model2vec
v0.3.3

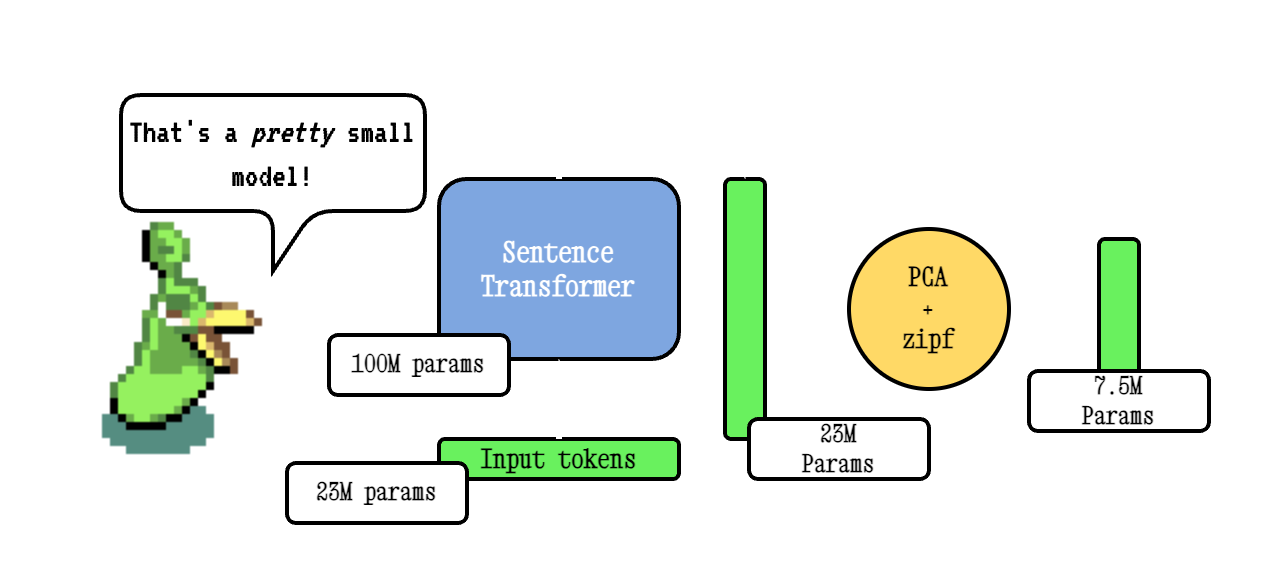
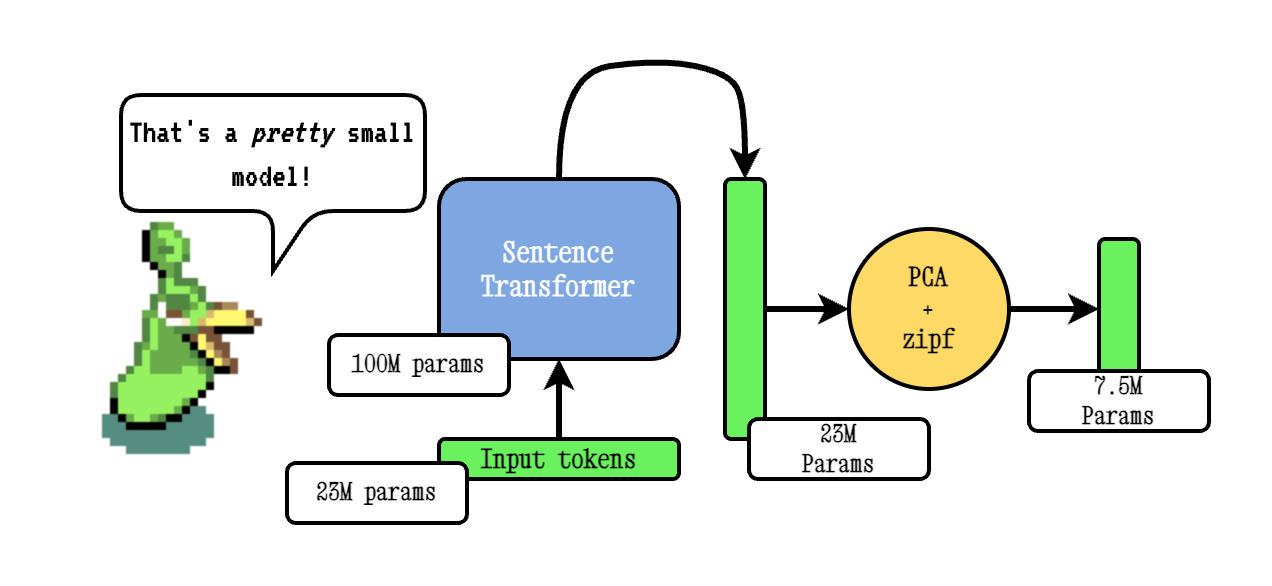
Model2Vec est une technique pour transformer n'importe quel transformateur de phrase en un modèle statique vraiment petit, réduisant la taille du modèle de 15x et rendant les modèles jusqu'à 500x plus rapidement, avec une petite baisse des performances. Notre meilleur modèle est le modèle d'intégration statique le plus performant au monde. Voir nos résultats ici ou plonger pour voir comment cela fonctionne.
