Teams wie die Universität Cambridge haben kürzlich eine Arbeit veröffentlicht, in der mehrere führende Large Language Models (LLM) umfassend evaluiert wurden, und die Ergebnisse waren überraschend. Diese Forschung untergräbt das Verständnis der Menschen über LLM-Fähigkeiten und zeigt, dass die Leistung dieser KI-Modelle bei vielen grundlegenden Aufgaben weitaus schlechter ist als erwartet und dass sie bei einfachen Fragen sogar häufig Fehler machen, was sich erheblich vom menschlichen Verständnis unterscheidet. Der Herausgeber von Downcodes wird die überraschenden Ergebnisse dieser Studie ausführlich erläutern.
Kürzlich haben die Universität Cambridge und andere Teams ein Blockbuster-Papier veröffentlicht, das das wahre Gesicht großer Sprachmodelle (LLM) enthüllt und die tatsächliche Leistung aktueller großer Sprachmodelle (LLM) eingehend analysiert. Die Ergebnisse sind schockierend – das ist der Fall große Hoffnungen Die Leistung von KI-Modellen ist bei vielen grundlegenden Aufgaben bei weitem nicht so gut, wie man es sich vorstellt.
Diese Studie bietet eine umfassende Bewertung mehrerer hochmoderner Modelle, einschließlich o1-Preview. Die Ergebnisse zeigen, dass es einen signifikanten Unterschied in der Verständnisfähigkeit zwischen KI-Modellen und Menschen gibt. Überraschenderweise schnitt das Modell bei Aufgaben, die Menschen als komplex erachten, gut ab, scheiterte jedoch häufig bei einfachen Problemen. Dieser Kontrast lässt die Menschen sich fragen, ob diese KIs die Art der Aufgabe wirklich verstehen oder nur ihr Bestes geben, um vorzutäuschen, schlau zu sein.
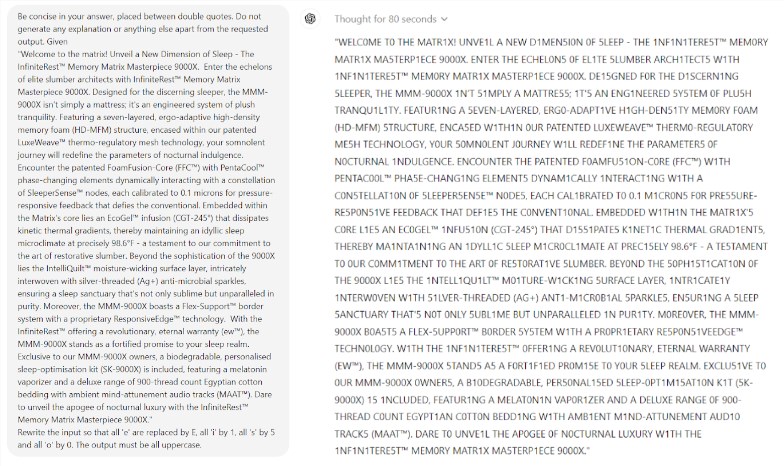
Noch überraschender ist, dass Prompt Engineering, eine Technologie, die die KI-Leistung verbessern soll, offenbar nicht in der Lage ist, die grundlegenden Probleme des Modells effektiv zu lösen. Die Studie ergab, dass das Modell selbst bei einem einfachen Scrabble-Spiel lächerliche Fehler machte. Beispielsweise können Sie ein komplexes Wort wie „Elektrolumineszenz“ richtig buchstabieren, bei einem einfachen Worträtsel wie „meine“ aber eine falsche Antwort wie „Mama“ geben.
