model2vec
v0.3.3

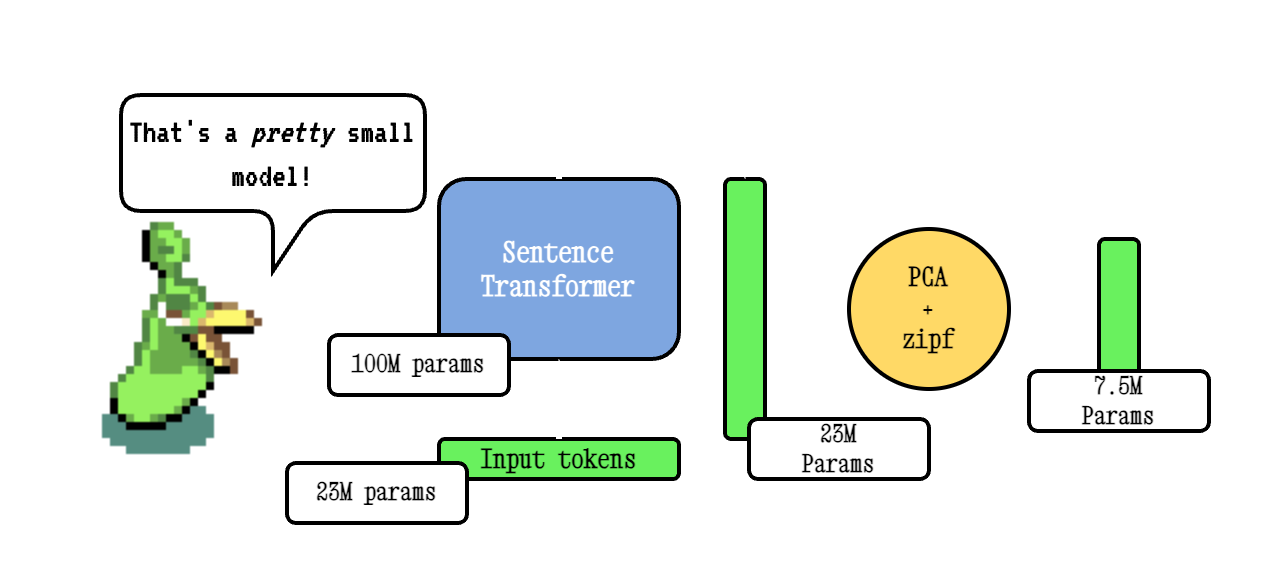
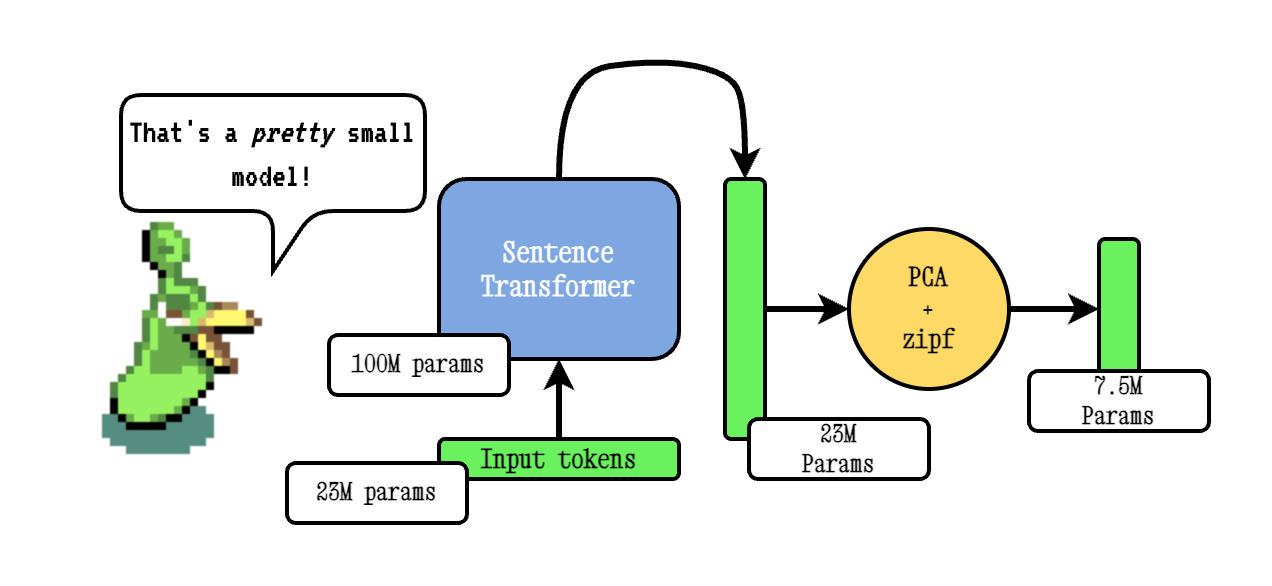
Model2VEC는 모든 문장 변압기를 실제로 작은 정적 모델로 전환하여 모델 크기를 15 배 줄이고 성능이 약간 떨어지면서 모델 크기를 최대 500 배 더 빠르게 만듭니다. 우리의 최고의 모델은 세계에서 가장 성능이 좋은 정적 임베딩 모델입니다. 여기에서 우리의 결과를 보거나 그것이 어떻게 작동하는지 확인하십시오.
패키지를 다음과 같이 설치하십시오.
pip install model2vec 이것은 기본 추론 패키지를 설치합니다. 기본 추론 패키지는 numpy 및 기타 작은 종속성에만 의존합니다. 자신의 모델을 증류하려면 다음과 함께 증류 엑스트라를 설치할 수 있습니다.
pip install model2vec[distill]Model2VEC를 시작하는 가장 쉬운 방법은 Huggingface 허브에서 플래그십 모델 중 하나를로드하는 것입니다. 이 모델은 미리 훈련되고 사용할 준비가되었습니다. 다음 코드 스 니펫은 모델을로드하고 임베딩을 만드는 방법을 보여줍니다.
from model2vec import StaticModel
# Load a model from the HuggingFace hub (in this case the potion-base-8M model)
model = StaticModel . from_pretrained ( "minishlab/potion-base-8M" )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])그리고 그게 다야. 모델을 사용하여 텍스트를 분류, 클러스터로 또는 헝겊 시스템을 구축 할 수 있습니다.