Installez le package avec:
pip install model2vec Cela installera le package d'inférence de base, qui ne dépend que de numpy et de quelques autres dépendances mineures. Si vous souhaitez distiller vos propres modèles, vous pouvez installer les extras de distillation avec:
pip install model2vec[distill]Le moyen le plus simple de commencer avec Model2Vec est de charger l'un de nos modèles phares du Huggingface Hub. Ces modèles sont pré-formés et prêts à l'emploi. L'extrait de code suivant montre comment charger un modèle et faire des incorporations:
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Et c'est tout. Vous pouvez utiliser le modèle pour classer les textes, pour vous regrouper ou pour construire un système de chiffon.
Au lieu d'utiliser l'un de nos modèles, vous pouvez également distiller votre propre modèle Model2Vec à partir d'un modèle de transformateur de phrase. L'extrait de code suivant montre comment distiller un modèle:
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )La distillation est vraiment rapide et ne prend que 30 secondes sur le processeur. Mieux encore, la distillation ne nécessite aucune donnée de formation.
Pour une utilisation avancée, comme l'utilisation de Model2Vec dans la bibliothèque des transformateurs de phrase, veuillez vous référer aux sections d'utilisation.
numpy .from_pretrained et push_to_hub . Nos propres modèles peuvent être trouvés ici. N'hésitez pas à partager le vôtre. Model2Vec crée un petit modèle rapide et puissant qui surpasse d'autres modèles d'intégration statique par une grande marge sur toutes les tâches que nous avons pu trouver, tout en étant beaucoup plus rapide à créer que des modèles d'intégration statique traditionnels tels que le gant. Comme BPEMB, il peut créer des incorporations de sous-mots, mais avec de bien meilleures performances. La distillation n'a pas besoin de données, juste un vocabulaire et un modèle.
La technique Model2VEC de base fonctionne en passant un vocabulaire via un modèle de transformateur de phrase, puis en réduisant la dimensionnalité des incorporations résultantes en utilisant PCA, et enfin pondérant les intérêts en utilisant la pondération ZIPF. Pendant l'inférence, nous prenons simplement la moyenne de toutes les intérêts de jetons qui se produisent dans une phrase.
Nos modèles de potion sont pré-formés à l'aide de Tokenlearn, une technique pour pré-entraîner les modèles de distillation Model2VEC. Ces modèles sont créés avec les étapes suivantes:
smooth inverse frequency (SIF) en utilisant la formule suivante: w = 1e-3 / (1e-3 + proba) . Ici, proba est la probabilité de jeton dans le corpus que nous avons utilisé pour la formation.Pour un Deepdive beaucoup plus étendu, veuillez vous référer à notre article de blog Model2Vec et à notre article de blog Tokenleary.
L'inférence fonctionne comme suit. L'exemple montre l'un de nos propres modèles, mais vous pouvez également en charger un local, ou un autre du Hub.
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])L'extrait de code suivant montre comment utiliser un modèle Model2Vec dans la bibliothèque des transformateurs de phrase. Ceci est utile si vous souhaitez utiliser le modèle dans un pipeline de transformateurs de phrase.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Le code suivant peut être utilisé pour distiller un modèle à partir d'un transformateur de phrase. Comme mentionné ci-dessus, cela conduit à un modèle vraiment petit qui pourrait être moins performant.
