model2vec
v0.3.3

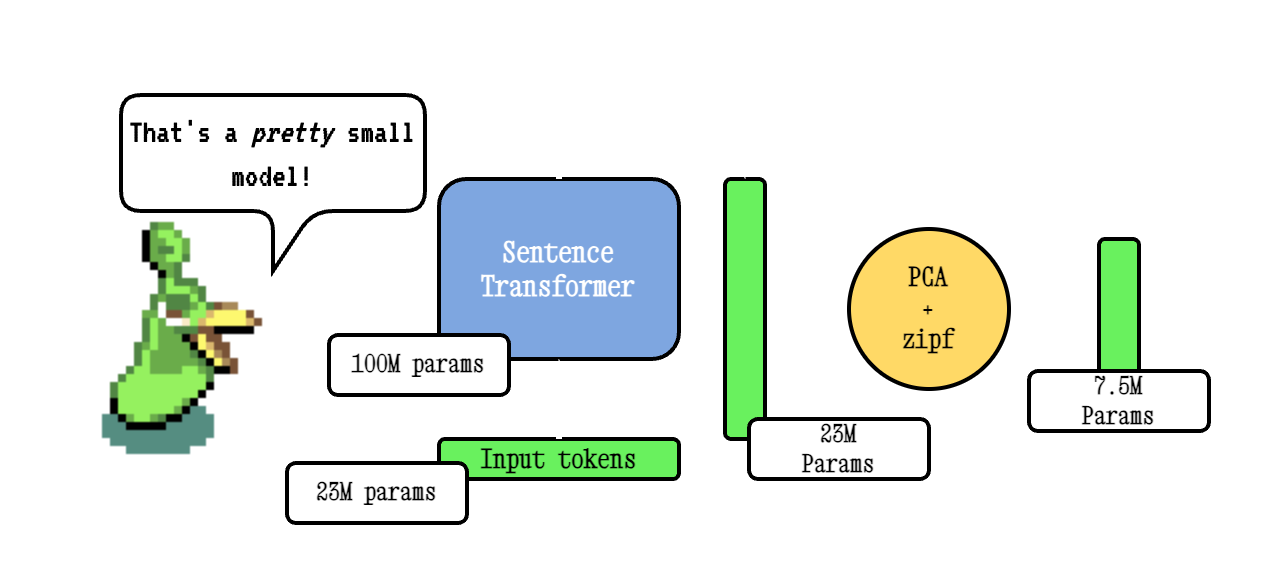
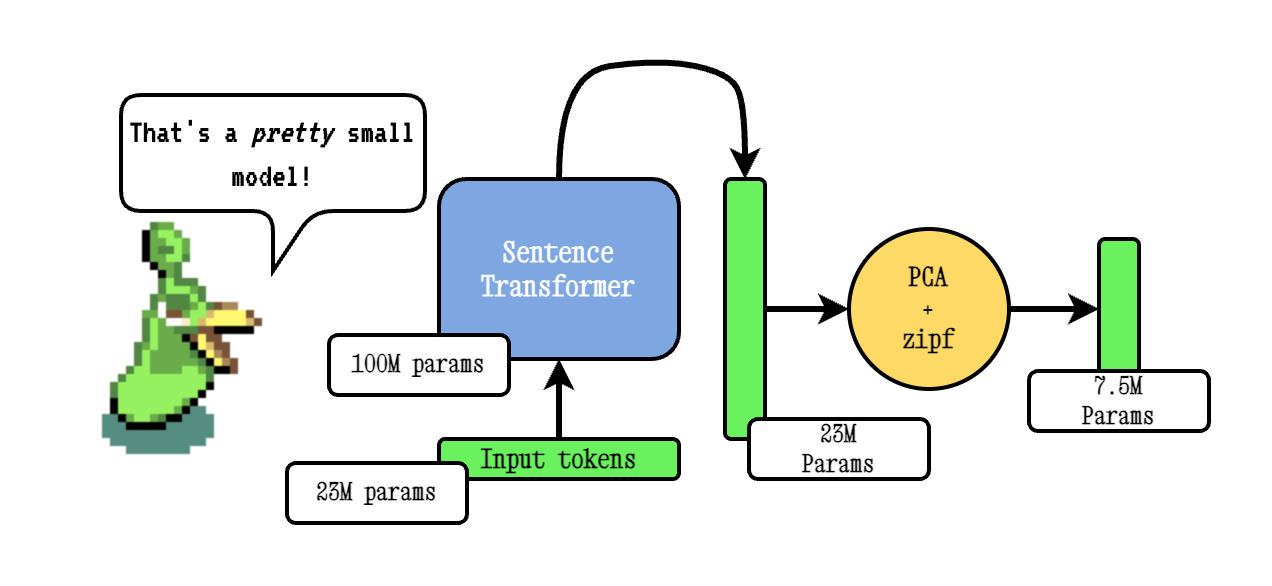
Model2Vecは、あらゆる文トランスを非常に小さな静的モデルに変える手法であり、モデルサイズを15倍に縮小し、パフォーマンスがわずかに低下してモデルを最大500倍高速にします。私たちの最高のモデルは、世界で最もパフォーマンスのある静的埋め込みモデルです。ここで結果をご覧になるか、それがどのように機能するかを確認してください。
パッケージをインストールします:
pip install model2vecこれにより、 numpyと他のいくつかのマイナーな依存関係にのみ依存するベース推論パッケージがインストールされます。独自のモデルを蒸留したい場合は、次のように蒸留エクストラをインストールできます。
pip install model2vec[distill]Model2Vecを開始する最も簡単な方法は、Huggingface Hubからフラッグシップモデルの1つをロードすることです。これらのモデルは事前に訓練されており、使用可能です。次のコードスニペットは、モデルをロードして埋め込みの方法を示しています。
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])そしてそれだけです。モデルを使用して、テキストを分類、クラスター、またはRAGシステムの構築にできます。
モデルのいずれかを使用する代わりに、独自のモデル2VECモデルを文から蒸留することもできます。次のコードスニペットは、モデルを蒸留する方法を示しています。
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )蒸留は非常に速く、CPUで30秒しかかかりません。何よりも、蒸留にはトレーニングデータは必要ありません。
Sente Transformers LibraryでModel2Vecを使用するなど、高度な使用法については、使用セクションを参照してください。
numpyです。from_pretrainedとpush_to_hubを使用します。私たち自身のモデルはここにあります。お気軽に自分で共有してください。 Model2Vecは、グローブなどの従来の静的埋め込みモデルよりもはるかに高速であるが、見つけることができるすべてのタスクで他の静的な埋め込みモデルを上回る小規模で高速で強力なモデルを作成します。 BPEMBと同様に、サブワード埋め込みを作成できますが、パフォーマンスがはるかに優れています。蒸留はデータを必要とせず、語彙とモデルだけです。
ベースモデル2VEC手法は、文化器モデルを通過して語彙を渡し、PCAを使用した結果の埋め込みの次元を減らし、最後にZIPFの重み付けを使用して埋め込みを重み付けすることにより機能します。推論中に、文で発生するすべてのトークン埋め込みの平均を単に取るだけです。
ポーションモデルは、TokenLearnを使用して事前に訓練されています。これは、モデル2VEC蒸留モデルを事前にトレインする手法です。これらのモデルは、次の手順で作成されます。
smooth inverse frequency (SIF)を使用して埋め込みを重み付けすることにより、訓練されたemebeddingsを再正規化します: w = 1e-3 / (1e-3 + proba) 。ここで、 proba 、トレーニングに使用したコーパス内のトークンの確率です。はるかに広範なディープダイブについては、Model2Vecブログ投稿とTokenlearnブログ投稿を参照してください。