우리 모델 중 하나를 사용하는 대신 문장 변압기 모델에서 자신의 Model2VEC 모델을 증류 할 수도 있습니다. 다음 코드 스 니펫은 모델을 증류하는 방법을 보여줍니다.
from model2vec . distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )증류는 실제로 빠르며 CPU에서 30 초 밖에 걸리지 않습니다. 무엇보다도 증류에는 훈련 데이터가 필요하지 않습니다.
Sentence Transformers 라이브러리에서 Model2Vec 사용과 같은 고급 사용에 대해서는 사용 섹션을 참조하십시오.
numpy 입니다.from_pretrained 및 push_to_hub 사용하여 Huggingface Hub에서 모델을 쉽게 공유하고로드합니다. 우리 자신의 모델은 여기에서 찾을 수 있습니다. 자신의 공유를 자유롭게 공유하십시오. Model2VEC는 작고 빠르며 강력한 모델을 만듭니다. 작고 빠르며 강력한 모델을 만듭니다.이 모델은 우리가 찾을 수있는 모든 작업에서 다른 정적 임베딩 모델보다 큰 마진을 능가하는 반면, 글러브와 같은 기존의 정적 임베딩 모델보다 훨씬 빠릅니다. BPEMB와 마찬가지로 서브 워드 임베딩을 만들 수 있지만 훨씬 더 나은 성능을 제공합니다. 증류에는 데이터 가 필요하지 않으며 어휘 및 모델 만 필요합니다.
