ทีมงานอย่างมหาวิทยาลัยเคมบริดจ์เพิ่งตีพิมพ์บทความที่ประเมินแบบจำลองภาษาขนาดใหญ่ชั้นนำ (LLM) จำนวนมากอย่างครอบคลุม และผลลัพธ์ก็น่าประหลาดใจ งานวิจัยนี้ล้มล้างความเข้าใจของผู้คนเกี่ยวกับความสามารถของ LLM โดยเผยให้เห็นว่าประสิทธิภาพของโมเดล AI เหล่านี้ในงานพื้นฐานหลายอย่างนั้นแย่กว่าที่คาดไว้มาก และยังทำผิดพลาดกับคำถามง่ายๆ บ่อยครั้ง ซึ่งแตกต่างจากความเข้าใจของมนุษย์อย่างมาก บรรณาธิการของ Downcodes จะอธิบายรายละเอียดการค้นพบที่น่าประหลาดใจของการศึกษาครั้งนี้
เมื่อเร็ว ๆ นี้ มหาวิทยาลัยเคมบริดจ์และทีมอื่น ๆ ตีพิมพ์บทความบล็อกบัสเตอร์ ซึ่งเผยให้เห็นโฉมหน้าที่แท้จริงของโมเดลภาษาขนาดใหญ่ (LLM) และการวิเคราะห์เชิงลึกเกี่ยวกับประสิทธิภาพที่แท้จริงของโมเดลภาษาขนาดใหญ่ในปัจจุบัน (LLM) ผลลัพธ์ที่ได้น่าตกใจ - สิ่งเหล่านี้มี ความหวังสูง ประสิทธิภาพของโมเดล AI ในงานพื้นฐานหลายอย่างยังห่างไกลจากสิ่งที่ดีเท่าที่ผู้คนจินตนาการ
การศึกษานี้ให้การประเมินที่ครอบคลุมของแบบจำลองที่ทันสมัยหลายแบบ รวมถึง o1-preview ผลการวิจัยพบว่ามีความแตกต่างอย่างมีนัยสำคัญในการทำความเข้าใจความสามารถในการทำความเข้าใจระหว่างโมเดล AI และมนุษย์ น่าประหลาดใจที่แบบจำลองทำงานได้ดีกับงานที่มนุษย์พิจารณาว่าซับซ้อน แต่มักล้มเหลวในปัญหาง่ายๆ ความแตกต่างนี้ทำให้ผู้คนสงสัยว่า AI เหล่านี้เข้าใจธรรมชาติของงานจริง ๆ หรือแค่พยายามอย่างเต็มที่เพื่อแสร้งทำเป็นว่าฉลาด
สิ่งที่น่าแปลกใจยิ่งกว่านั้นคือ Prompt Engineering ซึ่งเป็นเทคโนโลยีที่คิดว่าจะช่วยปรับปรุงประสิทธิภาพของ AI ดูเหมือนจะไม่สามารถแก้ไขปัญหาพื้นฐานของแบบจำลองได้อย่างมีประสิทธิภาพ การศึกษาพบว่าแม้ในเกม Scrabble ง่ายๆ แต่โมเดลก็ยังทำผิดพลาดอย่างน่าขัน ตัวอย่างเช่น คุณสามารถสะกดคำที่ซับซ้อน เช่น อิเล็กโตรลูมิเนสเซนส์ ได้อย่างถูกต้อง แต่ให้คำตอบที่ไม่ถูกต้อง เช่น มัมมี่ กับปริศนาคำศัพท์ง่ายๆ เช่น ฉัน
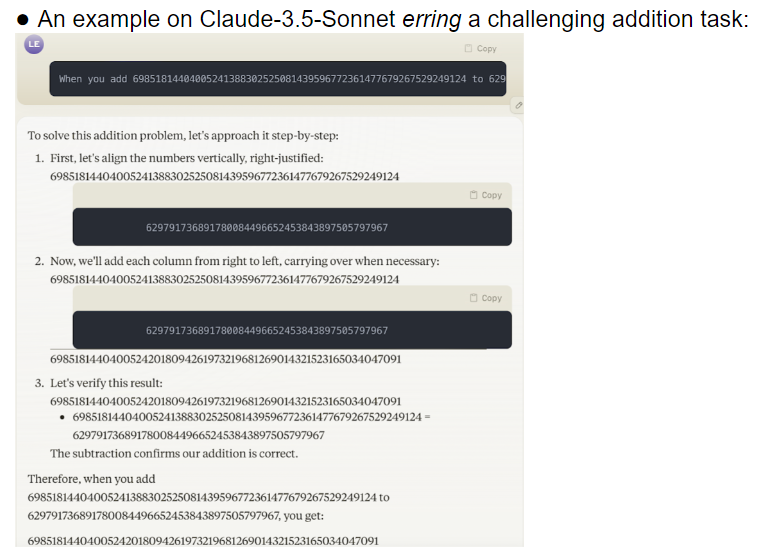
ทีมวิจัยได้ประเมินโมเดลขนาดใหญ่ที่แตกต่างกัน 32 โมเดล และผลการวิจัยพบว่าประสิทธิภาพของโมเดลเหล่านี้ไม่เสถียรอย่างยิ่งเมื่อต้องรับมือกับงานที่มีความยากต่างกัน ในงานที่ซับซ้อน ความแม่นยำนั้นต่ำกว่าความคาดหมายของมนุษย์มาก ที่แย่กว่านั้นคือ แบบจำลองต่างๆ ดูเหมือนจะก้าวไปสู่งานที่ยากขึ้นก่อนที่จะเชี่ยวชาญงานง่ายๆ ได้อย่างเต็มที่ ซึ่งนำไปสู่ข้อผิดพลาดบ่อยครั้ง