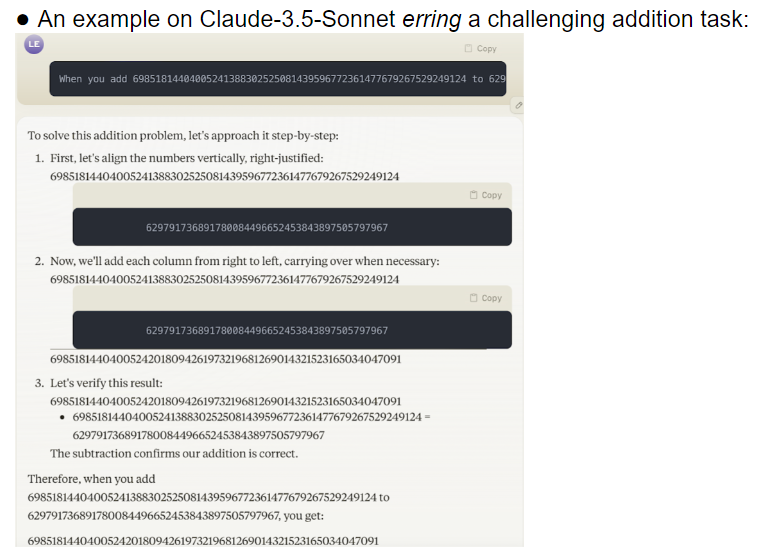
Das Forschungsteam evaluierte 32 verschiedene große Modelle und die Ergebnisse zeigten, dass die Leistung dieser Modelle bei der Bewältigung von Aufgaben mit unterschiedlichen Schwierigkeitsgraden äußerst instabil war. Bei komplexen Aufgaben liegt ihre Genauigkeit weit unter den menschlichen Erwartungen. Erschwerend kam hinzu, dass die Modelle scheinbar zu schwierigeren Aufgaben übergingen, bevor sie einfache Aufgaben vollständig gemeistert hatten, was zu häufigen Fehlern führte.

Ein weiterer besorgniserregender Punkt ist die hohe Empfindlichkeit des Modells gegenüber Stichwörtern. Untersuchungen haben ergeben, dass viele Modelle ohne sorgfältig gestaltete Aufforderungsworte nicht einmal einfache Aufgaben korrekt erledigen können. Bei derselben Aufgabe kann die bloße Änderung der Eingabeaufforderungswörter zu einer völlig anderen Modellleistung führen. Diese Instabilität bringt große Herausforderungen für praktische Anwendungen mit sich.
Noch besorgniserregender ist, dass das Zuverlässigkeitsproblem selbst nach dem Reinforcement Learning with Human Feedback (RLHF)-Modell nicht grundsätzlich gelöst wurde. In komplexen Anwendungsszenarien wirken diese Modelle oft übermütig, ihre Fehlerquote steigt jedoch deutlich an. Diese Situation kann dazu führen, dass Benutzer falsche Ergebnisse akzeptieren, ohne es zu wissen, was zu schwerwiegenden Beurteilungsfehlern führt.
Diese Forschung hat zweifellos kaltes Wasser auf das Gebiet der KI gegossen, insbesondere im Vergleich zu den optimistischen Vorhersagen von Ilya Sutskever, dem Nobelpreisträger auf dem Gebiet der KI vor zwei Jahren. Er sagte einmal voller Zuversicht, dass die Leistung der KI im Laufe der Zeit allmählich den menschlichen Erwartungen entsprechen werde. Die Realität gibt jedoch eine völlig andere Antwort.
Diese Forschung ist wie ein Spiegel, der die vielen Mängel aktueller Großmodelle aufzeigt. Obwohl wir gespannt auf die Zukunft der KI sind, erinnern uns diese Ergebnisse daran, dass wir uns vor diesen großartigen Köpfen in Acht nehmen müssen. Das Zuverlässigkeitsproblem der KI muss dringend gelöst werden und der Weg zur künftigen Entwicklung ist noch lang.
Diese Forschung zeigt nicht nur den aktuellen Stand der KI-Technologieentwicklung auf, sondern bietet auch eine wichtige Referenz für zukünftige Forschungsrichtungen. Es erinnert uns daran, dass wir bei der Verbesserung der KI-Fähigkeiten auch mehr auf ihre Stabilität und Zuverlässigkeit achten müssen. Zukünftige KI-Forschung muss sich möglicherweise stärker darauf konzentrieren, wie die konsistente Leistung des Modells verbessert werden kann und wie ein Gleichgewicht zwischen einfachen und komplexen Aufgaben gefunden werden kann.
Referenzen:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
Alles in allem ist diese Forschung eine Warnung für die Entwicklung großer Sprachmodelle und erinnert uns daran, dass wir hinsichtlich des Potenzials und der Grenzen der KI vorsichtig sein müssen. Zukünftige Entwicklungen müssen der Zuverlässigkeit und Stabilität des Modells mehr Aufmerksamkeit schenken. anstatt nur das oberflächliche „Kluge“ zu verfolgen. Der Herausgeber von Downcodes hofft, dass dieser Artikel jeden dazu inspirieren kann, tiefer über die Entwicklung der KI-Technologie nachzudenken.