Base Model2VEC 기술은 문장 변압기 모델을 통해 어휘를 전달한 다음 PCA를 사용하여 결과 임베딩의 차원을 줄이고 마지막으로 ZIPF 가중치를 사용하여 임베딩을 가중시켜 작동합니다. 추론하는 동안, 우리는 단순히 문장에서 발생하는 모든 토큰 임베딩의 평균을 취합니다.
우리의 물약 모델은 Model2VEC 증류 모델을 사전 트레인하는 기술인 Tokenlearn을 사용하여 미리 훈련됩니다. 이 모델은 다음 단계로 만들어집니다.
smooth inverse frequency (SIF) 가중치를 사용하여 내장 가중화합니다. w = 1e-3 / (1e-3 + proba) . 여기서 proba 우리가 훈련에 사용한 코퍼스에서 토큰의 확률입니다.훨씬 더 광범위한 딥 디브는 Model2Vec 블로그 게시물과 TokenLearn 블로그 게시물을 참조하십시오.
추론은 다음과 같이 작동합니다. 이 예제는 우리 자신의 모델 중 하나를 보여 주지만 로컬 모델 또는 허브에서 다른 모델을로드 할 수도 있습니다.
from model2vec import StaticModel
# Load a model from the Hub. You can optionally pass a token when loading a private model
model = StaticModel . from_pretrained ( model_name = "minishlab/potion-base-8M" , token = None )
# Make embeddings
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])
# Make sequences of token embeddings
token_embeddings = model . encode_as_sequence ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])다음 코드 스 니펫은 문장 변압기 라이브러리에서 Model2VEC 모델을 사용하는 방법을 보여줍니다. 문장 변압기 파이프 라인에서 모델을 사용하려는 경우 유용합니다.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])다음 코드는 문장 변압기에서 모델을 증류하는 데 사용될 수 있습니다. 위에서 언급했듯이, 이것은 성능이 떨어질 수있는 실제로 작은 모델로 이어집니다.
from model2vec . distill import distill
# Distill a Sentence Transformer model
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , pca_dims = 256 )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )이미 모델을로드하거나 특별한 방식으로 모델을로드 해야하는 경우 메모리에서 모델을 증류하기위한 인터페이스도 제공합니다.
from transformers import AutoModel , AutoTokenizer
from model2vec . distill import distill_from_model
# Assuming a loaded model and tokenizer
model_name = "baai/bge-base-en-v1.5"
model = AutoModel . from_pretrained ( model_name )
tokenizer = AutoTokenizer . from_pretrained ( model_name )
m2v_model = distill_from_model ( model = model , tokenizer = tokenizer , pca_dims = 256 )
m2v_model . save_pretrained ( "m2v_model" )다음 코드 스 니펫은 문장 변압기 라이브러리를 사용하여 모델을 증류하는 방법을 보여줍니다. 문장 변압기 파이프 라인에서 모델을 사용하려는 경우 유용합니다.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])어휘를 통과하면 정확히 그 어휘를 위해 맞춤형 토큰 화기와 함께 정적 단어 임베딩 세트를 얻을 수 있습니다. 이것은 글러브 또는 전통적인 Word2Vec을 사용하는 방법과 비교할 수 있지만 실제로는 코퍼스 나 데이터가 필요하지 않습니다.
from model2vec . distill import distill
# Load a vocabulary as a list of strings
vocabulary = [ "word1" , "word2" , "word3" ]
# Distill a Sentence Transformer model with the custom vocabulary
m2v_model = distill ( model_name = "BAAI/bge-base-en-v1.5" , vocabulary = vocabulary )
# Save the model
m2v_model . save_pretrained ( "m2v_model" )
# Or push it to the hub
m2v_model . push_to_hub ( "my_organization/my_model" , token = "<it's a secret to everybody>" ) 기본적으로 이렇게하면 서브 워드 토큰 화제로 모델을 증류하여 모델 (서브 워드) 어휘를 새로운 어휘와 결합합니다. 대신 단어 수준의 토큰 화제를 받으려면 (전달 된 어휘만으로) use_subword 매개 변수를 False 로 설정할 수 있습니다.
m2v_model = distill ( model_name = model_name , vocabulary = vocabulary , use_subword = False ) 중요한 참고 : 통과 된 어휘가 순위 주파수로 정렬된다고 가정합니다. 즉, 우리는 실제 단어 주파수를 신경 쓰지 않지만 가장 빈번한 단어가 가장 먼저하고 가장 빈번한 단어가 마지막이라고 가정합니다. 이것이 사실인지 확실하지 않은 경우 apply_zipf False 로 설정하십시오. 이것은 가중치를 비활성화하지만 성능도 조금 악화시킬 것입니다.
