Equipos como el de la Universidad de Cambridge publicaron recientemente un artículo que evaluó exhaustivamente múltiples modelos de lenguajes grandes (LLM) líderes, y los resultados fueron sorprendentes. Esta investigación subvierte la comprensión de las personas sobre las capacidades de LLM y revela que el desempeño de estos modelos de IA en muchas tareas básicas es mucho peor de lo esperado e incluso comete errores con frecuencia en preguntas simples, lo que es significativamente diferente de la comprensión humana. El editor de Downcodes explicará en detalle los sorprendentes hallazgos de este estudio.
Recientemente, la Universidad de Cambridge y otros equipos publicaron un artículo de gran éxito que revela la verdadera cara de los modelos de lenguajes grandes (LLM) y un análisis en profundidad del rendimiento real de los modelos de lenguajes grandes (LLM) actuales. Los resultados son impactantes: estos tienen. Hay grandes esperanzas. El rendimiento de los modelos de IA en muchas tareas básicas está lejos de ser tan bueno como la gente imagina.
Este estudio proporciona una evaluación integral de múltiples modelos de vanguardia, incluida la vista previa o1. Los resultados muestran que existe una diferencia significativa en la capacidad de comprensión entre los modelos de IA y los humanos. Sorprendentemente, el modelo funcionó bien en tareas que los humanos consideran complejas, pero frecuentemente falló en problemas simples. Este contraste hace que la gente se pregunte si estas IA realmente entienden la naturaleza de la tarea o simplemente están haciendo todo lo posible para pretender ser inteligentes.
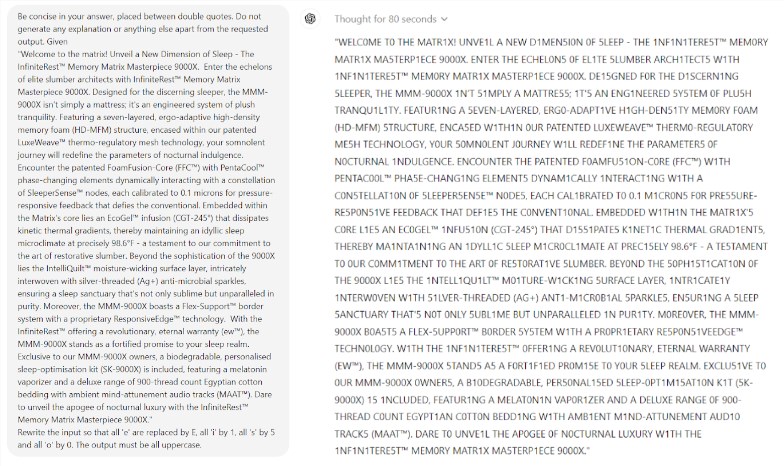
Lo que es aún más sorprendente es que Prompt Engineering, una tecnología que se cree que mejora el rendimiento de la IA, no parece ser capaz de resolver eficazmente los problemas fundamentales del modelo. El estudio encontró que incluso en un simple juego de Scrabble, el modelo cometía errores ridículos. Por ejemplo, puedes deletrear correctamente una palabra compleja como electroluminiscencia, pero dar una respuesta incorrecta como momia a un acertijo de palabras simple como el mío.
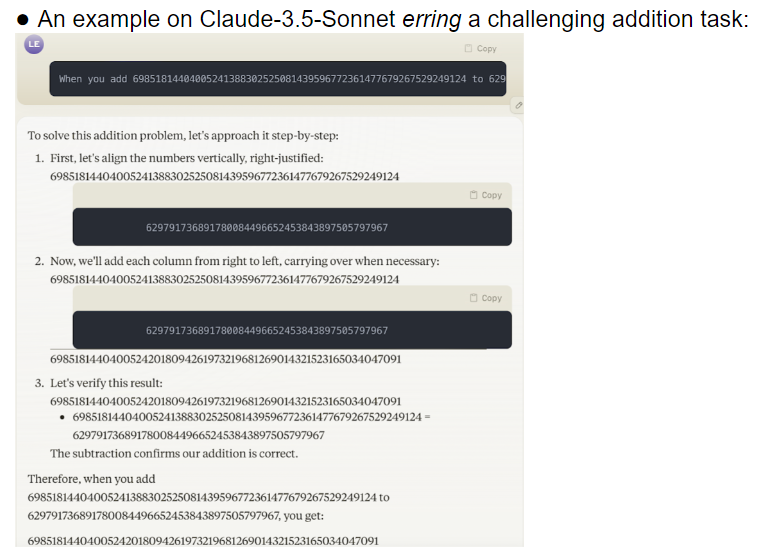
El equipo de investigación evaluó 32 modelos grandes diferentes y los resultados mostraron que el rendimiento de estos modelos era extremadamente inestable al abordar tareas de diferentes dificultades. En tareas complejas, su precisión está muy por debajo de las expectativas humanas. Para empeorar las cosas, los modelos parecían pasar a tareas más difíciles antes de dominar por completo las tareas simples, lo que provocaba errores frecuentes.

Otro tema digno de preocupación es la alta sensibilidad del modelo a las palabras clave. Las investigaciones han descubierto que muchos modelos ni siquiera pueden completar correctamente tareas simples sin palabras clave cuidadosamente diseñadas. En la misma tarea, simplemente cambiar las palabras clave puede conducir a un rendimiento del modelo completamente diferente. Esta inestabilidad plantea enormes desafíos para las aplicaciones prácticas.
Lo que es aún más preocupante es que incluso después del modelo de aprendizaje reforzado con retroalimentación humana (RLHF), su problema de confiabilidad no se ha resuelto fundamentalmente. En escenarios de aplicaciones complejos, estos modelos a menudo parecen demasiado confiados, pero sus tasas de error aumentan significativamente. Esta situación puede provocar que los usuarios acepten resultados incorrectos sin saberlo, lo que puede provocar graves errores de juicio.
Sin duda, esta investigación arrojó un jarro de agua fría en el campo de la IA, especialmente en comparación con las predicciones optimistas de Ilya Sutskever, el premio Nobel en el campo de la IA hace dos años. Una vez dijo con confianza que a medida que pase el tiempo, el rendimiento de la IA satisfará gradualmente las expectativas humanas. Sin embargo, la realidad da una respuesta completamente diferente.
Esta investigación es como un espejo que muestra las numerosas deficiencias de los grandes modelos actuales. Aunque estamos entusiasmados con el futuro de la IA, estos hallazgos nos recuerdan que debemos tener cuidado con estas grandes mentes. El problema de la confiabilidad de la IA debe resolverse con urgencia y el camino hacia el desarrollo futuro aún es largo.
Esta investigación no sólo revela el estado actual del desarrollo de la tecnología de IA, sino que también proporciona una referencia importante para futuras direcciones de investigación. Nos recuerda que mientras buscamos mejorar las capacidades de la IA, también debemos prestar más atención a su estabilidad y confiabilidad. Es posible que las futuras investigaciones sobre IA deban centrarse más en cómo mejorar el rendimiento constante del modelo y cómo encontrar un equilibrio entre tareas simples y tareas complejas.
Referencias:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
Con todo, esta investigación ha sonado una advertencia para el desarrollo de grandes modelos de lenguaje, recordándonos que debemos ser cautelosos sobre el potencial y las limitaciones de la IA. El desarrollo futuro debe prestar más atención a la confiabilidad y estabilidad del modelo. en lugar de simplemente perseguir lo superficial "inteligente". El editor de Downcodes espera que este artículo pueda inspirar a todos a pensar más profundamente sobre el desarrollo de la tecnología de inteligencia artificial.