推論は次のように機能します。この例は、独自のモデルの1つを示していますが、地元のモデルをハブから別のモデルまたは別のモデルをロードすることもできます。
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])次のコードスニペットには、文化器系ライブラリでモデル2VECモデルを使用する方法を示しています。これは、Modelを文でモデルを使用したい場合に役立ちます。
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])次のコードを使用して、モデルを文から蒸留できます。上記のように、これはパフォーマンスが低いかもしれない非常に小さなモデルにつながります。
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )モデルが既にロードされている場合、またはモデルを何らかの方法でロードする必要がある場合は、メモリ内のモデルを蒸留するインターフェイスも提供します。
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )次のコードスニペットには、文化器変圧器ライブラリを使用してモデルを蒸留する方法を示しています。これは、Modelを文でモデルを使用したい場合に役立ちます。
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])語彙を渡すと、その語彙のためのカスタムトークンザーとともに、静的な単語埋め込みのセットが得られます。これは、グローブまたは従来のword2vecの使用方法に匹敵しますが、実際にはコーパスやデータを必要としません。
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" )デフォルトでは、モデル(サブワード)の語彙と新しい語彙を組み合わせて、サブワードトークネイザーでモデルを蒸留します。代わりに(通過した語彙のみ)、単語レベルのトークナイザーを取得したい場合、 use_subwordパラメーターはFalseに設定できます。
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False )重要な注意:合格した語彙がランクの頻度でソートされていると仮定します。つまり、実際の単語の頻度は気にしませんが、最も頻繁な単語が最初であり、最も頻繁な単語が最後であると仮定します。これがケースかどうかわからない場合は、 apply_zipf Falseに設定します。これにより、重みが無効になりますが、パフォーマンスも少し悪化します。
モデルは、評価パッケージを使用して評価できます。評価パッケージをインストールしてください。
pip install git+https://github.com/MinishLab/evaluation.git@main次のコードスニペットは、モデル2VECモデルを評価する方法を示しています。
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores ))Model2Vecは、 StaticEmbedding編集モジュールを使用して、文で直接使用できます。
次のコードスニペットは、モデル2VECモデルを文変圧器モデルにロードする方法を示しています。