우리의 모델은 평가 패키지를 사용하여 평가할 수 있습니다. 다음과 같이 평가 패키지를 설치하십시오.
pip install git+https://github.com/MinishLab/evaluation.git@main다음 코드 스 니펫은 Model2VEC 모델을 평가하는 방법을 보여줍니다.
from model2vec import StaticModel
from evaluation import CustomMTEB , get_tasks , parse_mteb_results , make_leaderboard , summarize_results
from mteb import ModelMeta
# Get all available tasks
tasks = get_tasks ()
# Define the CustomMTEB object with the specified tasks
evaluation = CustomMTEB ( tasks = tasks )
# Load the model
model_name = "m2v_model"
model = StaticModel . from_pretrained ( model_name )
# Optionally, add model metadata in MTEB format
model . mteb_model_meta = ModelMeta (
name = model_name , revision = "no_revision_available" , release_date = None , languages = None
)
# Run the evaluation
results = evaluation . run ( model , eval_splits = [ "test" ], output_folder = f"results" )
# Parse the results and summarize them
parsed_results = parse_mteb_results ( mteb_results = results , model_name = model_name )
task_scores = summarize_results ( parsed_results )
# Print the results in a leaderboard format
print ( make_leaderboard ( task_scores )) Model2VEC는 StaticEmbedding 모듈을 사용하여 문장 변압기에서 직접 사용할 수 있습니다.
다음 코드 스 니펫은 Model2VEC 모델을 문장 변압기 모델에로드하는 방법을 보여줍니다.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
# Initialize a StaticEmbedding module
static_embedding = StaticEmbedding . from_model2vec ( "minishlab/potion-base-8M" )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])다음 코드 스 니펫은 모델을 문장 변압기 모델로 직접 증류하는 방법을 보여줍니다.
from sentence_transformers import SentenceTransformer
from sentence_transformers . models import StaticEmbedding
static_embedding = StaticEmbedding . from_distillation ( "BAAI/bge-base-en-v1.5" , device = "cpu" , pca_dims = 256 )
model = SentenceTransformer ( modules = [ static_embedding ])
embeddings = model . encode ([ "It's dangerous to go alone!" , "It's a secret to everybody." ])자세한 내용은 문장 변압기 문서를 참조하십시오.
Model2VEC는 TXTAI에서 텍스트 임베딩, 가장 가까운 노이버 검색 및 TXTAI가 제공하는 다른 기능을 위해 사용할 수 있습니다. 다음 코드 스 니펫은 txtai에서 Model2Vec 사용 방법을 보여줍니다.
from txtai import Embeddings
# Load a model2vec model
embeddings = Embeddings ( path = "minishlab/potion-base-8M" , method = "model2vec" , backend = "numpy" )
# Create some example texts
texts = [ "Enduring Stew" , "Hearty Elixir" , "Mighty Mushroom Risotto" , "Spicy Meat Skewer" , "Chilly Fruit Salad" ]
# Create embeddings for downstream tasks
vectors = embeddings . batchtransform ( texts )
# Or create a nearest-neighbors index and search it
embeddings . index ( texts )
result = embeddings . search ( "Risotto" , 1 ) Model2VEC는 Chonkie의 시맨틱 청크를위한 기본 모델입니다. Chonkie에서 Semantic Chunking에 Model2Vec을 사용하려면 Chonkie를 설치하여 pip install chonkie[semantic] 하고 SemanticChunker 클래스에서 potion 모델 중 하나를 사용하십시오. 다음 코드 스 니펫은 Chonkie에서 Model2Vec 사용 방법을 보여줍니다.
from chonkie import SDPMChunker
# Create some example text to chunk
text = "It's dangerous to go alone! Take this."