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )Si vous avez déjà un modèle chargé ou si vous avez besoin de charger un modèle d'une manière spéciale, nous proposons également une interface pour distiller les modèles en mémoire.
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )L'extrait de code suivant montre comment distiller un modèle à l'aide de la bibliothèque Transformers de phrase. Ceci est utile si vous souhaitez utiliser le modèle dans un pipeline de transformateurs de phrase.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Si vous passez un vocabulaire, vous obtenez un ensemble d'incorporation de mots statiques, avec un tokenizer personnalisé pour exactement ce vocabulaire. Ceci est comparable à la façon dont vous utiliseriez le gant ou le word2vec traditionnel, mais ne nécessite pas réellement de corpus ou de données.
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) Par défaut, cela distillera un modèle avec un tokenizer sous-mot, combinant le vocabulaire des modèles (sous-mots) avec le nouveau vocabulaire. Si vous souhaitez obtenir un tokenizer de niveau mot à la place (avec seulement le vocabulaire passé), le paramètre use_subword peut être défini sur False , par exemple:
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) Remarque importante: nous supposons que le vocabulaire passé est trié en fréquence de rang. IE, nous ne nous soucions pas des fréquences de mots réelles, mais supposons que le mot le plus fréquent est le premier, et le mot le moins fréquent est le dernier. Si vous ne savez pas si ce cas est un cas, définissez apply_zipf sur False . Cela désactive la pondération, mais aggravera également les performances.
Nos modèles peuvent être évalués à l'aide de notre ensemble d'évaluation. Installez le package d'évaluation avec:
pip install git+https://github.com/MinishLab/evaluation.git@mainL'extrait de code suivant montre comment évaluer un modèle Model2Vec:
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) Model2VEC peut être utilisé directement dans les transformateurs de phrase en utilisant le module StaticEmbedding .
L'extrait de code suivant montre comment charger un modèle Model2Vec dans un modèle de transformateur de phrase:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])L'extrait de code suivant montre comment distiller un modèle directement dans un modèle de transformateur de phrase:
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])Pour plus de documentation, veuillez vous référer à la documentation des transformateurs de phrase.
Model2VEC peut être utilisé dans TXTAI pour les incorporations de texte, la recherche les plus proches de Neighbors et toutes les autres fonctionnalités offertes par Txtai. L'extrait de code suivant montre comment utiliser Model2Vec dans txtai:
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2VEC est le modèle par défaut de section sémantique à Chonkie. Pour utiliser Model2VEC pour le groupe sémantique à Chonkie, installez simplement Chonkie avec pip install chonkie[semantic] et utilisez l'un des modèles potion dans la classe SemanticChunker . L'extrait de code suivant montre comment utiliser Model2Vec dans Chonkie:
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )Pour utiliser un modèle Model2VEC dans Transformers.js, l'extrait de code suivant peut être utilisé comme point de départ:
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version Notez que cela nécessite que le modèle2vec dispose d'un fichier model.onnx et de plusieurs fichiers de tokenisers requis. Pour les générer pour un modèle qui ne les a pas encore, l'extrait de code suivant peut être utilisé:
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " Nous fournissons un certain nombre de modèles qui peuvent être utilisés hors de la boîte. Ces modèles sont disponibles sur le hub HuggingFace et peuvent être chargés à l'aide de la méthode from_pretrained . Les modèles sont répertoriés ci-dessous.
| Modèle | Langue | Vocab | Transformateur de phrase | Type de jetons | Paramètres | Tokenary |
|---|---|---|---|---|---|---|
| Potion-base-8m | Anglais | Sortir | BGE-base-en-v1.5 | Subordon | 7,5 m | ✅ |
| Potion-base-4m | Anglais | Sortir | BGE-base-en-v1.5 | Subordon | 3,7 m | ✅ |
| Potion-base-2m | Anglais | Sortir | BGE-base-en-v1.5 | Subordon | 1,8 m | ✅ |
| M2v_mullingal_output | Multilingue | Sortir | Labourant | Subordon | 471m |
Nous avons effectué des expériences approfondies pour évaluer les performances des modèles Model2VEC. Les résultats sont documentés dans le dossier des résultats. Les résultats sont présentés dans les sections suivantes:
Mit
Si vous utilisez Model2Vec dans votre recherche, veuillez citer ce qui suit:
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

