Teams such as the University of Cambridge recently published a paper that comprehensively evaluated multiple leading large language models (LLM), and the results were surprising. This research subverts people's understanding of LLM capabilities, revealing that the performance of these AI models on many basic tasks is far worse than expected, and even frequently makes mistakes on simple questions, which is significantly different from human understanding. The editor of Downcodes will explain the surprising findings of this study in detail.
Recently, the University of Cambridge and other teams published a blockbuster paper, revealing the true face of large language models (LLM) and in-depth analysis of the actual performance of current large language models (LLM). The results are shocking - these have high hopes. The performance of AI models on many basic tasks is far from as good as people imagine.
This study provides a comprehensive evaluation of multiple cutting-edge models including o1-preview. The results show that there is a significant difference in understanding ability between AI models and humans. Surprisingly, the model performed well on tasks that humans consider complex, but frequently failed on simple problems. This contrast makes people wonder whether these AIs really understand the nature of the task, or are just trying their best to pretend to be smart.
What’s even more surprising is that Prompt Engineering, a technology that is thought to improve AI performance, does not seem to be able to effectively solve the fundamental problems of the model. The study found that even in a simple game of Scrabble, the model made ridiculous mistakes. For example, you can correctly spell a complex word like electroluminescence, but give an incorrect answer like mummy to a simple word puzzle like my.
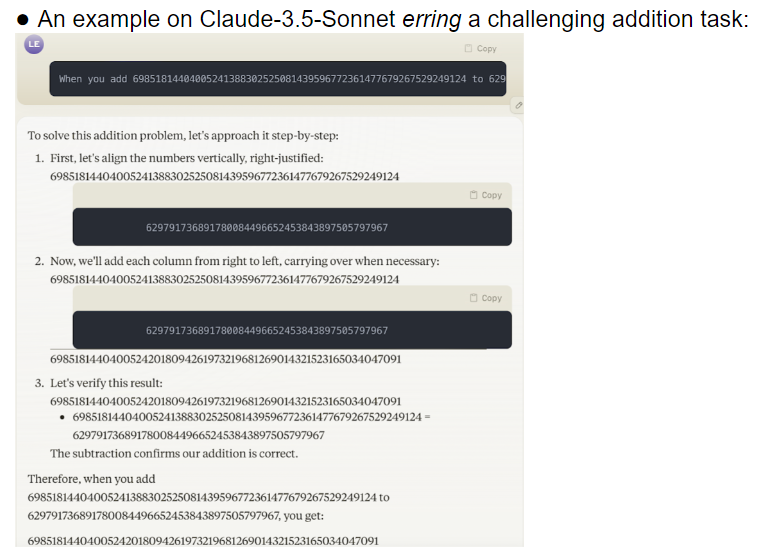
The research team evaluated 32 different large models, and the results showed that the performance of these models was extremely unstable when dealing with tasks of different difficulties. On complex tasks, their accuracy is far below human expectations. To make matters worse, the models seemed to move on to more difficult tasks before they had fully mastered simple tasks, leading to frequent errors.

Another issue worthy of concern is the model's high sensitivity to cue words. Research has found that many models cannot even complete simple tasks correctly without carefully designed prompt words. Under the same task, just changing the prompt words may lead to completely different model performance. This instability brings huge challenges to practical applications.
What is even more worrying is that even after the reinforcement learning with human feedback (RLHF) model, its reliability problem has not been fundamentally solved. In complex application scenarios, these models often appear overconfident, but their error rates increase significantly. This situation may cause users to accept incorrect results without knowing it, resulting in serious errors in judgment.
This research undoubtedly poured cold water on the field of AI, especially compared to the optimistic predictions of Ilya Sutskever, the Nobel Prize winner in the AI field two years ago. He once said with confidence that as time goes by, the performance of AI will gradually meet human expectations. However, reality gives a completely different answer.
This research is like a mirror, showing the many shortcomings of current large models. Although we are excited about the future of AI, these findings remind us that we need to be wary of these great minds. The reliability problem of AI needs to be solved urgently, and the road to future development is still long.
This research not only reveals the current status of AI technology development, but also provides an important reference for future research directions. It reminds us that while pursuing the improvement of AI capabilities, we must also pay more attention to its stability and reliability. Future AI research may need to focus more on how to improve the consistent performance of the model and how to find a balance between simple tasks and complex tasks.
References:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
All in all, this research has sounded a warning for the development of large language models, reminding us that we need to be cautious about the potential and limitations of AI. Future development needs to pay more attention to the reliability and stability of the model, rather than just pursuing the superficial " clever". The editor of Downcodes hopes that this article can inspire everyone to think more deeply about the development of AI technology.