# Initialize the SemanticChunker with a potion model
chunker = SDPMChunker (
embedding_model = "minishlab/potion-base-8M" ,
similarity_threshold = 0.3
)
# Chunk the text
chunks = chunker . chunk ( text )Transformers.js에서 Model2Vec 모델을 사용하려면 다음 코드 스 니펫을 시작점으로 사용할 수 있습니다.
import { AutoModel , AutoTokenizer , Tensor } from '@huggingface/transformers' ;
const modelName = 'minishlab/potion-base-8M' ;
const modelConfig = {
config : { model_type : 'model2vec' } ,
dtype : 'fp32' ,
revision : 'refs/pr/1'
} ;
const tokenizerConfig = {
revision : 'refs/pr/2'
} ;
const model = await AutoModel . from_pretrained ( modelName , modelConfig ) ;
const tokenizer = await AutoTokenizer . from_pretrained ( modelName , tokenizerConfig ) ;
const texts = [ 'hello' , 'hello world' ] ;
const { input_ids } = await tokenizer ( texts , { add_special_tokens : false , return_tensor : false } ) ;
const cumsum = arr => arr . reduce ( ( acc , num , i ) => [ ... acc , num + ( acc [ i - 1 ] || 0 ) ] , [ ] ) ;
const offsets = [ 0 , ... cumsum ( input_ids . slice ( 0 , - 1 ) . map ( x => x . length ) ) ] ;
const flattened_input_ids = input_ids . flat ( ) ;
const modelInputs = {
input_ids : new Tensor ( 'int64' , flattened_input_ids , [ flattened_input_ids . length ] ) ,
offsets : new Tensor ( 'int64' , offsets , [ offsets . length ] )
} ;
const { embeddings } = await model ( modelInputs ) ;
console . log ( embeddings . tolist ( ) ) ; // output matches python version Model2Vec에는 model.onnx 파일과 몇 가지 필요한 토큰 화제 파일이 있어야합니다. 아직 모델이없는 모델에 대해 이들을 생성하려면 다음 코드 스 니펫을 사용할 수 있습니다.
python scripts/export_to_onnx.py --model_path < path-to-a-model2vec-model > --save_path " <path-to-save-the-onnx-model> " 우리는 상자에서 사용할 수있는 여러 모델을 제공합니다. 이 모델은 Huggingface Hub에서 사용할 수 있으며 from_pretrained 메소드를 사용하여로드 할 수 있습니다. 모델은 아래에 나열되어 있습니다.
| 모델 | 언어 | 어휘 | 문장 변압기 | 토 케이저 유형 | 매개 변수 | TokenLearn |
|---|---|---|---|---|---|---|
| 물약베이스 -8m | 영어 | 산출 | BGE-BASE-EN-V1.5 | 하위 단어 | 7.5m | ✅ |
| 물약베이스 -4m | 영어 | 산출 | BGE-BASE-EN-V1.5 | 하위 단어 | 3.7m | ✅ |
| Potion-Base-2M | 영어 | 산출 | BGE-BASE-EN-V1.5 | 하위 단어 | 1.8m | ✅ |
| m2v_multingual_output | 다국어 | 산출 | labse | 하위 단어 | 471m |
우리는 Model2VEC 모델의 성능을 평가하기 위해 광범위한 실험을 수행했습니다. 결과는 결과 폴더에 문서화되어 있습니다. 결과는 다음 섹션에 나와 있습니다.
MIT
연구에서 Model2VEC를 사용하는 경우 다음을 인용하십시오.
@software { minishlab2024model2vec ,
authors = { Stephan Tulkens, Thomas van Dongen } ,
title = { Model2Vec: The Fastest State-of-the-Art Static Embeddings in the World } ,
year = { 2024 } ,
url = { https://github.com/MinishLab/model2vec } ,
}