อีกประเด็นที่น่ากังวลคือความไวสูงของโมเดลต่อคำคิว การวิจัยพบว่าแบบจำลองจำนวนมากไม่สามารถทำงานง่ายๆ ให้สำเร็จได้อย่างถูกต้องหากไม่มีคำที่ออกแบบอย่างระมัดระวัง ภายใต้งานเดียวกัน การเปลี่ยนคำแจ้งเตือนอาจทำให้ประสิทธิภาพของโมเดลแตกต่างไปจากเดิมอย่างสิ้นเชิง ความไม่แน่นอนนี้นำมาซึ่งความท้าทายอย่างมากต่อการใช้งานจริง
สิ่งที่น่ากังวลยิ่งกว่านั้นคือแม้หลังจากการเรียนรู้แบบเสริมกำลังด้วยแบบจำลองการตอบสนองของมนุษย์ (RLHF) แล้ว ปัญหาความน่าเชื่อถือยังไม่ได้รับการแก้ไขขั้นพื้นฐาน ในสถานการณ์การใช้งานที่ซับซ้อน โมเดลเหล่านี้มักจะดูมั่นใจมากเกินไป แต่อัตราข้อผิดพลาดเพิ่มขึ้นอย่างมาก สถานการณ์นี้อาจทำให้ผู้ใช้ยอมรับผลลัพธ์ที่ไม่ถูกต้องโดยไม่รู้ตัว ส่งผลให้เกิดข้อผิดพลาดร้ายแรงในการตัดสิน
งานวิจัยนี้เทน้ำเย็นลงในสาขา AI อย่างไม่ต้องสงสัย โดยเฉพาะอย่างยิ่งเมื่อเปรียบเทียบกับการคาดการณ์ในแง่ดีของ Ilya Sutskever ผู้ชนะรางวัลโนเบลในสาขา AI เมื่อสองปีที่แล้ว เขาเคยกล่าวไว้ด้วยความมั่นใจว่าเมื่อเวลาผ่านไป ประสิทธิภาพของ AI จะค่อยๆ เป็นไปตามความคาดหวังของมนุษย์ อย่างไรก็ตาม ความเป็นจริงให้คำตอบที่แตกต่างไปจากเดิมอย่างสิ้นเชิง
งานวิจัยนี้เปรียบเสมือนกระจกเงาที่แสดงให้เห็นข้อบกพร่องหลายประการของโมเดลขนาดใหญ่ในปัจจุบัน แม้ว่าเราจะรู้สึกตื่นเต้นกับอนาคตของ AI แต่การค้นพบนี้เตือนเราว่าเราต้องระวังผู้ที่มีจิตใจดีเหล่านี้ ปัญหาความน่าเชื่อถือของ AI จำเป็นต้องได้รับการแก้ไขอย่างเร่งด่วน และเส้นทางสู่การพัฒนาในอนาคตยังอีกยาวไกล
งานวิจัยนี้ไม่เพียงแต่เผยให้เห็นสถานะปัจจุบันของการพัฒนาเทคโนโลยี AI แต่ยังให้ข้อมูลอ้างอิงที่สำคัญสำหรับทิศทางการวิจัยในอนาคตอีกด้วย มันเตือนเราว่าในขณะที่ดำเนินการปรับปรุงความสามารถของ AI เราต้องให้ความสำคัญกับความเสถียรและความน่าเชื่อถือให้มากขึ้นด้วย การวิจัย AI ในอนาคตอาจต้องมุ่งเน้นมากขึ้นเกี่ยวกับวิธีการปรับปรุงประสิทธิภาพที่สอดคล้องกันของแบบจำลอง และวิธีการค้นหาสมดุลระหว่างงานง่ายๆ และงานที่ซับซ้อน
อ้างอิง:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
โดยรวมแล้ว การวิจัยครั้งนี้ถือเป็นคำเตือนสำหรับการพัฒนาโมเดลภาษาขนาดใหญ่ โดยเตือนเราว่าเราต้องระมัดระวังเกี่ยวกับศักยภาพและข้อจำกัดของ AI การพัฒนาในอนาคตจำเป็นต้องให้ความสำคัญกับความน่าเชื่อถือและความเสถียรของโมเดลมากขึ้น แทนที่จะแสวงหา "ความฉลาด" เพียงผิวเผิน บรรณาธิการของ Downcodes หวังว่าบทความนี้สามารถสร้างแรงบันดาลใจให้ทุกคนคิดอย่างลึกซึ้งมากขึ้นเกี่ยวกับการพัฒนาเทคโนโลยี AI