos uma interface para destilar os modelos na memória.
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )O snippet de código a seguir mostra como destilar um modelo usando a biblioteca de Transformers de sentenças. Isso é útil se você deseja usar o modelo em um pipeline de transformadores de frases.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Se você passar por um vocabulário, obterá um conjunto de incorporações de palavras estáticas, juntamente com um tokenizador personalizado para exatamente esse vocabulário. Isso é comparável a como você usaria a luva ou o Word2Vec tradicional, mas na verdade não requer um corpus ou dados.
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) Por padrão, isso destilará um modelo com um tokenizador de subgletas, combinando o vocabulário de modelos (subgletas) com o novo vocabulário. Se você deseja obter um tokenizador no nível da palavra (apenas com o vocabulário aprovado), o parâmetro use_subword pode ser definido como False , por exemplo:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) NOTA IMPORTANTE: Assumimos que o vocabulário aprovado é classificado na frequência de classificação. Por exemplo, não nos importamos com as frequências reais das palavras, mas assumimos que a palavra mais frequente é a primeira e a palavra menos frequente é a última. Se você não tiver certeza se esse é o caso, defina apply_zipf como False . Isso desativa a ponderação, mas também piorará o desempenho.
Nossos modelos podem ser avaliados usando nosso pacote de avaliação. Instale o pacote de avaliação com:
pip install git+https://github.com/MinishLab/evaluation.git@mainO snippet de código a seguir mostra como avaliar um modelo Model2vec:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) O Model2vec pode ser usado diretamente nos transformadores de frases usando o módulo StaticEmbedding .
O snippet de código a seguir mostra como carregar um modelo Model2vec em um modelo de transformador de frases:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])O snippet de código a seguir mostra como destilar um modelo diretamente em um modelo de transformador de frases:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Para mais documentação, consulte a documentação dos transformadores da frase.
O Model2vec pode ser usado no txtai para incorporação de texto, pesquisa mais próxima-vizinhos e qualquer uma das outras funcionalidades que o TXTAI oferece. O snippet de código a seguir mostra como usar o Model2vec em txtai:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2vec é o modelo padrão para Chunking semântico em Chonkie. Para usar o Model2vec para Chunking semântico em Chonkie, basta instalar o Chonkie com pip install chonkie[semantic] e usar um dos modelos potion na classe SemanticChunker . O snippet de código a seguir mostra como usar o Model2vec em Chonkie:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )Para usar um modelo Model2vec no Transformers.js, o seguinte snippet de código pode ser usado como ponto de partida:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version Observe que isso exige que o modelo2VEC tenha um arquivo model.onnx e vários tokenizers necessários. Para gerá -los para um modelo que ainda não os possui, o seguinte snippet de código pode ser usado:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " Fornecemos vários modelos que podem ser usados imediatamente. Esses modelos estão disponíveis no hub do Huggingface e podem ser carregados usando o método from_pretrained . Os modelos estão listados abaixo.
| Modelo | Linguagem | Vocab | Transformador de frases | Tipo de tokenizer | Params | Tokenlearn |
|---|---|---|---|---|---|---|
| Poção-base-8m | Inglês | Saída | BGE-BASE-EN-V1.5 | SubbORT | 7,5m | ✅ |
| Poção-base-4m | Inglês | Saída | BGE-BASE-EN-V1.5 | SubbORT | 3,7m | ✅ |
| Poção-base-2M | Inglês | Saída | BGE-BASE-EN-V1.5 | Subbater | 1,8m | ✅ |
| M2v_multilingual_output | Multilíngue | Saída | Labse | SubbORT | 471m |
Realizamos extensos experimentos para avaliar o desempenho dos modelos Model2Vec. Os resultados estão documentados na pasta de resultados. Os resultados são apresentados nas seções a seguir:
Mit
Se você usar o Model2Vec em sua pesquisa, cite o seguinte:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

