Такие группы, как Кембриджский университет, недавно опубликовали статью, в которой всесторонне оценивались несколько ведущих моделей больших языков (LLM), и результаты были удивительными. Это исследование подрывает понимание людьми возможностей LLM, показывая, что эффективность этих моделей ИИ во многих базовых задачах намного хуже, чем ожидалось, и даже часто допускает ошибки в простых вопросах, что значительно отличается от человеческого понимания. Редактор Downcodes подробно объяснит удивительные результаты этого исследования.
Недавно Кембриджский университет и другие команды опубликовали нашумевшую статью, раскрывающую истинное лицо моделей больших языков (LLM) и углубленный анализ фактической производительности существующих моделей больших языков (LLM). Результаты шокируют — они уже есть. большие надежды. Производительность моделей ИИ во многих основных задачах далеко не так хороша, как люди себе представляют.
В этом исследовании представлена всесторонняя оценка нескольких передовых моделей, включая o1-preview. Результаты показывают, что существует значительная разница в способности понимания между моделями ИИ и людьми. Удивительно, но модель хорошо справлялась с задачами, которые люди считают сложными, но часто терпела неудачу с простыми задачами. Этот контраст заставляет людей задуматься, действительно ли эти ИИ понимают суть задачи или просто изо всех сил стараются притвориться умными.
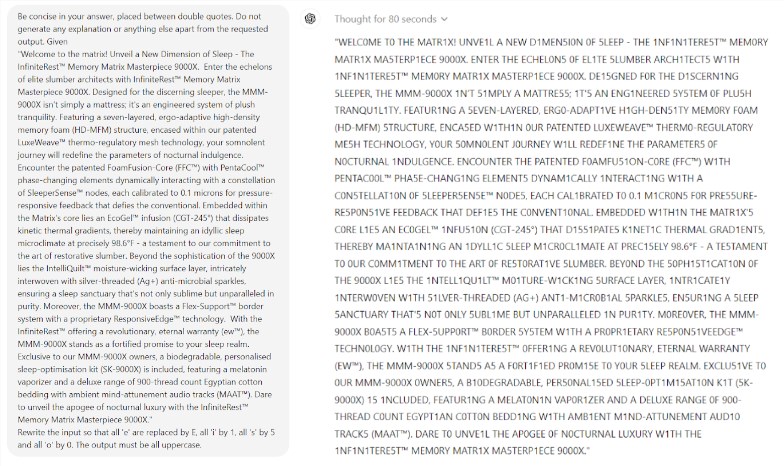
Что еще более удивительно, так это то, что Prompt Engineering, технология, которая, как считается, улучшает производительность ИИ, похоже, не способна эффективно решить фундаментальные проблемы модели. Исследование показало, что даже в простой игре в «Эрудит» модель допускала нелепые ошибки. Например, вы можете правильно написать сложное слово, например «электролюминесценция», но дать неправильный ответ, например «мумия», на простую словесную головоломку, такую как «моя».
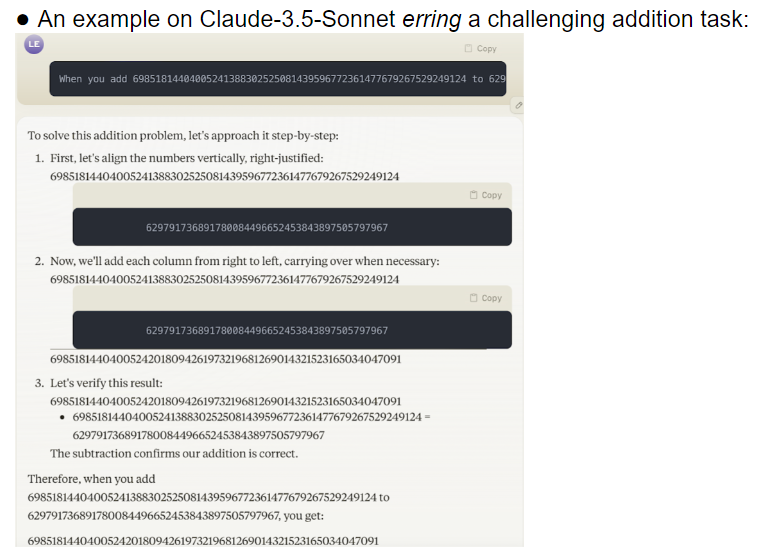
Исследовательская группа оценила 32 различные большие модели, и результаты показали, что производительность этих моделей была крайне нестабильной при решении задач различной сложности. В сложных задачах их точность намного ниже человеческих ожиданий. Что еще хуже, модели, казалось, переходили к более сложным задачам еще до того, как полностью освоили простые задачи, что приводило к частым ошибкам.

Еще одна проблема, заслуживающая внимания, — высокая чувствительность модели к репликам. Исследования показали, что многие модели не могут правильно выполнить даже простые задачи без тщательно продуманных слов-подсказок. В той же задаче простое изменение слов-подсказок может привести к совершенно другой производительности модели. Эта нестабильность создает огромные проблемы для практических приложений.
Что еще больше беспокоит, так это то, что даже после модели обучения с подкреплением с обратной связью от человека (RLHF) ее проблема надежности не была фундаментально решена. В сложных сценариях приложений эти модели часто кажутся слишком самоуверенными, но частота ошибок в них значительно возрастает. Эта ситуация может привести к тому, что пользователи, даже не подозревая об этом, примут неправильные результаты, что приведет к серьезным ошибкам в суждениях.
Это исследование, несомненно, пролило холодную воду на область ИИ, особенно по сравнению с оптимистичными прогнозами Ильи Суцкевера, лауреата Нобелевской премии в области ИИ два года назад. Однажды он с уверенностью сказал, что со временем производительность ИИ постепенно будет соответствовать человеческим ожиданиям. Однако реальность дает совершенно другой ответ.
Это исследование похоже на зеркало, показывающее многие недостатки нынешних больших моделей. Хотя мы воодушевлены будущим искусственного интеллекта, эти результаты напоминают нам, что нам следует опасаться этих великих умов. Проблема надежности ИИ требует срочного решения, а путь к будущему развитию еще долгий.
Это исследование не только раскрывает текущий статус развития технологий искусственного интеллекта, но и дает важную информацию для будущих направлений исследований. Это напоминает нам, что, стремясь к совершенствованию возможностей ИИ, мы также должны уделять больше внимания его стабильности и надежности. Будущим исследованиям ИИ, возможно, придется больше сосредоточиться на том, как улучшить стабильную производительность модели и как найти баланс между простыми и сложными задачами.
Ссылки:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
В целом, это исследование прозвучало предупреждением о необходимости разработки больших языковых моделей, напомнив нам, что нам нужно быть осторожными в отношении потенциала и ограничений ИИ. Будущие разработки должны уделять больше внимания надежности и стабильности модели. а не просто гоняться за поверхностными «умными». Редактор Downcodes надеется, что эта статья сможет вдохновить каждого более глубоко задуматься о развитии технологий искусственного интеллекта.