Des équipes telles que l'Université de Cambridge ont récemment publié un article évaluant de manière exhaustive plusieurs grands modèles de langage (LLM) de premier plan, et les résultats ont été surprenants. Cette recherche bouleverse la compréhension des capacités LLM, révélant que les performances de ces modèles d'IA sur de nombreuses tâches de base sont bien pires que prévu, et commettent même fréquemment des erreurs sur des questions simples, ce qui est très différent de la compréhension humaine. L’éditeur de Downcodes expliquera en détail les résultats surprenants de cette étude.
Récemment, l'Université de Cambridge et d'autres équipes ont publié un article à succès, révélant le vrai visage des grands modèles de langage (LLM) et une analyse approfondie des performances réelles des grands modèles de langage (LLM) actuels. Les résultats sont choquants. de grands espoirs. Les performances des modèles d’IA sur de nombreuses tâches de base sont loin d’être aussi bonnes qu’on l’imagine.
Cette étude fournit une évaluation complète de plusieurs modèles de pointe, y compris o1-preview. Les résultats montrent qu’il existe une différence significative dans la capacité de compréhension entre les modèles d’IA et les humains. Étonnamment, le modèle a donné de bons résultats sur des tâches que les humains considèrent comme complexes, mais a souvent échoué sur des problèmes simples. Ce contraste amène les gens à se demander si ces IA comprennent vraiment la nature de la tâche ou si elles font simplement de leur mieux pour prétendre être intelligentes.
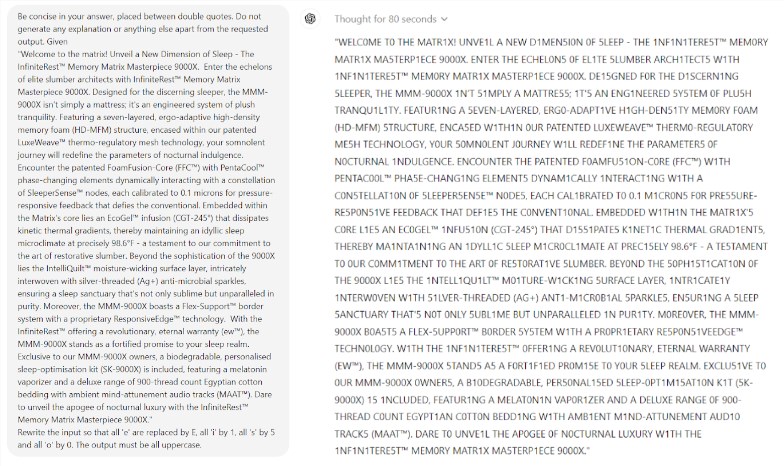
Ce qui est encore plus surprenant, c’est que Prompt Engineering, une technologie censée améliorer les performances de l’IA, ne semble pas être en mesure de résoudre efficacement les problèmes fondamentaux du modèle. L’étude a révélé que même dans un simple jeu de Scrabble, le modèle commettait des erreurs ridicules. Par exemple, vous pouvez épeler correctement un mot complexe comme électroluminescence, mais donner une réponse incorrecte comme maman à un mot simple comme mon.
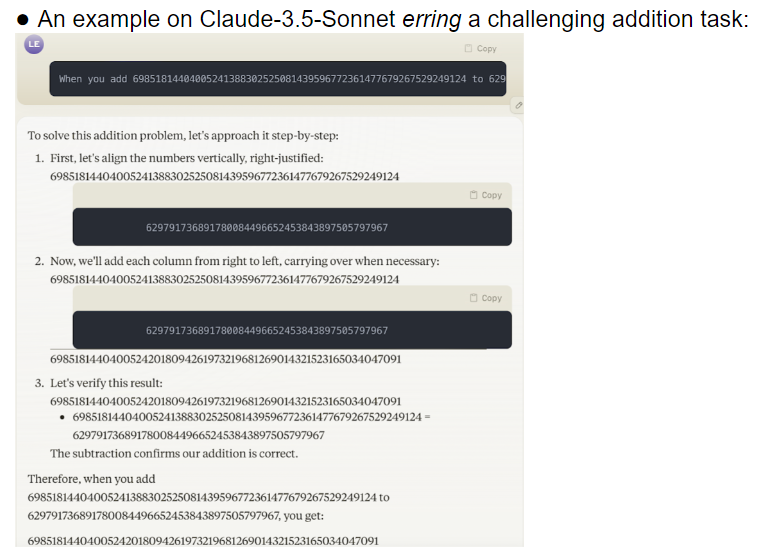
L'équipe de recherche a évalué 32 grands modèles différents et les résultats ont montré que les performances de ces modèles étaient extrêmement instables lorsqu'il s'agissait de tâches de différentes difficultés. Sur des tâches complexes, leur précision est bien inférieure aux attentes humaines. Pire encore, les modèles semblaient passer à des tâches plus difficiles avant d’avoir pleinement maîtrisé des tâches simples, ce qui entraînait des erreurs fréquentes.

Un autre problème digne de préoccupation est la grande sensibilité du modèle aux mots indicateurs. Des recherches ont montré que de nombreux modèles ne peuvent même pas accomplir correctement des tâches simples sans des invites soigneusement conçues. Dans le cadre d'une même tâche, le simple fait de modifier les mots d'invite peut conduire à des performances de modèle complètement différentes. Cette instabilité pose d'énormes défis aux applications pratiques.
Ce qui est encore plus inquiétant, c’est que même après le modèle d’apprentissage par renforcement avec rétroaction humaine (RLHF), son problème de fiabilité n’a pas été fondamentalement résolu. Dans des scénarios d’application complexes, ces modèles semblent souvent trop confiants, mais leurs taux d’erreur augmentent considérablement. Cette situation peut amener les utilisateurs à accepter des résultats incorrects sans le savoir, entraînant ainsi de graves erreurs de jugement.
Cette recherche a sans aucun doute versé de l’eau froide dans le domaine de l’IA, surtout si on la compare aux prédictions optimistes d’Ilya Sutskever, lauréat du prix Nobel dans le domaine de l’IA il y a deux ans. Il a dit un jour avec confiance qu'avec le temps, les performances de l'IA répondraient progressivement aux attentes humaines. Cependant, la réalité donne une réponse complètement différente.
Cette recherche est comme un miroir, montrant les nombreuses lacunes des grands modèles actuels. Même si nous sommes enthousiasmés par l’avenir de l’IA, ces découvertes nous rappellent que nous devons nous méfier de ces grands esprits. Le problème de fiabilité de l’IA doit être résolu de toute urgence et le chemin vers son développement futur est encore long.
Cette recherche révèle non seulement l’état actuel du développement de la technologie de l’IA, mais constitue également une référence importante pour les orientations futures de la recherche. Cela nous rappelle que tout en poursuivant l’amélioration des capacités de l’IA, nous devons également accorder davantage d’attention à sa stabilité et à sa fiabilité. Les futures recherches sur l’IA devront peut-être se concentrer davantage sur la manière d’améliorer les performances cohérentes du modèle et sur la manière de trouver un équilibre entre les tâches simples et les tâches complexes.
Références :
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
Dans l'ensemble, cette recherche a lancé un avertissement pour le développement de grands modèles de langage, nous rappelant que nous devons être prudents quant au potentiel et aux limites de l'IA. Les développements futurs doivent accorder davantage d'attention à la fiabilité et à la stabilité du modèle. plutôt que de simplement poursuivre le « intelligent » superficiel. L'éditeur de Downcodes espère que cet article pourra inciter tout le monde à réfléchir plus profondément au développement de la technologie de l'IA.