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])次のコードスニペットは、モデルを文変圧器モデルに直接蒸留する方法を示しています。
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])その他のドキュメントについては、Sente Transformersのドキュメントを参照してください。
Model2Vecは、TXTAIでテキストの埋め込み、最近傍の検索、およびTXTAIが提供するその他の機能のいずれかに使用できます。次のコードスニペットは、TXTAIでModel2Vecの使用方法を示しています。
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 )Model2Vecは、Chonkieのセマンティックチャンキングのデフォルトモデルです。 ChonkieでセマンティックチャンキングにModel2Vecを使用するには、 pip install chonkie[semantic]にChonkieをインストールし、 SemanticChunkerクラスのpotionモデルの1つを使用します。次のコードスニペットは、ChonkieでModel2Vecの使用方法を示しています。
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )Transformers.jsでModel2Vecモデルを使用するには、次のコードスニペットを出発点として使用できます。
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python versionこれには、Model2Vecにはmodel.onnxファイルがあり、いくつかの必要なトークナーファイルが必要であることに注意してください。これらをまだ持っていないモデルにこれらを生成するには、次のコードスニペットを使用できます。
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " 箱から出して使用できる多くのモデルを提供します。これらのモデルは、Huggingface Hubで利用でき、 from_pretrainedメソッドを使用してロードできます。モデルは以下にリストされています。
| モデル | 言語 | 語彙 | 文変圧器 | トークン剤の種類 | パラメージ | tokenlearn |
|---|---|---|---|---|---|---|
| ポーションベース-8m | 英語 | 出力 | bge-base-en-v1.5 | サブワード | 7.5m | ✅ |
| ポーションベース-4M | 英語 | 出力 | bge-base-en-v1.5 | サブワード | 3.7m | ✅ |
| ポーションベース-2M | 英語 | 出力 | bge-base-en-v1.5 | サブワード | 1.8m | ✅ |
| m2v_multilingual_output | 多言語 | 出力 | ラボ | サブワード | 471m |
Model2VECモデルのパフォーマンスを評価するために、広範な実験を実施しました。結果は、結果フォルダーに文書化されています。結果は、次のセクションに示されています。
mit
研究でModel2Vecを使用する場合は、以下を引用してください。
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

